AWS SQS란?

SQS 란 aws에서 제공하는 완전 관리형 메시지 큐 서비스로 MSA, 분산 시스템, 서버리스 아키텍처에서 데이터를 안전하게 교환하거나 안정적으로 처리할 수 있도록 한다.
요청을 동기로 처리하는 것이 아닌 메시지 큐에 넣어 비동기적으로 백그라운드에서 요청을 처리하기 때문에 트래픽이 몰렸을 시에도 안정적으로 처리할 수 있는 것이다. 다만 이는 어디까지나 안정에 집중했을 뿐, 서비스가 감당할 수 있는 수준 이상의 대규모 트래픽이 요청됐을 경우엔 비동기 처리는 처리 속도가 느려질 수 밖에 없다. 따라서 트래픽을 분산하는 것은 SQS에게는 논외의 이야기다.
sqs는 서버리스 아키텍처에 적합하므로 aws에서 제공하는 대표적인 서버리스 서비스인 lambda와 함께 쓰이는 경우가 많다.
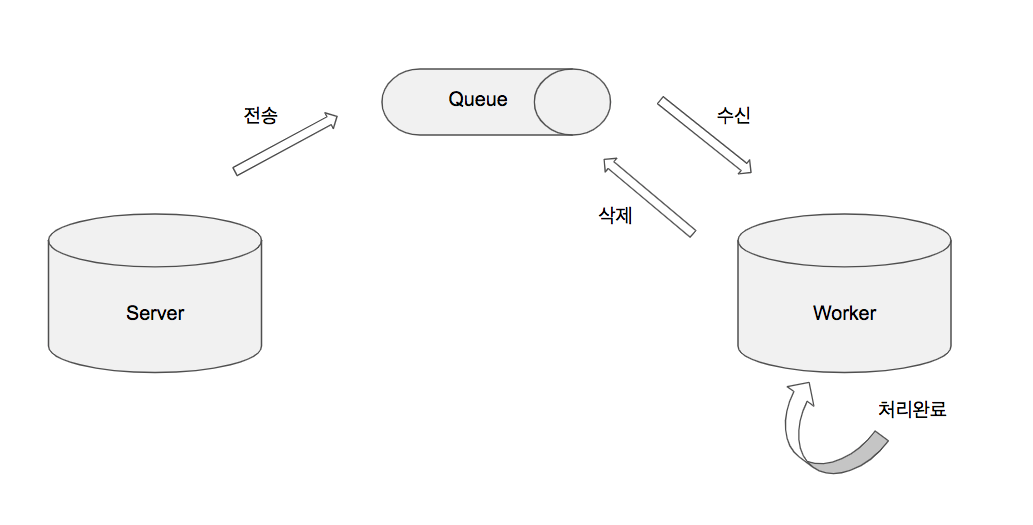
SQS 동작 구조
- Producer 는 메시지를 생성하여 Queue로 메시지를 전송한다.
- Queue는 메시지를 일정 기간 가지고 있게 된다.
- Consumer 는 주기적으로 Queue를 Polling 하면서 신규 메시지가 있다면 가져가서 처리한다.
- 처리가 끝나면 Queue로 Ack 를 전송한다. (메시지 아이디에 해당하는 Ack를 받으면 Queue에서 메시지를 제거한다. )
대략적인 동작 구조는 다음과 같다. 그럼 여기서 의문이 생긴다.
Consumer가 전송 받은 메시지를 처리하지 못하고 죽어버리면 어떻게 돼?
큐는 ack도, nack도 받지 못한 채 무한 대기에 빠질 것이다.
따라서 메시지를 받을 때는 Consumer에 절대적으로 의존하지 않고 Consumer가 죽더라도 메시지를 어떻게든 처리할 수 있는 보험 수단이 필요하다.
Timeout 설정
SQS에서는 VisibilityTimeout parameter를 설정해놔 설정한 시간이 지날동안 응답을 받지 못하면 대기 상태에서 해제할 수 있다. 이러면 나중에 프로세스가 살아났을 때 메시지 처리를 재시도 할 수 있다.
Timeout을 도입할 경우 만약 메시지 처리 (비즈니스 로직) 이 설정한 Time보다 오래 걸리면 로직을 2번 실행할 수도 있다. 이 경우 메시지 처리에도 timeout을 걸어주는 것이 안전하다!
SQS pseudo - code
이러한 주의점을 따르며 수도 코드를 작성해보면 SQS의 worker pseudo-code는 다음과 같다
참고로 위의 주의점과 코드는 여기에서 도움을 받았다.
function worker() {
while (true) {
const message = sqs.receive({ timeout })
try {
// process는 실제 비즈니스 로직이다.
// withTimeout 설정으로 메시지 처리가 시간을 초과하지 않도록 한다.
withTimeout(process(message), timeout)
// 처리 성공시 ack를 날려준다.
sqs.ack(message)
} catch (e) {
if (e instanceof TimeoutException) {
/* just pass, no need to do something. */
continue
}
// 처리 실패시 nack를 날려준다.
sqs.nack(message)
}
}
}중복 필터링
단 위 코드에서는 비즈니스 로직과 ack 응답을 atomic 하게 묶지 못한다.
따라서 ack가 도달하지 않았을 때 비즈니스 로직이 완료됐는데 ack가 응답하지 않은 것인지, 아니면 비즈니스 로직 자체가 동작하지 않은 것인지 구분할 수단이 필요하다.
따라서 로직이 여러 번 실행되지 않도록 로직 앞에 중복 제거 필터를 사용해야 한다. 이를 Publisher deduplication 라고 한다.
요약 : 메시지가 publish 되다 실패했을 때 메세지가 도달조차 못한 것인지, 도달해 publish까지 성공했지만 response만 실패한 것인지 구분할 수가 없다. 따라서 publisher는 요청을 재시도할 수 밖에 없는데 이를 방지하기 위해 MessageDeduplicationId parameter를 추가할 수 있다.
참고하면 좋을 자료들 & 출처
