0. 갑자기 왜 컴퓨터 구조 공부?
우연찮게 아는 수강생을 통해서 인프런에 있는 강의에 대해 듣게 되었고, 이와 같은 강의와 혜택이 있단 걸 듣게 되었다.

해당 강의 자체는 무료인데, 강의를 수강하지 않고도 전자책을 받을 수 있고, 거기에 강의를 수강하고 나서 인증한 채로 다른 유료 강의를 1000원에 살 수 있는 혜택까지 제공하고 있었다.
강의 퀄리티가 어떨진 몰라도, 해당 내용을 공부해 보는 것은 좋아 보이고 밑져야 본전이라고, 컴퓨터 구조에 대한 공부를 좀 해보기로 했다.
1. 강의 개요

컴퓨터의 구조에 관해서 기본기를 다질 수 있는 내용으로 보였다. 또한 강의 내용이 간결하고 괜찮게 정리되어 있는 것으로 보였다.
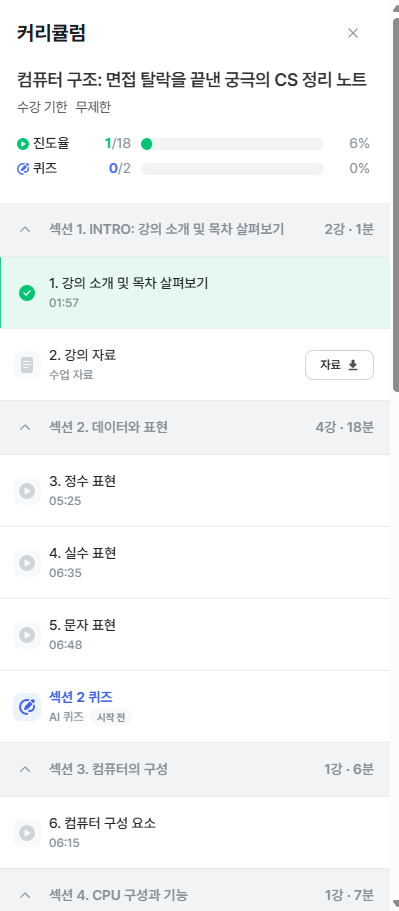
부담 없이 각 섹션이 5 ~ 6분 분량으로 정리되어 있는 것으로 보인다. 이 정도면 가볍게 들으면서 공부해 볼 만하다는 느낌을 받았다.
또한 강의자료가 제공되는데, 사실 내용은 별 거 없고 강의에서 쓰이는 PPT 자료를 그대로 PDF로 제공해주는 것으로 보인다.
2. 데이터와 표현
2.1 비트와 바이트
컴퓨터는 10진법이 아닌 2진법을 사용해 정보를 저장한다. 따라서 0과 1만을 저장하여 데이터를 표현한다.
- 비트 : 0과 1을 표현할 수 있는 최소 단위
- 바이트 : 8비트를 한 묶음으로 표현한 단위, 즉 1바이트 당 256(=2^8)가지의 데이터 표현이 가능하다.
또한 바이트를 더 큰 단위로 묶어 1KB, 1MB, 1GB, 1TB 등으로 표현이 가능하다.
2.2 컴퓨터의 숫자 표현
1. 정수
컴퓨터에서의 정수 표현은 다음과 같이 표현된다.
- 정수에는 양수와 음수가 있으며, 양수와 음수의 여부를 결정하는 방식은 다음과 같다.
- 음수는 n비트에서 가장 왼쪽의 비트(최상위 비트)에서 표현된다.
- 양수 혹은 0일 경우 0, 음수일 경우 1로 표현된다.
정수의 경우에 2진법을 10진법으로 계산하는 방식이니 그리 어려운 내용은 없을 것이다.
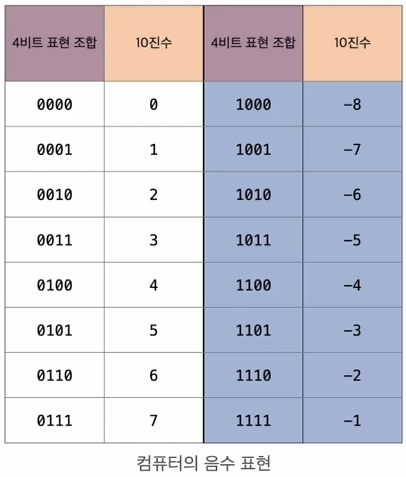
다만 여기서 음수의 계산 방식이 왜 저렇게 나오는지 의문이 생길 수 있을 것이다.
여기서, 2의 보수라는 개념이 나온다.
- 음수를 저장하기 위해서는 다음과 같은 과정을 거친다.
아래와 같은 과정으로 컴퓨터에서의 음수가 표현되며, 이 과정을 2의 보수라고 한다.
- 특정 정수를 표현하는 표현이 있을 때, 해당 비트를 반전시킨다.
- 위의 결과값에 대해 1을 더한다.
이에 대한 예시로 3이란 정수의 음수 값을 표시할 때, 아래와 같은 과정으로 변환된다.

이와 같은 방식으로 n개의 비트로 표현할 수 있는 정수 범위는 -2^(n-1) ~ 2(n-1) - 1까지이다.
2. 실수
컴퓨터에서의 실수 표현은 다음과 같이 표현된다.
- 실수를 표현하기 위해서는 부동소수점이란 개념이 활용된다.
부동 소수점은 32비트 기준으로 가장 최상위 비트를 부호비트로 사용하고, 나머지 31개 비트를 지수필드와 가수 필드로 분리한다.
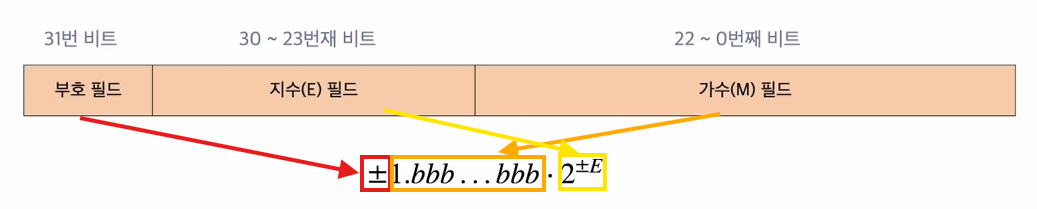
-
지수 필드(E) 는 값의 볌위를 나타나는 2의 거듭제곱 수를 저장한다.
23 ~ 30번째 비트를 사용하고 256개의 표현이 가능하다. -
가수 필드(M) 는 정밀도를 나타내기 위해 실제 숫자의 유효한 자릿수를 저장한다.
0 ~ 22번째 비트를 사용하며 2^23개의 표현이 가능하다.
해당 비트에는 마찬가지로 0과 1만 들어갈 수 있다.
- 실수를 계산하는 방법은 다음과 같다.
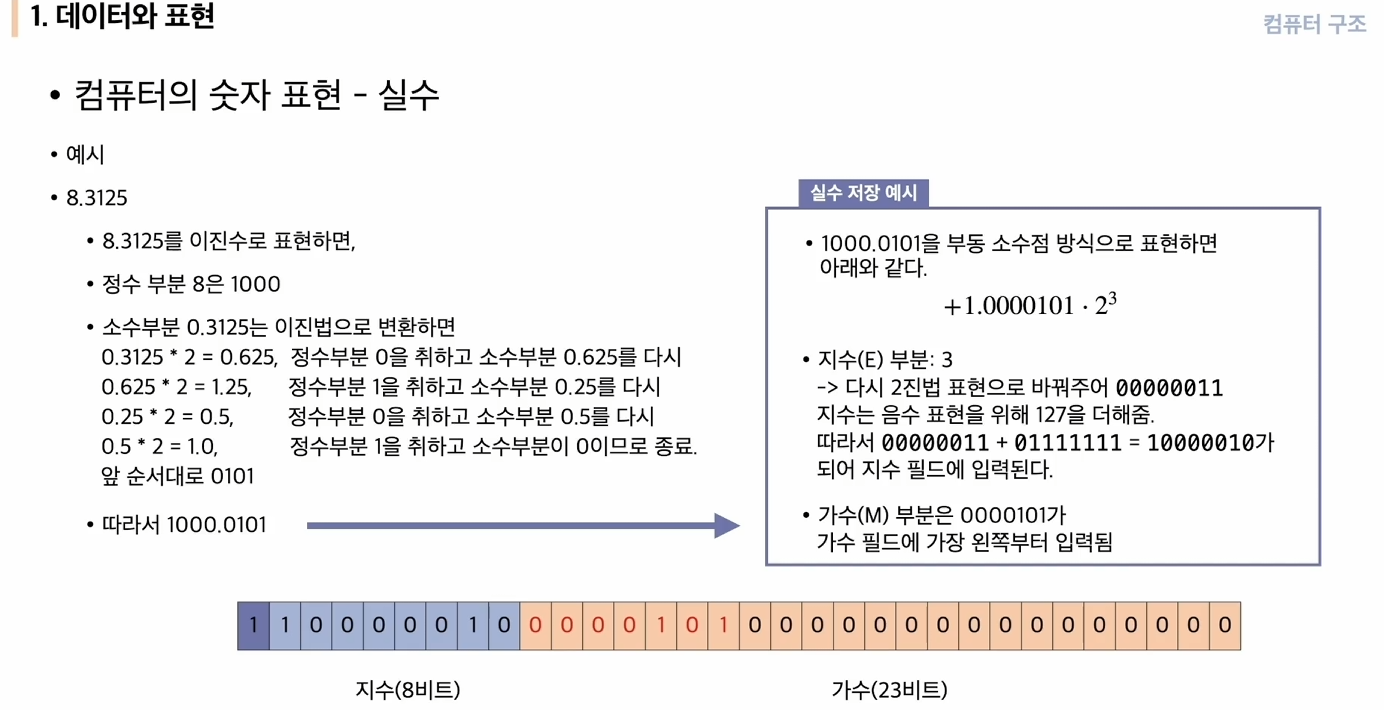
(해당 자료의 결론의 맨 앞 자리 수가 1인 것은 오타로 보인다. 해당 부분에 대해 문의를 했더니 오타가 맞다고 확인되어서 수정하겠다는 답변을 받았다.)
정수부분은 2진법 정수 계산 방식처럼 간단하게 계산하면 되고, 소수점 부분의 계산은 이와 같이 계산된다.
- 소수점 부분만 놓고 다음과 같이 계산을 반복한다.
해당 소수점에 2를 계속해서 곱하고, 맨 첫 자리 수를 저장한다.
맨 첫 자리 수가 0일 때는 0을 저장하고, 1일 때는 1을 저장하여, 소수점 자리수가 0이 될 때까지 해당 작업을 반복한다.
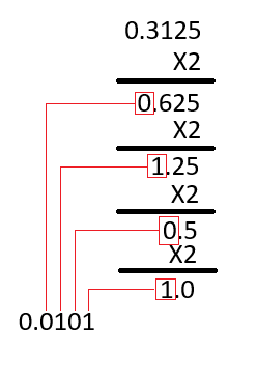
따라서 8.3125라는 숫자를 정수부와 소수부를 2진수로 전환했을 때 1차적으로 1000.0101이 된다는 것을 알 수 있다.
여기서 부동소수점을 저장하는 방식은 (+-) (1.M) * 2^(e-127) 이다.
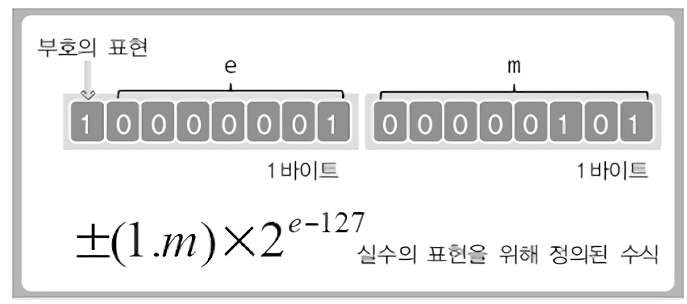
따라서 처음 계산했던 1000.0101이라는 소수를 이에 맞춰 계산해야 하므로, 소수점 앞으로 3자리를 당겨야 한다.
따라서 8.3125 = +1.0000101 * 2^(3 - 127) 으로 계산되며, 이 (3 - 127) 부분이 지수 부분에 저장되며 00000011 + 01111111 = 10000010이 된다.
따라서 최종적으로 저장되는 숫자는 01000001000001010000000000000000 이 된다.
이에 따라 왜 float 등의 수를 사용할 때 소수점 등에서 오차가 발생하는지 확인할 수 있다.
3. 문자
컴퓨터에서의 문자 표현은 다음과 같이 표현된다.
3.1 아스키 코드
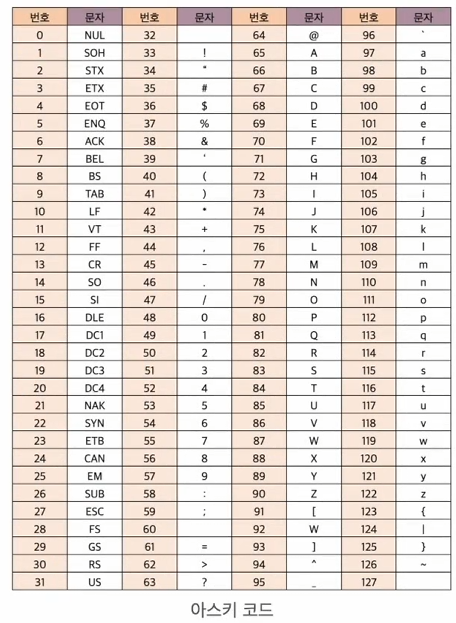
128개의 문자 조합을 제공하는 7비트 부호이다.
이때 오류 검출을 위한 패리티 부호에 해당하는 1비트를 포함하여 총 8비트로 구성한다.
패리티 부호를 이용한 오류 검사의 경우 다음과 같이 이루어진다.
-
7자리 비트로 다음과 같은 문자가 있다고 하자.
1010001
이때, 해당 문자의 오류 여부를 판별하기 위해 해당 비트 내의 1의 숫자를 짝수 개로 유지한다.
즉 지금의 숫자에서 1의 개수는 3개이므로, 맨 마지막에 1을 추가하여 1을 4개 - 짝수개로 만들어준다.
10100011 -
어떠한 이유로 인해 숫자 하나가 잘못 입력되었을 경우를 생각해보자.
10110011
이와 같이 데이터가 변조되었을 경우 1의 개수가 짝수 개가 아니므로, 데이터에 오류가 있다는 것을 감지할 수 있다.
다만 이와 같이 오류를 검사하는 경우에서의 한계점은, 짝수 개의 수가 변조되었을 경우 잡아낼 수 없다는 한계점이 있다.
- 문자 A를 숫자 65로 변환하는 것을 인코딩이라고 하며, 숫자 65를 해석하여 문자 A로 변환하는 것을 디코딩이라고 한다.
3.2 유니코드
아스키 코드는 미국의 표준이라 외국어를 표현하는 데 한계가 있었다. 따라서 전 사계 문자를 동일한 방법으로 표현하기 위해 1995년 유니코드가 국제 표준으로 제정되었다.
아스키 코드는 초기엔 16비트였으나 표현할 문자나 이모티콘이 많아져 지금은 21비트로 늘렸다.
- 유니코드의 표현 방법(16진법 기준)
유니코드는 비트를 4개씩 나눠서 16진법(4비트)으로 표현한다.

16진법을 사용하는 경우 맨 앞에 U+를 붙여서 표현한다
따라서 표현할 수 있는 범위는 U+0000 ~ U+10FFFF까지이므로 약 111만개의 문자를 표현할 수 있다.
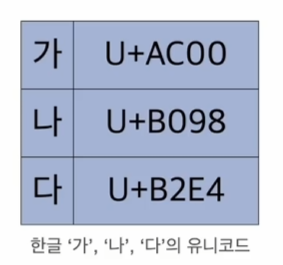
해당 사이트에 들어가면 한글의 유니코드를 확인할 수 있다.
https://www.unicode.org/charts/PDF/UAC00.pdf
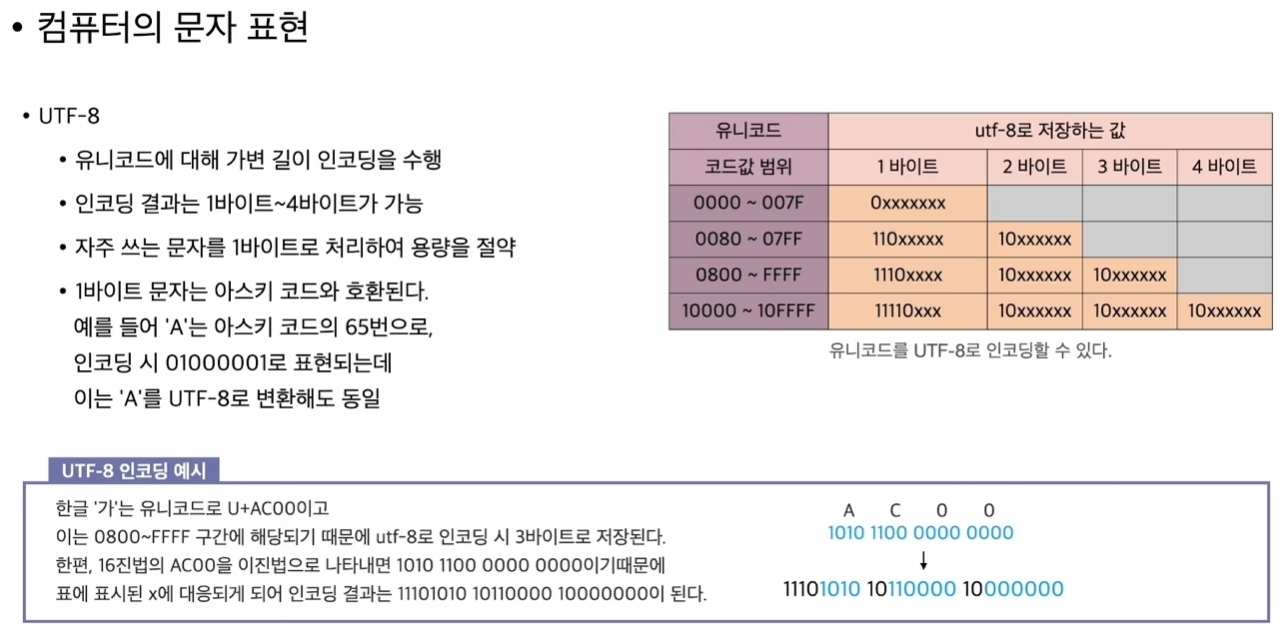
3.3 UTF-8
유니코드에 대해 가변 길이 인코딩을 수행하는 방법이다.
유니코드의 경우 16비트를 사용하는 방식이었으나, UTF-8로 인코딩하여 1바이트(4비트) ~ 4바이트(16비트) 크기의 데이터로 사용하는 방식인 것이다.
이에 따라 자주 쓰는 문자는 1바이트로 처리하여 용량을 절약할 수 있다.
또한 1바이트 문자는 아스키 코드와 호환된다는 특징도 가지고 있다.
3. 컴퓨터의 구성요소
컴퓨터의 구성요소는 크게 하드웨어와 소프트웨어로 나뉜다.
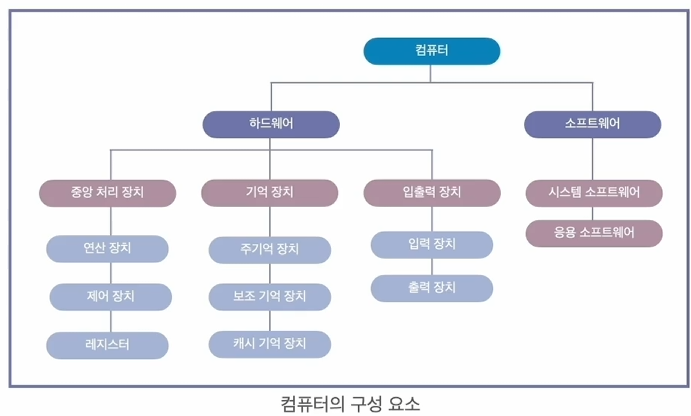
하드웨어는 컴퓨터의 물리적인 장치를 말하며, 프로세스, 메모리, I/O 장치 등이 있다,
소프트웨어는 하드웨어의 동작을 제어하는 프로그램으로 응용 소프트웨어와 시스템 소프트웨어 등으로 나뉜다.
- 응용 소프트웨어 : ex) 메모장, 인터넷
- 시스템 소프트웨어 : ex) 컴파일러, 운영체제
3.1 하드웨어
- 구성요소
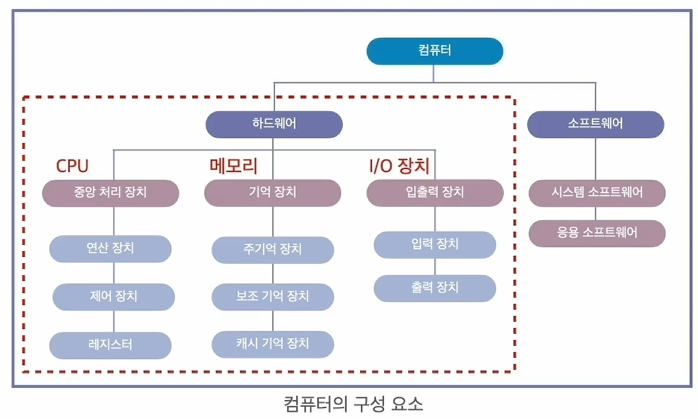
-
CPU : 메모리로부터 프로그램 명령과 데이터를 읽어와 명령을 처리하고 명령 실행순서를 제어하는 역할
-
메모리 : 주기억장치와 보조기억장치로 나뉜다.
- 주기억장치 : 실행 중인 프로그램의 데이터를 일시적으로 저장.
- 보조기억장치 : 데이터를 영구히 저장
-
입출력장치 : 키보드, 마웃, 모니터, 스피커 등 CPU와 사용자의 정보 교환을 위한 장치이다.
3.2 시스템 버스
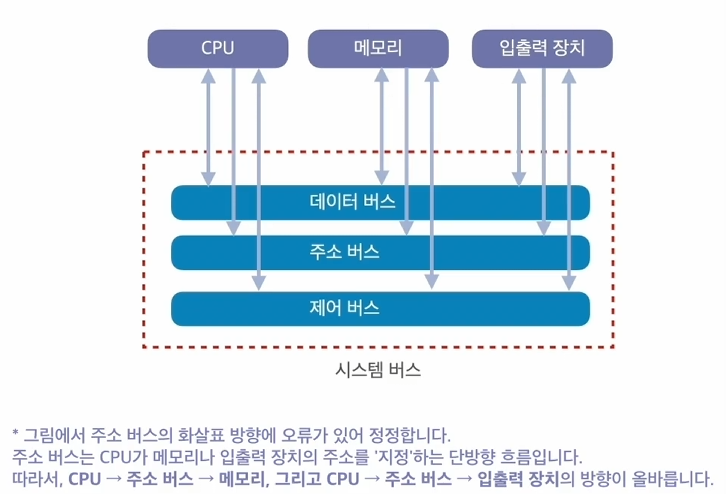
시스템 버스는 하드웨어 구성요소를 물리적으로 연결하는 선으로, 용도에 따라 데이터 버스, 주소 버스, 제어 버스로 나뉜다.
- 데이터 버스 : 중앙처리장치와 그 외 장치 사이에서 데이터를 전달하는 양방향 통로
- 주소 버스 : 데이터가 읽고 쓰여질 메모리 주소를 전달하는 단방향 통로
- 제어 버스 : 데이터 전송의 제어 신호를 전달하는 양방향 통로
ex) 데이터 읽기의 과정
1) 주소 버스 - 주소 전달
CPU는 메모리에서 특정 데이터를 읽기 위해 주소 버스를 통해 읽고자 하는 데이터의 메모리 주소를 전달한다.
2) 제어 버스 - 제어 신호 전달
CPU는 동시에 제어 버스를 통해 Read 신호를 메모리에 보낸다.
3) 데이터 버스 - 데이터 준비 및 응답
메모리는 주소 버스를 통해 전달받은 주소의 데이터를 확인하고 준비하며, 준비된 데이터는 데이터 버스를 통해 CPU로 전송된다.
4) 제어 버스 - 완료 신호
메모리는 데이터 준비가 완료되면 Ready 신호를 CPU로 보내고, CPU는 데이터 버스에서 데이터를 가져온다.
