List, Set, Map
Java 의 Collection 자료구조에서 List와 Set이 있고, 이 외의 주요 자료구조는 Map이 있다.
List
List는 객체에 인덱스를 부여해 관리하는 선형 자료구조이다.
이때 객체 자체가 아닌 개체의 번지를 저장하는 구조라 동일한 객체를 중복 저장하면 동일한 번지가 저장되고, null 또한 저장이 가능하다.
다음은 List의 주요 메소드이다.
- add(idx, element)
- set(idx,element) : update
- contains(object) : 포함 여부
- get(idx) : 객체 리턴
- isEmpty()
- size()
- clear() : 모두 삭제
- remove(idx)
- remove(object)ArrayList
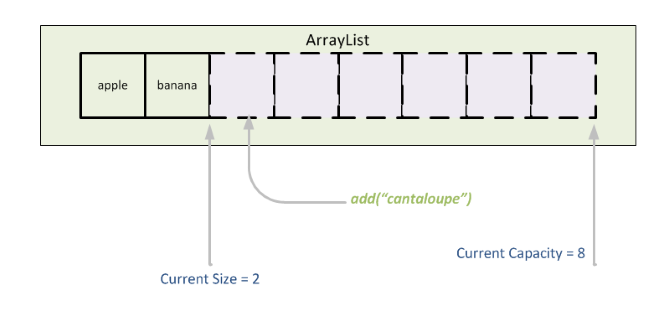
ArrayList는 동적으로 관리할 수 있는 배열이다.
List<E> list = new ArrayList<E>(); //E 타입 리스트
List<E> list = new ArrayList<>(); //동일
List list = new ArrayList(); //모든 타입 객체 저장 그런데 삽입과 삭제가 빈번한 경우에는 ArrayList를 사용하지 않는 것이 바람직하다.
왜냐면 동적 배열의 특성상 중간 요소를 삽입하거나 삭제하면 요소들이 하나씩 뒤로 밀리거나 당겨지기 때문에 O(n)이라는 시간복잡도가 소요되기 때문이다.
다음은 ArrayList의 주요 메소드이다.
Vector
vector은 arraylist와 동일한 내부 구조를 가지고 있으나, 멀티스레드 환경에서 안전하게 객체를 추가 또는 삭제할 수 있다는 장점이 있다.
List<E> list = new Vector<E>(); //E 타입 리스트
List<E> list = new Vector<>(); //동일
List list = new Vector(); //모든 타입 객체 저장LinkedList
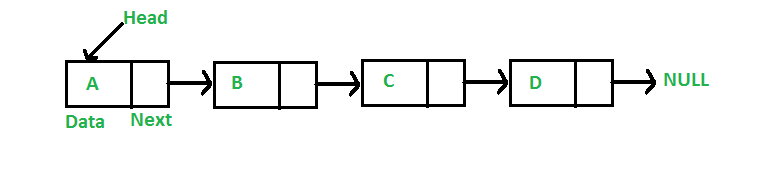
LinkedList는 인접 객체를 체인처럼 연결해서 관리한다.
요소의 추가와 삭제에서는 O(1)로 우수한 성능을 띄지만, 검색과 접근에서는 O(n) 성능을 띈다.
List<E> list = new LinkedList<E>(); //E 타입 리스트
List<E> list = new LinkedList<>(); //동일
List list = new LinkedList(); //모든 타입 객체 저장Set
set은 말그대로 집합이라는 뜻으로써 배열과 달리 저장 순서가 유지되지 않는다. 또 중복해서 저장이 불가하며, 하나의 null만 저장할 수 있다.
HashSet
Set 컬렉션에서 가장 많이 사용되는 것이 HashSet이다.
Set<E> set = new HashSet<E>(); //E타입 set
Set<E> set = new HashSet<>();
Set set = new HashSet(); //모든타입 set 이때 동일한 객체는 중복 저장하지 않는다.
여기서 실제론 다른 객체라 하더라도 hashCode()의 리턴값이 같고 equals() 메소드가 true를 리턴하면 동일한 객체로 취급하고 저장하지 않는다.
TreeSet
TreeSet은 집합을 정렬해서 저장한다.
public class SetTest {
public static void main(String[] args) {
// 순서가 없음
Set<String> s = new HashSet<>();
s.add("홍길동");
s.add("손오공");
s.add("강호동");
s.add("홍길동");
System.out.println(s);
// Set은 순서가 없는데 LinkedHashSet을 사용하면 순서대로 입력 가능
s = new LinkedHashSet<>();
s.add("홍길동");
s.add("손오공");
s.add("강호동");
s.add("홍길동");
System.out.println(s);
// 정렬
s = new TreeSet<>();
s.add("홍길동");
s.add("손오공");
s.add("강호동");
s.add("홍길동");
System.out.println(s);
for(String t : s) System.out.println(t);
}
}Map
map은 키(key)와 값(value)로 구성된 엔트리 객체를 저장한다. 여기서 키와 값은 모두 객체이다. 키는 중복 저장할 수 없지만 값은 중복 저장할 수 있다. 기본에 저장된 키와 동일한 키로 값을 저장하면 기존의 값(value)는 사라지고 새로운 값으로 대체된다.
- HashMap
Map<K, V> map = new HashMap<K, V>();
Map<K, V> map = new HashMap<>();- Hashtable
HashTable은 HashMap과 구조는 같지만 멀티 스레드 환경에서도 안전하게 객체를 추가, 삭제할 수 있다.
Map<K, V> map = new HashTable<K, V>();
Map<K, V> map = new HashTable<>();- TreeMap
TreeMap은 HashMap을 정렬해서 저장한다. - Properties
Properties는 HashTable의 자식 클래스이다. 여기서 HashTable과 차이점은 키와 값이 String 타입으로 제한된다는 점이다.
public class MapTest {
public static void main(String[] args) {
// 순서가 없음
Map<String, Integer> m = new HashMap<>();
m.put("홍길동", 4);
m.put("손오공", 2);
m.put("강호동", 1);
m.put("홍길동", 3);
System.out.println(m);
// 순서
m = new LinkedHashMap<>();
m.put("홍길동", 4);
m.put("손오공", 2);
m.put("강호동", 1);
m.put("홍길동", 3);
System.out.println(m);
// 정렬
m = new TreeMap<>();
m.put("홍길동", 4);
m.put("손오공", 2);
m.put("강호동", 1);
m.put("홍길동", 3);System.out.println(m);
for(Map.Entry<String, Integer> e : m.entrySet()) System.out.println(e);
for(String key : m.keySet()) System.out.println(m.get(key));
for(Integer value : m.values()) System.out.println(value);
}
}