난 그동안 오픈서치를 직접 구축해서 사용은 해봤는데 그 원리에 대해서는 잘 몰랐었다.
그래서 이번에 한 번 공부하면서 블로그에도 정보 남겨보려고 한다.
1. 오픈서치란?
- Elasticsearch와 Kibana를 기반으로 하는 포크(fork)된 검색 프로젝트
- 데이터 탐색 및 분석을 쉽고 빠르게 해주는 통합 시각화 도구
- Elastic NV사에서 엘라스틱 서치, 키바나를 더 이상 오픈소스로 제공하지 않음 → 오픈 소스 유지를 위해 탄생
- 용도
- 로그 모니터링
- 통계 시각화
- 검색 엔진 등
2. 오픈서치 클러스터 구조
2-1. 노드

| 종류 | 역할 |
|---|---|
| 코디네이팅 노드 | 클러스터의 상태를 확인해서 사용자의 요청을 적절한 노드로 보내도록 라우팅을 하는 로드밸런서(LB) 역할을 하는 노드 엘라스틱서치의 노드에 모든 데이터 노드에 검색을 분산하고 결과를 집계해서 사용자에게 검색 결과를 반환 |
| 마스터 노드 | 클러스터의 전반적인 작업을 처리하는 역할 인덱스 생성, 삭제, 노드 추가, 노드 헬스 체크, 샤드 분배 |
| 데이터 노드 | 물리적으로 데이터를 저장하는 노드 |
2-2. 구성요소
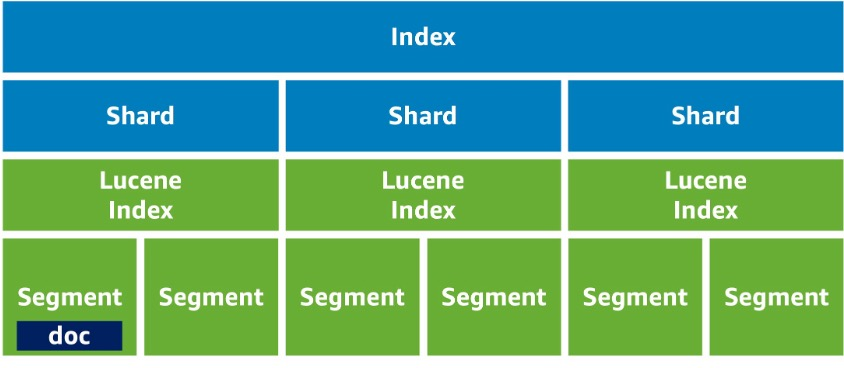
구성요소는 간단히 말해면 위 처럼 인덱스라는 개념이 있고 그 하위에 인덱스를 쪼갠 샤드가 있고 그 하위에 실제 데이터인 document가 저장되는 구조다
이해를 돕기 위해 RDBMS와 비교하면
index는 RDBMS의 table이고, document는 그 테이블 안에 저장되는 데이터라고 볼 수 있다.
| ElasticSearch | RDBMS |
|---|---|
| index | table |
| document | row |
좀 더 자세한 설명은 아래 덧붙이겠다.
인덱스
- Document가 저장되는 논리적인 공간
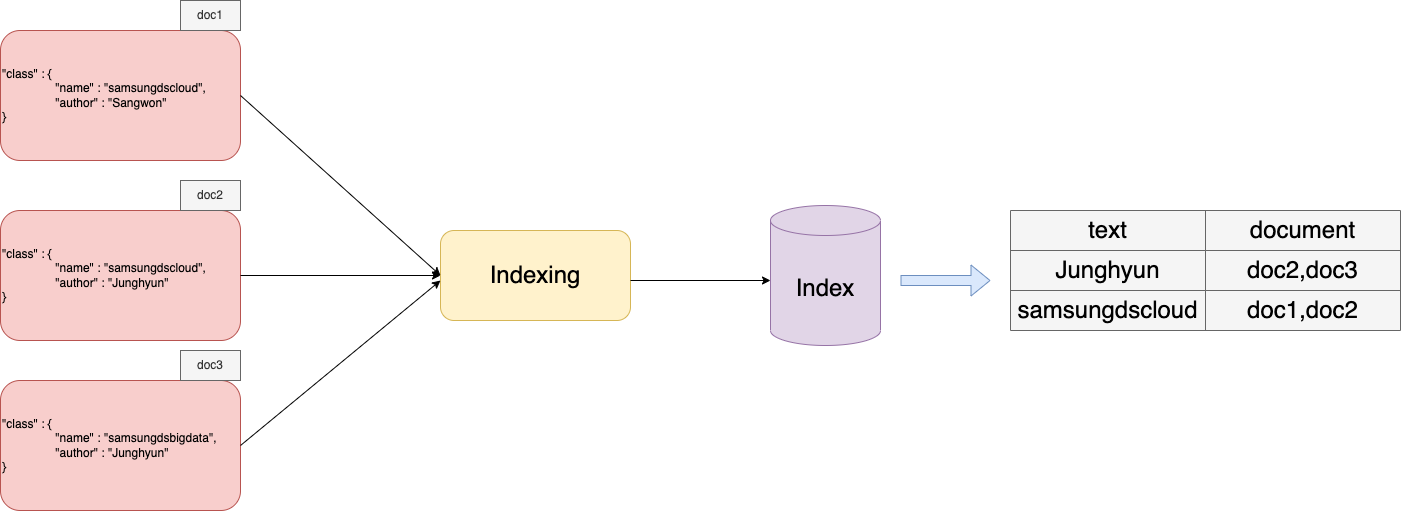
오픈서치 클러스터에 document가 들어오면 인덱싱이라는 과정을 통해 맨 오른 쪽 처럼 인덱스가 만들어진다.
인덱스가 만들어지면 저렇게 어떤 텍스트를 어떤 document가 포함하고 있는 지를 테이블 형태로 바로 알 수 있게 된다
샤드
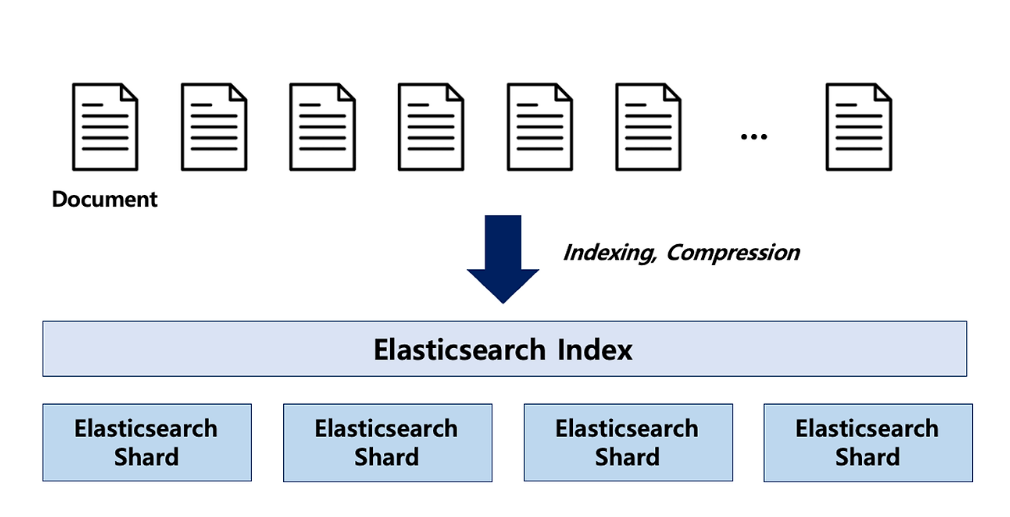
- 인덱스에 색인되는 문서(Document)가 직접 저장되는 공간
- 즉 인덱스에 데이터를 저장하면 데이터는 샤드에 기록되며 디스크에 저장
쉽게 말하면 실제 운영하는 서비스에서는 인덱스 크기 때문에 저렇게 쪼개서 저장한다. 그리고 이 때 나눠진 단위를 샤드라고 부른다고 보면 된다.
샤드의 종류는 아래와 같다.
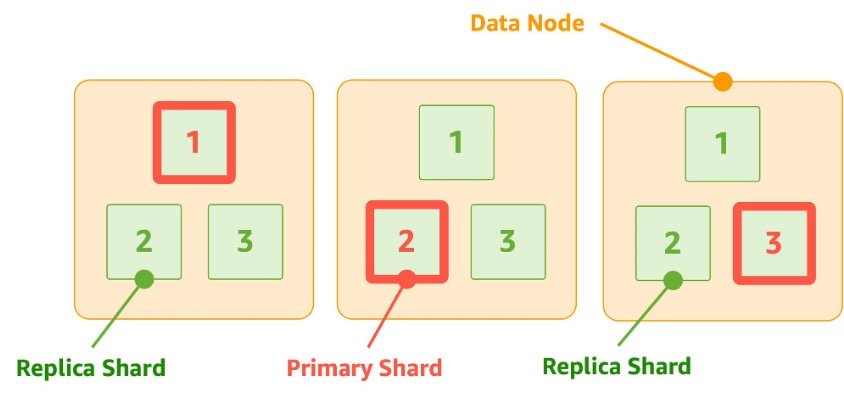
| 종류 | 역할 |
|---|---|
| 프라이머리 샤드 | 문서가 저장되는 원본 샤드, 색인과 검색 성능에 모두 영향을 줌 |
| 레플리카 샤드 | 프라이머리 샤드의 복제 샤드, 검색 성능에 영향을 줌 프라이머리 샤드에 문제가 생기면 레플리카 샤드가 프라이머리 샤드로 승격 |
2-3. 검색 원리
- RDBMS
- 테이블 형태로 저장
- walk가 들어간 데이터 검색 시 한 줄 씩 like 문을 통해 조회
→ 데이터가 많아질 수록 검색 속도가 느려짐

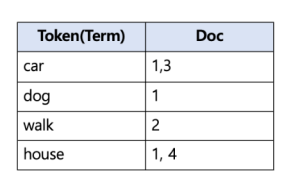
- Opensearch
- 텍스트를 tokenizer한 다음 검색어 사전을 만들어 테이블 형태로 저장
- 대,소문자 상관없이 검색되어야 하기 떄문에 모든 영어는 소문자로 변환
- 불필요한 단어 제거, token으로 만듦
- 각 단어에 매핑되는 document를 바로 찾을 수 있음

백엔드 개발자