concurrency control 4 : 동시성 제어 기법 Locking, 2PL, MVCC
0. reference
https://youtu.be/0PScmeO3Fig
https://youtu.be/wiVvVanI3p4
https://youtu.be/-kJ3fxqFmqA
https://m.blog.naver.com/hw5773/220674740623
https://sabarada.tistory.com/121
https://velog.io/@znftm97/MySQL-MVCC%EB%9E%80
https://willbfine.tistory.com/578?category=1044057
https://youngminz.netlify.app/posts/data-intensive-application-transaction
https://blog.naver.com/PostView.naver?blogId=sdug12051205&logNo=221575076036&categoryNo=44&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView
https://bubble-dev.tistory.com/entry/DB-Serializablilty
https://bubble-dev.tistory.com/entry/DB-%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%A0%9C%EC%96%B4
https://slideplayer.com/slide/16145398/
https://www.datio.com/architecture/choosing-a-rdb-for-a-data-platform-a-journey-towards-postgresql-part-i/
1. abstract
concurrency control의 실제 구현은 lock에 기반했었다. 모든 자원에는 lock이 있고, 쓰거나 읽기 위해선 lock을 취득해야 하며, lock의 공유를 금지함으로써 자원의 동시 접근을 막는 것이다.
하지만 단순히 lock을 걸고 푸는 것으로는 serializability를 보장할 수 없기에 lock과 unlock의 순서에 조건을 걸어 serializable한 2PL을 사용하고, 추가적으로 recoverability와 deadlock의 해결을 위해 순서 조건을 추가한 SS2PL, S2PL을 썼다.
하지만, locking에서 발생하는 경합의 4가지 경우 중 쓰기-읽기나 쓰기-쓰기, 읽기-쓰기가 잇따라 일어나는 세 경우에서 lock 취득을 위한 실행 지연이 발생한다. 따라서 자원의 읽기 시 lock 취득을 해야한다는 조건을 없애고(쓰기-읽기, 읽기-쓰기 경합 제거), 그에 따라 발생하는 inconsistency는 mvcc라는 기법으로 해결한다는 것이다. 쓰기에서 lock 취득을 없애고 locking 기법을 완전히 mvcc로 대체할 수도 있지만, mvcc의 오버헤드로 인해서 최신 DBMS는 읽기-쓰기 경합까지만 mvcc로 대체하는 듯 하다.
내가 헷갈렸던 부분에 대한 추가 설명이다.
락은 데이터를 잠그는 것이 아니다. 반드시 쓰기 시에는 공유락을 취득해야 하고 읽기 시에는 배타락을 취득해야 함을 전제로 하고, 특히 배타락은 lock의 공유를 막아서 마치 데이터가 잠기는 것처럼 작동하게 하는 것이다. 락 기반 동시성 제어에서는 읽기 시에도 락을 취득해야 하기에, 읽기-쓰기와 쓰기-읽기에서도 트랜잭션의 락 취득을 위한 대기가 발생하는 것이고, 최신의 lock과 mvcc를 혼용한 기법에서는 읽기 시 락을 취득할 필요가 없으니 쓰기-읽기(락 공유 안해줘도 락 필요 없어서 대기x), 읽기-쓰기(읽기에서 락을 취득하지 않으니까 쓰기 시 바로 락 취득 가능)에서 시간 지연이 발생하지 않는 것이다.
2. lock
트랜잭션이 인터리빙 방식으로 수행되는 경우 서로의 데이터에 영향을 끼칠 수 있다.(lost update 등) 그래서 다른 트랜잭션들이 처리 중인 데이터에 접근하는 것을 막기 위해 lock을 사용한다. lock의 개념은 다음과 같다.
- 트랜잭션이 데이터에 접근하기 위해선 lock이라는 것을 취득해야 한다.
(단, 읽기 쓰기 등 작업별로 lock을 얻어야 하는지 여부는 dbms에서 결정) - lock을 취득하고 작업을 수행한 뒤에 unlock을 하면 다른 트랜잭션에서 lock을 얻어 작업을 할 수 있다.
- 다른 트랜잭션에서 해당 데이터에 lock을 취득하려는데, 다른 트랜잭션에서 lock을 가지고 있으면 lock을 취득할 때까지(unlock) 대기해야 한다. 이런 원리로 접근을 막는 것이다.
물론 lock 종류마다 위 설명은 달라질 수 있다.
2.1. exclusive lock(배타락, write-lock)
- read / write(insert, modify, delete) 할 때 사용한다.
- 어떤 데이터에 대해 배타락을 취득하면 다른 트랜잭션은 해당 데이터의 공유락과 배타락 둘 다 획득할 수 없다.
(이게 무슨 말이냐면, 배타락을 얻으면 다른 트랜잭션에서 읽기 시 보통 공유락을 취득해야 하고 쓰기 시 배타락을 얻어야 하는데, 이미 배타락을 누가 쥐고 있으면, 공유락이나 배타락이나 다 취득 못하니까 write와 read가 막히는 것이다.) - 보통 쓰기 시 이 락을 쓰는 이유는 변경 작업에 누가 덮어쓰든, 중간에 읽든 둘 다 이상현상의 소지가 있으므로 다 막아야 하기 때문이다.
2.2. shared lock(공유락, read-lock)
- 주로 read 할 때 사용한다.
- 어떤 데이터에 대해 공유락을 취득하면 다른 트랜잭션은 해당 데이터의 공유락은 획득할 수 있으나, 배타락은 획득할 수 없다.
- 보통 읽기 시에는 변경이 없으니 누가 와서 쓰는것만 아니면 되니까 공유락을 쓰는 것이다.
2.3. lock 호환성 정리
read시에 shared lock을 획득하고, write시에 exclusive lock을 획득해야 한다 치면 호환성은 다음과 같다.
<read> <write>
<read> O X
<write> X X2.4. lock 활용 예제
t1: x를 20으로 바꾼다.
t2: x를 읽는다.
x = 10
s_lock(x)
e_lock(x)
read(x)=>10
commit
s_unlock(x) // 여기에서 대기중인 t1의 e_lock(x)이 실행
write(x=20)
commit
e_unlock(x)t1: x를 읽는다.
t2: x를 읽는다.
x = 10
s_lock(x)
s_lock(x)
read(x)=>10
read(x)=>10
commit
s_unlock(x)
commit
s_unlock(x)아래 예제는 lock을 쓰더라도 이상 현상이 발생하는 경우이다.
t1: x와 y의 합을 x에 저장한다.
t2: x와 y의 합을 y에 저장한다.
x = 100, y = 200
serial schedule의 결과는 다음과 같다.
t1 -> t2 : x = 300, y = 500
t2 -> t1 : x = 400, y = 300
s_lock(x)
read(x)=>100
s_unlock(x)
s_lock(y)
e_lock(y)
read(y)=>200
s_unlock(y)
read(y)=>200
write(y=300)
commit
e_unlock(y)
e_lock(x)
read(x)=>100
write(x=300)
commit
e_unlock(x)write skew 문제인 듯 하다? 6번째 줄을 보면 y를 읽고 있고, 관련된 x에 14번째 줄에서 쓰기를 하고 있다. 근데, 읽기 시 y는 t2에 의한 업데이트 전이고 쓰기 시 x는 t2에 의한 업데이트 후이기 때문이다. 지금까지 배타락을 e_lock이라 했는데, x_lock이 맞는 표현인 것 같다.
해당 문제를 해결하려면, 두 트랜잭션 모두 락 해제 전에 락을 취득하는 방식으로 수정하면 된다. 이를 2PL이라고 한다.
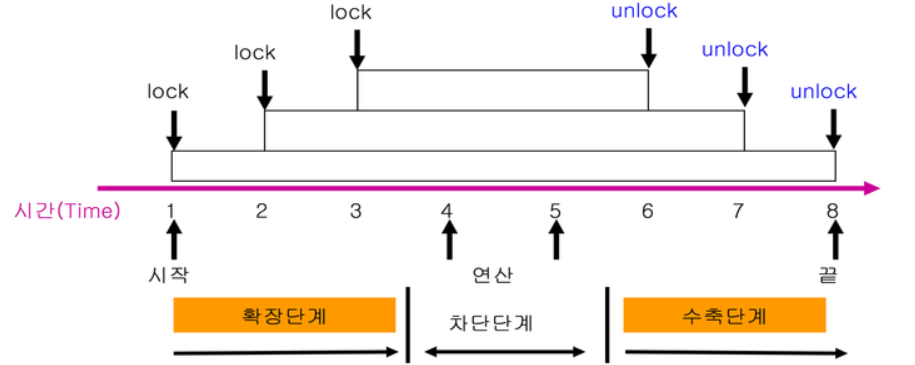
3. 2PL(two-phase locking)
2PL protocol이란 tx에서 모든 locking operation이 최초의 unlock operation보다 먼저 수행되도록 하는 것이다. 이를 활용하면 스케줄의 conflict serializable을 보장한다.
어떻게 보장하는지 알기 위해선 conflict serializable를 어떻게 판별하는지 알아야 한다.
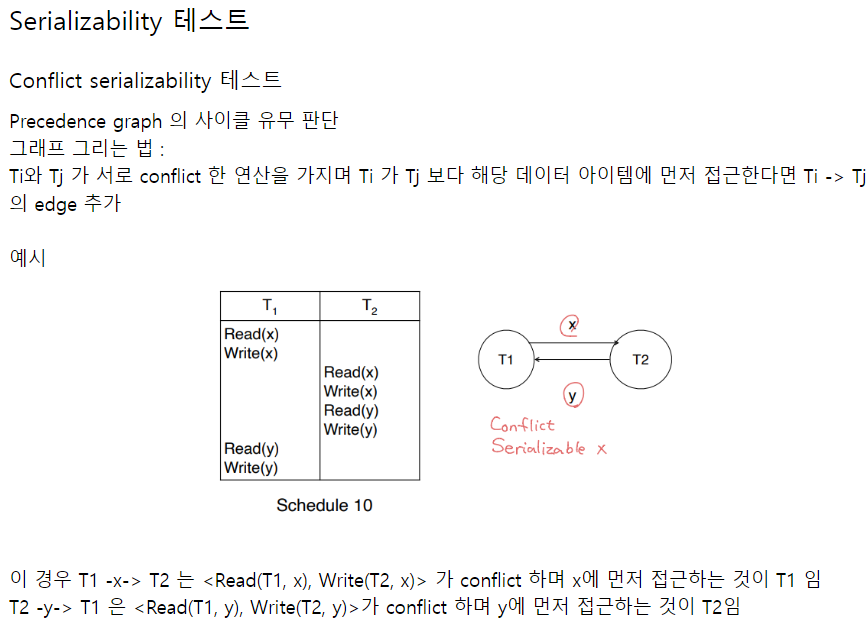
여기에서 사이클이 생긴다는 것이 갑자기 왜 나오나 싶을 텐데, 사이클은 conflict 연산 중 순서가 바뀐 것이 있다는 것을 말한다. conflict serializable이라면 한쪽으로만 화살표가 가야 하고, 사이클이 절대 생기지 않는다. 잘 생각해보면 너무 당연한 것이다.
이 사이클을 활용해서 2PL이 conflict serializable한지 증명할 수 있다.

중요한 것은 Ti -> Tj 일 때, ai < aj인 이유이다. 아래 사진을 보면 알 수 있는데,
Ti가 conflict 연산을 먼저 시작했으니(Ti -> Tj), Ti가 락을 모두 얻은 다음에(ai시점) unlock을 하게 된다.(Tj가 lock을 취득하기 시작) 그 이후에야 Tj가 락을 반환하게 된다.(aj시점) 시간을 정리하면 이런 식이다.
Ti 첫 번째 락 취득 < Ti 마지막 락 취득(ai)
< Tj 첫번째 락 취득(Ti 락 반환중) < Tj 마지막 락 취득(aj)
증명은 귀류법을 활용한다. 일단 2PL로 만들어진 스케줄이 conflict serializable 하지 않다고 가정한 뒤, 모순을 발견하여 2PL인데 non-conflict ... 한 스케줄은 존재하지 않음을 증명한다.
스케줄의 conflict serializable 하지 않다면, 사이클이 존재할 것이다. T1->T2->..->Ti->T1이라고 하자. 위에 정리한 바에 따라, 2PL이 적용된 Ti->Tj 이면 ai<aj이다. 따라서, a1<a2<ai<a1이고 a1<a1이다. 모순이 발생했으니, 2PL이면서 conflict serializable 하지 않은 스케줄을 존재하지 않는다.
물론 serializablity 장에서 설명했듯이, 2PL은 conflict operation 쌍만 순서가 유지되면 되는 것이고, 동시처리가 되지 않는 스케줄은 모든 operation 쌍에 대해 순서가 유지되어야 하는 것이므로 동시처리가 일부 가능해져 tx 처리량이 높아지게 된다.
예제로 트랜잭션 하나를 2PL을 적용해 바꾸어보자
t1: x와 y의 합을 x에 저장한다.
t2: x와 y의 합을 y에 저장한다.
x = 100, y = 200
serial schedule의 결과는 다음과 같다.
t1 -> t2 : x = 300, y = 500
t2 -> t1 : x = 400, y = 300
s_lock(x)
read(x)=>100
s_unlock(x)
s_lock(y)
x_lock(y)
read(y)=>200
s_unlock(y)
read(y)=>200
write(y=300)
commit
x_unlock(y)
x_lock(x)
read(x)=>100
write(x=300)
commit
x_unlock(x)2PL로 바꾸면
s_lock(x)
read(x)=>100
x_lock(y)
s_lock(y)
s_unlock(x)
read(y)=>200
write(y)=300
commit
x_unlock(y)
read(y)=>300
x_lock(x)
s_unlock(y)
read(x)=>100
write(x)=400
commit
x_unlock(x)근데 이거 순서 좀만 바꾸면 생기는 문제가 있다.
s_lock(x)
read(x)=>100
s_lock(y)
read(y)=>200
x_lock(y)
x_lock(x)
...
y에 대한 slock 반환까지 대기
...
x에 대한 slock 반환까지 대기데드락이다. 서로의 작업이 끝나기만을 기다리고 있다. 해결책은 OS에서 배운다고 하니 나중에 배우자!
이러한 2PL은 serializablity(conflict)를 보장하나, 데드락과 recoverablity는 모른다. 2PL에 제약을 추가해 보다 안전하게 돌리는 방법들이 있다.
3.1. conservative 2PL
conservative 2PL은 모든 lock을 취득한 뒤 tx를 시작한다. 데드락에 안전하지만 트랜잭션에서 필요한 락을 모두 얻을 때까지 기다려야 하는데(tx를 시작하기 위함) 그 상황이 잘 오지 않는 경우가 오면 별로 안 좋음
x_lock(y)
s_lock(x)
read(x)=>100
x_lock(x)
s_unlock(x)
s_lock(y)
read(y)=>200
write(y)=300
x_unlock(y)
commit
read(x)=>100
read(y)=>300
write(x=400)
x_unlock(x)
s_unlock(y)
commit
3.2. strict 2PL(S2PL)
S2PL은 2PL중에서도 x-lock을 commit/rollback 후에 반환하는 것을 말한다. S2PL은 conflict serializable 뿐만 아니라 strict schedule을 보장한다. 이전 장에서 봤듯이 recoverablity는 물론이고 cascading rollback까지도 막아준다.
strict schedule은 커밋되지 않은 변화에는 read도 write도 하지 않는 것이다. S2PL은 변화를 해제(x-lock의 해제)를 commit 이후로 고정함으로써, 어떤 트랜잭션도 commit되기 전에 write 혹은 read하는 것을 막는다.(commit 전에는 s-lock도 x-lock도 못얻음)
s_lock(x)
read(x)=>100
x_lock(y)
s_lock(y)
s_unlock(x)
read(y)=>200
write(y)=300
commit
x_unlock(y)
read(y)=>300
x_lock(x)
s_unlock(y)
read(x)=>100
write(x)=400
commit
x_unlock(x)3.3. strong strict 2PL(SS2PL, rigorous 2PL)
SS2PL은 2PL 중에서도 모든 unlock을 commit/rollback 이후에 수행하는 것을 말한다. S2PL처럼 recoverability를 보장한다. S2PL에 비해 구현이 쉽다는 장점이 있지만, lock과 unlock의 시점이 S2PL보다 길어서 동시성이 조금 떨어지게 된다는 단점이 있다.
s_lock(x)
read(x)=>100
x_lock(y)
s_lock(y)
read(y)=>200
write(y)=300
commit
x_unlock(y)
s_unlock(x)
read(y)=>300
x_lock(x)
read(x)=>100
write(x)=400
commit
x_unlock(x)
s_unlock(y)3.4. 2PL, locking의 한계
locking 방식은 위에 있는 lock 호환성에서 볼 수 있듯이 block 현상이 너무 많이 발생한다. read-read 경합에서만 공유락끼리 만나므로 동시처리가 되는데, 나머지는 다 서로 기다리기 때문이다. 그래서 write-write경합까지는 아니더라도 read-write, write-read에서는 lock을 쓰지 않고 동시성을 제어하는 기법을 사용한다.
4. MVCC(multiversion concurrency control)
- MVCC란 데이터베이스가 데이터 업데이트를 필요로 할 때, 기존 데이터를 덮어쓰는 대신, 새로운 데이터 버전을 만든다. 이때, 다양한 버전이 생기는데, 트랜잭션이 접근하는 버전은 isolation level에 따라서 바뀐다.
- MVCC란 데이터베이스의 스냅샷을 유지하여 데이터가 업데이트 되는 중에도 이전 버전의 데이터를 읽어가도록 허용하여 읽기의 일관성을 유지하면서도 쓰기의 종료를 대기하지 않도록 하는 기법이다.
- MVCC는 서로 다른 tx들이 같은 레코드에 접근했을 때 쓰기와 읽기의 경합을 최소화하면서 point-in-time consistency를 보장한다. tx의 레코드 수정 시 수정 시점들의 버전이 저장된다. 하나의 tx가 여러 버전이 있는 레코드에 읽기를 수행 시, 버전을 탐색하면서 isolation level에 따라 생긴 스냅샷 이미지를 읽는다.
주로 읽기-쓰기 간의 동시성을 제어하던 locking 대신에 사용된다. locking보다 훨씬 적은 block 경우의 수를 가지고 있기 때문에, 성능에 유리하다. 근데 굳이 쓰기에서까지 lock을 대체하지 않는 이유는 MVCC가 가진 오버헤드 때문인 듯하다. 요즘 RDBMS에서는 read의 공유락만 대체하는 듯하다.
4.1. lock 호환성 정리
read시에 lock을 획득할 필요가 없으며, write시에 exclusive lock을 획득해야 한다. 그래서 쓰는 도중 읽거나 읽는 도중 쓰는 것이 가능해진다. 대신 read-write conflict 사이에서는 mvcc로 일관성을 보장하도록 한다.
<read> <write>
<read> O O
<write> O X4.2. MVCC 동작 방식
- 데이터를 읽을 때 특정 시점 기준으로 가장 최근에 commit된 데이터를 읽는다. read committed라면 현재 수행 시점, repeatable read라면 트랜잭션 시작 시점 기준이다.
- 데이터의 변화 이력(write)를 트랜잭션마다 기록하고, commit시 db에 반영한다.
- read와 write는 서로를 block하지 않는다.(read에서 lock 취득 필요x)
t1: x를 두 번 읽는다.
t2: x를 50으로 바꾼다.
x = 10
<read committed 기준>
x_lock(x)
write(x=50) // ss(snapshot):x=50
read(x)=>10
commit // db:x=50
x_unlock(x)
read(x)=>50read committed에서는 read하는 시간을 기준으로 그 전에 commit된 데이터를 읽는다. t1의 첫 번째는 아직 t2의 스냅샷이 커밋이 안되었지만 두 번째는 t2의 스냅샷이 커밋된 후이므로 50이 된다.
<repeatable read 기준>
x_lock(x)
write(x=50) // ss:x=50
read(x)=>10
commit // db:x=50
x_unlock(x)
read(x)=>10repeatable read에서는 트랜잭션 시작 시점을 기준으로 그 전에 commit된 데이터를 읽는다. 4번째 줄에서 x=50이 커밋되었지만, 트랜잭션은 3번째 줄에서 시작되었으므로, 커밋 히스토리에서 그 전에 있던 최근의 변화(=db에 현재 있는 값)인 x=10을 읽는 것이다.
대략적인 방식은 같지만, RDBMS마다 살짝 다른 부분이 있다. MYSQL과 POSTGRESQL을 비교하면
우선 postgresql이다.
- postgresql은 repeatable read에서 first-update-win 방식으로 lost update까지 막는다. mvcc의 동작은 tx시점 기준 최근 commit을 읽는 것으로 동일하다.
- 하지만, write skew같은 문제가 아직 있고, locking read를 하거나 격리 수준을 올려 해결한다.
다음은 mysql이다.
- mysql은 repeatable read에서 lost update를 막을 수 없다.
- 이러한 lost update와 write skew 문제는 locking read나 격리 수준을 올려서 해결할 수 있다.
4.3. postgreSQL repeatable read
postgreSQL의 repeatable read는 mvcc와 더불어 first-updater-win방식으로 수행된다. first-updater-win이란 어떤 시점에서 같은 데이터에 먼저 update한 tx가 commit되면 나중 tx는 해당 시점에서 rollback되는 것을 말한다.
t1: x가 y에 40을 이체한다.
t2: x에 30을 입금한다.
x = 50, y = 10
read(x)=>50
x_lock(x)
write(x=10)
read(x)=>50 // mvcc, x is not 10
x_lock(x)
read(y)=>10
x_lock(y)
write(y=50)
commit
x_unlock(x)
write(x=80)
rollback(x=50) // t1이 x에 먼저 write함, 여기서 실패
x_unlock(y)결국 결과는 정상적으로 나타난 것을 확인할 수 있다. 원래였다면, x에 대한 40 감소가 무시된 채로 80이 쓰여저 lost update가 발생했을 터였다. 이렇게 롤백된 뒤 t2를 다시 수행하면 트랜잭션이 성공적으로 수행된다.
반대로 순서로 수행되었다고 해보자.
read(x)=>50
read(x)=>50
x_lock(x)
x_lock(x)
write(x=80)
commit // db:x=80
x_unlock(x)
rollback(x=50) // 여기에서 실패아마 rollback이 없었더라면 30만큼의 입금이라는 변화가 사라졌을 것이다. 하지만 postgreSQL은 그러한 경우 나중의 tx를 롤백시켜 정상적인 결과를 만들어낸다.
postgreSQL에서는 repeatable read에서 기본적으로 lost update까지 막을 수 있지만 write skew까지 막지는 못한다. 막을라면 격리 수준을 높이거나 locking read를 쓰면 된다. 다음은 해당 격리 수준에서 write skew가 발생하는 상황이다.
t1: x와 y를 더해서 x에 쓴다.
t2: x와 y를 더해서 y에 쓴다.
x = 10, y = 10
read(x)=>10
read(x)=>10
read(y)=>10
read(y)=>10
x_lock(x)
write(x=20)
x_lock(y)
write(y=20)
commit
x_unlock(x)
commit
x_unlock(y)first-updater-win만으로는 해결이 불가능하다. 해결할라면, locking read 하면 된다.
** select ... for update
x_lock(x)
read(x)=>10
x_lock(x) // 원래는 read(x)=>10
x_lock(y)
read(y)=>10
write(x=20)
commit
x_unlock(x)
x_unlock(y)
rollback // read 실패, first-updater-win
자세히 보면 왜 여기꺼는 롤백되고 앞에껀 롤백 안되는지 잘 이해가 안됐었다. 위에서는 첫 번째의 read(x)=>10 시점에서 그 이전에 x를 건들고 커밋된 tx가 없다. 하지만 이번에는 locking으로 인해서 read(x)=>10이 t1의 commit 이후로 미루어지므로 해당 시점에서 이전에 x를 건들고 커밋된 tx가 생기게 된다. 이로써 해당 시점에서 롤백이 되게 된다. 요지는 locking read로 인해 first-updater-win이 발동할 수 있게 되었다는 것이다.
4.4. mySQL repeatable read
mysql은 first-updater-win 그런거 없다. 그래서 그냥 repeatable read로는 lost update랑 write skew를 해결할 수 없다. 해결하기 위해선 격리 레벨을 올리거나 locking read라는 방법을 이용해야 한다.
locking read란 개발자가 쿼리문 뒤에 for update/share라는 구문을 쓰고, read시에 lock을 취득하여 수행하는 것이다. for update는 배타락, share는 공유락이다.
t1: x가 y에 40을 이체한다.
t2: x에 30을 입금한다.
x = 50, y = 10
// select ... for update
x_lock(x)
read(x)=>50
// select ... for update
x_lock(x)
write(x=80)
commit
x_unlock(x)
read(x)=>80 // 여기
write(x=40)
// select ... for update
read(y)=>10
write(y=50)
commit
// unlock...여기에서 중요한 것은 9번째 줄에서 read(x)=>80하는 부분이다. 원래대로라면 repeatable read니까 tx시작 시점인 5번째 줄에서 커밋된 x=50을 읽었어야 한다. 근데, mysql에서 locking read는 가장 최근의 commit된 데이터를 읽는다. 근데 보면 2PL같은 locking 기반이랑 비슷한 거 같기도 하다.
postgreSQL에서처럼 write skew가 발생하고, 이를 locking read로 해결하는 것을 보자. postgreSQL과 달리 mysql은 locking read시 읽는 스냅샷의 시점이 다르다는 것을 유념하자.
t1: x와 y를 더해서 x에 쓴다.
t2: x와 y를 더해서 y에 쓴다.
x = 10, y = 10
read(x)=>10
read(x)=>10
read(y)=>10
read(y)=>10
x_lock(x)
write(x=20)
x_lock(y)
write(y=20)
commit
x_unlock(x)
commit
x_unlock(y)locking read를 쓰면
** select ... for update
x_lock(x)
read(x)=>10
x_lock(x) // 원래는 read(x)=>10
y_lock(y)
read(y)=>10
write(x=20)
commit // db:x=20
x_unlock(x)
x_unlock(y)
read(x)=>20 // locking read 아니면 10이다.
x_lock(y)
read(y)=>10
write(y=30)
commit // db:y=30
x_unlock(x)
y_unlock(y)
요지는 locking read 시 tx 시작이 아니라 해당 시점을 기준으로 데이터를 읽는 것이다. write skew가 변화를 반영하지 못한 데이터를 바탕으로 write를 한 것이므로, locking read로 미루는 것 뿐만 아니라 최신의 데이터(tx시작시점 아니고 현재 시점)를 읽어야 write skew를 해결할 수 있었다고 볼 수 있겠다.
4.4. mySQL과 postgreSQL의 serializable level
postgreSQL
- SSI(serializable snapshot isolation)으로 구현된다.
- SSI는 뭔진 모르지만, first updater win 방식처럼 돌아간다고 한다.


"커미트된 읽기"(일반적으로 기본 옵션)에서 "직렬화 가능한 스냅샷 격리"(SSI), 중간 옵션인 "스냅샷 격리"(SI)에 이르기까지 여러 수준의 격리가 있습니다. Oracle의 다중 버전 동시성 제어(MVCC) 구현은 SI를 제공하지만 이 수준의 격리에서는 아직 이상 현상이 발생할 수 있습니다.
SSI를 구현한다는 것은 데이터 이상으로 이어질 수 있는 동시 트랜잭션 간의 충돌을 감지하고 해결할 수 있음을 의미합니다.
SSI는 엄격한 2단계 잠금으로 구현할 수 있지만 이는 블록 및 성능 저하를 의미합니다. PostgreSQL은 직렬화 가능성을 보장하기 위해 다른 접근 방식을 취합니다. 즉, 스냅샷 격리를 사용하여 트랜잭션을 실행하지만 이상이 가능한지 확인하기 위해 추가 검사를 추가합니다.
mySQL
- repeatable read와 유사하다.
- 모든 tx의 select는 암묵적으로 select ... for share로 작동한다. for share인 이유는 성능이 배타락보다 높기 때문이고, 다만 데드락 확률이 좀 더 늘어난다. 아무튼 거의 락 기반이라는 것이다.
4.5. SSI(serializable snapshot isolation)
https://medium.com/@fineroot1253/postgresql-mvcc-ssl-2f3ba4ce12da
SSI는 스냅샷 이상 현상이 발생할 것으로 예측되면, abort하여(롤백 후 다시 수행) 동시성을 제어하는 기법이다. repeatable read를 넘어서 이상 현상을 완전히 배제하기 위해(write skew, phantom read) 특정 반종속성(rw-conflict)을 탐지하는 것을 목표로 한다. 근데, 단순히 이전 버전을 read하는 것(rw-conflict)을 문제라 할 수는 없었고, 2개 이상의 rw-conflict가 존재하면 충돌 현상(SI anomaly의 발생)이라 규정하여 그것을 abort한다는 규칙을 구현했다. 이 부분이 다른 dbms(oracle, mysql)와 대비되는 중요한 차이점이다.
RW-반종속성 (rw — anti dependency, rw-충돌, rw-conflict) : T1이 Write, T2가 해당 튜플의 이전 버전을 read한다면 T2가 T1의 write한 튜블의 버전을 Read하지 않았기 때문에 T1이 T2보다 먼저 실행된 것으로 보이는 것을 의미한다. (이 의미는 T1의 결과가 T2의 Read 결과에 보이지 않아 생기는 결과를 의미한다.)
read(x)
write(x)
commit
read(x) or write(y)
// y는 x와 관련이렇게 되거나
read(z)
write(x)
commit
read(x) // t2 의 write(x)이전 버전을 읽는다.
write(x)...이런 걸 말하는 듯 하다.(skew 현상)
아무튼 정리하면, 반종속성을 추적해 tx를 abort하여 직렬화 격리를 달성한다. 물론 오탐 가능성이 있어서, 이상 현상이 없음에도 abort할 수는 있지만, 기존의 S2PL이나 OCC, Locking read같은 기법들보다 우수한 성능을 보인다고 한다.
OCC란 낙관적 동시성 제어를 말한다. 튜플에 락킹을 걸지 않고 튜플 조회시 버전을 확인해 최신인 경우에만 업데이트를 하는 방식이다.
postgreSQL이 반종속성을 추적하는 방법은 SI READ-LOCK을 활용한다. 해당 락을 다른 tx에서 취득한 상태에서, x-lock을 취득하려 한다면 rw-반종속성 플래그를 지정할 수 있다.(아마 2번 이상 그거인듯) 그리고 read의 커밋 이후에도 모든 동시에 실행되던 tx가 커밋될 때까지 SI READ-LOCK을 유지한다.
근데, 생각해보니까 이러면 shared locking read랑 별 다를 것이 없고, 다 abort 해버리는 것이 아닌가 싶다. 사실 이 부분은 잘 이해를 못한 것 같다.
또, 안전한 스냅샷인지를 감지하고 해당 SILOCK을 작동하지 않기도 한다. 즉, 실수로 잘못 abort하는 경우가 줄게 되는 것이다.
특히 활성화된 동시 R/W Tx가 없다면 이 Read-Only Tx의 스냅샷은 이 즉시 안전한 스냅샷으로 간주하며 SSI 오버헤드 또한 발생하지 않는다.
그리고, 해당 충돌을 감지하고 나서 retry를 하는 방법도 따로 있는가보다. 그냥 우당탕탕 바로 retry 하면 안되는 모양.
[충돌 복구: Safe Retry]
트랜잭션이 중단된 경우 동일한 트랜잭션을 즉시 재시도해도 동일한 serialize 실패로 또 다시 실패하지 않는다.
[트랜잭션 중단 시나리오]
rw-반종속성 리스트에서 위험한 구조를 발견 [ex: T1 rw → T2 rw → T3]
커밋 순서 조건 충족
일부 트랜잭션 중단
[Safe Retry 규칙]
이상 현상 2번과 같은 상황일 때,
1) T3가 커밋될 때까지 아무것도 중단하지 말 것
⇒ 이 조건은 커밋 순서 최적화 + Safe Retry까지 제공한다.
2) 아직 커밋 되지 않은경우 항상 이상 현상을 제공하던 동시 트랜잭션 T2를 중단할 것
⇒ 1번 조건에 의해 T3가 항상 먼저 커밋되고 T2가 그 다음 재시도를 하게 만든다.
⇒ 이러면 RW-반 종속성이 사라져 동일한 오류를 방지하게 되므로 safe retry가 가능하게 만든다.
3) 위험한 구조 감지시 이미 T2, T3가 커밋된 경우엔 유일한 방안으로 T1이라도 중단할 것
⇒ 이미 T2, T3가 이미 커밋된 경우이지만 Read-Only Tx인 T1은 T2, T3 커밋 이후 재시도 될 경우엔 동시적이지 않고 순차적으로 레코드를 안전하게 온전히 얻을 수 있어 safe retry에 해당한다.
[특징]
1의 규칙에서 즉시 동시 트랜잭션을 중단하지 않는 이유는 즉시 중단하게 될때 T3가 커밋을 하고보니 딱히 상관도 없었을 동시 트랜잭션의 작업이 중단되는 남용을 방지하기 위해서이다.

https://whatsgrouplink.com/education-whatsapp-group