학원 외주가 거의 다 끝났다. 이번에는 저번 프로젝트와는 다르게 RDB를 한 번 써보았다. 처음에 테이블 설계하고 분할된 테이블에 각각 데이터를 넣는 것은 꽤나 오래 걸린 듯 하지만, 실제 작업을 하는 데에는 시간이 얼마 걸리지 않았다.
이번 프로젝트는 꽤나 의미있는 것이었다. 처음으로 데이터베이스를 적극적으로 써보았고, 맞닥뜨리는 문제를 해결하면서 새롭게 알게 된 것이 많았다. 특히 데이터베이스시스템 수업을 수강하면서 추가적으로 찾아본 개념들이 실제로 어떻게 쓰이는 지 확인해볼 수 있었다.
앞으로 디비를 좀 더 공부해보고자 한다. 일단 지금 2/3까지 봤던 디자인 패턴 공부를 후딱 마무리하고, 스승님이랑 데이터베이스랑 스프링 공부를 할 것이다.
이번 프로젝트를 하면서 배운 점을 정리해보겠다.
1. 동시성 제어
SQL을 쓰다보니 갑자기 'table is locked'라는 에러가 떴다. 뭔고 하니 디비에서 어떤 작업을 할 때에는 다른 접근을 막는다고 한다. 왜냐하면
- A 트랜잭션에서 10번 사원의 나이를 27살에서 28살로 바꿈, 아직 커밋하지 않음
- B 트랜잭션에서 10번 사원의 나이를 조회함, 28살이 조회됨
- A 트랜잭션에서 문제가 발생해 ROLLBACK함
- B 트랜잭션은 10번 사원이 여전히 28살이라고 생각하고 로직을 수행함
이런 문제가 발생하기 때문이다. 근데 신기했던 것은, select할 때는 문제가 안뜨더니 insert할 때에만 문제가 떴던 것이다.
추석쯤이었나 집에 갈 때 이런 영상을 본 적이 있다.
어렴풋한 기억으로, 읽기 작업과 쓰기 작업이 번갈아 일어나면 위에 있는 문제가 발생한다고 했던 것 같다. 그러면 selection 작업이 뭔고 하니 디비 구조를 보기 위에 계속 켜놓고 있던 sqlite browser이었다.
이 브라우저에서도 아마 디비 구조를 보기 위해 selection 작업을 계속 하고 있을 것이다. 내가 이걸 켜놓고 있으니까 sqlite에서 쓰기(insert)작업이 발생하면 막아버리는 것 같다.
근데, 저 영상에 따르면 쓰기랑 읽기가 있으면 동시 접근을 무조건 막는 것이 아니라, 성능 향상을 위해서 동시 접근이더라도 허용을 하는 기법이 있다고 했었다. 브라우저 키고 있다고 무조건 막는건 좀 아니지 않나 싶었다. 근데 또 찾아보니까
https://stackoverflow.com/questions/3172929/operationalerror-database-is-locked
대충 읽어보긴 했는데, SQLite is meant to be a lightweight database, and thus can't support a high level of concurrency. 이렇다고 한다. 그러니까, sqlite 자체가 동시성 제어가 약하다는 것이다. 아직 동시성 제어가 뭔진 잘 모르지만 동시 접근에 의한 문제를 막으면서도 퍼포먼스를 높게 유지하는 작업이 다른 디비에 비해 적다는 것 같다.
아마 막 작업이 단순히 동시에 발생하면 막는다. 이러면 별도의 작업이 필요 없지만, 각 작업이 다른 작업을 기다려야 하니까 속도가 느릴 것이다. 아마 sqlite의 동시성 제어가 이것에 해당되는 듯 하다.
반면 조금 더 무겁고 정교한 디비는 단순히 동시에 발생했을 때 막는 것이 아니라, 몇 가지 조건을 따져보고 그것에 부합하면 막는 듯 하다. 아무래도 작업을 기다리는 조건이 더 생겼으니, 작업을 덜 기다리게 되는 것이다.
아무튼 동시성 제어가 이런 식으로 작동하는구나 싶었다. 위에 글은 아직 제대로 공부하지 않고 하는 추측성 글이니 믿지 않는 것이 좋다.
2. 파일 시스템 vs 관계형 데이터베이스
우리 외주의 데이터는 전부 엑셀(파일 시스템)로 주고받는다. 그러다보니 무슨 문제가 있었냐면
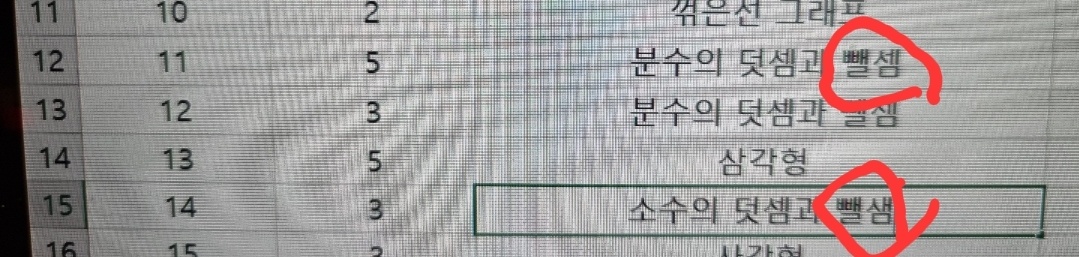
이런게 한 두개가 아니다. 아마 데이터 중복에 의한 데이터 불일치라 했던것 같다.(사진을 잘못찍었다. 분수의 덧셈과 뺄셈, 분수의 덧셈과 뺄샘 이렇게 되어있어야 한다.)
정규화 공부할 때 이상했던 것이 "데이터 중복은 사용자가 실수로 하나만 고쳤을 때 데이터 불일치가 발생하기 때문입니다!"라고 하길래, 뭔가 좀 억지스럽다고 생각했다. 뭔가 논리적 근거가 있는 것이 아니라(아직 덜 공부해서 그럴 수도 있겠지만) 나에게는 "실수하면 위험하잖아요!"라는 것처럼 들렸기 때문이다.
근데 진짜 겪어보니까 굉장히 화가 났다. 일일이 고쳤는데, 계속 빼먹어서 다시 검사하고 다시 고치고 했다. 계속 엑셀로 처리했으면 큰일 날 뻔했다.
이러한 데이터 중복 문제가 엑셀같은 파일 시스템의 문제점이다. 관계형 데이터베이스였으면
SHEET_UNIT({sheet_no}, {unit_no}, unit_name)={
(1, 4, '분수의 덧셈과 뺄셈'),
(1, 5, '삼각형'),
(1, 6, '소수의 덧셈과 뺄셈')
}
ANSWER_SHEET({item_no}, {answer}, unit_no)={
(11, 5, 4), (12, 3, 4), (13, 5, 5), (14, 3, 6)
}물론 외래키 unit_no(4, 4, 5, 6)에서 중복이 있긴 하나, 저렇게 복잡한 데이터보나 외래키에 여러 속성이 종속되는 경우보다는 훨씬 불일치가 덜 발생할 것이다.
아무튼 저런 데이터 중복을 줄이기 위해서라면 관계형 데이터베이스를 쓰는 것이 맞다.
그런고 하면, 파일의 장점도 있다. 관계형 데이터베이스를 쓴다는 것은 데이터를 릴레이션별로 분할하고 조인하는 방식을 쓴다는 이야기다. 분할을 어떻게 할 지, 제약을 뭘로 할 지, 분할된 릴레이션에 데이터를 어떻게 넣을 지, 조인을 어떻게 할 지 등 고민할 것이 많아진다. 파일 시스템은 그냥 갖다 넣으면 그만이다.
프로젝트가 단기에 완성되어야 하고, 유지보수의 중요도가 낮다면 파일 시스템이나 NoSql을 쓰면 되겠다. 반면 설계 과정같은 데에 시간을 투자할 수 있을 만큼 여유가 있고, 유지보수의 효율성을 추구한다면 정규화와 더불어 관계형 데이터베이스를 쓰면 될 것 같다.
첨언하자면 원교수님이 그랬다. 정규화 안하고 테이블 하나에 다 넣을꺼면 차라리 몽고디비같은 NoSQL 쓰라고. 결국 관계형 데이터베이스도 정규화를 해야 쓸모가 생긴다는 점을 명심하자.
3. null의 중요성
파일에 null값이 엄청 많았다. 시험 데이터인데, 이름이 없는 학생도 있고 OMR 인식이 잘 안된 건지 답이 거의 안적힌 것도 있었다. 데베시에서 null값의 위험성을 배웠기에, 미리 처리를 잘 해놓긴 했다.
조인이랑 그룹바이 집계함수 쓰는 부분이 있는데, 아마 null 처리 안하고 했으면 고생 꽤나 했을 것이다.
맞다 그리고 테이블 나누면 null값도 줄어들게 된다. 무슨 말이냐면
SHEET_UNIT({sheet_no}, {unit_no}, unit_name)={
(1, 4, null),
(1, 5, '삼각형'),
(1, 6, '소수의 덧셈과 뺄셈')
}
ANSWER_SHEET({item_no}, {answer}, unit_no)={
(11, 5, 4), (12, 3, 4), (13, 5, 4), (14, 3, 6)
}테이블이 분리되면 이렇게 null이 하나인데, 이게 직접 들어가게 되면
ANSWER_SHEET({item_no}, {answer}, unit_name)={
(11, 5, null), (12, 3, null), (13, 5, null), (14, 3, '소수의 덧셈과 뺄셈')
}이렇게 3개로 늘어난다.
4. 새로운 쿼리
데베시 공부하면서 조인이나 그룹같은 쿼리가 굉장히 익숙해졌다. 그래서 이것저것 찾아보고 이 프로젝트에 써먹어보았다.
insert에 select를 할 수 있다더라. 가령 이런 느낌이다.
INSERT INTO STUDENT_ERRATA(stu_no, item_no, errata)
SELECT R.stu_no, R.item_no,
CASE
WHEN R.response = A.answer then 1
WHEN R.response <> A.answer then 0
ELSE 0
END AS errata
FROM STUDENT_RESPONSE AS R
INNER JOIN STUDENT_PERSONAL AS P ON R.stu_no = P.stu_no
INNER JOIN SHEET_MATCH AS M ON P.level = M.level and P.school = M.school and P.grade = M.grade
INNER JOIN SHEET_ANSWER AS A ON R.item_no = A.item_no and M.sheet_no = A.sheet_no;원래라면 어플리케이션에서 select해서 조립하고 insert했을 것이다. 그럴라면 select 함수 만들고 튜플로 받아서 처리하고 또 insert 함수 만들어야하고, 결과를 바로 확인하기도 어렵다.
바로 쿼리 단에서 끝내니까 굉장히 편했다. 원래라면 다 리스트로 했던가 심지어는 이중 그룹도 select * 하고 리스트로 구현했던가 그랬는데, 코드가 3000줄 쯤에서 300줄로 줄어들었다.
이외에도 이중 그룹, switch case, 이중 ordering 등이 있다.
이전에는 select * 해서 어플리케이션 단에서 일일이 작업했는데, 한방에 해버리니까 너무 편하고 신기하다.
.
.
.
여튼 배운 점이 많은 프로젝트였다.
그리고 우정이형한테 맨날 짜증냈던 것 같은데 너무 미안하다는 말을 하고 싶다.
학원 측에서 계속 압박하고, 데이터는 이상하고, 마감 기한도 빡센데 내가 자꾸 일을 느릿느릿하게 하니까 멘탈이 남아나지 않을 것이다.
끝까지 화 한번 안내고 견뎌준 송우정 아주 칭찬해.
