Rate Limiter로 요청 수 제한하기
배경
서버 운영 맡아서 하는 중에 요청사항이 하나 들어왔다.
고의적으로 많은 요청을 보내 서버 리소스를 낭비하게 하려는 것을 방지해달라는 요청이었다.
이를 위해 유저의 IP별, API별로 Rate Limit을 적용해야해서 구현해봤다.
Rate Limit에는 여러 알고리즘이 있고 다양한 기술을 활용할 수 있는데 나는 어떤 알고리즘을 활용했고 어떤 기술을 통해 적용했는 지 소개 할 예정이다.
목적과 알고리즘
Rate Limiter란 백엔드 시스템에서 클라이언트의 과도한 요청을 제어하기 위해 사용되는 기술이다.
서버 보호, 공정한 리소스 사용, 시스템 안정성을 위해 중요한 역할을 한다. 목적은 다음과 같다.
Rate Limiter의 목적
- 서버 과부하 방지 누군가 너무 과도한 요청을 보내면 서버가 느려지거나 다운될 수 있는데 이를 방지한다.
- 리소스 분배 일부 유저가 리소스를 독점하지 못하도록 모든 유저가 최대한 공정하게 리소스를 사용할 수 있게 한다.
- 악성 공격, 디도스 방지 악성 트래픽을 막는 방어선 역할을 한다.
- 비용 절감 서버가 불필요한 요청을 처리하지 않아도 되니 불필요한 비용이 줄어든다.
비용 절감은 어떤 서버 시스템이냐에 따라 달라진다.
알고리즘
Rate Limit 알고리즘은 잘 알려진 것은 4개가 있다. 난 그 중에서 Token Bucket이란 알고리즘을 적용했다.
해당 알고리즘은 일정한 속도로 토큰을 버킷에 채워 넣고, 요청이 들어올 때마다 토큰을 하나 꺼내는 방식이다.
토큰이 남아있으면 요청이 처리되고 사용할 수 있는 토큰이 없다면 요청이 제한된다.
밑에서 소개 할 예정이지만 내가 구현한 관련 어노테이션을 보면 다음과 같이 돼있다.
@RateLimit(capacity = 10, refillTokens = 10, refillDuration = 1) // 1분에 10개 요청 제한용량이 10인 버킷에 1분마다 10개씩 채워넣겠다는 것이다. 즉, 1분에 요청을 10개로 제한한다는 것이고 참고로 예시의 수치일 뿐이다.
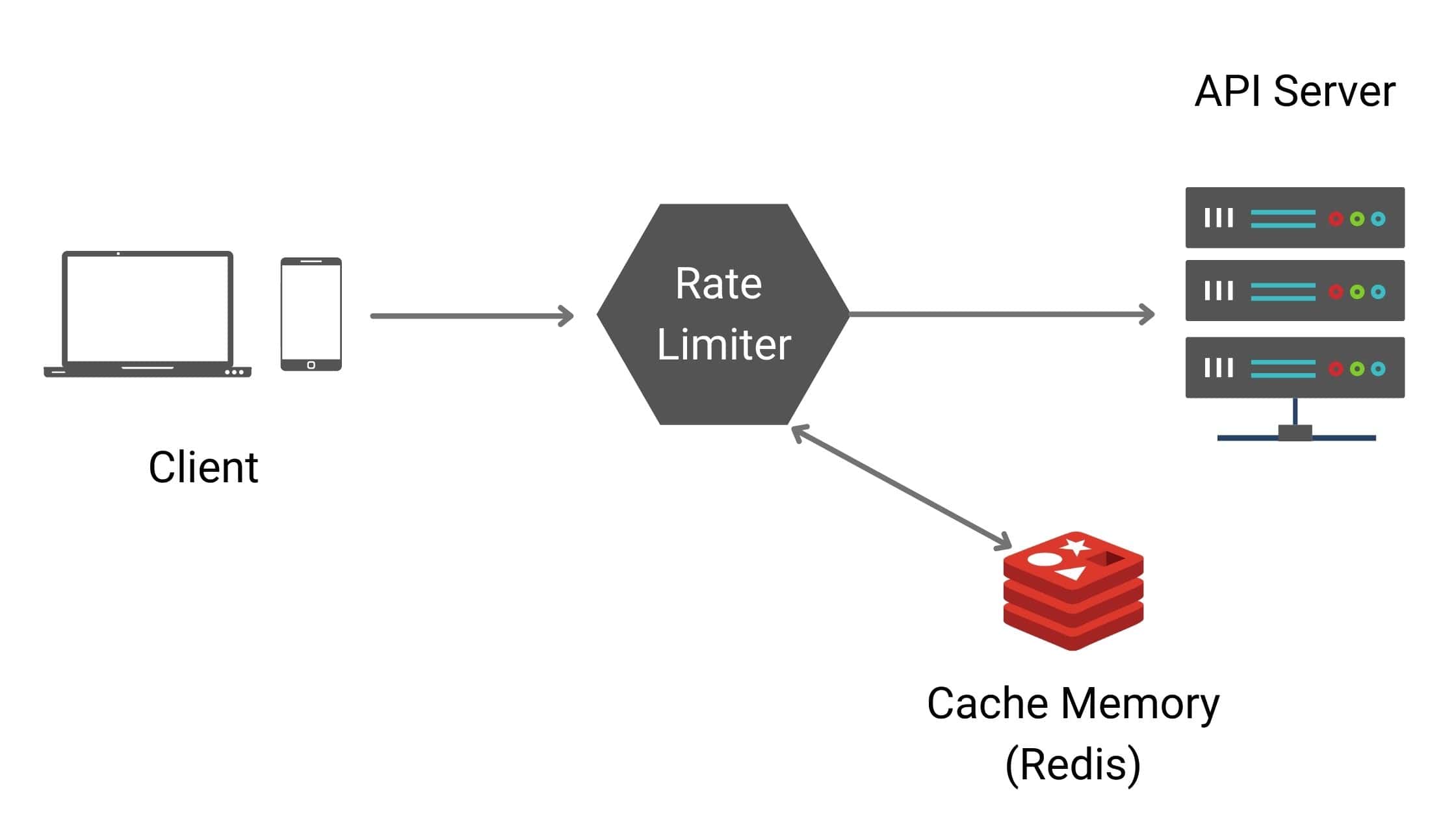
Bucket4j + Redis 활용 이유
Rate Limiter 구현은 Bucket4j와 Redis를 활용했다.
우선 Bucket4j는 토큰 버킷 알고리즘을 사용하고 Rate Limit을 위한 라이브러리이기 때문에 다른 라이브러리에 비해 상대적으로 가볍다. 목적에 알맞는 라이브러리다.
Redis를 활용하면 분산 시스템에서의 Rate Limiter를 구현하기에 안성맞춤이다.
모든 인스턴스가 Redis를 통한 공유 저장소를 활용해 버킷을 공유하므로 일관성을 확보할 수 있다.
난 Spring AOP를 활용해 위 기술을 적용했다. 이제 구현을 살펴보자.
구현
의존성을 먼저 추가해야한다.
build.gradle
implementation 'com.bucket4j:bucket4j-core:8.10.1'
implementation 'com.bucket4j:bucket4j-redis:8.10.1'Redis를 사용하므로 Redis 설정 파일도 만들어 주어야한다.
ProxyManager를 활용해 버킷을 만들 거라 관련 설정을 만들어준다.
RedisConfig.java
@RequiredArgsConstructor
@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisClient redisClient() {
return RedisClient.create(RedisURI.builder()
.withHost(host)
.withPort(port)
.build());
}
@Bean
public ProxyManager<String> lettuceBasedProxyManager() {
RedisClient redisClient = redisClient();
StatefulRedisConnection<String, byte[]> redisConnection = redisClient
.connect(RedisCodec.of(StringCodec.UTF8, ByteArrayCodec.INSTANCE));
// Expiration 전략 설정
return LettuceBasedProxyManager.builderFor(redisConnection)
.withExpirationStrategy(
ExpirationAfterWriteStrategy.basedOnTimeForRefillingBucketUpToMax(
Duration.ofMinutes(1L)))
.build();
}
}ProxyManager는 Bucket4j 분산 버전에서 사용되는 인터페이스로 Redis를 통해 버킷 상태를 관리하게 해준다.
이제 Rate Limiter를 구현해보자.
@Aspect
@Component
@EnableAspectJAutoProxy
public class RateLimitAspect {
private final ProxyManager<String> proxyManager;
private final HttpServletRequest request;
@Autowired
public RateLimitAspect(ProxyManager<String> proxyManager, HttpServletRequest request) {
this.proxyManager = proxyManager;
this.request = request;
}
@Around("@within(rateLimit)")
public Object rateLimitCheck(ProceedingJoinPoint joinPoint, RateLimit rateLimit)
throws Throwable {
String apiPath = request.getRequestURI();
String ip = request.getRemoteAddr();
String key = ip + ":" + apiPath;
// Bucket 설정
Supplier<BucketConfiguration> bucketConfig = getConfigSupplier(rateLimit);
Bucket bucket = proxyManager.builder().build(key, bucketConfig);
ConsumptionProbe probe = bucket.tryConsumeAndReturnRemaining(1); // 1개의 요청을 소모하려 시도
if (probe.isConsumed()) {
return joinPoint.proceed(); // 제한을 넘지 않으면 메소드 실행
} else {
throw new RateLimitException(_TOO_MANY_REQUESTS);
}
}
private Supplier<BucketConfiguration> getConfigSupplier(RateLimit rateLimit) {
Refill refill = Refill.greedy(rateLimit.refillTokens(),
Duration.ofMinutes(rateLimit.refillDuration()));
Bandwidth bandwidth = Bandwidth.classic(rateLimit.capacity(), refill);
return () -> BucketConfiguration.builder()
.addLimit(bandwidth)
.build();
}
}getConfigSuppliter(RateLimit rateLimit)
위에서 만든 어노테이션을 미리 언급했듯이 어노테이션을 통해 capacity, refillokens, refillDuration을 설정할 수 있다.
해당 속성들을 기반으로 getConfigSupplier 함수에서 버킷 설정을 한다.
rateLimitCheck(ProceedingJoinPoint joinPoint, RateLimit rateLimit)
key 설정은 ip + api path 조합으로 설정했다. API별로 유저의 요청을 제한하기 때문이다.
버킷 설정을 만든 후에 ProxyManager를 통해 해당 설정을 기반으로 버킷을 생성한다.
bucket.tryConsumeAndReturnRemaining(1); 를 통해 토큰 사용을 시도하고 남아있었다면 요청을 처리하고 아니라면 429 상태코드와 함께 Too Many Request 예외를 던진다.
오해와 사실
코드를 보면 마치 요청이 들어올 때마다 버킷이 새로 생성되는 걸로 보일 수 있지만 그렇지 않다‼️
proxyManager.build()는 내부적으로 다음과 같이 동작한다.
- Redis에서 해당 key (ip:apiPath)로 기존 상태가 있는지 조회
- 있으면 → 기존 버킷 상태에 연결된 프록시 객체를 반환
- 없으면 → 새로 생성하여 Redis에 저장 (이건 최초 요청일 때만)
즉, 요청 제한 구현에는 알맞게 된 것이다.
하지만 궁금증이 하나 더 있을 수 있다. 그럼 여러 api에 요청이 들어올 때는 버킷이 하나가 아닌 api개수만큼 버킷이 생성돼서 비효율적인건 아닌가? 그렇진 않다.
Bucket4j에서 추구하는 것은 각 key마다 독립적인 버킷을 만들자는 것이다.
우선, 모든 api의 버킷 설정이 같을 순 없다. api의 특성(트래픽 수준 등)에 따라 요청 제한 설정을 다양하게 둘 것이다. 그렇기에 독립적인 버킷을 통해 관리하는게 더 효율적이다.
정리하자면 key마다 refill 정책을 다르게 둘 수 있기에 독립적인 것이 효율적이다.
결론
서버 리소스 낭비 방지, 악성 공격 방어 등을 위해 Rate Limiter를 구현했다.
다양한 알고리즘과 활용 가능한 기술 스택이 있지만 난 위의 방식대로 구현했다. 제일 좋은 방법은 프로젝트의 규모와 상황에 따라 달라질 수 있다. 나의 경우에는 인스턴스는 늘어날 수 있지만 규모자체가 크진 않아서 위의 방식대로 해도 괜찮겠다는 생각이 들었다. Rate Limiter 구현 알고리즘 정보에 대해 남기면서 글을 마칩니다!