스타벅스 이디야커피 데이터 분석
최종목표
- 위 두사이트에서 서울시에 있는 매장 주소와 장소 데이터를 가져온다
- 주소 데이터를 이용하여 스타벅스 매장 주위에 이디야 커피 매장이 있는지 확인
문제 1. 스타벅스 매장의 이름과 주소, 구 이름을 Pandas data frame 으로 정리
- Selenium 으로 데이터에 접근한후 Beuatiful soup으로 위치 데이터 검색사용할 모듈
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
import numpy as np
import pandas as pd
from selenium import webdriver
import requests
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
from bs4 import BeautifulSoup
from urllib.request import urlopen
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook
import folium
import platform
driver = webdriver.Chrome("../driver/chromedriver.exe") # 구글드라이버 경로 입력
driver.get("https://www.starbucks.co.kr/store/store_map.do ") # 원하는 창 오픈
# 혹시 몰라서 최대창으로 키워서 진행
driver.maximize_window()
# 퀵 검색에서 지역 검색으로 이동
xpath_si = '''//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a'''
some_tag = driver.find_element_by_xpath(xpath_si)
some_tag.click()
# 지역검색에서 서울 칸으로 이동
xpath_gu = '''//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'''
some_tag = driver.find_element_by_xpath(xpath_gu).click()
# 전체 칸 클릭
xpath_gu = '//*[@id="mCSB_2_container"]/ul/li[1]/a'
some_tag = driver.find_element_by_xpath(xpath_gu)
some_tag.click()
'''
'''
#Beautifulsoup 을 이용하여 html불러오기
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
print(soup.prettify())
- html 파일에서 주소위치 확인
# id= "mCSB_3_container"
# 첫번째 매장확인
# 전화번호가 전부 똑같음.
content = soup.find("div", id = "mCSB_3_container")
contents = content.find_all("li")
contents[0]
# 함수에 사용될것을 미리사용해봄
a = contents[0]
b = []
name = a.find('strong').text.strip()
adress = a.find('p').text.strip()
adress = adress.replace('1522-3232', '')
gu = adress.split(' ')[1]
c = {
'브랜드' : '스타벅스',
'상호명' : name,
'구' : gu,
'주소' : adress
}
print(c)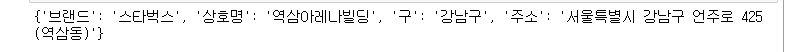
- 사용된 반복문
starbucks_list = []
for li in contents:
name = li.find('strong').text.strip()
adress = li.find('p').text.strip()
adress = adress.replace('1522-3232', '')
gu = adress.split(' ')[1]
a = {
'브랜드' : '스타벅스',
'상호명' : name,
'주소' : adress,
'구' : gu
}
starbucks_list.append(a)
df_starbucks = pd.DataFrame(starbucks_list)
df_starbucks.head(5)
# 서울시내 스타벅스 매장의 개수는 587개
len(starbucks_list)문제 2. 이디야커피 매장의 이름과 주소, 구 이름을 Pandas data frame 으로 정리
- 스타벅스 데이터와 동일하게 접근1driver = webdriver.Chrome("../driver/chromedriver.exe") # 구글드라이버 경로 입력
driver.get("https://ediya.com/contents/find_store.html ") # 원하는 창 오픈
# 주소 카테고리 클릭
xpath = '''//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a'''
some_tag_xpath = driver.find_element_by_xpath(xpath).click()
# 혹시 몰라서 최대창으로 키워서 진행
driver.maximize_window()
# 구를 하나하나 검색해야되서 스타벅스데이터에 있는 구 데이터를 활용
# 중복값은 set자료형으로 지움
gu_list = sorted(list(set(df_starbucks['구'])))
print(gu_list)
# 강남구를 예를 들어 자료 정리예시
some_tag = driver.find_element_by_id("keyword").clear()
some_tag = driver.find_element_by_id("keyword").send_keys(f'{gu_list[0]}')
xpath = '''//*[@id="keyword_div"]/form/button'''
some_tag_xpath = driver.find_element_by_xpath(xpath).click()
# 검색된 html 파일 불러오기
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
print(soup.prettify())- html 파일에서 주소위치 확인
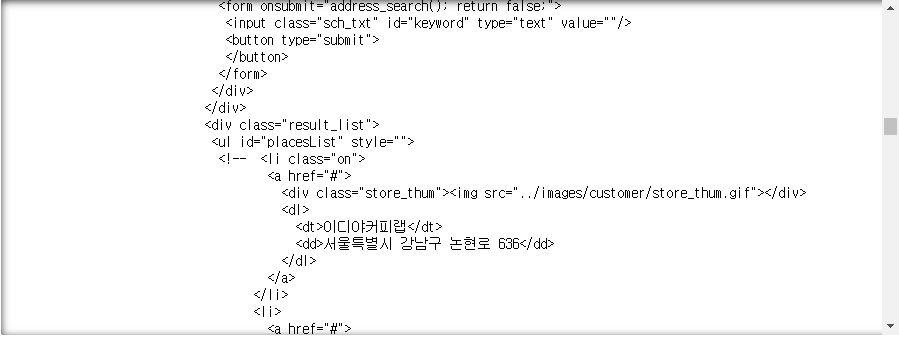
# [0] 구역 조사
a = soup.find("ul", id = "placesList")
a_t = a.find_all("dl")
aa = []
for dl in a_t:
name = dl.find("dt").text.strip()
address = dl.find("dd").text.strip()
gu = address.split(" ")[1]
c = {
"브랜드" : "이디야",
"매장이름": name,
"주소" : address,
"구" : gu
}
aa.append(c)
print(aa)
- 사용한 반복문
eidiya_list =[]
for gu in tqdm_notebook(gu_list):
some_tag = driver.find_element_by_id("keyword").clear()
some_tag = driver.find_element_by_id("keyword").send_keys(f'서울 {gu}')
xpath = '''//*[@id="keyword_div"]/form/button'''
some_tag_xpath = driver.find_element_by_xpath(xpath).click()
# 검색된 html 파일 불러오기
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
ul_tag = soup.find("ul",id ="placesList")
dl_all = ul_tag.find_all("dl")
for dl in dl_all:
name = dl.find("dt").text.strip()
address = dl.find("dd").text.strip()
gu = address.split(" ")[1]
a ={
"브랜드" : "이디야",
"상호명": name,
"주소" : address,
"구" : gu,
}
eidiya_list.append(a)
df_eidiya = pd.DataFrame(eidiya_list)
len(df_eidiya)
df_eidiya.head()
문제 3. 스타벅스 매장 주변에 이디야 커피가 있는가..
# 스타벅스 데이터와 이디야 커피 데이터 합치기
df_sum = pd.concat([df_starbucks, df_eidiya])
df_sum.reset_index(drop=True, inplace=True)
df_sum.tail()
# 구글맵을 통해 위도와 경도 좌표 얻기
import googlemaps
gmaps_keys= 'AIzaSyBINX-cw2mTaTlf3BQdMqKQAV2_QL-_lXs'
gmaps = googlemaps.Client(key=gmaps_keys)
gmaps
df_sum["위도"] = np.nan
df_sum["경도"] = np.nan
df_sum.head()
for idx, rows in tqdm_notebook(df_sum.iterrows()):
rows["주소"]
tmp = gmaps.geocode(rows["주소"], language="ko")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
df_sum.loc[idx, "위도"] = lat
df_sum.loc[idx, "경도"] = lng
df_sum.head(10)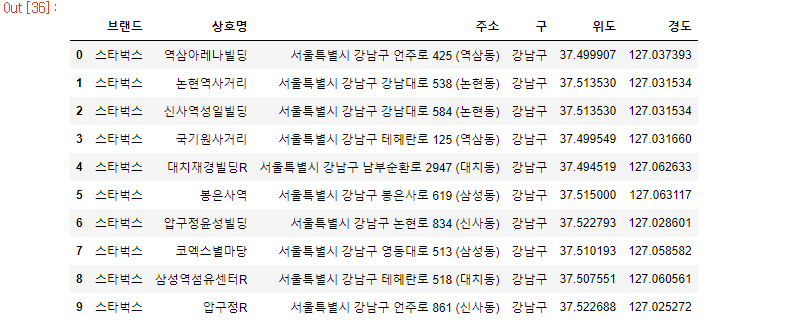
# mapping
mapping = folium.Map(location = [37.535855, 126.991558],zoom_start=11)
for idx, rows in df_sum.iterrows():
# 브랜드별 마커 설정
if rows["브랜드"] =="스타벅스":
mk_color="black",
elif rows["브랜드"] == "이디야":
mk_color = "blue"
# 지도마커 생성
folium.Marker(
location=[rows["위도"],rows["경도"]],
popup=rows["주소"],
tooltip = rows["상호명"],
icon =folium.Icon(
icon ="coffee",
prefix="fa",
color = mk_color)
).add_to(mapping)
mapping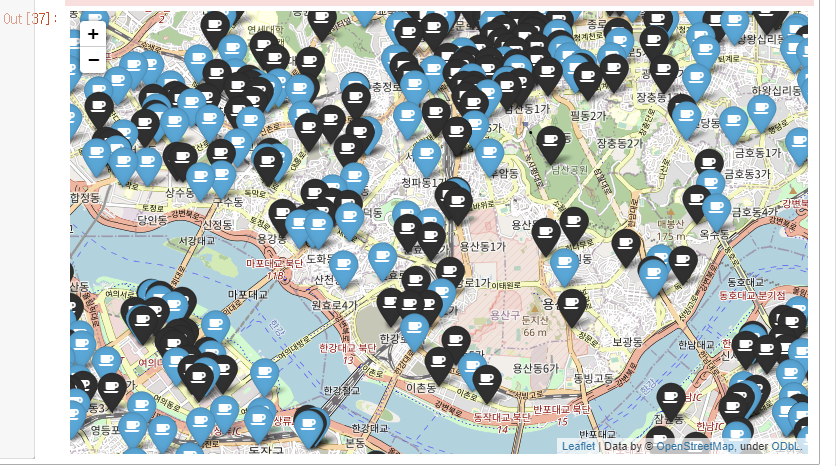
- 봐도 모르겟다.
# 구별로 매장수 구해보기
starbucks_gu = df_starbucks.groupby('구')['브랜드'].count().to_frame().sort_values(by='구', ascending=False)
starbucks_gu = starbucks_gu.reset_index()
starbucks_gu = starbucks_gu.set_index('구')
starbucks_gu
eidiya_gu = df_eidiya.groupby('구')['브랜드'].count().to_frame().sort_values(by='구', ascending=False)
eidiya_gu = eidiya_gu.reset_index()
eidiya_gu = eidiya_gu.set_index('구')
eidiya_gu
a = starbucks_gu.index
sum_gu = pd.DataFrame(index=a, columns=['스타벅스', '이디야커피'])
sum_gu["스타벅스"] = starbucks_gu
sum_gu["이디야커피"] = eidiya_gu
sum_gu.head(30)
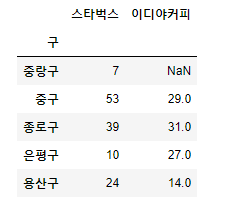
sum_gu.plot(kind='bar', figsize=(10, 10))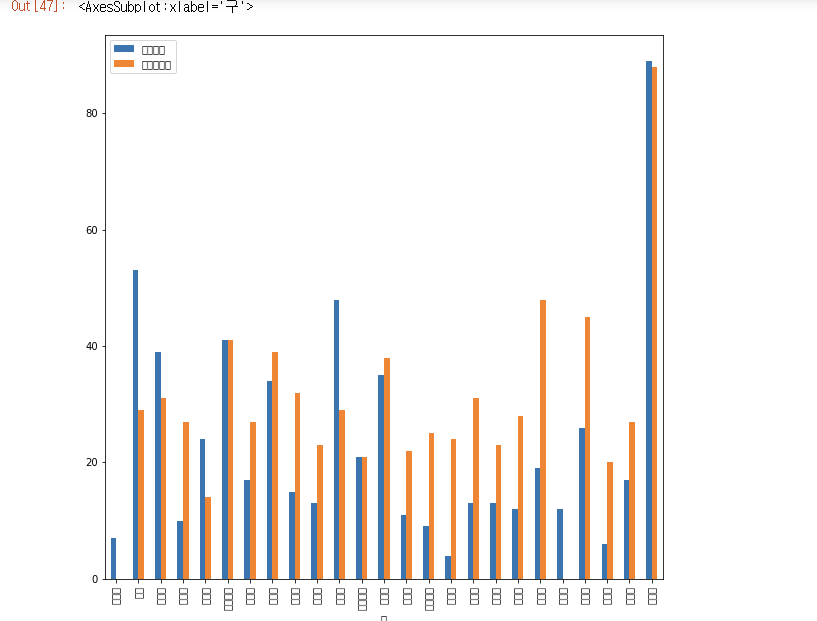
- 한글이 다깨졋는데 구글링을 아무리해봐도 해결이 안되서 일단 이대로 종료하고 해결방법찾고 수정하기로 했다.
분석결과
지도와 각 구별 데이터 프레임을 보면 스타벅스는 특정 구에 몰려있는 편이고 이디야 커피도 스타벅스만큼 극단적이지는 않지만
특정 구에 몰려있는 편이다. 서로 몰려있는 구가 강남구를 제외하면 다른편이고 스타벅스 매장보다 이디야 매장이 많다는 점을 봤을떄는
스타벅스 옆에 이디야커피가 있다는 말은 사살이 아니다.
