수업 초반에 이야기했던 내용이고 수업 내내 주소값을 가져오는 것과 그 반대의 경우에 대해 이야기하셨던 것 같은데,
그 때는 당연하지~ 하고 넘어갔는데 갑자기 헷갈리기 시작했다. 다시 정리해보자!
- 복제
public class ReferenceDemo1 {
public static void runValue(){
int a = 1;
int b = a;
b = 2;
System.out.println("runValue, "+a);
}
public static void main(String[] args) {
runValue();
}
}
- 결과
runValue, 1
결과는 당연하다. 값을 변경한 것은 변수 b이기 때문에 변수 a에 담겨있는 값은 그대로이다. 변수 b의 값에 변수 a의 값이 복제된 것이다. 이를 그림으로 표시하면 아래와 같다.
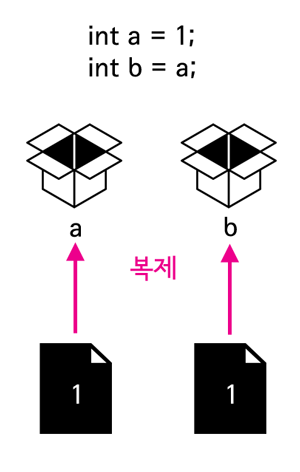
- 참조
- new로 객체를 만드는 데이터 타입, 기본 데이터 타입이 아닌 데이터 타입들은
- 변수를 만들게 되면 그 변수들은 그 객체(인스턴스)를 직접 저장하는 것이 아니라 그 객체에 대한 참조값만을 가지고 있기 때문에
- A b를 수정하면 A b를 가리키고있는 인스턴스를 수정한 것이고,
- 이는 곧 A a가 갖고있는 인스턴스를 수정한 것과 같은 것이다.

class A{ // 1. A라는 클래스는 id 값이라는 인스턴스 변수가 있고(public)
public int id;
A(int id){
// 2. A를 생성할 때 생성자에 인자를 받아서 그 인자가 인스턴스의 id 값을 세팅하도록 되어있는 클래스
// 4. 여기 A(int id)에 들어가서 이 int id 값은 1이 되어있는 상태가 됨
this.id = id;
}
}
public class ReferenceDemo1 {
public static void runValue(){
int a = 1;
int b = a;
b = 2;
System.out.println("runValue, "+a);
}
public static void runReference(){
A a = new A(1); // 3. 데이터 타입이 A인 변수 a 에 new를 해서 1이라는 값을 전달해서 a 안에는 클래스 A의 인스턴스가 저장되는데, 그 인스턴스의 내부 id값 (1)은
A b = a; // 5. 데이터 타입이 A인 변수 b는 = a 이다. 라고 할당함.
b = new A(2); // 9. 근데 이렇게 하면 더 이상 변수 b는 new A(1) 인스턴스를 가리키는 게 아니라 new A(2) 인스턴스를 가키기 때문에
// 10. a와 b는 다른 인스턴스를 가리키므로 b의 값을 바꿔도 a는 바뀌는 것이 없다.
b.id = 2; // 6. 이 상태에서 변수 b의 id 값을 2라고 바꾸면 --> a 의 id 값도 2가 됨. 참조한 원본 링크가 바뀐 것과 같기 때문에.
System.out.println("runReference, "+a.id);
}
// 7. A b를 수정하면 A b를 가리키고있는 인스턴스를 수정한 것이고, 이는 곧 A a가 갖고있는 인스턴스를 수정한 것과 같은 것이다.
public static void main(String[] args) {
runValue();
runReference();
}
}- 결과
runValue, 1
runReference, 2
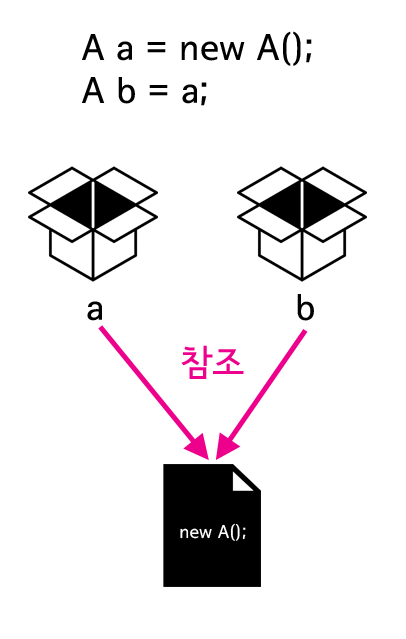
놀라운 차이점이 있다. 변수 b에 담긴 인스턴스의 id 값을 2로 변경했을 뿐인데 a.id의 값도 2가 된 것이다. 이것은 변수 b와 변수 a에 담긴 인스턴스가 서로 같다는 것을 의미하다.
복제는 파일을 복사하는 것이고 참조는 심볼릭 링크(symbolic link) 혹은 바로가기(윈도우)를 만드는 것과 비슷하다. 원본 파일에 대해서 심볼릭 링크를 만들면 원본이 수정되면 심볼릭 링크에도 그 내용이 실시간으로 반영되는 것과 같은 효과다. 심볼릭 링크를 통해서 만든 파일은 원본 파일에 대한 주소 값이 담겨 있다. 누군가 심볼릭 링크에 접근하면 컴퓨터는 심볼릭 링크에 저장된 원본의 주소를 참조해서 원본의 위치를 알아내고 원본에 대한 작업을 하게 된다. 다시 말해서 원본을 복제한 것이 아니라 원본 파일을 참조(reference)하고 있는 것이다.
아래 두 개의 구문의 차이점을 생각해보자.
int a = 1;
A a = new A(1);
무엇일까? 전자는 데이터형이 int이고 후자는 A이다. int는 기본 데이터형(원시 데이터형, Primitive Data Types)이다. 자바에서는 기본 데이터형을 제외한 모든 데이터 타입은 참조 데이터형(참조 자료형)이라고 부른다. 기본 데이터형은 위와 같이 복제 되지만 참조 데이터형은 참조된다. new를 사용해서 객체를 만드는 모든 데이터 타입이 참조 데이터형이라고 생각해도 된다. (단 String은 제외다) 이를 그림으로 나타내면 아래와 같다.
( 출처 생활코딩 https://opentutorials.org/module/2495/14152 )
- 참조 데이터 형과 매개 변수
그럼 일종의 변수할당이라고 할 수 있는 메소드의 매개변수는 어떻게 동작하는가를 살펴보자. 조금 복잡하므로 꼼꼼하게 살펴봐야 한다. 예제를 보자.
public class ReferenceDemo2 {
static void _value(int b){
b = 2; // int b = a; 인데 b=2; 했다고 해서 a가 바뀌나? no!
}
public static void runValue(){
int a = 1;
_value(a); // int b = a; 와 같은 의미다!
System.out.println("runValue, "+a); // 그러니까 위에서 어쨌든 a 값은 안바뀌었으니 a=1
}
static void _reference1(A b){ // 3. 이 _reference1 메소드의 매개변수는 b 즉, A b = a;
b = new A(2); // 4. b = new A(2) --- 새로 생긴 변수 b는 새로운 new A(2) id값이 2인 인스턴스를 참조중
}
public static void runReference1(){
A a = new A(1); // 1. a라는 변수에 A(1)라는 인스턴스를 담았고 id값은 1인 상태 (참조 관계)
_reference1(a); // 2. _reference1 라는 메소드를 호출했고, 그리고 거기에 인자는 a를 줬음
System.out.println("runReference1, "+a.id);
}
static void _reference2(A b){ // 5. A b = a ; -- 변수 a가 new A(1) 참조 중이고
b.id = 2; // 6. b.id = 2 ; -- 변수 b는 같은 new A(1)를 참조 중이다.
}
public static void runReference2(){
A a = new A(1);
_reference2(a);
System.out.println("runReference2, "+a.id); // 7. 즉 new A(1)의 id 값이 2로 바뀌었으니 a의 id도 2로 바뀌었음!
}
public static void main(String[] args) {
runValue(); // runValue, 1
runReference1(); // runReference1, 1
runReference2(); // runReference2, 2
}
}
- 결과는
runValue, 1
runReference1, 1
runReference2, 2
위의 예제는 3가지 경우를 설명하고 있다. 하나씩 살펴보자.
첫번째는 int형 데이터가 복제되어 전달되므로 호출된 메소드의 작업이 호출한 메소드에 영향을 미치지 않고 있다. 어찌보면 자연스러운 결과다.
두번째 코드를 보자. 아래 코드는 _reference1의 매개변수로 참조 데이터 타입을 전달하고 있다.
runReference1();
메소드 _reference1 안에서 매개변수 b의 값을 다른 객체로 변경하고 있다. 이것은 지역변수인 b의 데이터를 교체한 것일 뿐이기 때문에 runReference1의 결과에는 영향을 미치지 않는다.
그런데 다음의 코드는 호출된 메소드의 작업이 호출한 메소드의 변수에 영향을 미친다.
runReference2();
매개변수 b의 값을 다른 객체로 교체한 것이 아니라 매개변수 b의 인스턴스 변수 id 값을 2로 변경하고 있다. 이러한 맥락에서 _reference2의 변수 b는 runReference2의 변수 a와 참조 관계로 연결되어 있는 것이기 때문에 a와 b는 모두 같은 객체를 참조하고 있는 변수다.
매개변수를 다른 객체로 변경하는 것과 참조 데이터 타입의 매개변수에 담겨 있는 객체에 접근하는 것은 완전히 다른 의미를 가지기 때문에 두가지 경우의 차이점을 확실하게 이해하도록 하자.
