
커넥션 풀(DBCP)이란
다음과 같이 JDBC API를 사용하여 매 연결마다 Connection 객체를 새로 생성하는 것은 비효율적이다.
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
sql = "SELECT * FROM T_BOARD"
// 1. 드라이버 연결 DB 커넥션 객체를 얻음
connection = DriverManager.getConnection(DBURL, DBUSER, DBPASSWORD);
// 2. 쿼리 수행을 위한 PreparedStatement 객체 생성
pstmt = conn.createStatement();
// 3. executeQuery: 쿼리 실행 후
// ResultSet: DB 레코드 ResultSet에 객체에 담김
rs = pstmt.executeQuery(sql);
} catch (Exception e) {
} finally {
conn.close();
pstmt.close();
rs.close();
}
}- Connection 객체를 생성하는 과정
① 애플리케이션에서 DB 드라이버를 통해 커넥션을 조회한다. ② DB 드라이버는 DB와 TCP/IP 커넥션을 연결한다. (3 way handshake와 같은 네트워크 연결 동작 발생) ③ DB 드라이버는 TCP/IP 커넥션이 연결되면 아이디와 패스워드, 기타 부가 정보를 DB에 전달한다. ④ DB는 아이디, 패스워드를 통해 내부 인증을 거친 후 내부에 DB를 생성한다. ⑤ DB는 커넥션 생성이 완료되었다는 응답을 보낸다. ⑥ DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환한다.
따라서 애플리케이션 로딩 시점에 Connection 객체를 미리 생성하고 애플리케이션에서 DB 연결이 필요한 시점에 이를 갖다 쓰게 되었고, 이 생성한 Connection 객체들을 관리하는 곳을 Connection Pool이라 부른다.
커넥션 풀 동작 구조
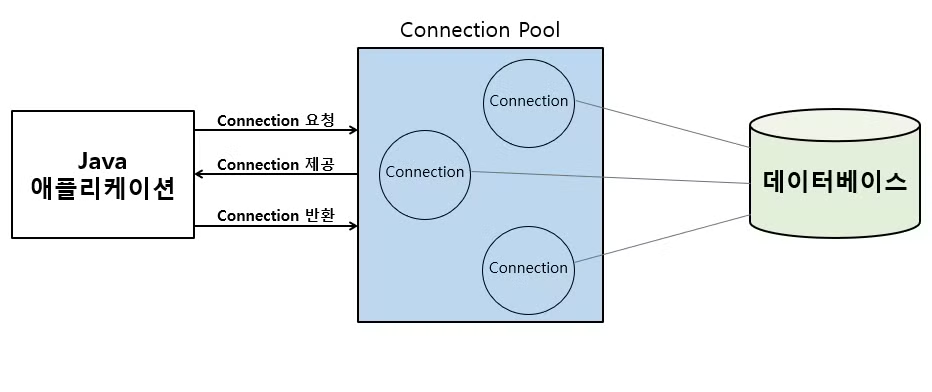
- 애플리케이션을 시작하는 시점에 커넥션 풀은 필요한 만큼의 Connection 객체를 미리 생성해 보관한다.
- 상황에 따라 다르긴 하지만 일반적으로 생성되는 Connection 객체는 10개다.
- 커넥션 풀 내의 Connection 객체는 TCP/IP로 DB와 연결돼잇는 상태기 때문에 즉시 SQL을 DB에 전달할 수 있다. (즉, 이미 생성되어있는 커넥션을 참조해 사용한다는 것)
- 커넥션 풀에 커넥션을 요청하면 커넥션 풀은 자신이 가지고 있는 Connection 객체를 반환한다.
- 객체 임무가 완료되면 다시 Connection Pool로 객체가 반납된다.
커넥션 풀 종류
- commons-dbcp
- tomcat-jdbc-pool
- HikariCP
Spring Boot 2.0 이후부터는 HikariCP를 기본 DBCP로 채택하여 사용되고 있다.
HikariCP는 가벼운 용량과 빠른 속도를 가지는 우수한 성능의 JDBC Connection Pool 프레임워크이다.
HikariCP의 동작 방식
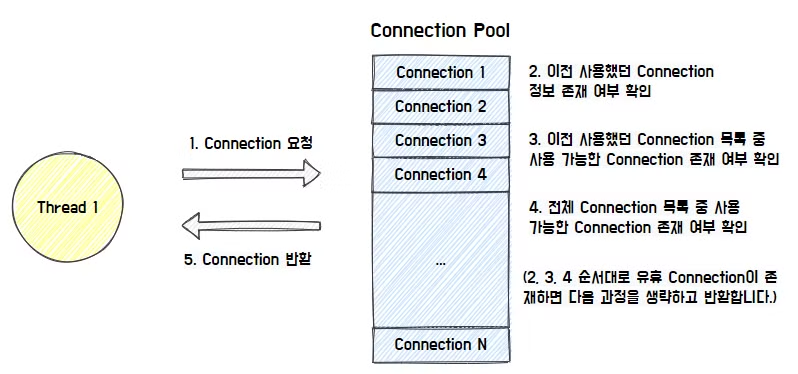
- 쓰레드가 Connection을 요청하면 유휴 Connection 객체를 찾아서 반환한다. HikariCp는 이전에 사용했던 Connection 객체를 우선적으로 반환한다.
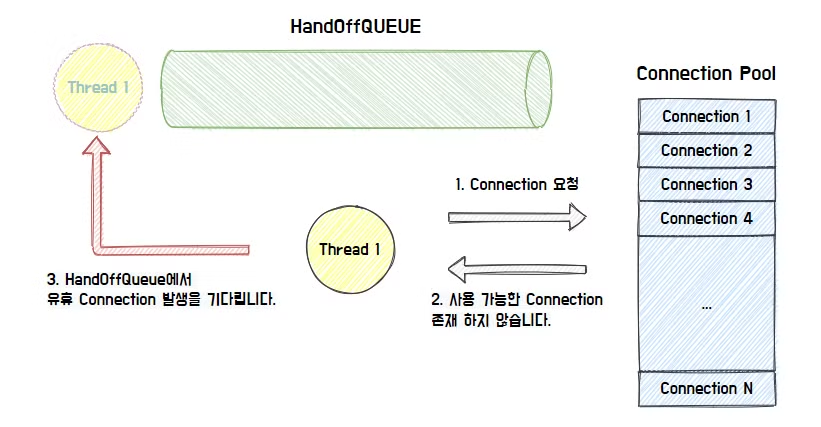
- 가능한 Connection이 존재하지 않으면 HandOffQueue를 Polling 하면서 다른 쓰레드가 Connection을 반납하기를 기다린다. (지정한 TimeOut 시간까지 대기, 초과하면 예외)
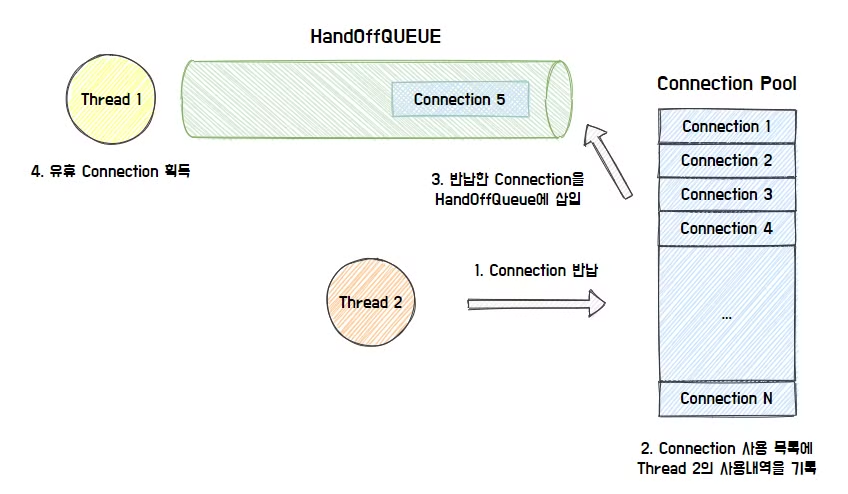
- Connection 객체가 반납되면 Connection Pool이 사용 내역을 기록하고 HandOffQueue에 반납된 Connection 객체를 삽입한다.
- 이를 통해 HandOffQueue를 Polling하던 쓰레드는 Connection 객체를 획득하게 된다.
유휴 Connection 이 존재할 때
유휴 Connection이 존재하지 않을 때
커넥션 풀의 장점
- 재사용으로 인해 생성, 해제에 드는 오버헤드를 크게 줄일 수 있다. (성능 대폭 향상)
- DB Connection 수를 제한할 수 있어 서버 자원 고갈 예방 가능
- DB 서버 환경이 바뀌어도 쉬운 유지보수 가능
커넥션 풀의 특징(유의사항)
- 커넥션 풀의 크기가 크다면 ?
- 메모리 소모가 크지만 많은 사용자의 대기 시간이 줄어든다.
- 커넥션 풀의 크기가 작다면?
- 메모리는 아끼겠지만 사용자의 대기 시간이 늘어난다.
→ 적정 크기를 유지하는 것이 중요
쓰레드 풀과의 관계
- Thread Pool 크기 < Connection Pool 크기
- 쓰레드가 사용하는 Connection 외의 Connection 객체는 메모리만 차지하게 된다.
- Thread Pool 크기 > Connection Pool 크기
- 대기하는 쓰레드가 많아져 대기 시간 증가 (병목 현상)
- Thread Pool의 크기와 Connection Pool의 크기가 모두 증가하면?
- 쓰레드가 증가해 더 많은 문맥교환 (Context Switching) 이 발생한다.
- 쓰레드가 너무 많아지면 I/O 블로킹으로 인해 디스크가 처리할 수 있는 최대 요청량에 도달하고, 실제 성능 향상은 미비해진다. (Disk 경합 측면에서 성능 한계 발생)
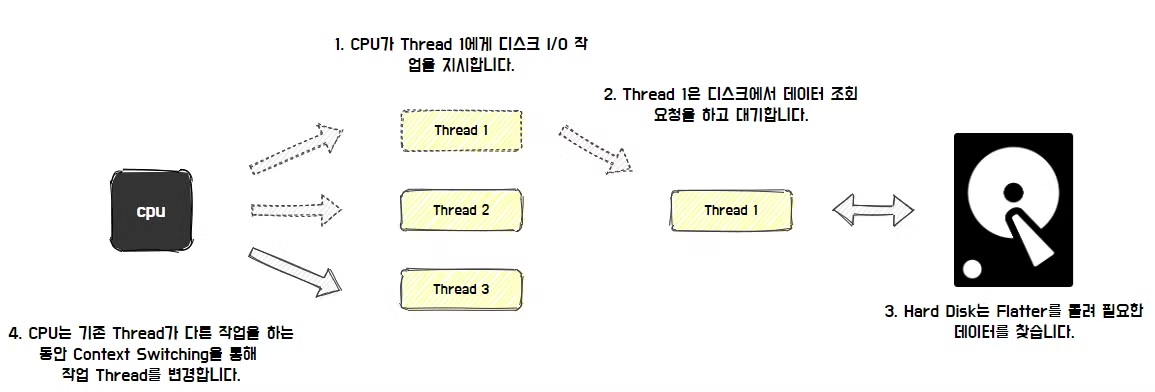
적절한 Connection Pool의 크기는?
- Hikari CP의 공식 문서에 의하면,
1 connections = ((core_count) * 2) + effective_spindle_count)로 정의하고 있다. - 여기서 core_count란 현재 사용하는 서버 환경에서의 CPU 개수를 의미한다.
core_count * 2를 하는 이유는 문맥 교환으로 인한 오버헤드를 고려해도 Disk I/O보다 CPU 속도가 훨씬 빠르기 때문이다.- 따라서 쓰레드가 디스크에서 블로킹되는 시간에 CPU는 다른 쓰레드의 작업을 처리할 수 있는 여유가 생기고, 멀티 쓰레드 작업을 수행할 수 있기 때문에 쓰레드 개수를 코어 수의 2배로 설정하는 것이 성능을 극대화할 수 있다.
effective_spindle_count는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수이다.- 하드 디스크는 하나의 spindle을 가지며 디스크가 16개 있다면 시스템은 동시에 16개 I/O 요청을 처리할 수 있다.

좋아하는 걸로 밥 벌어먹기