소켓 인터페이스 💡
소켓 인터페이스는 함수들의 집합으로서, Unix I/O 함수들과 함께 네트워크 어플리케이션을 구축하는 데에 사용된다. 이는 Unix, 윈도우, 매킨토시와 같은 대부분의 현대 시스템에서 구현되어 있다.
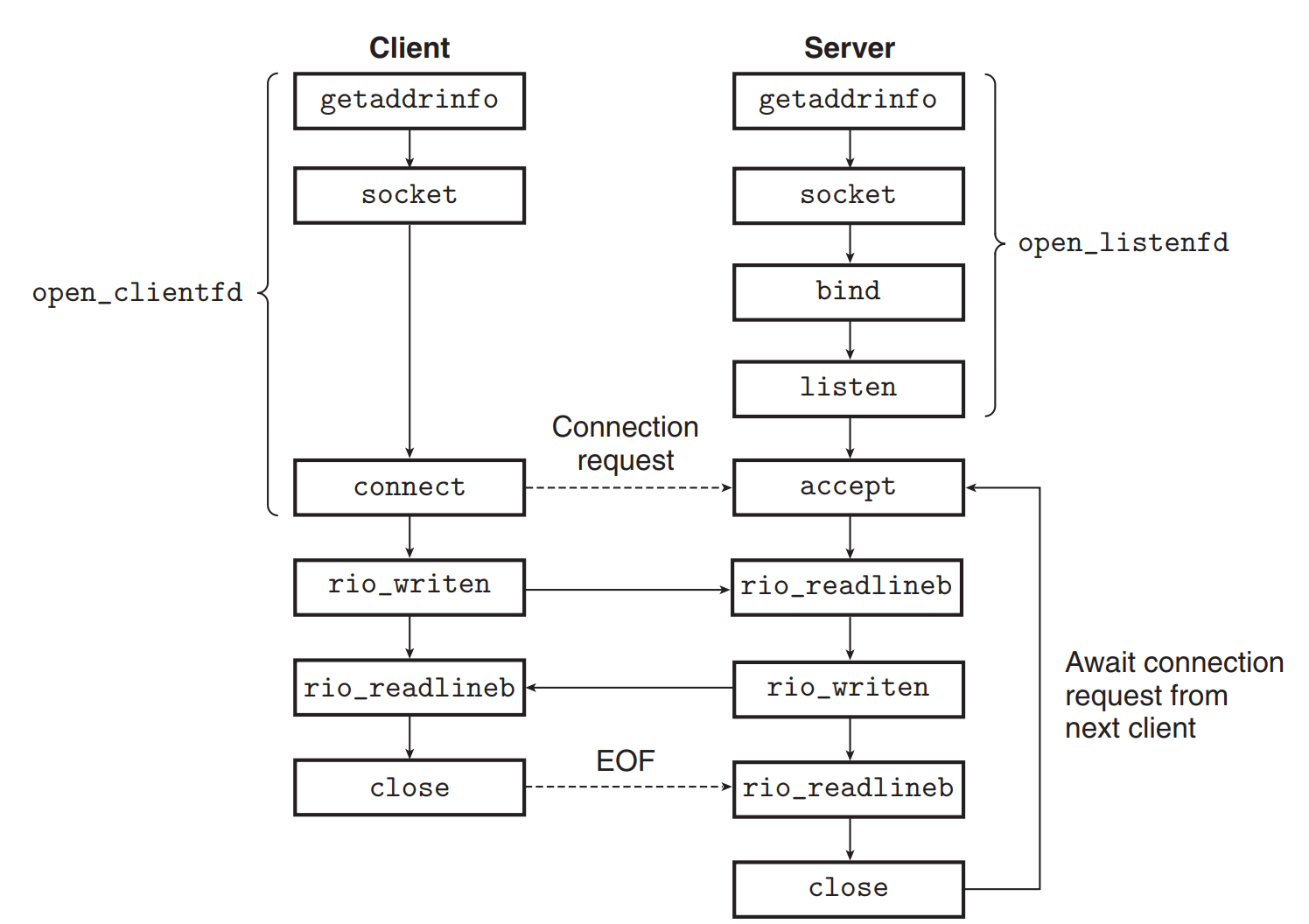
- 소켓 인터페이스를 기반으로 한 전형적인 네트워크 어플리케이션의 모습
소켓 주소 구조체

소켓 주소는 그림처럼 sockaddr_in 타입의 16바이트 구조체에 저장된다. (IPv4의 경우)
-
sin_family멤버는 어떤 유형의 주소가 사용되는지(주소 패밀리)를 나타낸다.AF_INET은 IPv4 주소 패밀리를 나타낸다. -
sin_port멤버는 16비트(2바이트) 포트 번호,sin_addr멤버는 32비트(4바이트) IP주소를 저장한다. 이 둘은 항상 네트워크 바이트 순서(빅 엔디안)로 저장된다. -
sin_zero멤버는 64비트(8바이트)의Padding필드로, 구조체의 크기를 일정하게 유지하기 위해 사용된다. 일반적으로는 0으로 설정!
이후 다룰 connect, bind, accept 함수는 위와 같은 소켓 주소 구조체를 가리키는 포인터를 필요로 한다. 오늘날 C에서는 void *를 통해 해결하면 되겠지만, 이런 소켓 함수를 디자인했던 시절에는 존재하지 않았다. 설계자들은 이를 sockaddr 구조체를 이용하여 해결했다.
웹 서버 📫
웹 기초
웹 클라이언트와 서버는 HTTP(HyperText Transfer Protocol) 라고 하는 텍스트 기반 어플리케이션 레벨 프로토콜을 이용해 상호작용한다. 웹 클라이언트(브라우저)는 서버로의 인터넷 연결 후, 컨텐츠를 요청한다. 서버는 요청한 컨텐츠로 응답하고, 그 후 연결을 닫아준다. 웹 클라이언트는 수신한 컨텐츠를 읽고 이것을 스크린에 보여준다.
이러한 웹 서비스와 전통적인 파일 전송 서비스(ex.FTP)와는 어떤 차이점이 있을까? 주요 차이점은 웹 컨텐츠는 HTML(HyperText Markup Language) 이라는 언어로 작성될 수 있다는 것! HTML 프로그램(페이지)은 명령들(태그)을 포함하고 있어서 브라우저에게 여러 가지 텍스트와 그래픽 객체들을 페이지에 어떻게 표시할지 알려준다.
웹 컨텐츠
웹 서버는 두 가지 서로 다른 방법으로 클라이언트에게 컨텐츠를 제공한다.
-
디스크 파일을 가져와서 그 내용을 클라이언트에게 보낸다.
-
실행파일을 돌리고, 그 출력을 클라이언트에게 보낸다.
웹 서버가 리턴하는 모든 내용들은 서버가 관리하는 파일에 연관된다. 이러한 파일들은 URL(Universal Resource Locator) 라고 하는 고유의 이름을 가진다. 예를 들면,
http://www.google.com:80/index.html와 같은 URL은 포트 80에서 listening하고 있는 웹 서버가 관리하는 인터넷 호스트 www.google.com의 /index.html이라는 HTML 파일을 확인한다. 포트번호는 필수가 아닌 옵션이고, 잘 알려진 HTTP 포트 80이 기본값이다.
실행 파일을 위한 URL은 파일 이름 뒤에 프로그램의 인자를 포함할 수도 있는데, ?문자는 파일 이름과 인자를 구분하며, 각 인자는 &로 구분된다. 예를 들면,
http://bluefish.ics.cs.cmu.edu:8000/cgi-bin/adder?15000&213와 같은 URL은 /cgi-bin/adder라는 실행파일을 확인하고, 이 파일은 두 개의 인자(15000, 213)와 함께 호출된다.
클라이언트와 서버는 트랜잭션(일련의 연관된 작업들을 하나의 논리적인 단위로 묶은 것)동안에 URL의 서로 다른 부분을 사용한다.
-
클라이언트는 다음과 같이 접두어를 사용해서
http://www.google.com:80어떤 종류의 서버에 접속해야 하는지 결정하고, 어디에 서버가 있는지, 서버가 무슨 포트를 듣고 있는지를 결정한다. -
서버는 다음과 같은 접미어를 사용해서
/index.html자신의 파일 시스템 상의 파일을 검색하고, 이 요청이 정적 또는 동적 컨텐츠에 대한 것인지 결정한다.
추가적으로 서버가 어떻게 URL의 접미어를 해석하는지에 대해서 이해해야 할 몇 가지가 있다.
-
URL이 정적 또는 동적 컨텐츠를 참조하는지를 결정하기 위한 표준 규칙은 없다. 각각의 서버는 자신이 관리하는 파일들을 위한 자신만의 규칙들을 가진다. -
접미어 앞 부분의
/는 리눅스의 루트 디렉토리를 나타내는 것은 아니다. 오히려 어떤 종류의 컨첸츠가 요청되든 간에 홈 디렉토리를 나타낸다. -
최소한의
URL은/문자이며, 모든 서버는 이것을/index.html같은 특정 기본 홈페이지로 확장해서 해석한다. 이러한 특성 덕에 우리는 도메인 이름만 입력하고도 어떤 사이트의 홈페이지에 접근할 수 있는 것! 브라우저는 빠져 있는/를 추가해주고 서버에 전달하고, 서버는/를 이를 위처럼 확장해서 읽어들이는 것.
아무 생각 없이 한평생 사용해왔던 URL에 대해 이러한 규칙이 존재하고, 편의를 위해 이러한 기능들이 존재했다는 걸 공부하니 참으로 신기하고 재밌구만 😎
HTTP 트랜잭션
HTTP가 인터넷 연결 위에서 전송된 텍스트들에 기반하고 있기 때문에, 리눅스 TELNET과 같은 프로그램을 사용해서 인터넷 상의 모든 웹 서버와 트랜잭션을 실행할 수 있다.
- 정적 컨텐츠를 제공하는 HTTP 트랜잭션의 예시
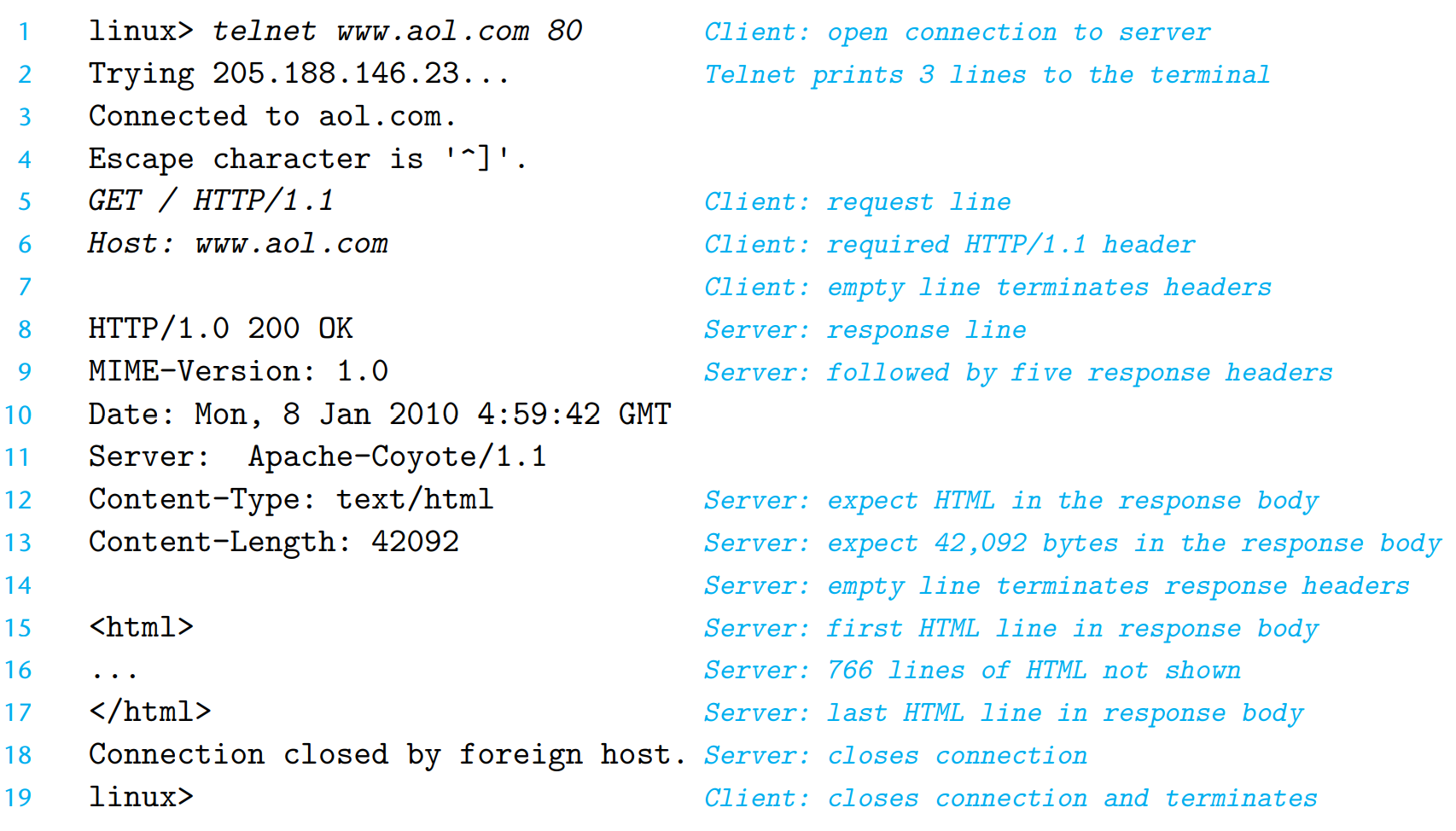
HTTP 요청은 요청 라인과 따라 나오는 여러 개의 요청 헤더, 헤더 리스트들을 종료하는 빈 텍스트 줄이 따라온다. (Line 5~7)
method URI(L이 아님!) version요청 라인은 위와 같은 형태를 지닌다. HTTP는 많은 서로 다른 method를 지원하며, 거기에는 GET, POST, OPTIONS, HEAD, PUT, DELETE, TRACE 등이 포함되어 있다. 이 책에서는 가장 대표적이고, 가장 많이 사용되는 GET만을 다룬다고 하네~
GET 메소드는 서버에게 URI(Uniform Resource Identifer)에 의해 식별되는 내용을 리턴할 것을 지시하는데, 여기서 URI는 파일 이름과 옵션인 인자들을 포함하는 URL의 접미어다.
HTTP 응답은 HTTP 요청과 비슷하다. HTTP 응답은 응답 라인, 그 다음에 오는 요청 헤더들, 헤더를 종료하는 빈 줄이 따라오고, 응답 본체가 따라온다. (Line 8~17)
version status-code status-message응답 라인은 위와 같은 형태를 지닌다. version 필드는 요청이 준수하는 HTTP 버전을 나타낸다. status-code는 3비트 양수로, 요청의 특성을 나타내고, status-code는 에러 코드를 영어로 나타낸 것이다.
동적 컨텐츠의 처리
정적 컨텐츠에 대해서는 알겠고, 그렇다면 서버는 동적 컨텐츠를 어떻게 제공하는 것일까? 클라이언트는 어떻게 프로그램의 인자를 서버에 전달하고, 서버는 어떻게 수신한 인자들을 자신이 만든 자식 프로세스들에게 넘겨주는 걸까? 이러한 질문들은 CGI(Common Gateway Interface) 라고 부르는 표준 인터페이스로 설명할 수 있다.
서버가 GET /cgi-bin/adder?15000&213 HTTP/1.1와 같은 요청을 받은 후에, fork를 호출해서 자식 프로세스를 생성하고, execve를 호출해서 /cgi-bin/adder 프로그램을 자신의 컨텍스트에서 실행한다.
이후, 웹 서버는 CGI 프로그램의 반환 결과를 클라이언트에게 전달하여 응답한다.
