1주차 미션 회고
우테코 5기 모집이 시작돼서 지원을 했다.
사실 나는 경력이 있기 때문에 어차피 프리코스를 진행해도 코스에 참여할 수 없다.
그럼에도 지원한 이유는 이번 기회에 프리코스 미션들을 진행하면서 실력을 쌓고 싶어서였다.
그리고 실제로 문제를 풀면서 정말 많은 생각을 할 수 있었고 많은 도움이 됐다.
그래서 후기를 남겨 보고자 한다.
1주차 미션은 7개의 알고리즘 문제를 자바로 푸는 미션이었다.
자세한 내용은 1주차 미션 깃헙 주소을 참고하면 된다.
1번 문제
요구사항

풀이 과정
요구사항을 나눠서 기능 단위로 커밋을 하는 걸 추천한다고 하길래
기능 단위로 함수를 만들고 그 단위로 커밋을 하려고 노력했다.
기능 단위로 쪼개기
- 페이지에서 각 자리 숫자를 더하거나 곱해서 큰 수를 반환하는 함수
- 왼쪽 페이지와 오른쪽 페이지 연산 결과 중에 큰 값을 반환하는 함수
- 페이지 오류를 확인하는 함수
이렇게 3가지 기능을 하는 함수로 쪼개서 메인함수에서는
이 함수들을 호출하기만 해서 그 구현내용을 알지못하도록 추상화했다.
제출 코드
package onboarding;
import java.util.List;
class Problem1 {
public static int solution(List<Integer> pobi, List<Integer> crong) {
int answer = Integer.MAX_VALUE;
try {
// 페이지 정보가 제대로 됐는 지 확인
if (is_abnormal_pages(pobi) || is_abnormal_pages(crong)){
return -1;
}
// 포비와 크롱이 뽑은 페이지 연산 결과 중 각각 최댓값
int pobi_max = find_max_between_pages(pobi);
int crong_max = find_max_between_pages(crong);
// 연산 결과를 토대로 누가 승리했는 지 찾기
answer = who_win(pobi_max, crong_max);
} catch (Exception e) {
return -1;
}
return answer;
}
public static int who_win(int pobi, int crong) {
if (pobi == crong) {
return 0;
} else if (pobi < crong) {
return 2;
} else {
return 1;
}
}
// 페이지 오류 확인
public static boolean is_abnormal_pages(List<Integer> pages){
int left_page = pages.get(0);
int right_page = pages.get(1);
if (left_page < 0 || right_page > 400){
return true;
}
if (left_page + 1 != right_page) {
return true;
}
return false;
}
// 왼쪽 페이지와 오른쪽 페이지 연산 결과 중에 최댓값
public static int find_max_between_pages(List<Integer> pages){
int left_max = find_max_between_sum_and_multi(pages.get(0));
int right_max = find_max_between_sum_and_multi(pages.get(1));
int max_num = (left_max < right_max) ? right_max : left_max;
return max_num;
}
// 해당 페이지의 숫자들을 더하거나 곱한 것 중에 최댓값
public static int find_max_between_sum_and_multi(Integer num) {
int sum = 0;
int multi = 1;
while (num != 0) {
int units = num % 10;
sum += units;
multi *= units;
num /= 10;
}
int max_num = (sum < multi) ? multi : sum;
return max_num;
}
}보완할 점
메인 함수(solution)에서는 최대한 함수를 호출해서 자세한 구현내용을 신경쓰지 않도록 추상화하려고 노력했다.
그런데 이제 생각해보니까 answer를 구하는 부분도 따로 함수로 빼는 게 더 깔끔하지 않나싶다.
public static int solution(List<Integer> pobi, List<Integer> crong) {
int answer = Integer.MAX_VALUE;
try {
// 페이지 정보가 제대로 됐는 지 확인
if (is_abnormal_pages(pobi) || is_abnormal_pages(crong)){
return -1;
}
// 포비와 크롱이 뽑은 페이지 연산 결과 중 각각 최댓값
int pobi_max = find_max_between_pages(pobi);
int crong_max = find_max_between_pages(crong);
// 연산 결과를 토대로 누가 승리했는 지 찾기 << 요렇게 추상화
answer = who_win(pobi_max, crong_max);
} catch (Exception e) {
return -1;
}
return answer;
}
public static int who_win(int pobi, int crong) {
if (pobi == crong) {
return 0;
} else if (pobi < crong) {
return 2;
} else {
return 1;
}
}이런식으로 했으면 더 깔끔했을 것 같다.
배운점
자바를 잘 사용하지 않아서 타입 선언할때 int도 있고 Integer도 있던데 대체 무슨 차이인지 궁금했다.
int는 null값을 가질 수 없고 Integer는 null값을 가질 수도 있다는 차이점이 있었다.
그래서 Integer는 언박싱을 안하면 연산을 할 수가 없다고 한다. (자바에선 대부분 자동으로 해준다)
그리고 int는 4바이트고 Integer는 16바이트라서 메모리를 더 사용한다.
2번 문제
요구사항

풀이 과정
처음에는 그냥 cryptogram을 돌면서 새로운 String 변수에 추가하되
이후값이 현재 값과 같을 경우에는 추가하지 않으면 된다고 생각했다.
근데 그러니까 중복이 제거가 되긴하는데 'aab'가 있으면 'ab'가 돼버린다.
이 문제는 아예 중복 문자를 다 제거해서 'b'가 되어야 하는 문제이기 때문에 이 방법은 못쓴다.
그래서 다음으로 생각한 게 그럼 이전 값과 이후 값을 둘다 체크해서 같으면 추가하지 않도록 할까였다.
그런데 이렇게 되면 구현할 수 있을 것 같지만 코드가 좀.. 더러울 것 같았다.
그래서 인터넷에 중복 제거 관련해서 어떻게 하는 지 살짝 검색을 해봤는데,
스택을 사용한다는 것을 알고 아! 했다.
그래서 최종적으로 생각한 방법은 cryptogram을 처음부터 돌면서 스택에다가 추가하되
이전 값을 계속 prev 변수에 저장해두고 현재 값이 이전값이랑 똑같으면 중복이라는 거니까 추가하지 않고,
중복 문자를 완전히 제거하기 위해 덱에서도 마지막 값이 현재 값이랑 같은지 확인하고 같으면 삭제하도록 했다.
기능단위로 쪼개기
- 주어진 cryptogram에 대해 중복 제거하기
- 1을 계속 반복하기
딱히 더 쪼갤 만한 게 없어서 이정도로만 쪼갰다.
제출 코드
package onboarding;
import java.util.ArrayDeque;
import java.util.Deque;
public class Problem2 {
public static String solution(String cryptogram) {
String cleaned_cryptogram = "";
while (true) {
cleaned_cryptogram = remove_duplication_from(cryptogram);
if (cleaned_cryptogram.equals(cryptogram)){
break;
}
cryptogram = cleaned_cryptogram;
}
return cleaned_cryptogram;
}
public static String remove_duplication_from(String cryptogram) {
int length = cryptogram.length();
if (length == 0){
return "";
}
Deque<Character> dq = new ArrayDeque<>();
dq.addLast(cryptogram.charAt(0));
Character prev = cryptogram.charAt(0);
for (int i=1; i < length; i++) {
Character curr = cryptogram.charAt(i);
if (prev == curr){
if (dq.peekLast() == curr) {
dq.removeLast();
}
} else {
dq.addLast(curr);
prev = curr;
}
String result = "";
while (!dq.isEmpty()){
result += dq.removeFirst();
}
return result;
}
}보완할 점
메인함수에서 while을 통해 계속 중복을 제거해줬는데,
이것도 따로 함수로 빼는 게 나았으려나? 하는 생각이 들어서 변경했다.
package onboarding;
import java.util.ArrayDeque;
import java.util.Deque;
public class Problem2 {
public static String solution(String cryptogram) {
String cleaned_cryptogram = remove_all_duplication_from(cryptogram);
return cleaned_cryptogram;
}
public static String remove_all_duplication_from(String cryptogram) {
String cleaned_cryptogram = "";
while (true) {
cleaned_cryptogram = remove_one_duplication_from(cryptogram);
if (cleaned_cryptogram.equals(cryptogram)){
break;
}
cryptogram = cleaned_cryptogram;
}
return cleaned_cryptogram;
}
public static String remove_one_duplication_from(String cryptogram) {
int length = cryptogram.length();
if (length == 0){
return "";
}
Deque<Character> dq = new ArrayDeque<>();
dq.addLast(cryptogram.charAt(0));
Character prev = cryptogram.charAt(0);
for (int i=1; i < length; i++) {
Character curr = cryptogram.charAt(i);
if (prev == curr){
if (dq.peekLast() == curr) {
dq.removeLast();
}
} else {
dq.addLast(curr);
}
prev = curr;
}
String result = "";
while (!dq.isEmpty()){
result += dq.removeFirst();
}
return result;
}
}변경해보니 확실이 이쪽이 더 깔끔해 보인다.
배운점
자바에서 덱을 어떻게 사용하는 지 알았다.
그리고 나는 if cleaned_cryptogram.equals(cryptogram) 이 부분을 원래는
if cleaned_cryptogram == cryptogram 이렇게 작성했었다.
그런데 인텔리제이에서 equals로 바꾸라고 제안이 떠서 뭐가 다른거지.. 하고 찾아봤다.
쉽게 말하면 == 연산은 주소를 비교하고 equals()는 주소도 비교하고 다르면 값도 비교한다.
좀 더 자세하게 말하면
== 연산은 int,boolean primitive type에 대해서는 값을 비교하고 reference type에 대해서는 주소값을 비교한다.
String은 객체니까 reference type이므로 ==를 사용하면 주소를 비교하게 된다.
String 객체의 equals()는 변수로 들어온 객체가 자기 자신과 주소값이 같으면 true를 리턴한다.
주소값이 다르다면 내부의 Char를 하나씩 비교해 보면서 끝까지 같다면 true, 다르면 false를 리턴한다.
참고로, equals()는 Object타입에서는 ==연산을 사용하는데 String객체에서만 이렇게 오버라이딩한 것이다.
그래서 코드로 설명하면 아래와 같다.
public static void main(String[] args){
Stirng A = "Java"; // 리터럴(literal) 주소값 : 1000
Stirng B = "Java"; // 리터럴(literal) 주소값 : 1000
Stirng C = new Stirng("Java"); // new 연산자 주소값 : 2000
Stirng D = new Stirng("Java"); // new 연산자 주소값 : 3000
}리터럴(literal)을 사용해서 String을 생성하면 객체가 String Constant Pool 영역에 만들어지고,
new 연산자를 통해 String을 생성하면 Heap 영역에 만들어진다.
그래서 A와 B는 String Constant Pool 영역에 만들어진 하나의 객체를 참조하고,
C와 D는 Heap 영역에 각각 개별의 객체가 생성된다.
즉, 객체 개수는 A와 B 합쳐서 1개 + C 1개 + D 1개 = 총 3개가 나온다.

그림으로 표현하면 이렇게 된다.
System.out.println( A == B ); // true 주소값 : 1000 == 1000
System.out.println( B == C ); // false 주소값 : 1000 == 2000
System.out.println( C == D ); // false 주소값 : 2000 == 3000그래서 == 연산을 사용하면 결과가 이렇게 나오게 되는 것이다.
하지만 equals()같은 경우에는 값도 비교하기 때문에 모두 true를 반환한다.
3번 문제
요구사항

풀이 과정
DP문제를 몇개 풀다보니까 딱 보자마자 DP의 냄새가 났다.
어떻게 DP문제를 판단하고 푸는 지는 이전에 블로그에 정리한 적이 있어서 이 포스팅을 참고해도 좋을 것 같다.
dp[i] = i 까지 누적된 박수 횟수
dp[1] = 0 = 0
dp[2] = dp[1] + 0 = 0
dp[3] = dp[2] + 1 = 1 (3이니까 한번 쳐야함)
dp[4] = dp[3] + 1 = 1이런식으로 이전까지 누적된 박수 횟수에 현재 쳐야할 박수 횟수를 더하는 식으로 구성하면 된다.
기능 별로 쪼개기
- 현재 값에서 쳐야할 박수 횟수 계산하기
- dp 테이블에 누적해서 저장하고 dp[number] 값 리턴하기
현재 값에서 쳐야할 박수 횟수는 그냥 숫자의 모든 자리수를 돌면서 3,6,9가 들어있으면 +1을 추가하면 된다.
제출 코드
package onboarding;
import java.util.List;
public class Problem3 {
public static int solution(int number) {
int[] crap_count = new int[number+1];
crap_count[0] = 0;
for (int i=1; i <= number; i++) {
crap_count[i] = crap_count[i-1] + calculate_clap_count(i);
}
return crap_count[number];
}
public static int calculate_clap_count(int number){
int count = 0;
while (number != 0) {
int units = number % 10;
if (units == 3 || units == 6 || units == 9) {
count += 1;
}
number /= 10;
}
return count;
}
}보완할 점
이것도 메인함수에서 dp테이블을 채워나가는 것까지 구현했는데,
dp 테이블을 만드는 함수도 따로 추가하는 게 더 깔끔했겠다라는 생각이 든다.
배운 점
dp 테이블을 선언할 때 배열, 배열리스트 중에 하나를 써야했어서 뭐가 다르지? 하고 찾아봤다.
-
Array
- 고정된 크기를 갖는 같은 자료형의 원소들이 연속적인 형태로 저장된 자료구조
- 메모리에 연속되어 저장된다.
- 데이터 갯수가 확실하게 정해져 있고, 접근이 빈번한 경우 효율적
- Compile time에 할당되는 정적 메모리 할당
- cache hit 가능성이 커져 성능에 큰 도움이 된다.
- cache hit : CPU가 참조하고자 하는 메모리가 캐시에 존재하고 있는 경우
- 왜냐하면 메모리에 연속적인 주소에 저장돼 있기 때문이다.
- 특정위치에 있는 값에 접근하거나, 수정하는 연산은 O(1)이다.
- 중간에 삽입과 삭제의 경우 연속적인 형태 유지를 위해 shift 연산을 해야하므로 O(n)이 된다.
- 삽입하면 그 뒤에 있는 요소들을 뒤로 한칸 씩 밀고 삭제하면 앞으로 땡기는 식으로 동작
- 끝에 삽입/삭제 시에는 O(1)이다.
- 삽입/삭제가 빈번하다면 링크드 리스트를 사용하는 게 좋다.
-
List
- 빈틈없는 데이터의 적재를 위한 자료구조
- 메모리에 분산되어 저장된다.
- 특정위치에 있는 값에 접근하거나, 수정하는 연산은 O(n)이다.
- 삽입/삭제의 경우 O(1)이다.
- 그 값을 찾으러 가는데는 최악의 경우에 O(n)이 걸릴 수도 있다.
- 새로운 Node가 추가되는 runtime에 할당되는 동적 메모리 할당
- 빈 엘리먼트는 허용하지 않는다.
- 순차성을 보장하지 못하기 때문에 spacial locality 보장이 되지 않아 cash hit가 어렵다.
- spacial locality : 이후 접근할 메모리 영역은 이미 접근이 이루어진 영역의 근처일 확률이 높다는 특성
-
Array List
- 쉽게 말하면 크기가 가변적인 배열
- 배열과 인덱스의 특징을 모두 가진다.
- 인덱스를 사용할 수 있고(배열 특징) 가변적인 크기(리스트 특징)를 가질 수도 있다.
- 배열을 통해 리스트를 구현한 것
- 용량이 꽉 차면 기존 용량의 1.5배를 늘린 새로운 배열에 기존 배열을 copy하는 식으로 동작
- Default 저장용량은 10
- List 인터페이스를 상속받은 클래스로 크기가 가변적으로 변하는 선형리스트
- 중간에 삽입과 삭제의 경우 연속적인 형태 유지를 위해 shift 연산을 해야하므로 O(n)이 된다.
- 삽입하면 그 뒤에 있는 요소들을 뒤로 한칸 씩 밀고 삭제하면 앞으로 땡기는 식으로 동작
- 끝에 삽입/삭제 시에는 O(1)이다.
- 삽입/삭제가 빈번하다면 링크드 리스트를 사용하는 게 좋다.
- 특정위치에 있는 값에 접근하거나, 수정하는 연산은 O(1)이다.
- 배열에 비해 살짝 느리다.
- 새로운 요소를 추가할 때, 여유 공간이 있는 경우엔 O(1)이지만, 여유공간이 없는 경우엔 O(n)이므로
리스트는 인덱스를 사용할 수 없으니 탈락이고
배열과 배열리스트 중에서는 어차피 dp 테이블의 크기는 number+1로 고정돼 있기 때문에
속도가 좀 더 빠른 배열로 선언하면 되겠다 하고 배열로 선언했다.
4번 문제
요구사항
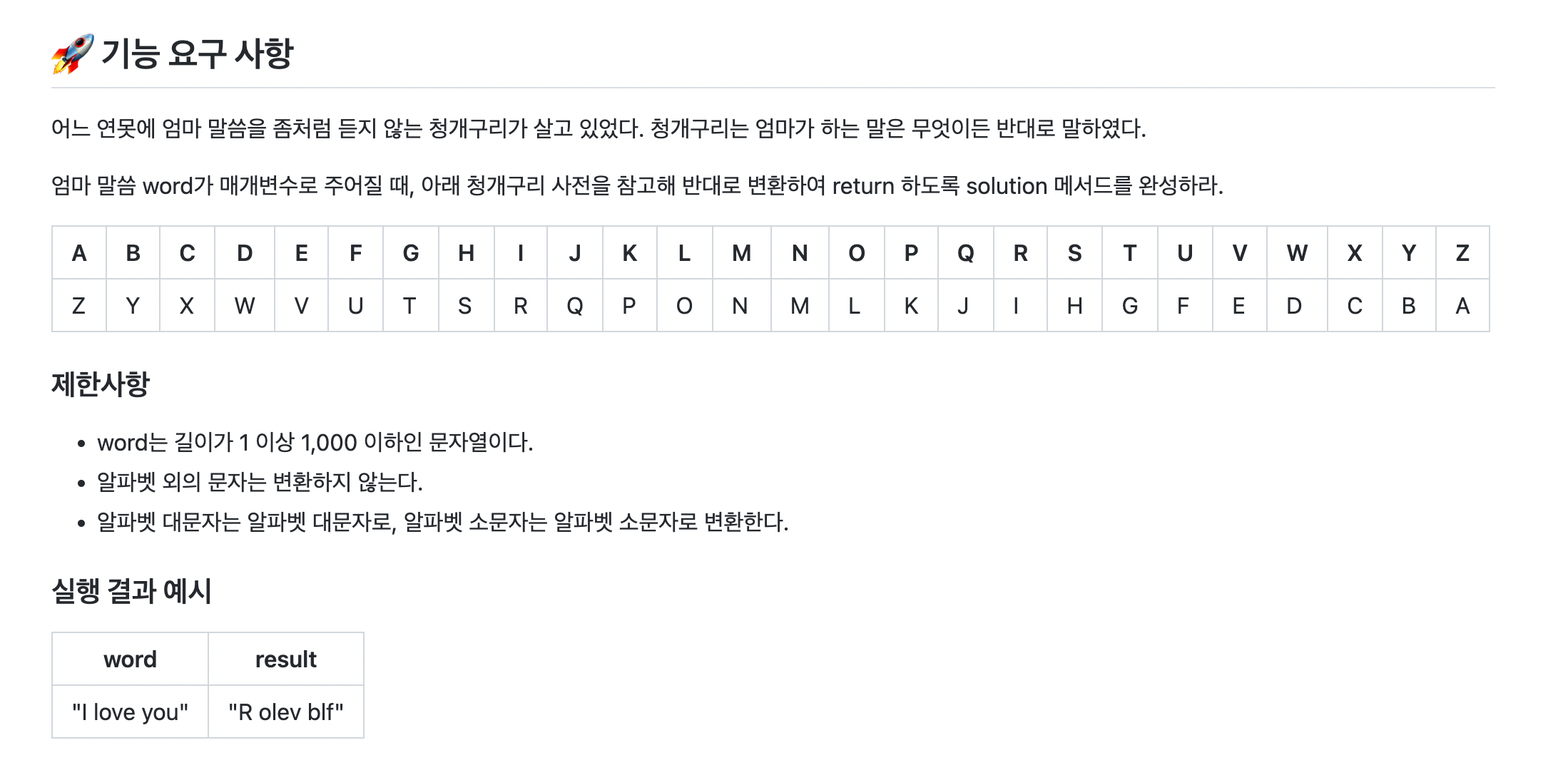
풀이 과정
아스키 코드를 이용해서 변환 사전을 만들어서 하나씩 변환하면 되겠다고 생각했다.
기능 별로 쪼개기
- 아스키 코드 두개를 받아서 하나는 +1 하나는 -1하면서 매칭 시키기
- 소문자 변환, 대문자 변환 따로 해서 합친 사전 만들기
- 변환 사전을 적용해 첫글자 부터 변환해서 결과 리턴하기
제출 코드
package onboarding;
import java.util.HashMap;
import java.util.Map;
public class Problem4 {
public static String solution(String word) {
String answer = "";
Map<Character, Character> convert_dict = make_convert_dict();
for (char c : word.toCharArray()) {
if (convert_dict.get(c) != null){
answer += convert_dict.get(c);
} else {
answer += c;
}
}
return answer;
}
public static Map<Character, Character> make_convert_dict(){
Map<Character, Character> convert_dict;
Map<Character, Character> uppercase_convert_dict = match_ascii_between(65, 90);
Map<Character, Character> lowercase_convert_dict = match_ascii_between(97, 122);
uppercase_convert_dict.putAll(lowercase_convert_dict);
convert_dict = uppercase_convert_dict;
return convert_dict;
}
public static Map<Character, Character> match_ascii_between(int start_ascii, int end_ascii){
Map<Character, Character> convert_dict = new HashMap<>();
for (int i = 0; i < 26; i++) {
Character start_alpha = (char)start_ascii;
Character end_alpha = (char)end_ascii;
convert_dict.put(start_alpha, end_alpha);
convert_dict.put(end_alpha, start_alpha);
start_ascii += 1;
end_ascii -= 1;
}
return convert_dict;
}
}5번 문제
요구사항

풀이 과정
그리디로 풀면 되지 않을까 하고 그렇게 풀었다.
큰 금액으로 나눌 수 있으면 최대한 큰 금액으로 나누고 그걸 그 다음 큰 금액으로 나누고 하는식으로..
- 50000원으로 나눈 몫을 result[0]에 저장하고 나머지는 남은 돈에 저장한다.
- 1번에서 남은 돈을 10000원으로 나누고 몫을 result[1]에 저장하고 나머지는 남은 돈에 저장한다.
....
를 반복했다.
제출 코드
package onboarding;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class Problem5 {
public static List<Integer> solution(int money) {
List<Integer> answer = new ArrayList<>();
// 돈 종류
List<Integer> money_types = List.of(50000, 10000, 5000, 1000, 500, 100, 50, 10, 1);
// 큰 돈 부터 나눠가면서 몫을 구해가면 된다.
for (int money_type : money_types) {
int quotient = money / money_type;
answer.add(quotient);
money %= money_type;
}
return answer;
}
}배운점
배열 초기화할 때 List.of 와 Arrays.asList 이런 것들이 있던데 뭐가 다른 건지 궁금해서 찾아봈다.
| Array.asList | List.of | |
|---|---|---|
| 삽입(add) | 불가능 | 불가능 |
| 삭제(remove) | 불가능 | 불가능 |
| 변경(set, replace) | 가능 | 불가능 |
| Null허용여부 | 허용 | 허용X |
일단 요약하면 이런 특징을 가진다.
Arrays.asList()는 수정이 가능하고, List.of()는 불가능한 이유는 뭘까?
Arrays.asList()는 Arrays 내부 클래스 타입인 ArrayList를 반환하기 때문에 set이 구현돼 있다.
List.of()는 ListN이라는 타입의 객체를 반환하는데 이는 불변 객체라서 변경할 수 없다.
그리고 Arrays.asList()는 thread safety 하지 않고, List.of()는 thread safety하다.
thread safety
어떤 함수나 변수, 혹은 객체가 여러 스레드로부터 동시에 접근이 이루어져도
프로그램의 실행에 문제가 없다는 것을 의미한다.
추가로 Arrays.asList()는 참조를 사용하기 때문에 배열의 값이 변경되면 list에도 영향이 간다.
Integer[] array = {1,2};
List<Integer> list = Arrays.asList(array);
array[0] = 100;
System.out.println(list); // [100, 2]반대로 List.of()의 결과는 값을 기반으로 독립적인 객체를 만들기 때문에 참조가 일어나지 않는다.
Integer[] array = {1,2};
List<Integer> list = List.of(array);
array[0] = 100;
System.out.println(list); // [1, 2]Arrays.asList()는 List.of()보다 힙에 더 많은 개체를 생성해서 공간을 더 많이 차지한다.
따라서 단지 값 요소가 필요한 경우라면 List.of()가 적합하다고 한다.
Arrays.asList()는 크고 동적인 데이터에 사용하고,
List.of()는 작고 변경되지 않는 데이터의 경우 사용한다고 기억하면 될 듯하다.
6번 문제
요구 사항
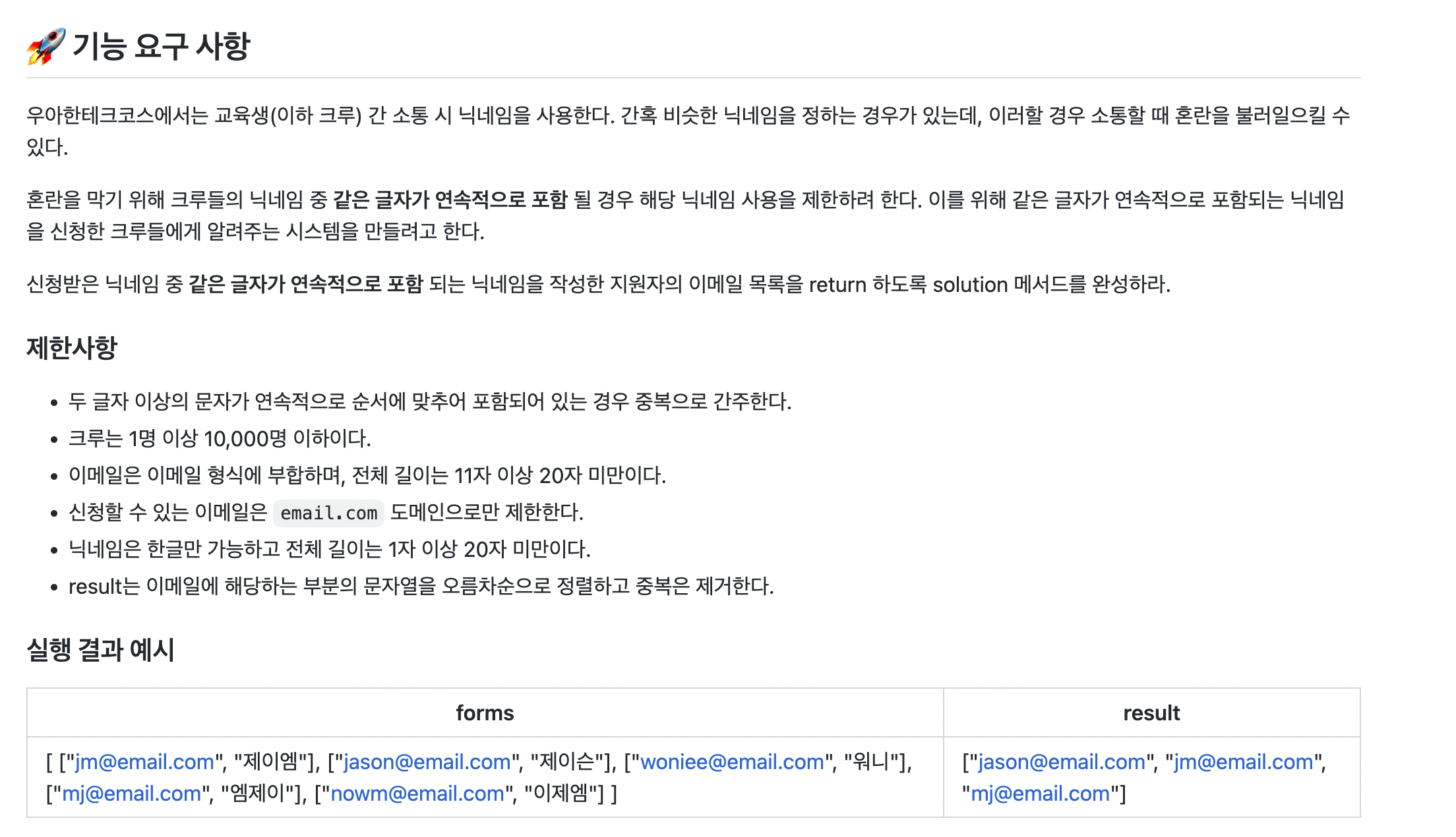
풀이 과정
hashmap을 이용해서 각 크루의 닉네임을 모두 돌면서 연속된 2글자씩 잘라서 key로 설정하고,
그 key에 속하는 이메일들을 value에 set으로 저장해 나가면 되지 않을까 해서 그렇게 풀었다.
그러니가 위의 예시를 보면
먼저 제이엠의 경우에는 제이, 이엠으로 나누어진다.
이걸 key로 해서 아래와 같이 저장한다.
{
제이: {jm@email.com},
이엠: {jm@email.com},
}그 다음에 제이슨으로 넘어가면
{
제이: {jm@email.com, jason@email.com},
이엠: {jm@email.com},
이슨: {jason@email.com}
}이런식으로 채워나가서 value의 길이가 2개 이상인 것들만 뽑아내면 답이 될 것이다.
기능 별로 쪼개기
- 해시맵을 만든다.
- 해시맵을 토대로 key에 대한 value가 2개 이상인 항목들을 찾아서 중복 이메일 set에 넣는다.
- 결과를 sort한다.
제출 코드
package onboarding;
import java.util.*;
import java.util.Collections;
public class Problem6 {
public static List<String> solution(List<List<String>> forms) {
List<String> answer = List.of();
answer = find_duplicated_email_addresses(forms);
Collections.sort(answer);
return answer;
}
// 중복된 닉네임을 가진 유저들의 이메일 주소 모두 찾기
public static List<String> find_duplicated_email_addresses(List<List<String>> forms) {
Map<String, HashSet<String>> matched_addresses_hash = new HashMap<>();
Set<String> duplicated_email_addresses = new HashSet<>();
// 각자 닉네임에서 나올 수 있는 연속된 두글자 조합을 모두 구해서 각 조합에 해당하는 사람이 몇명인 지 확인하면 된다.
for (List<String> form : forms) {
String email = form.get(0);
String nickname = form.get(1);
// 이 유저의 닉네임에서 나올 수 있는 모든 연속된 두 글자 조합에 대하여
for (int i = 0; i < nickname.length() - 1; i++) {
String sub_str = nickname.substring(i, i + 2);
// 이 두글자 조합이 들어간 닉네임을 가진 사람들의 이메일 주소들 (set으로 구현해서 중복이 제거됨)
HashSet<String> matched_email_addresses = matched_addresses_hash.getOrDefault(sub_str, new HashSet<>());
matched_email_addresses.add(email);
// 이 두글자 조합이 들어간 닉네임을 가진 사람들의 수가 2명 이상일 경우
if (matched_email_addresses.size() > 1) {
// 다른사람들과 중복된 닉네임이므로 추가 (set으로 구현해서 중복이 제거됨)
duplicated_email_addresses.addAll(matched_email_addresses);
}
// 이 두글자 조합이 들어간 닉네임을 가진 사람들의 이메일 주소들에 현재 유저의 이메일도 추가
matched_addresses_hash.put(sub_str, matched_email_addresses);
}
}
return new ArrayList<>(duplicated_email_addresses);
}
}개선할 점
나중에 모든 key를 확인하는 작업을 하지 않을려고 해시맵을 만듦과 동시에 중복된 이메일 주소도 추가해줬는데,
이렇게 되면 이미 체크한 key들을 계속 체크해서 추가해줘야 해서 작업이 더 늘어나는 문제가 있을 수 있다.
{
제이: {jm@email.com, jason@email.com},
이엠: {jm@email.com},
이슨: {jason@email.com}
}예를 들어서 해시 맵을 만들다가 위의 상황이 되면 value가 2개가 됐기 때문에
duplicated_email_addresses에 jm@email.com, jason@email.com가 추가된다.
여기서 [jamie@email.com", "제이미"] 라는 데이터가 더 들어왔다고 생각해보자.
{
제이: {jm@email.com, jason@email.com, jamie@email.com},
이엠: {jm@email.com},
이슨: {jason@email.com},
이미: {jamie@email.com}
}그러면 또 다시 duplicated_email_addresses에
jm@email.com, jason@email.com, jamie@email.com를 넣어야 한다.
그래서 value의 길이가 2개가 됐을 경우에는 둘 다 duplicated_email_addresses에 add해 주고,
3개 이상이 됐을 경우에는 현재 이메일만 add하는 방법으로 개선하고 싶다.
public static List<String> find_duplicated_email_addresses(List<List<String>> forms) {
Map<String, HashSet<String>> matched_addresses_hash = new HashMap<>();
Set<String> duplicated_email_addresses = new HashSet<>();
for (List<String> form : forms) {
String email = form.get(0);
String nickname = form.get(1);
for (int i = 0; i < nickname.length() - 1; i++) {
String sub_str = nickname.substring(i, i + 2);
HashSet<String> matched_email_addresses = matched_addresses_hash.getOrDefault(sub_str, new HashSet<>());
matched_email_addresses.add(email);
// 이 두글자 조합이 들어간 닉네임을 가진 사람들의 수가 2명 인 경우
if (matched_email_addresses.size() == 2) {
// 저장된 모든 이메일 추가
duplicated_email_addresses.addAll(matched_email_addresses);
}
// 이 두글자 조합이 들어간 닉네임을 가진 사람들의 수가 2명 이상인 경우
else if (matched_email_addresses.size() > 2) {
// 현재 이메일 한 개 만 추가
duplicated_email_addresses.add(email);
}
matched_addresses_hash.put(sub_str, matched_email_addresses);
}
}
return new ArrayList<>(duplicated_email_addresses);
}코드로 나타내면 이렇게 된다.
배운점
HashMap과 HashSet의 차이를 알게 됐다.
HashMap
1. HashMap은 Map 인터페이스를 구현했다.(implement)
2. HashMap은 데이터를 key-value 형식으로 저장한다.
3. put() 메소드는 데이터를 넣을 때 사용된다.
4. HashMap에서 hashcode 값은 key value를 이용하여 생성한다.
5. HashMap은 unique key를 이용하여 데이터에 바로 접근하기에 HashSet에 비해서 빠르다.
HashSet
1. HashSet은 Set 인터페이스를 구현했다.(implement)
2. HashSet은 객체만 저장할 수 있다.
3. add() 메소드를 통해 데이터를 저장한다.
4. 들어가는 객체를 이용하여 hashcode를 생성하고, equal() 메소드를 이용해 hashcode를 비교, 중복된 객체가 있는지 체크한다. (equal() 메소드는 중복된 객체가 있으면 true를, 없으면 false를 리턴한다.
5. HashMap에 비해 느리다.
커밋 & 푸시
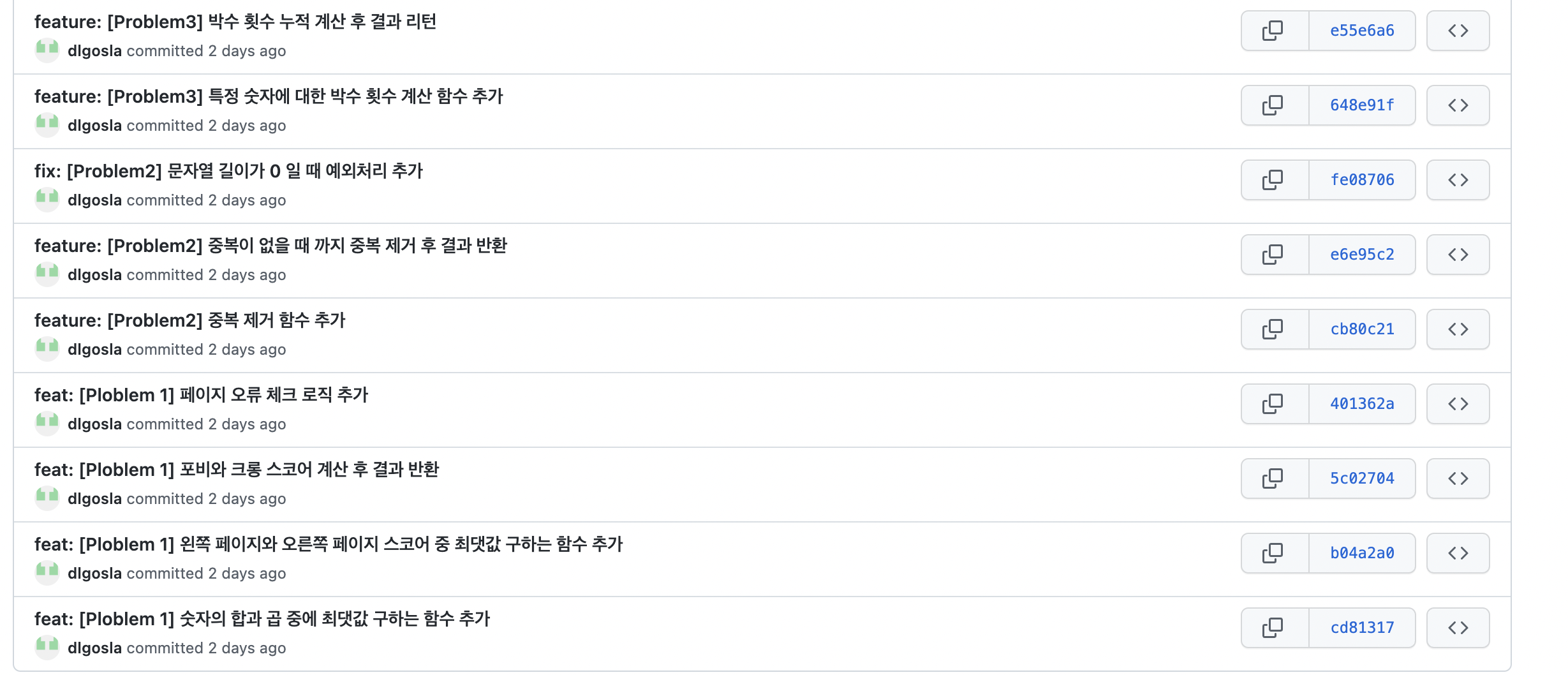
이렇게 문제를 풀고서는 문제마다 기능별로 커밋하도록하고, 커밋 메시지도 알기 쉽게 작성하도록 노력했다.
이렇게 커밋하니까 훨씬 깔끔하고 알기 쉽다는 것을 깨닫고 계속 이런 습관을 길러야겠다고 다짐했다.
생각보다 길어져서 시간 날때 마다 추가하겠다.
이제 7번 문제만 추가하면 된다.
문제를 풀면서도 많이 배웠지만 블로그에 포스팅하면서
다시 코드를 보니까 개선할 부분도 보이고 더 궁금한 것도 생기고 해서 더 배울 수 있게 됐다.
아! 그리고 여기 올린 코드들은 테케는 다 통과했지만 모든 테케에 대응하는 정답인 지는 모른다.
그래서 혹시 틀린점이 있다면 댓글 남겨주시면 감사하겠습니다.
