1. 해시테이블(Hashtable)
1.1 해시테이블이란?
해시테이블
-효율적인 검색과 삽입 연산을 위햇 설계된 자료구조
-키-값을 해시함수로 해싱하여 해시테이블의 특정 위치로 직접 엑세스하도록 만든 방식
해시(Hash) : 임의의 데이터를 고정된 길이의 데이터로 매핑하는 단방향 함수
해시 테이블을 사용할 수 있는 예시로, 아래와 같은 상황을 생각해볼 수 있다.
학생의 정보를 입력하고, 학생의 정보를 찾는 기능을 만들고 싶다. 이때 학생이 입력하는 정보는 이름, 주소, 전화번호라고 생각해보자.
여기서 학생의 정보를 찾기 위한 정보로, 전화번호를 사용한다고 하자. 전화번호를 전부 입력해서 대조하여 번호를 찾을 수도 있겠지만, 전화번호 010-XXXX-XXXX로 검색하기에는 데이터값이 너무 커서 검색 속도가 느려질 수 있다.
이와 같은 상황을 생각하여, 전화번호 전체가 아니라 일부만 사용하여 검색할 수 있도록 할 수 있다.
이와 같은 상황을 생각하여 아래와 같이 데이터를 입력하도록 만들었다.
전화번호 중 뒷자리 네 자리만 키로 만들어 정보를 검색할 수 있도록 만든 것이다.
public struct StudentData
{
public string name;
public string adress;
public int phone;
public int score;
}
static void Main(string[] args)
{
// 학생 : 학생정보(Value : 값)
// 핸드폰 번호 : 찾기 위힌 수단(Key : 키)
StudentData[] data = new StudentData[100000000];
// 해시(Hash) : 핸드폰 뒷자리 4자리를 써서 사용하자
data[5678] = new StudentData { name = "홍길동", adress = "서울", phone = 01012345678, score = 100 };
data[2222] = new StudentData { name = "김전사", adress = "경기", phone = 01011112222, score = 1 };
StudentData hong = data[5678];
StudentData kim = data[2222];
}여기에서 키를 전화번호 뒤 네 자리로 설정하고, 학생 정보를 탐색할 수 있게 설정하였다.
이때 전화번호 자체는 따로 저장되어 있지만, 전화번호의 뒷자리만 키로 따로 저장되어 검색이 용이하게 만든 것이다.
1.2 해시테이블의 구현
데이터를 담을 테이블을 이미 크게 확보해 놓은 후, 입력받은 키를 해싱하여 테이블의 고유한 index를 계산하고 데이터를 담아 보관한다.
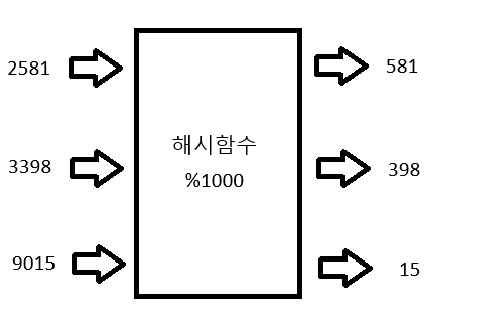
해시함수
-키값을 해싱하여 고유한 index를 만드는 함수이다.
-조건으로 하나의 키값을 해싱하는 경우 반드시 항상 같은 index를 반환해야 한다.
- 대표적인 해시함수로 나눗셈법이 있음
예시 : 2581 -> (2581 % 1000) = 581 (뒤 세 자리만 키로 사용)
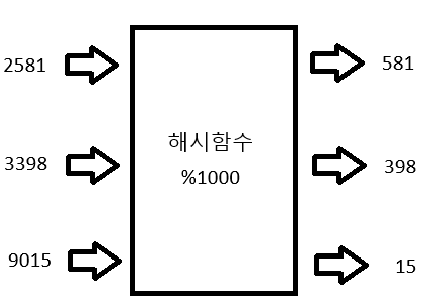
1.3 해시테이블 주의점 - 충돌
그렇다면 위와 같은 해시함수에서, 아래와 같은 상황이 발생한다고 생각할 수 있다.
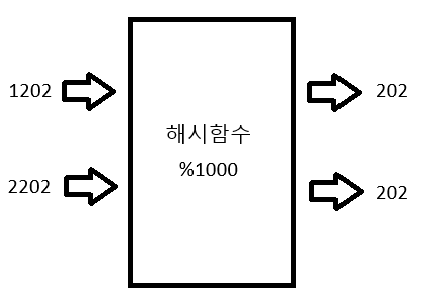
1202와 2202는 다른 숫자지만, 키로 변환하는 과정에서 같은 키가 되어버렸다. 이런 상황은 충분히 발생할 수 있으며, 이와 같은 상황을 충돌이라고 한다.
해시테이블의 주의점 - 충돌
해시함수가 서로 다른 입력값에 대해 동일한 해시테이블 주소를 반환하는 것.
모든 입력값에 대해 고유한 해시값을 만드는 것은 불가능하며 충돌은 피할 수 없다.
이와 같이 충돌이 발생하는 상황에서의 해결 방법에 관해 아래에 서술하겠다.
1.4 해시테이블의 충돌 해결 방안
1.4.1) 충돌 해결 방안 1 - 체이닝
- 체이닝
해시 충돌이 발생하면 연결리스트로 데이터들을 연결하는 방식
1.3) 의 상황을 예시로 들었을 때, 아래와 같이 표현하는 방식이다.
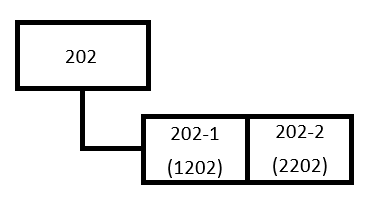
같은 키로 숫자가 저장되었을 때 그 키에 대한 연결리스트를 만들어, 해당 키의 상세 숫자를 저장한다.
이때 해당 연결리스트 정보를 저장하기 위한 공간이 따로 필요하다.
체이닝의 장단점
장점 : 해시테이블에 자료사용률에 따른 성능저하가 적다
단점 : 해시테이블 외 추가적인 저장공간이 필요하며, 삽입/삭제시 오버헤드가 발생한다
1.4.2) 충돌 해결 방안 2 - 개방주소법
- 개방주소법
해시 충돌이 발생하면, 다른 빈 공간에 데이터를 삽입하는 방식
해시 충돌시 선형탐색, 제곱탐색, 이중해시 등을 통해 다른 빈 공간을 선정
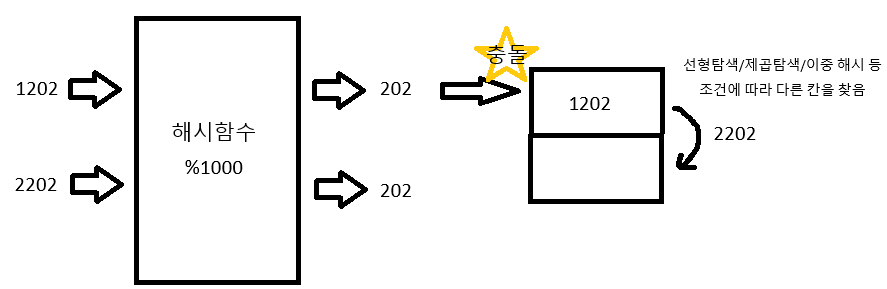
- 선형탐색 : 키 값에 인접한 칸 순서로 이동하며 빈 칸이 나올 때까지 탐색
- 제곱탐색 : 키 값에 제곱수를 곱한 수만큼 이동하며 빈 칸이 나올 때까지 탐색
- 이중해시 : 키 값 변환을 위한 함수가 있고(해시함수), 키 값이 충돌했을 때의 함수가 따로 있어, 해당 함수에 따라 계산한 빈칸으로 이동
장점 : 추가적인 저장공간이 필요하지 않음, 삽입/삭제시 오버헤드가 적음
단점 : 해시테이블에 자료사용률에 따른 성능저하 발생 (여유공간이 적어질 때 체이닝 보다 느려짐)
1.5 해시테이블의 효율
| 접근 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|
| X | O(1) | O(1) | O(1) |
*해시테이블은 접근 용도로 사용되는 것보다는, 탐색을 위한 알고리즘의 성격이 강하다.
해시테이블은 탐색을 위해 특화된 알고리즘이라 할 수 있다. 다만, 아래와 같은 한계가 있다.
해시테이블의 공간 사용률이 높을 경우( 통계적으로 70% 이상 ) 급격한 성능저하가 발생한다.
이런 경우 재해싱을 통해 공간 사용률을 낮추어 다시 효율을 확보한다.
재해싱: 해시테이블의 크기를 늘리고 테이블 내의 모든 데이터를 다시 해싱하여 보관
또한 유의해야 할 점이 있는데, 삽입과 삭제의 시간 효율이 좋은 것으로 나타나지만 빈번히 쓰는 건 피해야 한다는 것이다. 빈번하게 삽입하거나 삭제할 경우 아래와 같은 문제가 발생한다.
- 빈번하게 삽입할 경우
-체이닝의 경우 연결리스트의 정보가 쌓이게 되면서 탐색 속도가 저하됨, 저장 공간 손실이 심해짐
-개방주소법의 경우 정보가 쌓이면서 계속 다른 칸으로 이동하기 때문에, 탐색 속도가 저하됨
- 빈번하게 삭제할 경우
-(두 경우 모두 해당) 해시테이블에서 데이터를 삭제한다는 것은 생각보다 리스크가 크다. 왜냐하면 데이터를 삭제하고 그 칸을 다시 쓸 수 있는 것이 아니라, 데이터를 제거한 해당 칸을 아예 못 쓰는 칸으로 취급하기 때문이다. 따라서 삽입과 삭제가 빈번히 일어날 경우 사용할 수 없는 공간이 늘어나게 된다.
이와 같은 점에 유의하며 사용해야 할 것이다.
2. 딕셔너리(Dictionary)
2.1 딕셔너리란?
앞서 설명한 해시테이블의 제네릭 컬랙션(C# 언어 구현체)이다.
선언 방법은 아래와 같다.
Dictionary<Key데이터형, Value데이터형> 오브젝트명 = new Dictionary<Key데이터형, Value데이터형>();2.2 딕셔너리 사용 예시
포켓몬스터의 정보를 담는 구조체를 만들고, 포켓몬 데이터를 입력하는 딕셔너리를 만들었다.
public class Monster
{
public string name;
public int id;
public Monster(string name, int id)
{
this.name = name;
this.id = id;
}
}
static void Main(string[] args)
{
// 추가: O(1)
Dictionary<string, Monster> monsterDic = new Dictionary<string, Monster>();
monsterDic.Add("피카츄", new Monster("피카츄", 1));
monsterDic.Add("파이리", new Monster("파이리", 2));
monsterDic.Add("꼬부기", new Monster("꼬부기", 3));
monsterDic.Add("이상해씨", new Monster("이상해씨", 4));
// monsterDic.Add("피카츄", new Monster("다른몬스터", 5)); error : 동일 키의 데이터를 중복 불가
monsterDic.TryAdd("라이츄", new Monster("라이츄", 5));
// 삭제 : O(1)
monsterDic.Remove("피카츄");
// 탐색 : O(1)
monsterDic.ContainsKey("파이리");
monsterDic.TryGetValue("파이리", out Monster monster);
// 인덱서를 통한 간략한 사용 - 위에가 정석 문법이나 간략하게 아래처럼 사용할 수 있음
Monster find = monsterDic["파이리"]; // 키가 없으면 오류가 나므로 불확실할 때는 사용하지 말 것
monsterDic["피카츄"] = new Monster("피카츄", 3); // 원래 없었으면 추가, 원래 있었으면 변경됨
}3. 그래프와 트리
3.1 트리(Tree)
트리는 엄연히 따지면 그래프의 종류 중 하나이다. 계층적인 자료를 나타내는데 자주 사용되는 자료 구조로, 부모 노드가 여러 자식 노드들을 가질 수 있는 1 대 다 구조이다. 순환할 수 있는 구조인 그래프에 비해, 순환 구조를 가지지 않는다.
트리의 구성
- 부모(Parent) : 루트 노드 방향으로 직접 연결된 노드
- 자식(Child) : 루트 노드 반대방향으로 직접 연결된 노드
- 뿌리(root) : 부모노드가 없는 최상위 노드, 트리의 깊이 0에 하나만 존재
- 가지(Branch) : 부모노드와 자식노드가 모두 있는 노드, 트리의 중간에 존재
- 잎(Leaf) : 자식노드가 없는 노드, 트리의 끝에 존재
- 길이(Length) : 출발 노드에서 도착 노드까지 거치는 수
- 깊이(Depth) : 루트 노드부터의 길이
- 차수(Degree) : 자식노드의 갯수
- 트리 사용처
주로 계층구조를 가질 수 있는 자료나 효율적인 검색에 많이 사용된다.
ex) 윈도우의 폴더 구조, 문서의 목차, 데이터 베이스 & 검색 엔진의 구조,
상위스킬을 배워야 하위스킬을 배울 수 있는 스킬트리
- 트리 구현
노드를 기반으로 부모 노드와 자식 노드들을 보관할 수 있도록 구성한다.
자식 노드들의 최대 갯수가 정해져 있는 경우 배열로, 정해지지 않은 경우 리스트로 구현한다.
3.2 그래프
정점(노드)과, 정점들을 잇는 간선의 결합을 말한다.
한 노드에서 출발하여 다시 자기 자신의 노드로 돌아오는 순환구조를 가진다.
그래프의 종류
간선의 방향성에 따라 단방향 그래프, 양방향 그래프가 있다
간선의 가중치 유무에 따라 따라 연결 그래프, 가중치 그래프가 있다.
아래와 같이 그래프를 구현할 수 있다.
public class GraphNode<T>
{
private T vertex;
public T Vertex { get { return vertex; } set { vertex = value; } }
private List<GraphNode<T>> edges = new List<GraphNode<T>>();
public GraphNode(T vertex)
{
this.vertex = vertex
}
public void AddEdge(GraphNode<T> node)
{
edges.Add(node);
}
public void RemoveEdge(GraphNode<T> node)
{
edges.Remove(node);
}
public bool IsConnect(GraphNode<T> node)
{
return edges.Contains(node);
}
}
internal class Program
{
static void Main(string[] args)
{
GraphNode<int> node0 = new GraphNode<int>(0);
GraphNode<int> node1 = new GraphNode<int>(1);
GraphNode<int> node2 = new GraphNode<int>(2);
GraphNode<int> node3 = new GraphNode<int>(3);
GraphNode<int> node4 = new GraphNode<int>(4);
GraphNode<int> node5 = new GraphNode<int>(5);
GraphNode<int> node6 = new GraphNode<int>(6);
GraphNode<int> node7 = new GraphNode<int>(7);
node0.AddEdge(node3);
node3.AddEdge(node0);
node7.AddEdge(node4);
node4.AddEdge(node0);
}
}3.3 그래프를 간단하게 표현하기 - 인접행렬 그래프, 인접 리스트 그래프
3.3.1 인접행렬 그래프
인접행렬 그래프는 그래프 내의 각 정점의 인접 관계를 나타내는 행렬을 말한다.
2차원 배열을 [출발정점, 도착정점] 으로 표현하는 방식이다.
- 예시 1 - 양방향 연걸 그래프
// 예시 - 양방향 연결 그래프
bool[,] matrixGraph1 = new bool[5, 5]
{
{ false, false, false, false, true },
{ false, false, true, false, false },
{ true, true, false , true, false },
{ false, false, true, false, true },
{ true, false, false, true, false }
};
// [0, 2] => 출발정점(0) -> 도착정점(2)
bool connect = matrixGraph1[0, 2]; // 연결 여부 확인
matrixGraph1[0, 2] = true; // 연결 추가
matrixGraph1[0, 2] = false; // 연결 해제- 예시 2 - 단방향 가중치 그래프
const int INF = int.MaxValue;
// 예시 - 단방향 가중치 그래프 (단절은 최대값으로 표현)
int[,] matrixGraph2 = new int[5, 5]
{
{ 0, 132, INF, INF, 16 },
{ 12, 0, INF, INF, INF },
{ INF, 38, 0, INF, INF },
{ INF, 12, INF, 0, 54 },
{ INF, INF, INF, INF, 0 },
};
// [0, 2] => 출발정점(0) -> 도착정점(2)
matrixGraph2[0, 2] = 10; // 가중치 변경
matrixGraph2[0, 2] = INF; // 연결 해제이와 같이 작성했을 때의 장단점은 아래와 같다.
장점: 인접 여부 접근이 빠르다, 관계를 체계적으로 구현 가능하다
단점: 코드량이 많아진다(메모리 사용량이 상승)
3.3.2 인접리스트 그래프
인접리스트 그래프 그래프 내의 각 정점의 인접 관계를 표현하는 리스트이다. 인접한 간선만을 리스트에 추가하여 관리하는 방식이다.
- 예시
List<int>[] listGraph = new List<int>[5];
listGraph[0] = new List<int>() { 2, 4 };
listGraph[1] = new List<int>() { 2, 3 };
listGraph[2] = new List<int>() { 0, 1, 4 };
listGraph[3] = new List<int>() { 1, 7 };
listGraph[4] = new List<int>() { 0, 2 };
listGraph[5] = new List<int>() { 6, 7 };
listGraph[6] = new List<int>() { 5, 7 };
listGraph[7] = new List<int>() { 3, 5, 6 };
// 연결 추가
listGraph[0].Add(5);
listGraph[5].Add(0);
// 연결 해제
listGraph[1].Remove(2);
listGraph[2].Remove(1);
// 연결 여부 확인
bool connect3 = listGraph[0].Contains(1);이와 같이 작성했을 때의 장단점은 아래와 같다.
장점 : 메모리 사용량이 적다. (절약 가능)
단점 : 인접여부를 확인하기 위해 리스트 탐색이 필요하다. 속도가 상대적으로 느리다.
