지도학습은 크게 분류와 회귀로 나뉜다.
회귀란 두 변수 사이의 상관관계를 분석하는 방법이라고 한다.
K-최근접 이웃
최근접이웃을 그림으로 표현하면 다음과 같다.
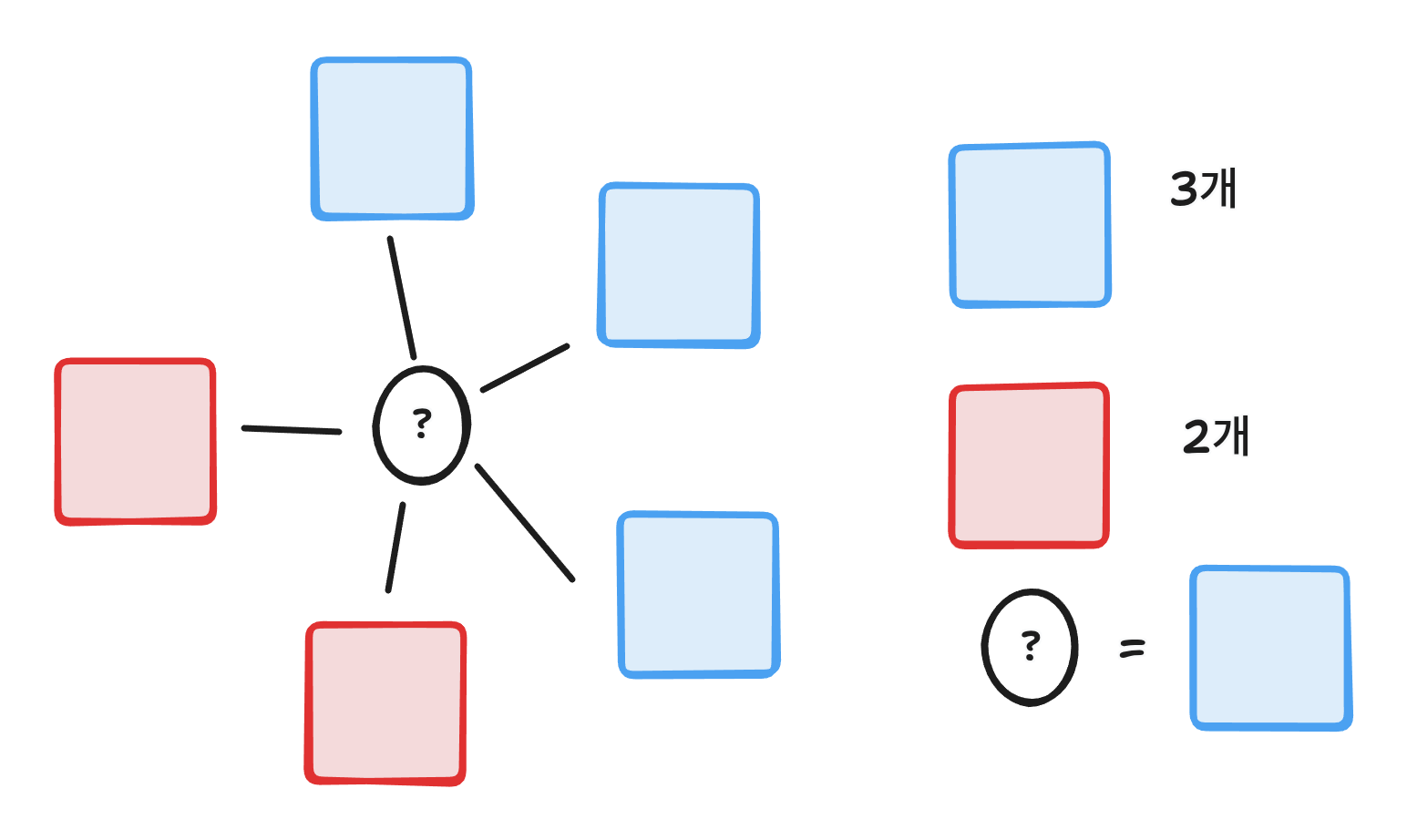
k가 5개라고 했을 때 샘플을 기준으로 가까운 데이터 5개를 추출하고 가장 많은 클래스를 값으로 선택한다.
하지만 이것은 분류고 회귀로 표현한다면 같은 방식이지만 이것을 수치로 나타낸다.
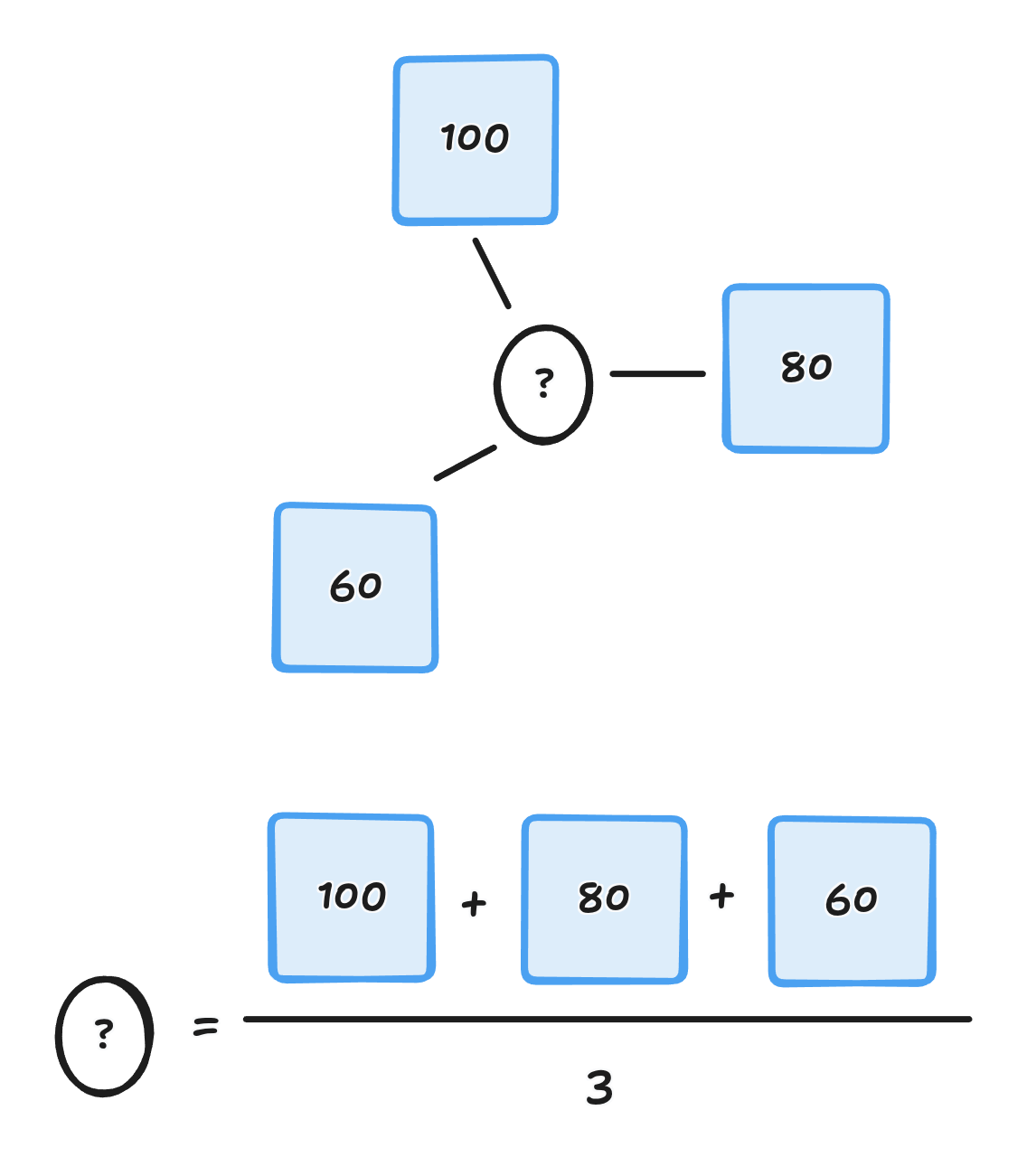
구현
데이터
산점도
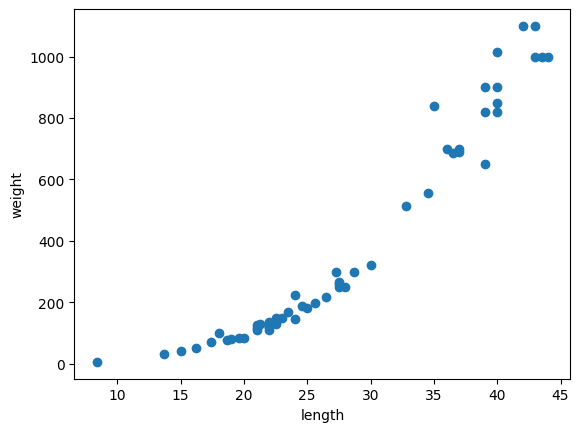
이것을 보면 길이(무게)가 늘어남에 따라 무게(길이)가 늘어나는 것을 알 수 있다.
데이터 분리
from sklearn.model_selection import train_test_split
# 데이터 분리
X_train, y_train, X_test, y_test = train_test_split(
perch_length,
perch_weight,
random_state=42
)
print(X_train.shape, y_train.shape)
# (42,) (14,)
# 차원 변경
X_train = X_train.reshape(-1, 1)
y_train = y_train.reshape(-1, 1)
print(X_train.shape, y_train.shape)
# (42, 1) (14, 1)train_test_split으로 데이터를 분리하고 reshape을 통해 1차원 배열이였던 것을 2차원 형태로 변환한다.
결정 계수
이제 K-최근접 이웃으로 모델을 훈련하고 예측해보자.
from sklearn.neighbors import KNeighborsRegressor
# 모델 불러오기
knr = KNeighborsRegressor()
# 학습
knr.fit(X_train, X_test)
# 훈련 데이터 정확도
print(knr.score(X_train, X_test))
# 0.9698823289099254
# 테스트 데이터 정확도
print(knr.score(y_train, y_test))
# 0.992809406101064회귀에서 정확도를 평가하는 방식을 결정계수라고 하며, 간단하게는 이라고 부른다.
의 계산식은 다음과 같다.
이번에는 평균 절댓값 오차를 평균하여 계산해보자.
from sklearn.metrics import mean_absolute_error
# 테스트 세트에 대한 예측
test_prediction = knr.predict(y_train)
# 평균 절대값 오차 계산
mae = mean_absolute_error(y_test, test_prediction)
print(mae)
# 19.157142857142862이것은 오차가 19정도 난다는 것을 위미한다.
과대적합과 과소적합
학습 데이터로 훈련을 했기 때문에 기본적으로 점수를 계산해보면 테스트 데이터보다 훈련 데이터에서 정확도가 높게 나온다.
하지만 만약 훈련 데이터에서는 높은 정확도가 나오지만 테스트데이터에서 너무 낮은 데이터가 나온다면 데이터가 훈련 데이터에만 맞춰졌고 이것을 과대적합이라고 한다.
만약 테스트 점수가 더 높거나 둘 다 너무 낮은 점수가 나온다면 과소적합이라고 한다.
현재 K-최근접 이웃은 훈련 데이터 정확도보다 테스트 데이터 정확도가 더 높은 과소적합 상태다.
이것을 해결하기 위해 기본값이 5인 K값을 3로 감소시켰다.
# K 값 감소
knr.n_neighbors = 3
# 훈련 데이터 훈련
knr.fit(X_train, X_test)
# 훈련 데이터 정확도
print(knr.score(X_train, X_test))
# 0.9804899950518966
# 테스트 데이터 정확도
print(knr.score(y_train, y_test))
# 0.9746459963987609과소 적합이 해결되었다.

코딩 공부하는 사람