SQL[sqlite]- Visual Studio Code를 이용한 python 연동, DB툴 활용(Dbeaver)
DATABASE, DB란?
데이터베이스란 사전적 의미로 공유되어 사용되기 위해 관리되는 데이터들의 집합을 의미하며, 데이터 사이언스에서 문제에 대한 해결을 위해 필요한 정보들을 효율적으로 관리 및 수집하여 이용할 수 있다.
SQL(Structured Query Language)
구조적 질의문이라고 하여 데이터베이스 내에서 테이블을 정의하거나, 데이터를 조작하고, 조회 및 권한 부여를 할 수 있는 질의어이다. MYSQL, ORACLE 등 여러가지 DB엔진에 따라 다 조금씩 차이가 있는데, 전체적인 문법 자체는 모두 비슷하다.
SQLITE3
다양한 SQL 중 Python3 package 설치 시 함께 설치되는 FILE 기반 DB엔진이다.
특징 1. 매우 가볍다.
- 고급 쿼리문이나 기타 복잡한 구조 및 조건의 쿼리문에 동작하지 못하는 제한적인 성능을 보인다.
- 다른 SQL에 비해 좋은 성능을 보이지는 못하지만, 이를 이용해 개발 단계에서 간단하고 가벼운 실험을 하기에 좋다.
특징 2. File형 SQL이다.
- 다른 SQL들과는 달리 분리된 서버가 없이 FILE형으로 응용프로그램에 적용해 사용하는 SQL
- 위의 이유로, 삭제 또는 프로세스 종료로 인한 정보손실이 될 수 있는 단점을 가진다.
python으로 sqlite3 사용하기
DB 툴에 연결을 해서 보면 보다 직관적으로 DATA를 이해할 수 있지만, 그렇지 않은경우 CLI나 VSCODE 환경을 통해 SQLITE3를 이용할 수 있다.
DB FILE 생성 및 연결하기 - 1(터미널 환경)

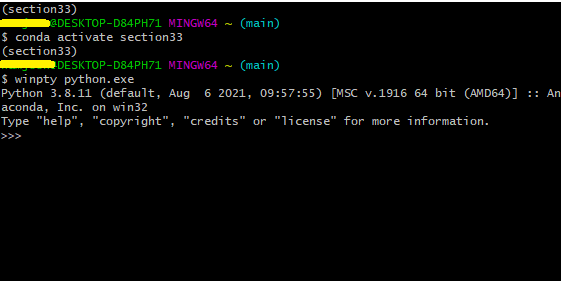
1) 터미널에서 python을 활성화시킨다.
일반 CLI 파워쉘에서나 VSCODE에서나 터미널에 python을 입력하면 위 이미지와 같이 >>> 커맨더가 나오면서 파이썬이 활성화가 된다.
(windows의 경우 먹통이 될 때가 있는데, winpty python.exe로 실행 가능하다.)
anaconda 환경을 이용하는 경우 가상 환경을 활성화 한 상태에서 python을 실행한다.
2) Sqlite3 import 및 DB 생성/연결하기(Connect)
>>> import sqlite3 # SQLITE3 패키지 import
>>> conn = sqlite3.connect('new_db.db') # new_db라는 database 생성 및 연결객체 conn 선언[out put]
<sqlite3.Connection object at 0x0000028B54782300>
위와 같이 python 활성화 상태에서 sqlite3 패키지를 불러오고, 새로 만들고자 하는 db file을 넣어 connect하면 텅 빈 새로운 db가 생성된다. 이 상태에서 쿼리문을 입력하면 해당 DB에 대한 데이터를 조작하거나 생성 등을 할 수 있다. .close()되기 전까지 DB 연결이 지속된다.
3) 쿼리문 작성하기(Cursor)
ORACLE이나 MYSQL 등과 기본 문법이 크게 다르지 않지만, python에서 사용하는 만큼 python의 Rule은 지켜서 사용해야 한다.
기본적으로 DB와의 연결 구조상에서 DB와의 connection이 되었으면, Cursor에서 SQL문을 실행하고, 그 결과를 row by row로 읽어낸다.
쿼리문 > cursor > DB 의 구조를 띈다고 볼 수 있다.
3-1) TABLE 생성 (DDL - CREATE)
# 지난 연결객체 conn에 대한 curcor객체를 생성해 cur에 넣는다.
>>> cur = conn.cursor()
# cur를 통해 execute 함수를 사용해 텅빈 DB에 새로운 TABLE을 생성했다.
>>> cur.execute("CREATE TABLE test(name VARCHAR(25), age INT);")[out put]
<sqlite3.Cursor object at 0x0000028B54922DC0>>>>python을 이용해 쿼리문을 실행할 때엔 connection 객체로 DB와의 연결을, cursor 객체로 쿼리문 실행 및 전달을 진행하게 된다. 이후에 cursor의 execute 함수를 통해 quote(' or ")를 통해 쿼리문을 전달한다.
위의 코드 예시에서 name column과 age column을 가지는 test라는 이름의 TABLE을 CREATE를 통해 생성해봤다.
(주의: 쿼리문은 모두 대문자로 작성해야한다.)
3-2) FIELD 추가 (DML - INSERT)
>>> cur.execute("INSERT INTO test(name, age) VALUES('son', 30);") [out put]
<sqlite3.Cursor object at 0x0000028B54922DC0>테이블 생성시와 마찬가지로 cur.execute()를 통해 INSERT로 데이터를 추가했다. 조금 다른 방법으로, python의 변수 선언을 통해 삽입을 해보도록 한다.
# 축구선수 5명의 이름과 나이를 각각 TUPLE로 묶어놓은 것을 LIST에 넣어 변수 선언
>>> players = [('kane',29),('foden',22),('kdb',31),('grealish',27),('ronaldo',36)]
# for문을 통해 VALUES의 ?, ?인자에 각각 한 row씩 삽입되도록 한다.
>>> for i in players:
... cur.execute("INSERT INTO test(name, age) VALUES(?, ?);", i)<sqlite3.Cursor object at 0x0000028B54922DC0>
<sqlite3.Cursor object at 0x0000028B54922DC0>
<sqlite3.Cursor object at 0x0000028B54922DC0>
<sqlite3.Cursor object at 0x0000028B54922DC0>
<sqlite3.Cursor object at 0x0000028B54922DC0>player 변수에 각 name과 age가 들어있는 tuple 5개를 list에 넣어 반복문(for)을 이용해 만들어놓았던 test TABLE에 넣어놓았다.
VALUES의 값을 뒤의 변수로 대체하여 삽입문의 가독성을 높일 수 있다.
3-3) 데이터 조회하기 (DML - SELECT, fetch)
# SELECT문을 이용해 29세 이상인 선수의 전체 정보를 가져온다.
>>> cur.execute("SELECT * FROM test WHERE age >= 29;")[out put]
<sqlite3.Cursor object at 0x0000028B54922DC0>cur.execute를 통해 일반적인 쿼리문으로 터미널에서 SELECT문을 진행했는데, 결과가 그저 객체가 활성화된 내용밖에 없다. 이제 fetch를 통해 불러온다.
- fetchone() 데이터 리스트의 첫행을 출력한다.
- fetchmany(n) 데이터 리스트 중 처음부터 n개 만큼의 행을 출력한다.
- fetchall() 전체를 출력한다.
# 커서에 쿼리문으로 요청한 데이터의 전체를 가져와본다.
>>> cur.fetchall()[out put]
[('son', 30), ('kane', 29), ('kdb', 31), ('ronaldo', 36)]fetchall()을 사용해서 전체 select문의 내용을 출력해보니 29세 이상의 선수들 리스트가 잘 출력 된 것을 알 수 있다.
4) 커밋과 되돌리기 (commit과 rollback)
>>> conn.commit()COMMIT은 python 연동시에도 필수요소인데, 특히 기존 DB에서 data를 조회만 한 것이 아니라, 약간의 수정을 했을 경우에 이를 DB에 적용하기 위해선 꼭 COMMIT을 진행해야한다. connect 개체의 commit을 통해 최종적으로 DB의 갱신을 만들어낸다.
ROLLBACK은 SQLITE3에서 COMMIT 이후엔 이전 상태로 돌릴 순 없지만, COMMIT을 하지 않았다면, 최종 COMMIT 시점으로 되돌린다.
DB FILE 생성 및 연결하기 - 2(dbeaver DB 툴)
1) Dbeaver를 설치 및 실행한다.
2) 터미널에서 python을 활성화하여 DB를 생성한다.
위와 동일하게 미리 터미널에서 connect를 진행한다. 포인트는 새로운 DB를 생성하는 것이다.
3) Dbeaver GUI 환경에서 다시 connect한다.
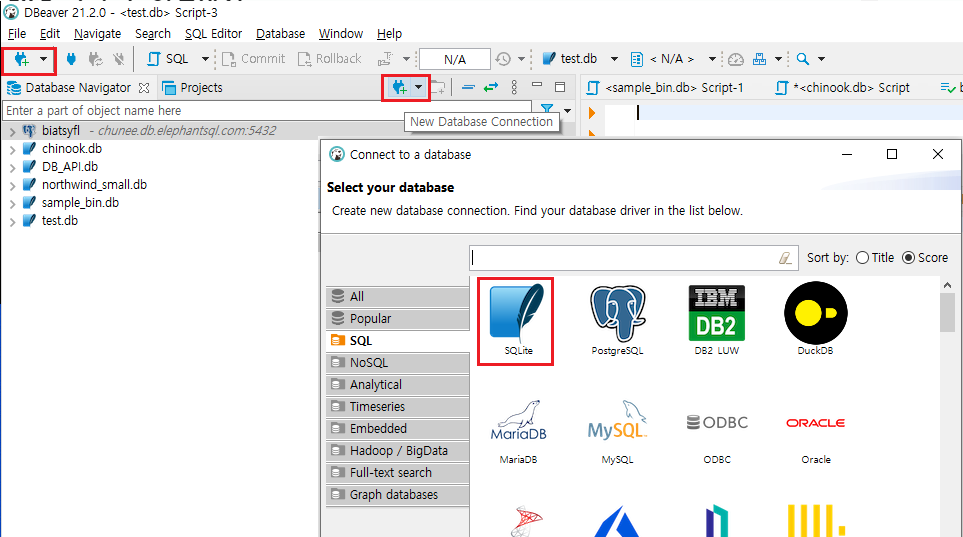
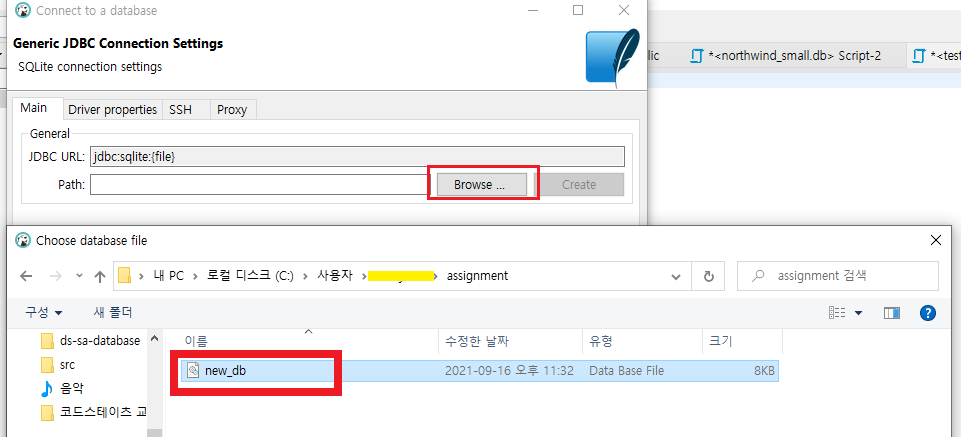
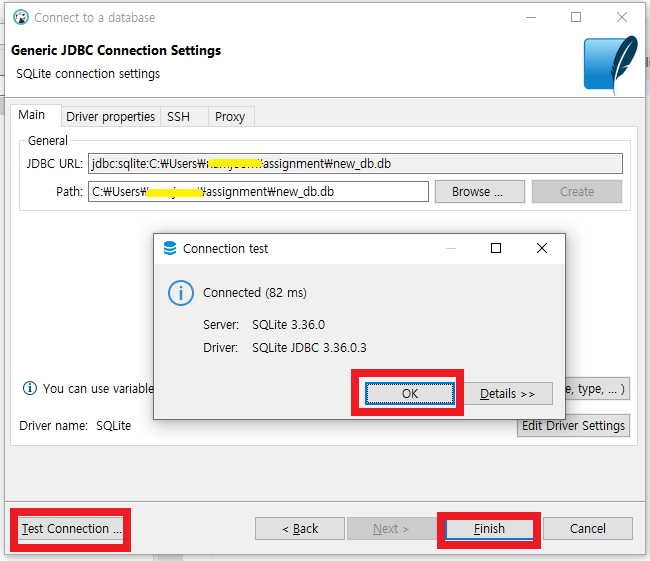
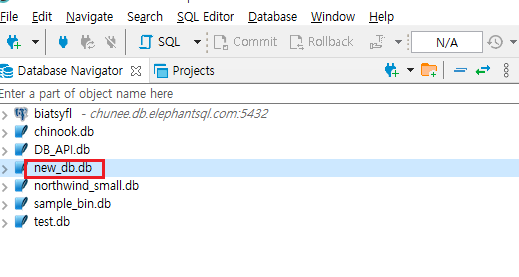
위와 같이 db를 생성한 폴터로부터 연결을 시작하고, Test Connection도 문제가 없다면 최종적으로 Database Navigator 창에 등록한 db가 뜬다.
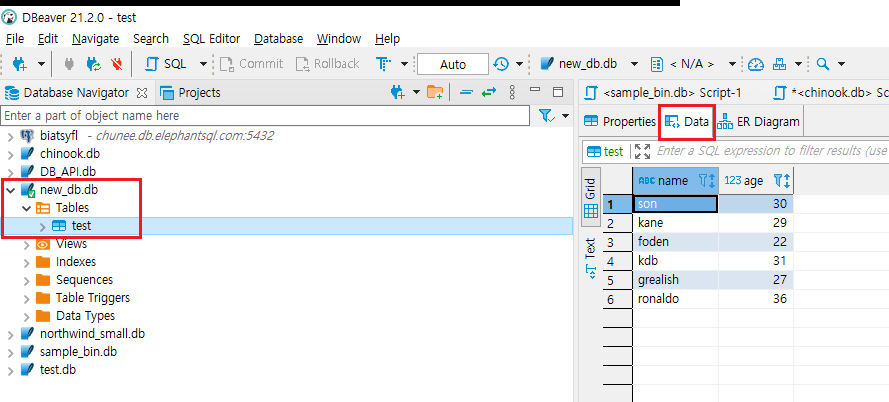
DB Navigator에서 해당 DB를 더블클릭하거나 위에서 PLUG 아이콘을 누르면 연결이 되고, TABLE의 test TABLE을 확인했을 때, insert 해뒀던 데이터들이 잘 commit되어 들어가있는 것을 볼 수 있다.
4) SQL 질의문을 통해 GUI에서의 직관적인 데이터 조회를 진행한다.
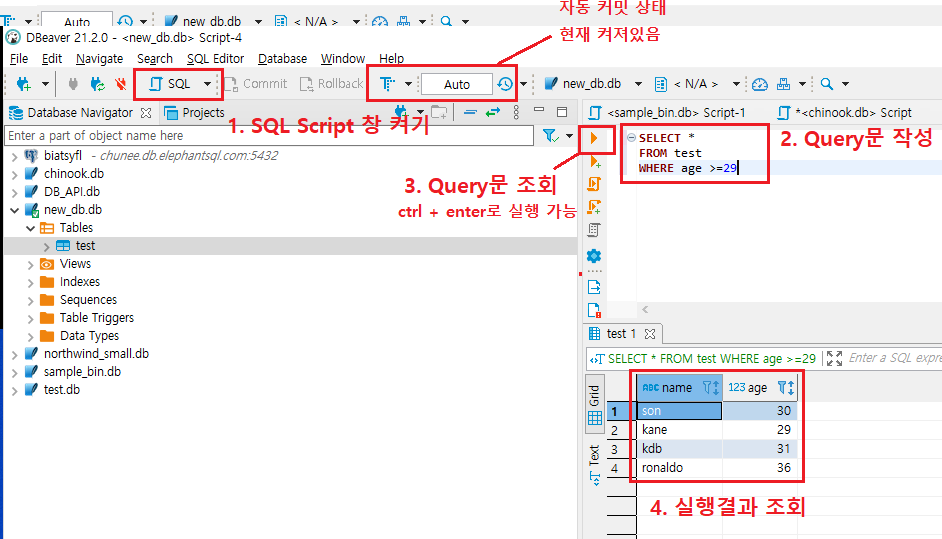
위와같이 순서대로 진행을 했을 때, 문제없이 결과가 나오는 것을 알 수 있다. 위에 터미널에서 진행했을 때보다 훨씬 더 직관적으로 파악이 가능해서 DB를 이용할 수 있다면 이용하는 것이 효율적일 수 있다.
