데이터 가져옥
keras를 이용하여 MNIST 데이터를 가져온다.
import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
# (60000, 28, 28) (60000,)현재 데이터는 60000만장, 28*28로 구성되어 있다.
샘플을 확인해 보자.

현재 타깃 값의 종류는 이렇게 되어있다.
| 레이블 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 패션 아이템 | 티셔츠 | 바지 | 스웨터 | 드레스 | 코트 | 샌달 | 셔츠 | 스니커즈 | 가방 | 앵클 부츠 |
그리고 각 레이블의 개수는 6000개씩 있다.
로지스틱 회귀로 분류하기
정규화
각 픽셀은 0~255 사이의 숫자로 이루어져 있다.
이것을 0~1 사이의 숫자로 정규화 한다.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)학습
경사하강법으로 학습해봤다.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
# 0.8194166666666666인공 신경망
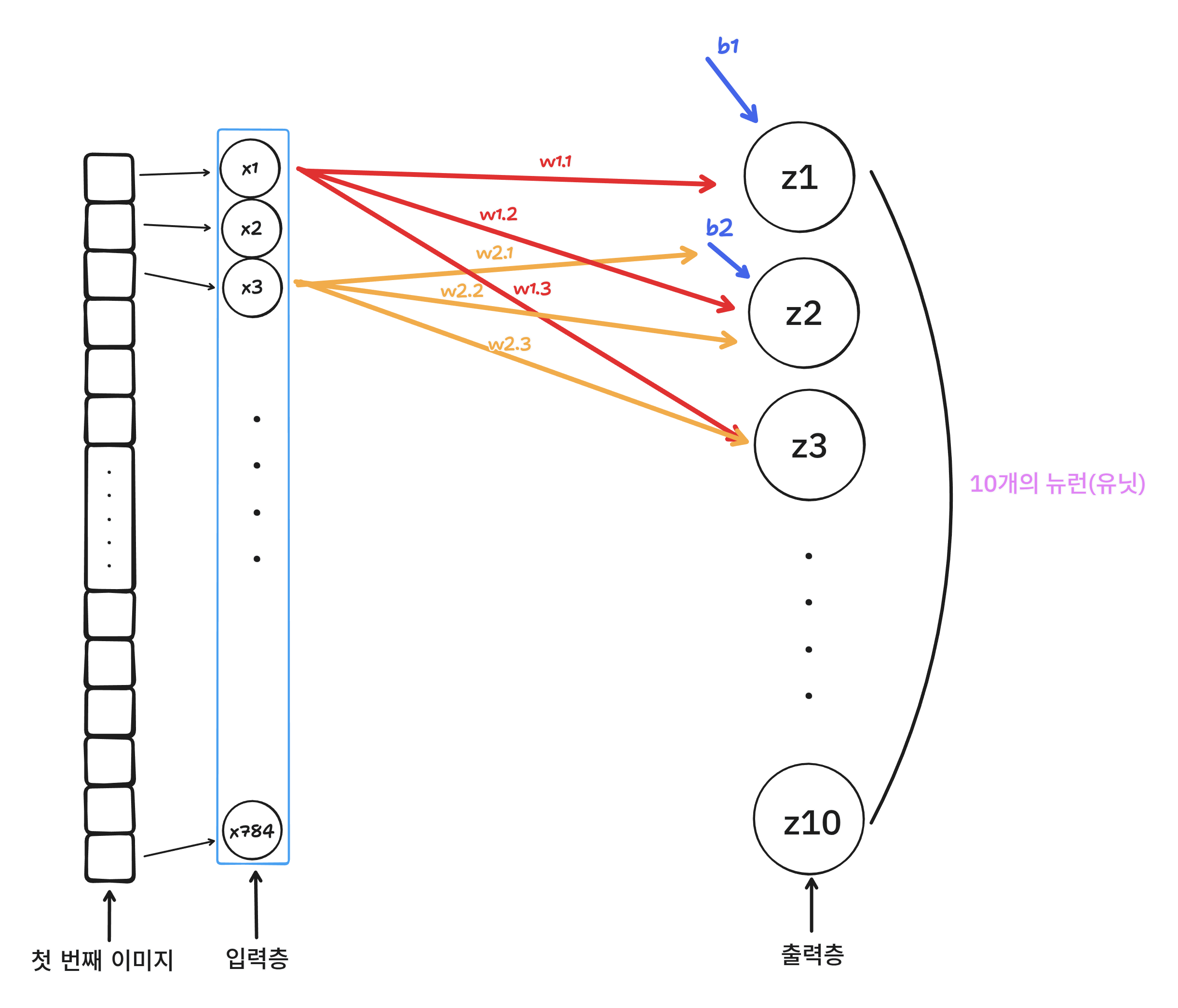
위 그림은 로지스틱 회귀를 그림으로 표현한 것이다.
인공 신경망에서 z 값을 계산한는 단위를 뉴런(유닛)이라고 한다.
그리고 우리가 사용할 이미지의 픽셀(784개)를 입력층이라고 한다.
그리고 우리가 분류할 라벨을 출력층이라고 한다.
이것은 생물학적 뉴련에서 영감을 얻어 만들어졌다.

딥러닝과 인공 신경망은 거의 동의어를 사용한다. 심층 신경망(deep neural netwrk,DNN)을 딥러닝이라고 부른다.
케라스 사용하기
# 입력 데이터(사진 1장에 784 픽셀)
inputs = keras.layers.Input(shape=(784,))현재 28*28 이미지를 1차원으로 784개로 사용하고 있기 때문에 (784, )와 같이 배열의 크기로 지정함.
신경망에서 가장 기본이 되는 층은 밀집층(dense layer)다.
784개의 픽셀을 10개의 뉴런과 모두 연결한다. 그러면 7840개의 선이 생기기 때문에 밀집이라고 이야기 한다.
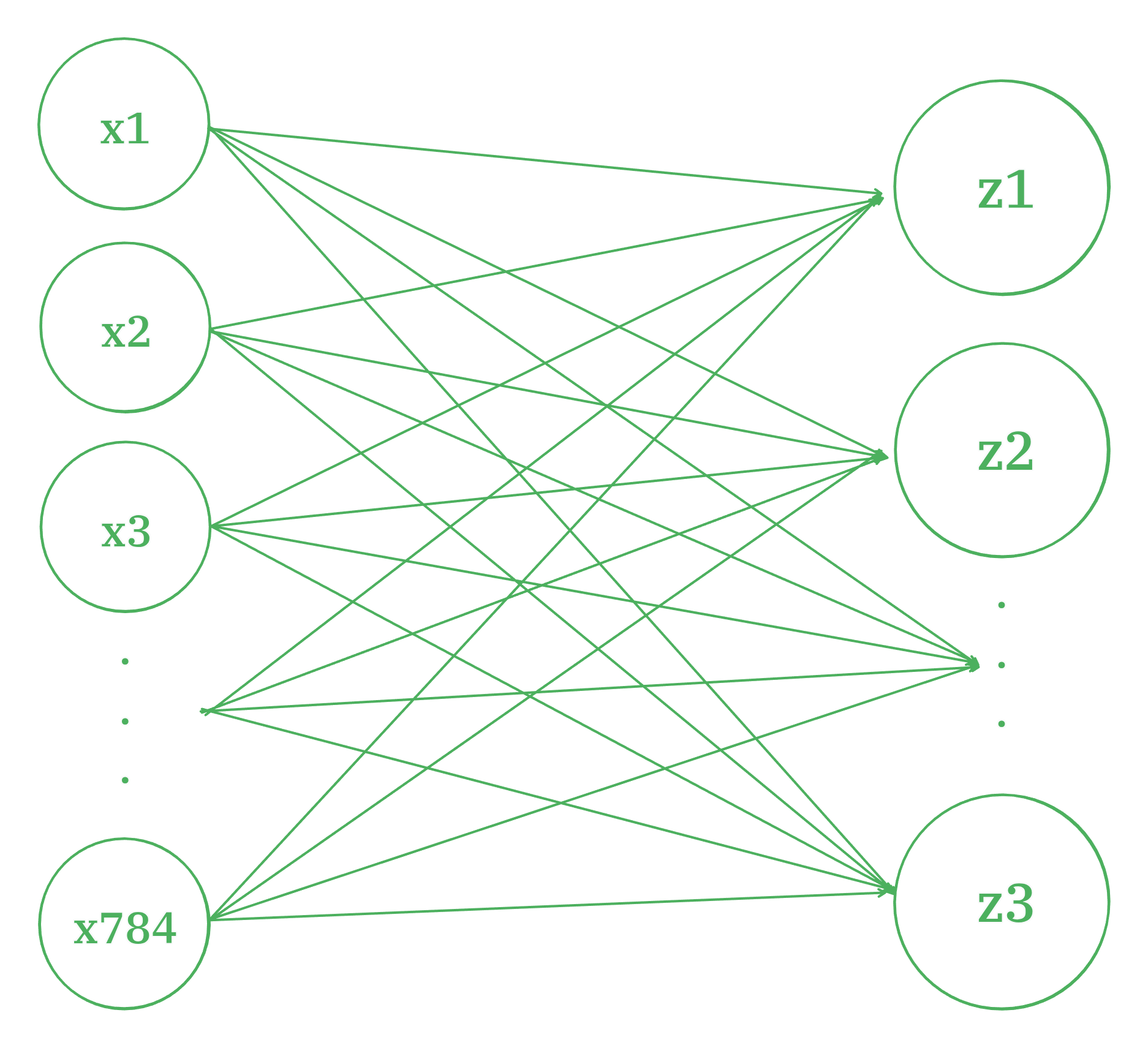
이렇게 양쪽 뉴런이 모두 연결되어있는 것을 완전 연결층이라고 한다.
dense = keras.layers.Dense(
10, # 출력 노드 개수
activation='softmax', # 출력에 적용할 함수
)10개의 아이템을 분류하기 때문에 출력 노드의 개수를 10으로 지정한다.
분류가 목적이기 때문에 softmax를 사용한다.
만약 이진분류(2개의 클래스)인 경우에는 sigmoid를 사용한다.
이제 신경망 모델을 만들기 때문에 Sequential 클래스를 사용한다.
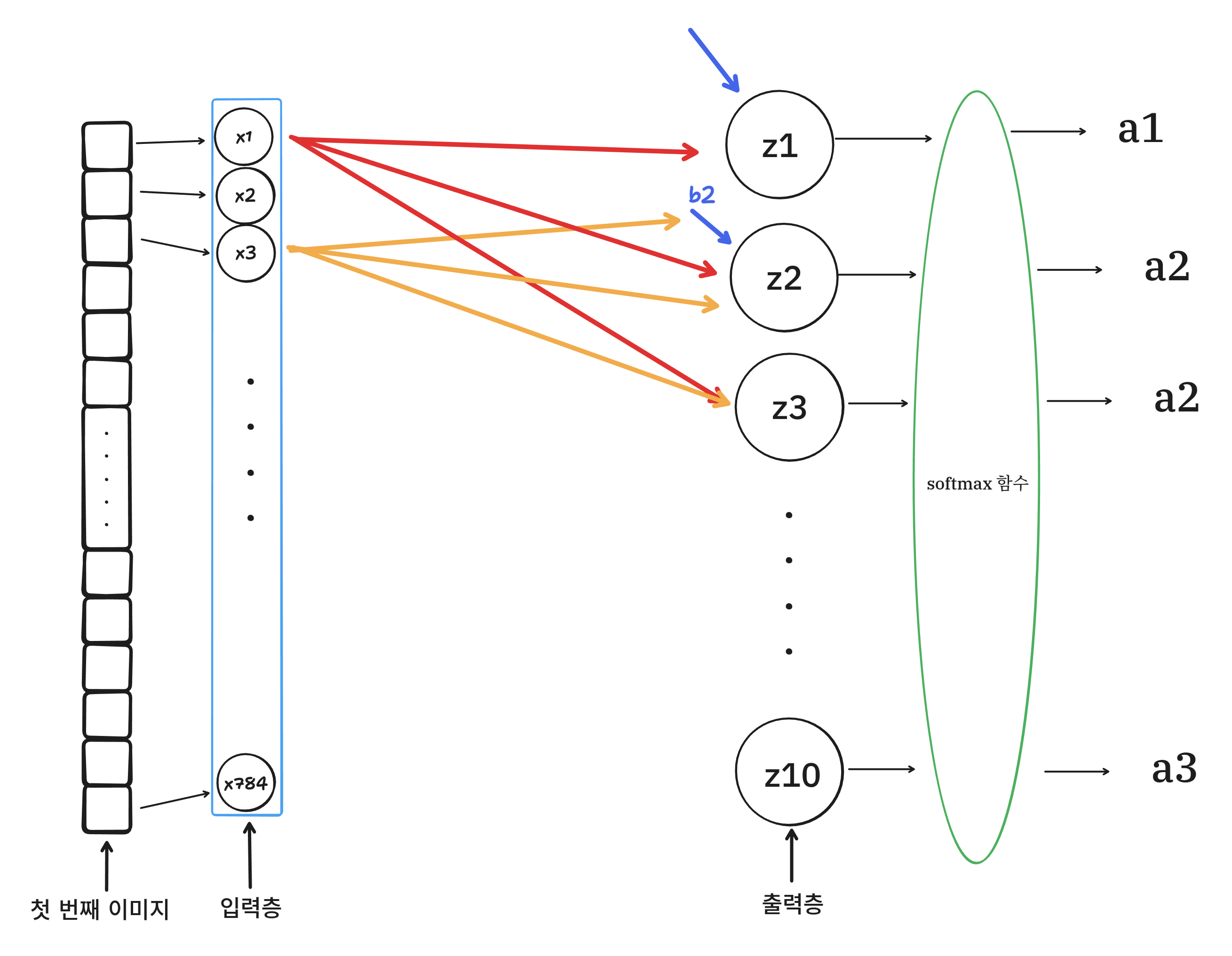
이제 훈련하기 전에 설정 단계가 있다.
model.compile(
loss='sparse_categorical_crossentoropy',
metrics=['accuracy']
)이진 분류: binary_crossentropy
다중 분류: categorical_crossentropy
sparse?
그리고 앞에 sparse라는 말이 붙은 이유는 이진 크로스 엔트로피 손실 계산식을 봐야 한다.
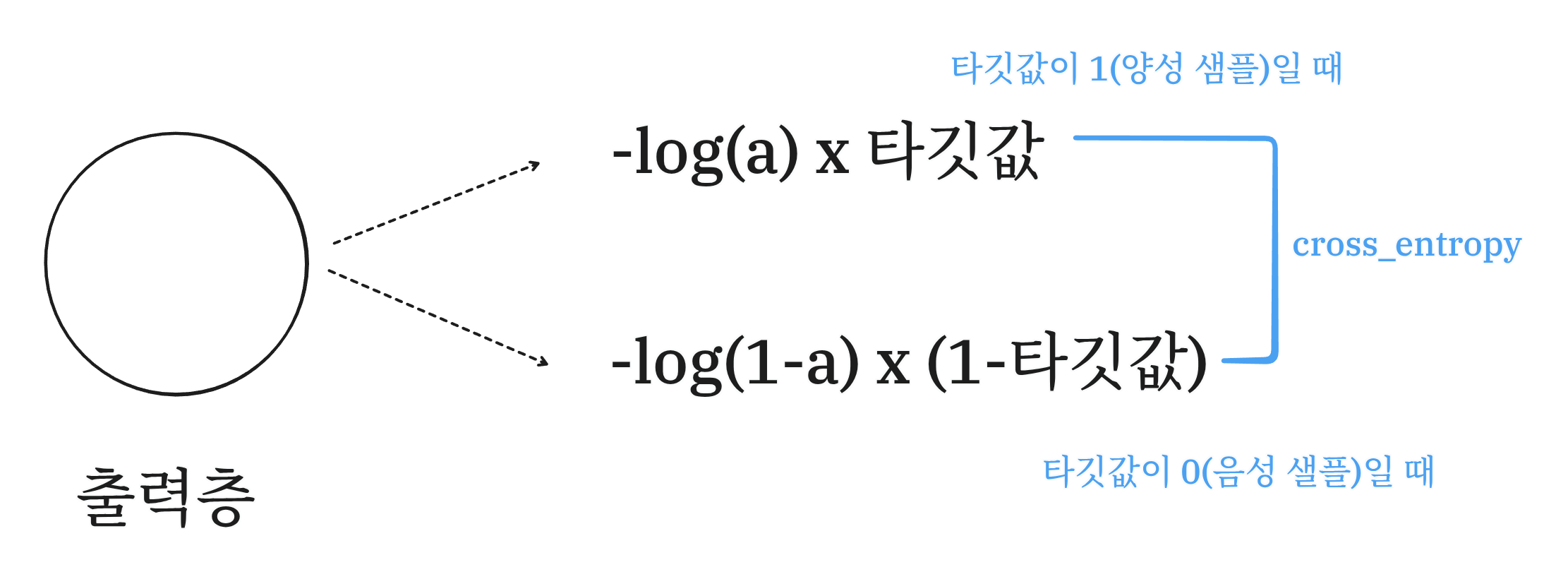
이진 분류에서는 출력층의 뉴련이 하나만 나온다.
이 뉴런값이 출력하는 확률값 a(시그모이드 함수 출력값)을 사용해 크로스 엔트로피를 계산한다.
이진 분류에서는 간단하게 양성은 1, 음성은 1-타깃값으로 계산한다.
그러면 다중 분류에서는 어떻게 계산될까.
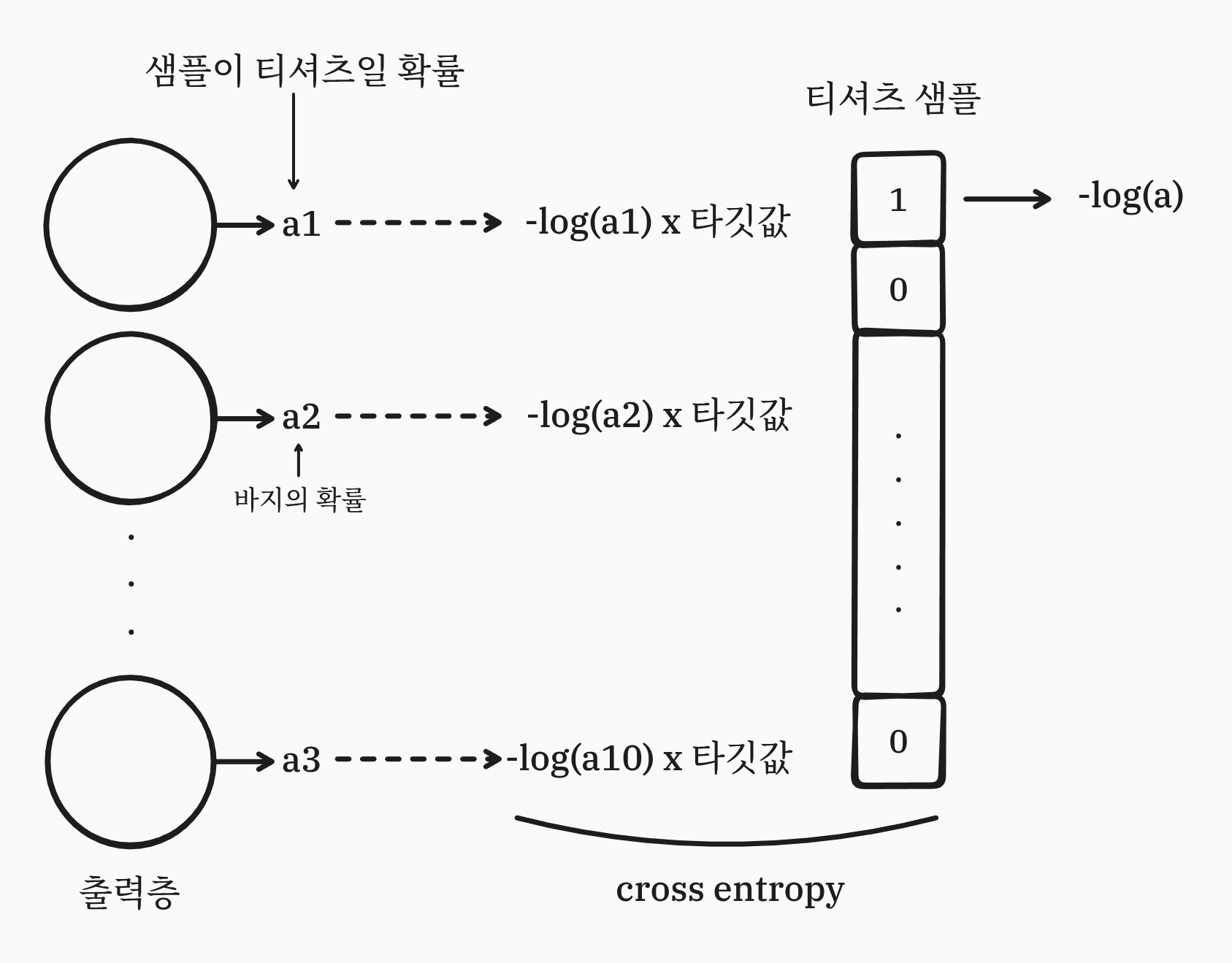
이렇게 되며 셜국 티셔츠 샘플의 타깃값은 첫 번째 원소만 1, 나머지는 0으로 나온다.
이것을 출력층의 활성화 값의 배열과 곱한다.
이러면 동등한 위치의 원소값만 1이되고 나머지는 0이 넘는다.
이렇게 타기값을 해당 클래스만 1이고 나머지를 0으로 채우는 배열을 원-핫-인코딩(one-hot-encoding)이라고 한다.
그리고 현재 MNIST의 타깃값은
으로 되어있다.
케라스에서는 이것을 굳이 원-핫-인코딩을 하지 않고 사용할 수 있는데, 이때 정수로된 타깃값을 이용하여 cross_entropy를 계산하는 것이 바로 sparse_categorical_crossentropy다.
만약 원-핫-인코딩을 했다면 sparse를 제거한 categorical_crossentropy가 된다.
model.fit(
train_scaled, # input
train_target, # 타깃값
epochs=5 # 학습 횟수
)Epoch 1/5
1875/1875 [==============================] - 2s 990us/step - loss: 0.5827 - accuracy: 0.8034
Epoch 2/5
1875/1875 [==============================] - 2s 883us/step - loss: 0.4658 - accuracy: 0.8418
Epoch 3/5
1875/1875 [==============================] - 2s 958us/step - loss: 0.4443 - accuracy: 0.8494
Epoch 4/5
1875/1875 [==============================] - 2s 985us/step - loss: 0.4340 - accuracy: 0.8537
Epoch 5/5
1875/1875 [==============================] - 2s 952us/step - loss: 0.4256 - accuracy: 0.8567성능을 평가할 대는 evaluate()를 사용한다.
test_scaled = test_input / 255.0
test_scaled = test_scaled.reshape(-1, 28*28)
model.evaluate(test_scaled, test_target)
# [0.47275468707084656, 0.8410999774932861]테스트 값도 비슷한걸 보니 과적합이나 과소적합이 안일어난것 같다.
