로지스틱 회귀
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
"""
alcohol: 알코올 도수
sugar: 당도
pH: pH값
class: 레드와인(0), 화이트 와인(1)
"""
wine.head()| alcohol | sugar | pH | class | |
|---|---|---|---|---|
| 0 | 9.4 | 1.9 | 3.51 | 0.0 |
| 1 | 9.8 | 2.6 | 3.20 | 0.0 |
| 2 | 9.8 | 2.3 | 3.26 | 0.0 |
| 3 | 9.8 | 1.9 | 3.16 | 0.0 |
| 4 | 9.4 | 1.9 | 3.51 | 0.0 |
wine.info()| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | alcohol | 6497 non-null | float64 |
| 1 | sugar | 6497 non-null | float64 |
| 2 | pH | 6497 non-null | float64 |
| 3 | class | 6497 non-null | float64 |
wine.describe()| alcohol | sugar | pH | class | ||
|---|---|---|---|---|---|
| count | 6497.000000 | 6497.000000 | 6497.000000 | 6497.000000 | |
| 평균 | mean | 10.491801 | 5.443235 | 3.218501 | 0.753886 |
| 표준편차 | std | 1.192712 | 4.757804 | 0.160787 | 0.430779 |
| 최소 | min | 8.000000 | 0.600000 | 2.720000 | 0.000000 |
| 1사분위수 | 25% | 9.500000 | 1.800000 | 3.110000 | 1.000000 |
| 중간값/2사분위수 | 50% | 10.300000 | 3.000000 | 3.210000 | 1.000000 |
| 3사분위수 | 75% | 11.300000 | 8.100000 | 3.320000 | 1.000000 |
| 최대 | max | 14.900000 | 65.800000 | 4.010000 | 1.000000 |
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
data = wine[['alcohol', 'sugar', 'pH']]
target = wine['class']
X_train, y_train, X_test, y_test = train_test_split(data, target, random_state=42)
ss = StandardScaler()
ss.fit(X_train)
X_train_scaled = ss.transform(X_train)
y_train_scaled = ss.transform(y_train)
lr = LogisticRegression()
lr.fit(X_train_scaled, X_test)
print(lr.score(X_train_scaled, X_test)) # 0.7859195402298851
print(lr.score(y_train_scaled, y_test)) # 0.7655384615384615결정 트리
결정 트리는 이유를 설명하기 쉽다.
지속적인 질문을 통해 분류하는 방식이다.
와인을 예로 들어보았을 때
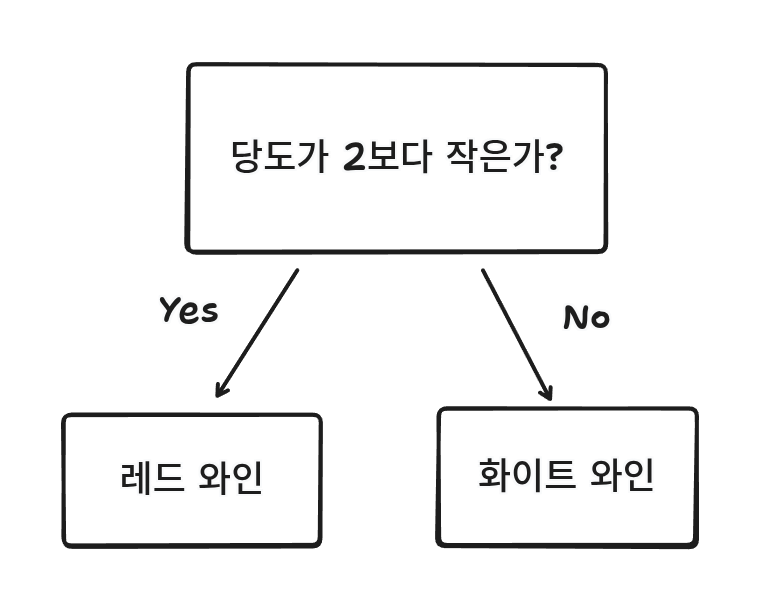
이런 느낌이다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
dt = DecisionTreeClassifier(random_state=42)
dt.fit(X_train_scaled, X_test)
print(dt.score(X_train_scaled, X_test)) # 0.9973316912972086
print(dt.score(y_train_scaled, y_test)) # 0.8516923076923076
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
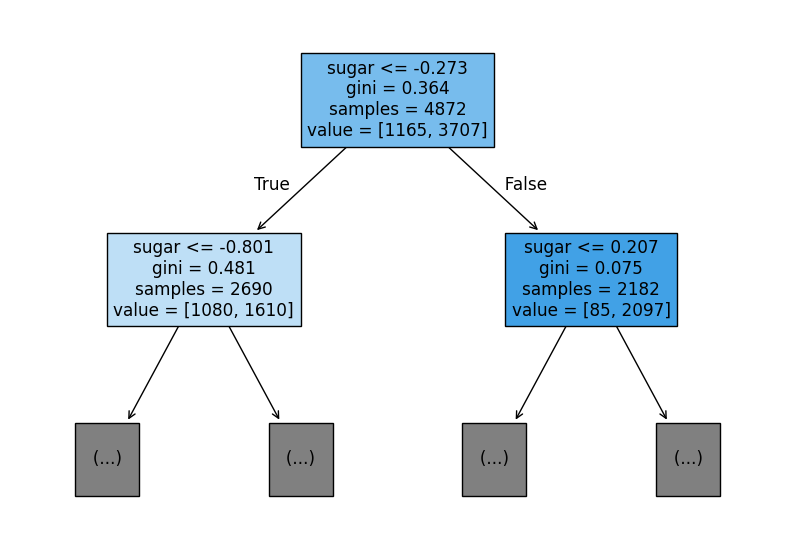
이런식으로 분류가 되는데 어떤 조건으로 분류 되는지 알 수 있다.
value에서 해당 조건이 만족한 데이터가 1165, 만족하지 않은 데이터가 3707개가 있다는 의미다.
그리고 상자 안에 있는 gini는 지니 불순도를 의미한다.
만약 노드에 하나의 클래스만 있다면 지니 불순도는 0이 된다.
이런 노드를 순수 노드라고 부른다.
이런 부모의 자식 노드 사이의 불순도 차이를 정보 이득이라고 부른다.
가지치기
나무를 가지치기 하듯이 결정 트리에도 가지치기를 하면 좋다.
max_depth가 그 역할을 한다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(X_train_scaled, X_test)
print(dt.score(X_train_scaled, X_test)) # 0.8499589490968801
print(dt.score(y_train_scaled, y_test)) # 0.8363076923076923훈련 점수는 낮아졌지만 테스트 점수는 큰 차이가 없다.
그리고 결정 트리에서는 어떤 특성이 가장 유용한지 계산해준다.
dt.feature_importances_
# [0.12871631, 0.86213285, 0.00915084]2번째 특성인 당도가 87%로 가장 중요하다.

코딩 공부하는 사람