WEB SCRAPING - [PYTHON]웹 스크래핑 방법 정리, 실습 (requests / beautifulsoup)
웹 데이터 필요성
- 데이터 분석을 위해선 자료 수집이 우선 되어야 분석진행이 가능하다.
- 모든 자료를 수기로 만들 수는 없기 때문에 자료를 페이지에서 불러오는 웹스크래핑 방법이 필요하다.
웹 스크래핑과 크롤링
1. 웹 스크래핑(WEB SCRAPING): web page 내에서 필요한 부분의 정보를 가져오는 방법.
python의 requests와 beautifulsoup 패키지를 통해 진행이 가능하다.
2. 웹 크롤링(WEB CRAWLING): 말 그대로 web page 이곳저곳을 기어다니면서 정보를 자동을 가져오는 방법이다.
python의 selenium 패키지를 통해 진행 가능하다.
동적 크롤링과 정적 크롤링
1. 동적 크롤링: web page 내에서 click, enter등을 통해 계속해서 움직이면서 여러가지 정보를 습득한다.
2. 정적 크롤링: web page 내에서 특별한 움직임을 요하지 않고, 필요한 부분의 정보를 습득한다. 웹 스크래핑이 이 정적 크롤링에 해당한다.
python web scraping 진행 준비
1. requests package
python 환경에서 reqeust libarary를 통해 해당 WEB PAGE의 내용을 요청을 하면 SERVER로부터 RESPONSE 객체를 받게 된다.
import requests
from bs4 import BeautifulSoup
url = 'https://www.google.com/'
resp = requests.get(url)
print(resp)
print(type(resp))
# response 객체를 text로 출력하는 방법 - 지저분하고 data가 많아 주석처리
# print(resp.text) [output]
<Response [200]>
<class 'requests.models.Response'>① get method를 통해 google.com의 web page 정보를 요청
② 그에 따른 response 객체를 resp 변수에 담아서 print로 출력
③ 페이지를 불러오는데에 성공을 의미하는 response code 200을 반환한다.
④ resp의 type은 requests에 따른 response 객체타입으로 반환된다.
⑤ .text를 통해 해당 response 객체의 내용을 text로 표시할 수 있다. 하지만 데이터가 너무 많고 지저분하게 출력되므로 출력은 생략한다.
requests는 get과 post 등 여러가지 methods가 있지만, 웹 스크래핑을 위한 내용이므로 get에 대해서만 취급하겠다.
2. beautiful soup package
BeautifulSoup은 위와같이 반환된 response 객체에 대한 내용을 조금은 더 보기좋게 interface 역할을 해주는 패키지이다.
import requests
from bs4 import BeautifulSoup
url = 'https://www.google.com/'
resp = requests.get(url)
soup = BeautifulSoup(resp.content, 'html.parser')
print(soup)① response 객체를 담은 resp의 content를 타깃으로 beautiful soup패키지를 이용해 html.parser로 파싱을 진행한다. html.parser는 python 기본 parser이며, lxml 등 기타 패키지를 따로 설치해 사용해도 된다.
② Jupyter notebook, Colab 환경에서 돌려보면 알 수 있는데, 훨씬 더 정돈된 느낌으로 정보를 확인할 수 있다.
3. 필요한 정보 위치 파악하기
웹 브라우저의 개발자 도구를 통해 추출할 내용의 위치를 먼저 파악해야한다.
원하는 추출정보의 위치에서 마우스 우클릭 > 검사 또는 F12 를 통해 개발자도구를 활성화한다.
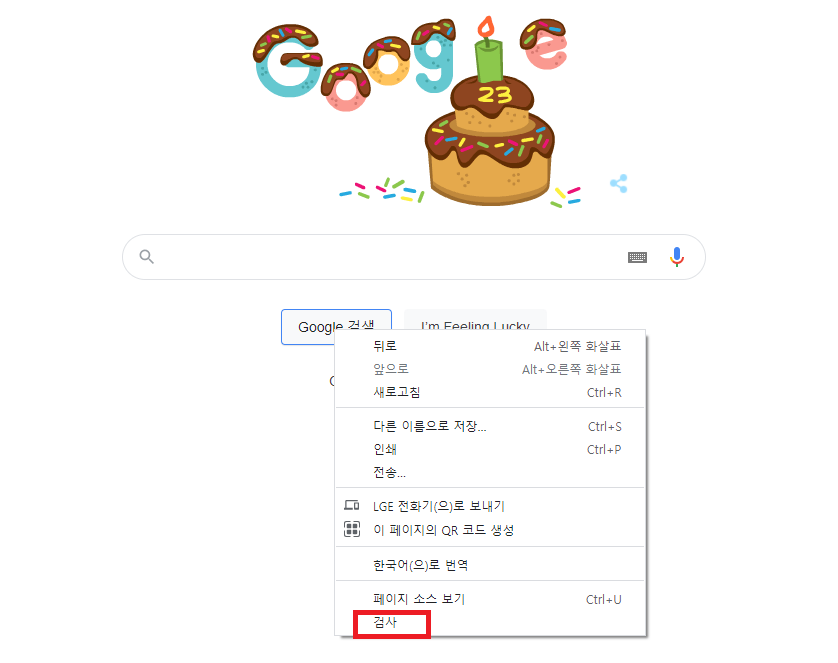
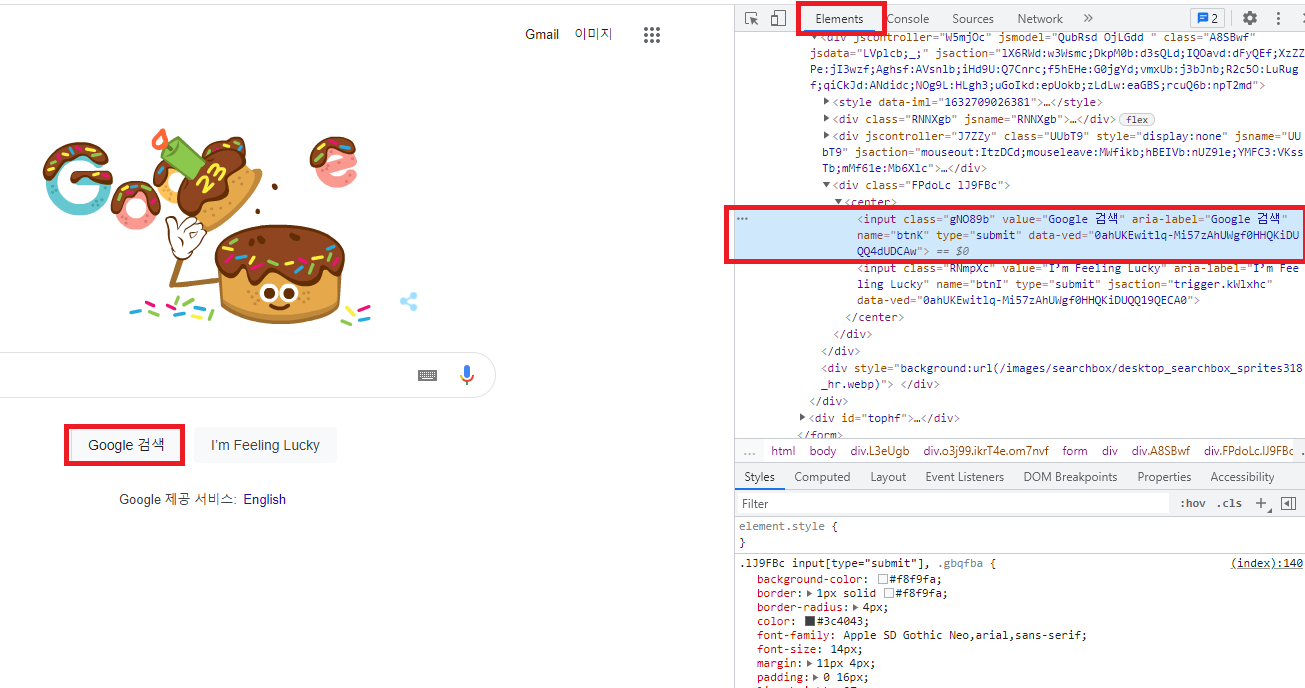
- 마우스 우클릭 > 검사를 진행하게 되면, 원하는 부분에 대한 TAG, CLASS, ID 정보의 위치를 확인할 수 있다.
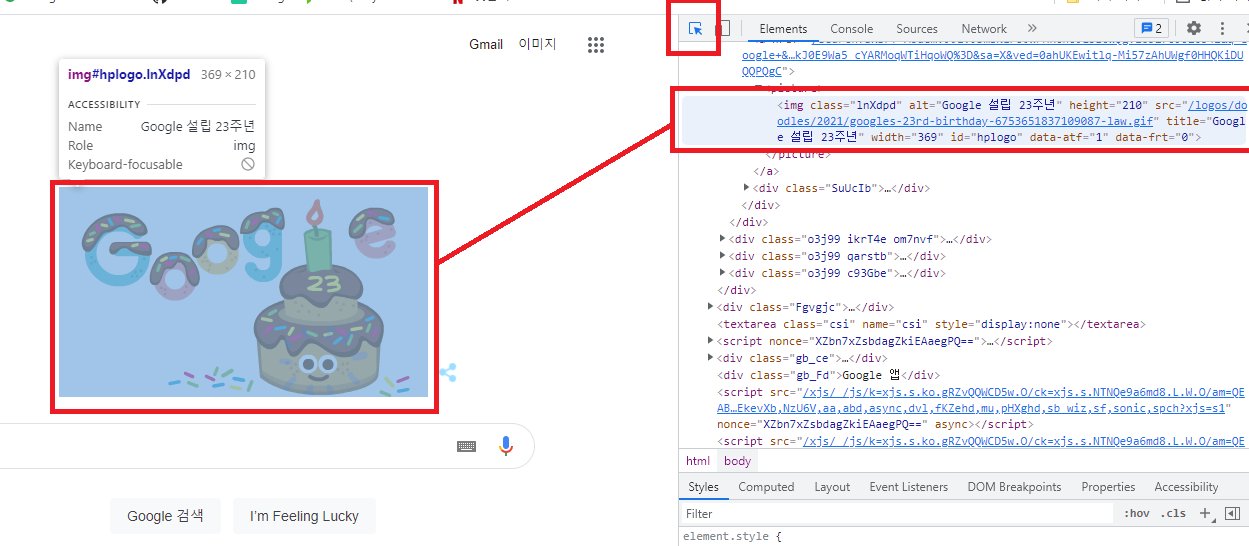
- F12 버튼으로도 개발자 도구를 실행할 수 있다.
좌측 상단의 inspection 아이콘을 클릭하거나 ctrl+shift+c를 누른 뒤 원하는 부분에 마우스를 옮겨보면 해당하는 tag 위치를 볼 수 있도록 옮겨준다.
find를 이용한 내용추출
r1 = soup.find('strong')
r = soup.find_all('strong')
print(type(r1))
print(type(r))[out put]
<class 'bs4.element.Tag'>
<class 'bs4.element.ResultSet'>find(): 해당하는 element 중 가장 먼저 출력되는 요소 element.Tag타입으로 반환
find_all(): 해당하는 전체 elements ResultSet타입으로 반환
1. tag를 이용한 data 찾기
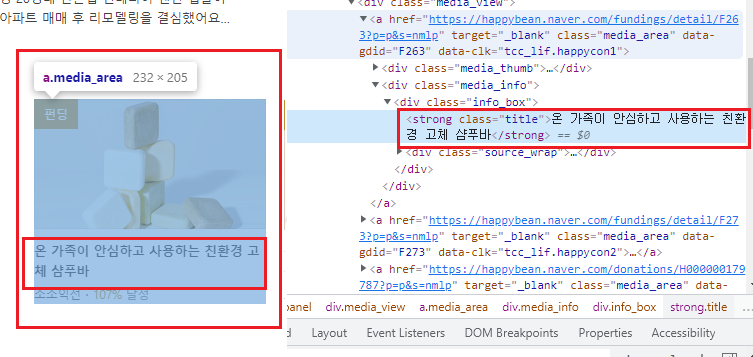
url = 'https://www.naver.com/'
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
r = soup.find_all('strong')
print(r)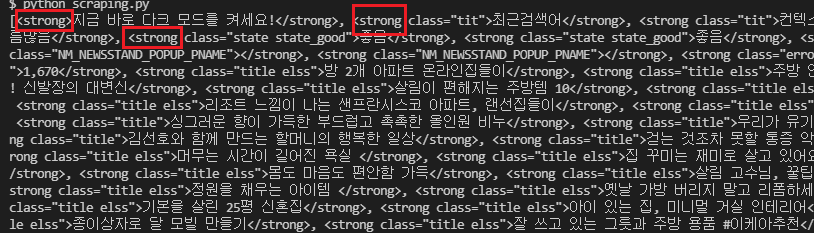
google 홈은 정보가 적기 때문에 URL을 naver로 바꾸어 원하는 글귀를 따오도록 한다.
find_all()을 통해 모든 'strong' tag를 가진 elements를 출력해보았다. 수많은 strong tag들과 그 자식노드들이 전부 출력된 것을 확인할 수 있다. 너무 데이터를 많이 출력했기 때문에 이대로 사용할 수 없으므로, 다른 부모노드 또는 자식 노드를 찾아 새로운 tag로 확인하거나 속성으로 찾아야 원하는 데이터를 구할 수 있다.
2. tag 및 속성을 이용한 data 찾기
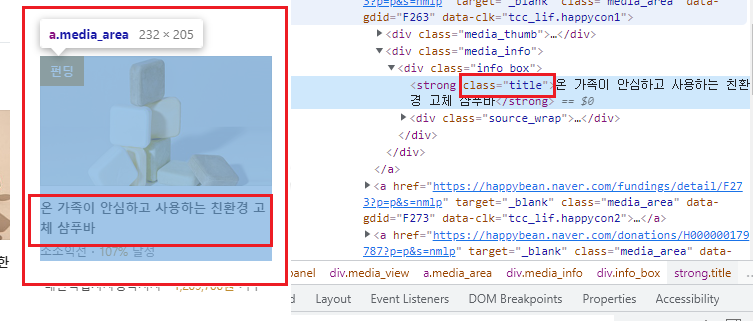
# strong tag에 class="title"인 속성을 더해서 좀 더 데이터를 추려낸다.
r = soup.find_all('strong', attrs = {'class':'title'})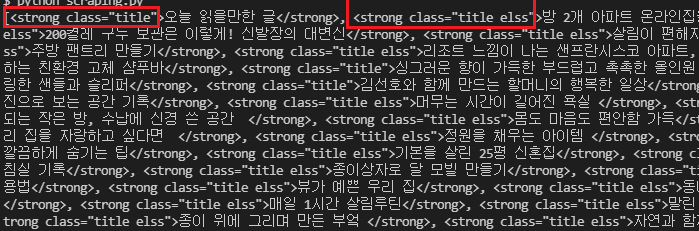
찾고자 했던 class = 'title 속성으로 추출했을 때, 조금 더 세부적으로 title을 가진 class 들만 반환되는것을 볼 수 있따.
해당 결과의 data type은 <class 'bs4.element.ResultSet'> 이며, 안에서 꺽새와 지저분한 내용을 제외한 글자들만 보고자 한다면, .text method를 이용할 수 있다.
(단, text는 element.Tag타입에 적용가능한 method이기 때문에 find() 결과에만 적용이 가능하다. 그러므로 전체 내용을 반환한 find_all()의 결과값은 for구문으로 풀어주면서 적용할 수 있다.)
3. get_text를 통한 Text 추출하기
r = soup.find_all('strong', class_ = 'title')
# print(r)
for i in r:
print(i.text)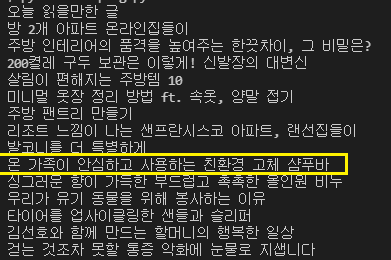
.text를 이용해 각 elements가 갖고있던 내용을 출력하면 깔끔하고 가독성이 좋게 나열되는 것을 볼 수 있다. 해당 데이터와 같은 위치의 데이터들을 비교분석 할 때엔 이렇게 list로 출력하여 진행할 수 있다.
find() 이후 형제노드를 오가는 next_siblings 와 previous_siblings 등은 추가 실습에서 진행토록 하겠다.
