
컬렉션 프레임워크 (Collection Framework)
-
Collection과 비교했을 때, 배열의 문제점
- 불특정 다수의 객체를 저장하는 것이 힘들다.
- 객체 삭제시 해당 인덱스가 비게된다.
- 크기가 고정되어 있다.
-
컬렉션 프레임워크
- 크기가 동적이며 인덱스로 객체들을 효율적으로 추가, 삭제, 검색할 수 있도록한다.
- 인터페이스를 통하여 다양한 클래스가 이용가능하다.
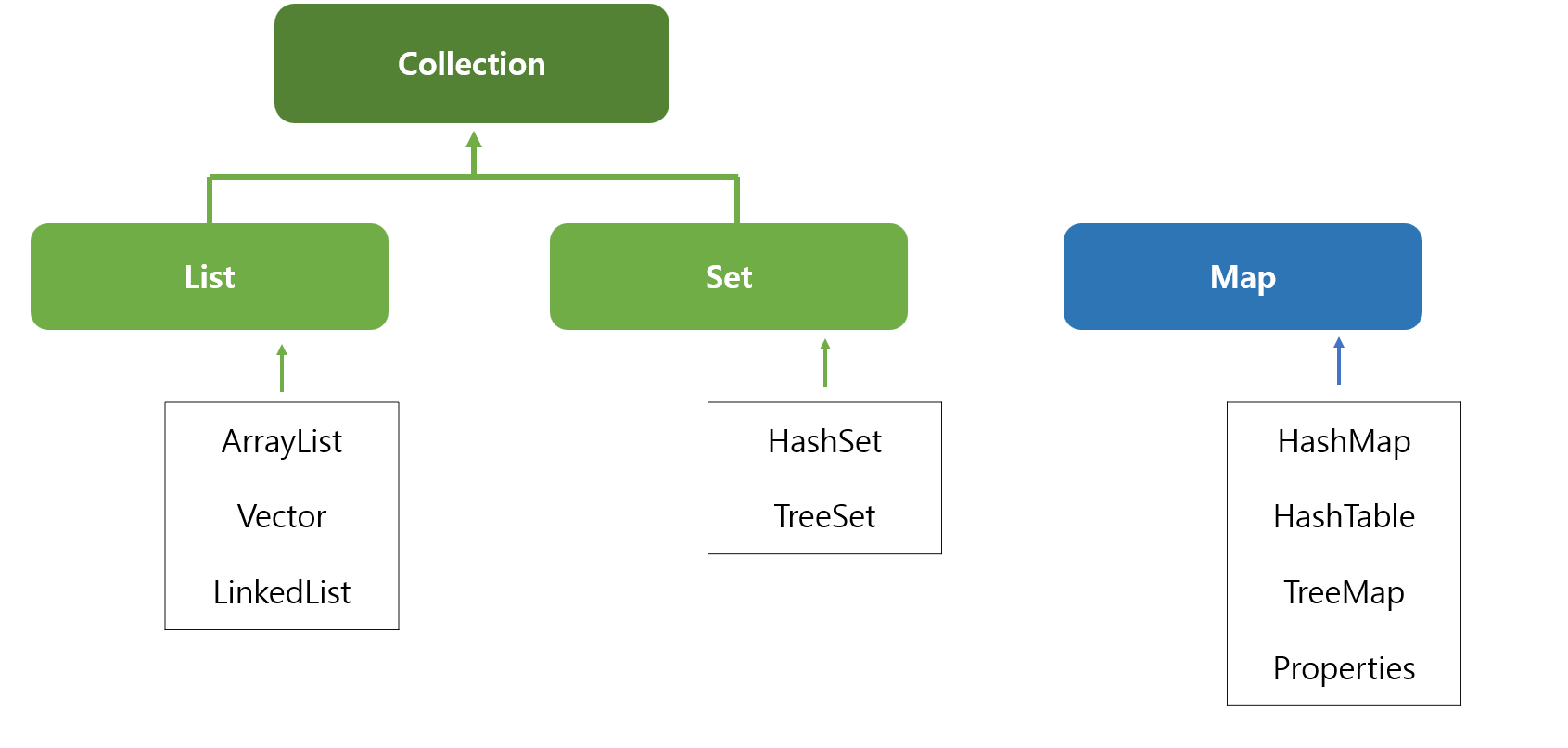
| List | Set | Map |
|---|---|---|
| 순서 유지하며 저장 | 순서유지하지않고 저장 | 키와 값의 쌍으로 저장 |
| 중복저장가능 | 중복저장불가 | 키는 중복저장 불가 |
📖 List
- List<
E> 긱체가 제너릭 인터페이스이므로 자식 클래스도 제네릭 클래스이므로 타입을 지정해야한다. - 생성
List<E> list = new ArrayList<E>();
List<E> vector = new Vector<E>();
List<E> linkedList = new LinkedList<E>();🔊 ArrayList
- 특징
- 동일 타입 수집, 메모리 동적 할당, 데이터 추가/변경/삭제 메서드 존재
주요 메서드
List<Integer> list = new ArrayList<Integer>();
boolean list.add(int value); //리스트 마지막에 추기
void list.add(int index, int value); //인덱스 위치에 원소 추가
boolean list.addAll(Collection<? Extends E> c);
E list.set(int index, E element);
E list.remove(int index);
boolean list.remove(E element); //동일한 객체 삭제
void list.clear();
E list.get(int index);
int list.size();
boolean list.isEmpty();
Object[] list.toArray(); //리스트를 Object 배열로 변환
T[] list.toArray(T[] t); //T 타입의 배열로 변환🔊 Vector
- ArrayList와 달리 Vector는 동기화 메서드가 제공되어 멀티 쓰레드를 활용할 수 있다는 점에서 차이를 가진다.
- 싱글 쓰레드에서는 무겁고 리소스를 많이 차지하여 잘 사용하지 않으므로 패스
🔊 LinkedList
- ArrayList와의 차이점
- 저장 용량을 지정할 생성자가 없다.
- 인덱스가 아닌 앞뒤 객체의 정보를 저장한다.
- 데이터의 추가 혹은 삭제에서 배열은 index관련 정보를 모두 수정해줘야하지만 얘는 앞뒤 객체 관련 정보만 바꿔주면된다.
- 검색은 index가 있어 Array가 빠르다.
List<Integer> linkedList = new LinkedList<Integer>();📖 Set
- Set
- 집합같이 타입은 같은 객체들을 묶지만 index는 없다.
- 데이터의 중복은 허용하지 않는다.
Set<Element> set = new Set<Element>();
boolean set.add(E e);
boolean set.addAll(Collection<? Extends E> c);
boolean set.remove(Object o);
void set.clear();
boolean set.isEmpty();
boolean set.contains(Object o)
int set.size();
Interator<E> iteratior(); //객체 내의 데이터를 연속으로 꺼내는 Iterator 객체 리턴
Object[] set.toArray();
T[] set.toArray(T[] t);🔊 HashSet
- 생성시 크기는 16이고 필요하면 동적으로 증가된다.
- index가 없어서 모든 데이터를 살펴보려면 Iterator 혹은 forEach문을 활용하면 된다.
- Iterator<
E> 클래스 메소드
boolean hasNext();
E next(); Set<String> hSet = new HashSet<String>();
Iterator<String> iterator = hSet.iterator();
while(iterator.hasNext()){
System.out.print(iterator.next() + " ");
}
for(String s : hSet){
System.out.print(s + " ");
}🔊 TreeSet
- HashSet은 중복만 확인하지만 TreeSet은 두 객체의 크기를 비교한다.
- TreeSet을 Set으로 선언하면 정렬(SortedSet) 및 검색(NavigableSet) 기능을 사용할 수 없으므로 TreeSet으로 선언해주어야한다.
TreeSet<String> treeSet = new TreeSet<String>();
E treeSet.first();
E treeSet.last();
E treeSet.lower(E element); //매개변수로 입력된 원소보다 작은, 가장 큰 수
E treeSet.higher(E element); //매개변수로 입력된 원소보다 큰, 가장 작은 수
E treeSet.floor(E element); 📖 Map<V, K>
key-value 한 쌍의 데이터를 저장하며 이를 '엔트리'라고 정의한다.
key값을 이용하여 검색이 가능하며 중복이 되지않으므로 구분도 가능하다.
V put(K key, V value);
void putAll(<? extends K, ? extends V> m);
V replace(K key, V value); //데이터 변경
boolean replace(K key, V oldValue, V newValue);
V get(Object key);
boolean containsKey(Object key);
boolean containsValue(Object value);
Set<K> ketSet(); //Map 객체 중 Key들만 뽑아 Set 객체로 리턴
Set<Entry<K,V>> entrySet();
int size();
V remove(Object key);
boolean remove(Object key, Object value);
void clear();🔊 HashMap<K, V>
- Key값의 중복은 허용되지 않는다. HashSet의 Map버전이라고 생각하면 될 거 같다.
📖 Stack
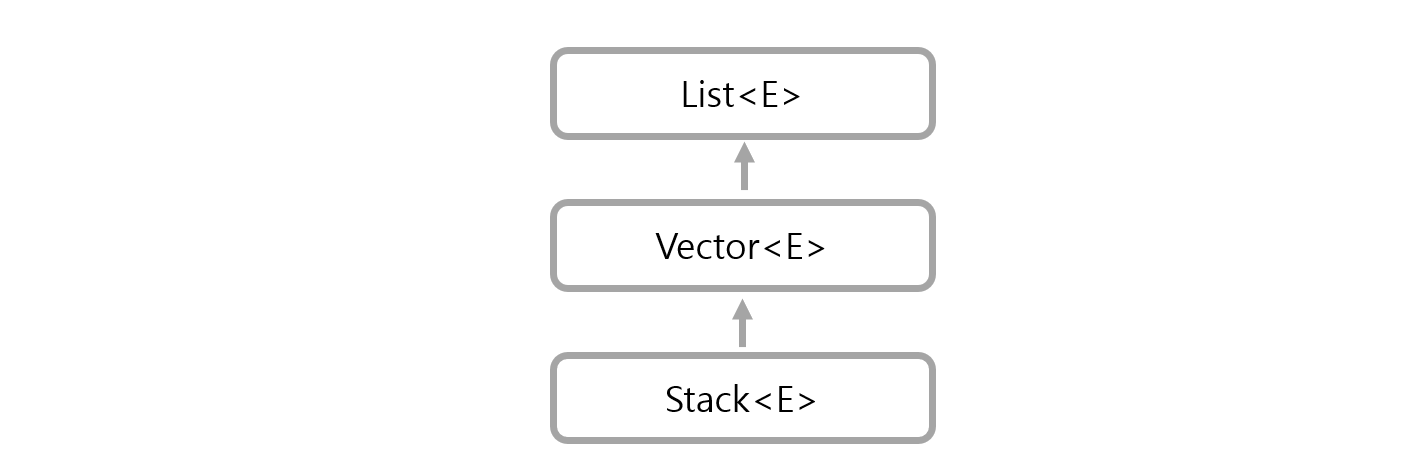
- Vector를 상속받으므로 LIFO(선입후출) 자료구조를 구현한 컬렉션이다. 원래의 add와 remove 함수로는 LIFO를 구현할 수 없다.
- 후입선출 관련되어 추가된 5가지 메서드가 있는데 Stack<
E>으로 선언해야 사용할 수 있다.
E push(E item); //매개변수 item을 Stack에 추가
E peek(); //최상위 원소값 리턴
int search(Object o); //위치값 리턴, 맨위가 1 아래로 갈수록 1씩 증가
E pop(); //최상위 원소 꺼내고 데이터 개수 감소
boolean empty();Queue
FIFO(선입선출) 방식을 이용한다.
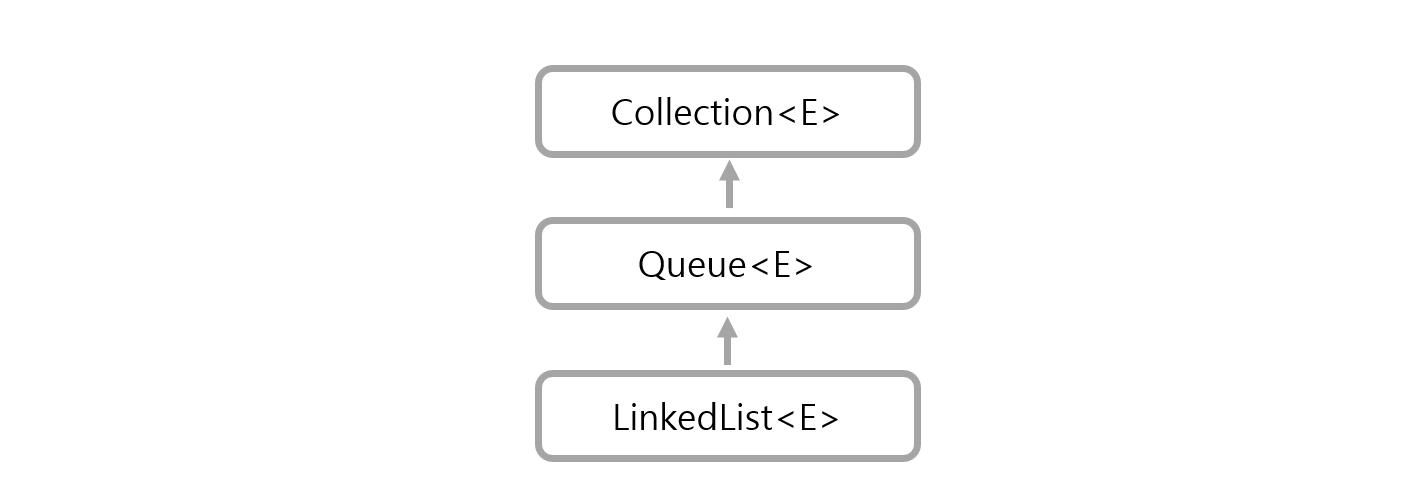
- add, remove, element는 데이터가 없을 때 예외를 발생시킨다.
- offer, poll, peek은 데이터가 없으면 기본값을 출력시킨다.
