
1. 우선순위 큐(Priority Queue)
우선순위 큐는 큐와 유사하지만 우선순위가 높은 데이터가 먼저 처리된다.
-
큐: 먼저 들어온 데이터가 먼저 나간다. (FIFO)
-
우선순위 큐: 먼저 들어온 데이터가 아니라, 우선순위가 높은 데이터가 먼저 나간다. 우선순위 큐는 일반적으로 힙을 이용해서 구현한다.
우선순위 큐의 주요 동작
-
insert: 데이터를 삽입하는데, 이때 각 데이터의 우선순위 정보를 같이 넣어준다.
-
delete: 큐에서 가장 우선순위가 높은 데이터를 제거한다.
-
peek: delete와 유사하나 실제 큐에서 데이터를 제거하지는 않는다.
2. 힙(Heap)
힙은 우선순위 큐의 구현 방식 중 하나로, 주로 이진 트리 기반으로 구현된다. (이진 트리: 자녀가 최대 두 개인 트리)
힙의 종료
- 최대 힙(max heap): 부모 노드의 키가 자식 노드들의 키보다 크거나 같은 이진 트리
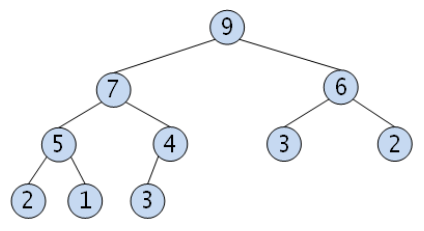
- 최소 힙(min heap): 부모 노드의 키가 자식 노드들의 키보다 작거나 같은 이진 트리
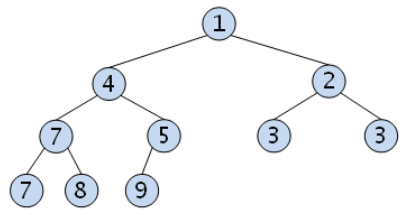
힙의 주요 동작
-
insert: 힙에 데이터를 넣어주는데, 이때 데이터의 키 값도 함께 넣어준다.
-
delete: max heap이라면 키 값이 가장 큰 데이터를 제거, min heap이라면 키 값이 가장 작은 데이터를 제거한다.
-
peek: delete와 유사하나 실제 힙에서 데이터를 제거하지는 않는다.
3. 우선순위 큐와 힙의 관계
힙의 키를 우선순위로 사용한다면, 힙은 우선순위 큐의 구현체가 된다. 즉 우선순위 큐는 ADT(Algebraic data type)이다. 실제 구현은 설명하지 않고, 어떻게 동작하는지 그 개념만 설명한다. 반면 힙은 data structure로, 구현까지 설명한다. 즉 힙이 우선순위 큐의 구현체 중 하나이다.
우선순위 큐를 힙이 아니라 배열 또는 연결리스트를 이용하여 구현할 수도 있다. 하지만 배열과 연결리스트는 선형 구조의 자료구조이므로 삽입 또는 삭제 연산을 위한 시간복잡도는 O(n)이다. 반면 힙트리는 완전이진트리 구조이므로 힙트리의 높이는 log₂(n+1)이며, 힙의 시간복잡도는 O(log₂n)이다.
4. 우선순위 큐와 힙의 사용 사례
-
프로세스 스케줄링
프로세스 스케줄링을 할 때 우선순위에 따라서 스케줄링 되야 한다면 ready queue에 우선순위 큐를 사용할 수 있다. -
힙 정렬
정렬해야 하는 n개의 아이템이 있다면, 이 n개의 아이템을 모두 힙에 넣은 뒤 차례대로 delete하면 정렬되어 나올 것이다.
참고 자료
