Logistic Regression에 대해 정리하고, 모델을 작성해본다.
Logistic Regression이란?
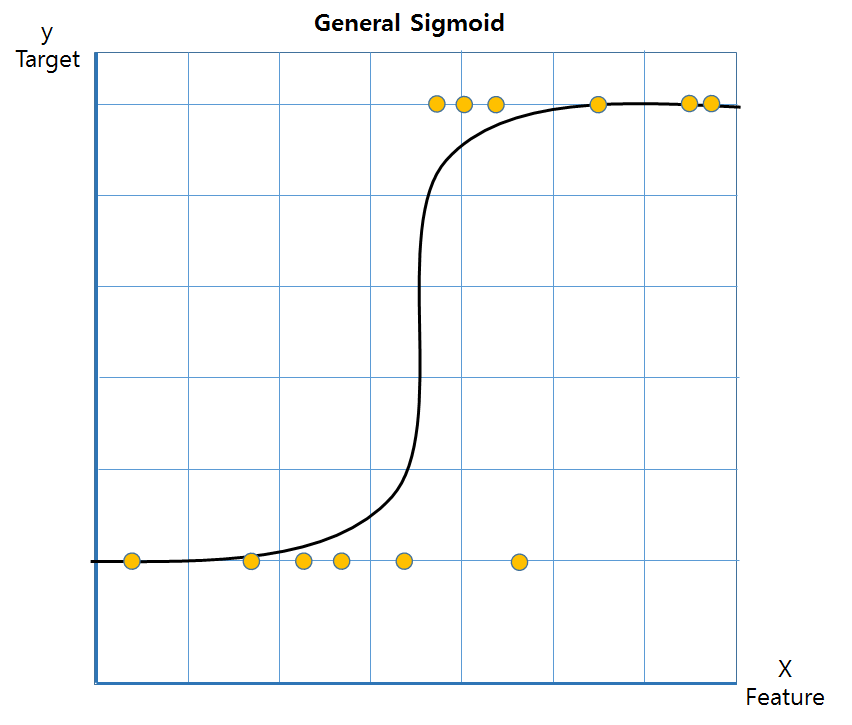
분류 문제(Classification)를 해결하기 위해 사용하는 모델로, S자 모양을 취하는 시그모이드 함수를 비용함수로 사용한다.
px = 1/ 1+exp^1(선형회귀RSS)로 표현되며, 타켓값 0 또는 1과 같이 두 가지 중 하나를 예측할 때 사용한다.
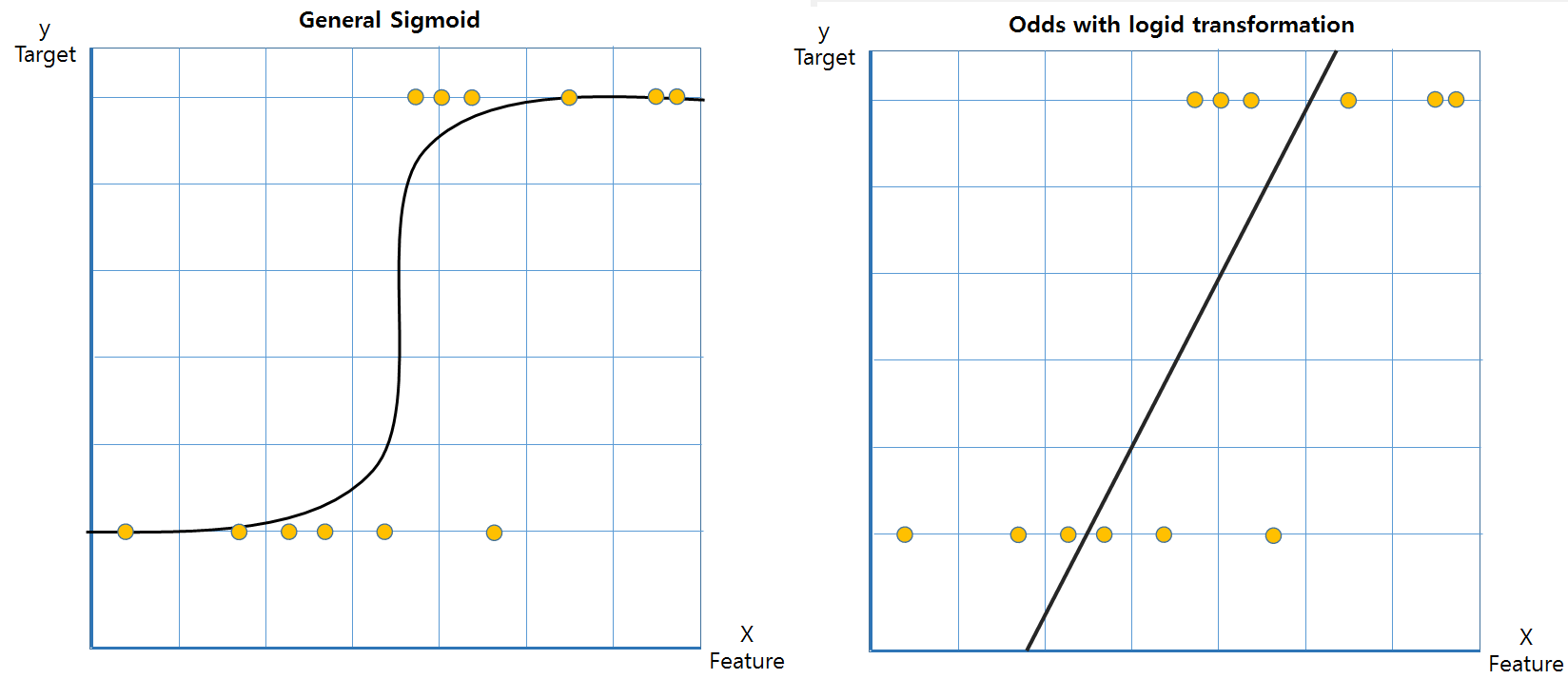
로지스틱회귀는 비선형임에도 회귀라고 표현한다. 그 이유는 오즈(odds)를 사용했을 때, 선형결합으로 변환해서 이에 대한 해석을 할 수 있기 때문이다.
Logistic Regression의 요소 (오즈비와 로짓변환)
오즈(odds):
로 실패확률 대비 성공확률의 비율을 뜻한다. odds가 2이면 성공확률이 실패확률의 2배이고, 3번 중 1번 실패할때 두번 성공한다는 뜻이다.
로짓(logid):
odds에 log를 취한 것으로 수식을 풀면 로 풀리게 된다.
y target이 0 ~1까지 정해져있고, S자로 비선형이었던 모델을 선형으로 변환하면서 y target의 범위가 ~ 로 넓어진다.
로지스틱 회귀 모델작성
import seaborn as sns
# 데이터셋 불러오기 - 온천 이용시간
df = sns.load_dataset('geyser')
df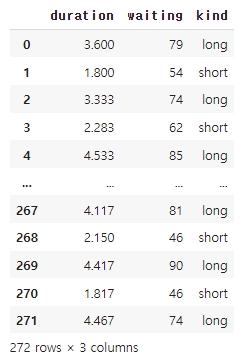
# target 선정 - 이진분류 long / short 중 하나를 예측
target = 'kind'from sklearn.model_selection import train_test_split
# 검증을 위해 train, test 셋을 나눈다.
df_train, df_test = train_test_split(df, test_size = 0.2, random_state = 5)
# feature와 target으로 분할한다.
features = df.drop(columns = [target]).columns
X_train = df_train[features]
y_train = df_train[target]
X_test = df_test[features]
y_test = df_test[target]from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 로지스틱회귀 진행
logid = LogisticRegression(max_iter = 500)
logid.fit(X_train, y_train)
# 회귀모델을 Test set에 적용해 예측해본다.
print('정확도:', logid.score(X_test, y_test))정확도: 1.0온천에서 이용한 시간 / 기다린 시간 / 이용시간의 구분(long/short)으로 구분된 간단한 데이터셋으로 로지스틱 회귀 모델을 구현했다.
정확도가 1이 나왔는데, 일반적으로 이 정도 수치면 data leakage(유출)을 의심 해봐야 하지만, 예측이 쉬운 데이터여서 그렇다.
다른 데이터로 한번 더 해보겠다.
(여기서 'max_iter = ' Gradient Descent 방식으로 최적의 해를 구하는 하이퍼 파라미터로 일정 수준이상이 되면 수렴되어 더이상 오르지 않는다.)
# 데이터셋 불러오기 - 붓꽃 종류별 데이터
df1 = sns.load_dataset('iris')
df1['species'].unique()# target 선정 - 이진분류 setosa / others 중 하나를 예측
target1 = 'species'
# target을 1로 변경하고 나머지 종은 0으로 한다.
df1['species'] = [1 if i == 'versicolor' else 0 for i in df1['species']]
df1.head()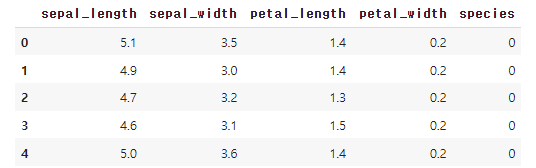
iris 데이터를 불러왔고, 맨 마지막 species column을 타깃으로 'versicolor' 종을 찾는 이진분류를 진행한다.
간단한 전처리로 species column의 versicolor는 1, 나머지들은 0으로 치환해서 모델링한다.
# 검증을 위해 train, test 셋을 나눈다.
df1_train, df1_test = train_test_split(df1, test_size = 0.5, random_state = 5)
# feature와 target으로 분할한다.
features1 = df1.drop(columns = [target1]).columns
X_train1 = df1_train[features1]
y_train1 = df1_train[target1]
X_test1 = df1_test[features1]
y_test1 = df1_test[target1]
# 로지스틱회귀 진행
logid1 = LogisticRegression(max_iter = 500)
logid1.fit(X_train1, y_train1)
# 회귀모델을 Test set에 적용해 예측해본다.
print('정확도:', logid1.score(X_test1, y_test1))정확도: 0.6666666666666666이번엔 정확도가 66.67% 정도로 출력이 되었다. 작성한 모델이 versicolor인것과 아닌것을 맞출 확률로 해석할 수 있다.
사실 여담으로 다른 두개의 종으로 모델을 돌리면 정확도가 1.0이 나왔는데, 이는 versicolor를 제외한 두 가지 종이 비슷하기 때문임을 알 수 있다. 이와 관련된 것은 나중에 차차 알아보도록 한다.
