힙(heap)
힙(heap)은 힙의 특성(부모 자식관의 관계)을 만족하는 거의 완전한 트리(Almost Complete Tree)인 특수한 트리 기반의 자료구조이다.
힙(heap)이라는자료구조는 J.W.J. 윌리엄스(Williams)라는 영국의 컴퓨터과학자가 1964년에 힙 정렬 알고리즘을 고안하면서 최초로 설계 되었다.
이진 힙(Binary Heap)
자식 노드가 둘인 힙을 특별히 이진 힙(Binary Heap)이라 하며, 대부분 이진 힙이 널리 사용된다.
이진 힙(Binary Heap)은 완전이진트리를 기반으로 구성하는 자료구조로
🤚완전이진트리(Complete Binary Tree) 란?
마지막 레벨을 제외하고 모든 레벨에 노드들이 완전히 채워져 있는 이진트리.
(마지막 레벨의 노드들은 왼쪽부터 채워져야 함.)
최소 힙(min heap) 과 최대 힙(max heap)으로 구성되어 있다
최소 힙(min heap)은 부모가 항상 자식보다 작은 경우로 루트 노드가 가장 작은 값을 가지며,
최대 힙(max heap)은 부모가 항상 자식보다 큰 경우로 루트 노드가 가장 큰 값을 가진다.(힙은 정렬된 구조가 아니다. 부모 자식 간의 관계만 정의할 뿐, 좌우 노드에 대한 대소관계는 정의하지 않는다.)
따라서 힙은 루트 노드(최상위 노드)만을 추출하여 최솟값 과 최대값을 빠르게 찾아낼 수 있다.
(시간복잡도: O(logn), 자세한 내용은 아래 추출 참조)
힙의 활용
힙은 대표적으로 우선순위 큐뿐 아니라 이를 이용한 다익스트라 알고리즘에도 활용된다.
(다익스트라 알고리즘에서 힙(우선순위 큐)를 사용하여 시간복잡도를 O(V²)에서 O(Elogn)로 줄일 수 있다.)
또한 원래의 용도인 힙 정렬 과 최소 신장 트리(Minimum Spanning Tree)를 구현하는 프림 알고리즘(Prim's Algorithm) 등에도 활용되며, 중앙값의 근사값(Approximation)을 빠르게 구하는 데도 활용할 수 있다.
파이썬에서 우선순위 큐를 사용할 때 활용하는 heapq 모듈이 힙으로 구현되어 있다.
(heapq모듈은 최소 힙만 구현되어 있음.)
힙의 표현
이진 힙(Binary Heap)은 완전 이진 트리이기 때문에 아래의 그림과 같이 배열에 순서대로 표현하는 것이 적합하다
(우선순위 큐는 이진 힙으로 구현 -> 따라서 우선순우 큐는 배열로 구현)
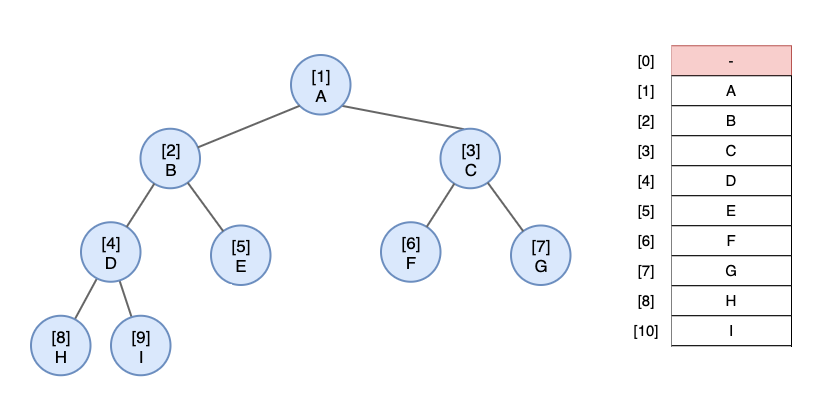
힙 연산
initialize
인덱스 계산을 편하게 하기 위해서 1부터 시작
class BinaryHeap(object):
def __init__(self):
self.items = [None] # index를 1부터 시작하기 위해서 비어있는 값(None)을 index=0에 채운다.
def __len__(self): # 매직메소드(__method__), len(a) -> a.__len__() 호출
return len(self.items) - 1삽입 (시간복잡도: O(logn))
힙에 요소를 삽입하기 위해서는 업힙(up-Heap) 연산을 수행해야 한다. 일반적으로 업힙 연산은 percolate_up()으로 정의한다.
- 요소를 가장 하위 레벨의 최대한 왼쪽에 삽입한다.(배열로 표현할 경우 가장 마지막에 삽입)
- 부모 값과 비교해 값이 더 작은 경우 위치를 변경한다.
- 계속해서 부모 값과 비교해 위치를 변경한다.(가장 작은 값인 경우 루트까지 올라간다.)

# 시간복잡도: log(n)
# => parent = i // 2 -> 절반씩 줄여나감, 로그(log(n)) 연산
# 삽입, 반복 구현
def _percolate_up(self):
i = len(self)
parent = i // 2 # parent_node_index = i -> child_node_index = 2i, 2i+1
while parent > 0:
# 추가한 node 값이 부모 node 값보다 작은 경우 스왑
if self.items[i] < self.items[parent]:
self.items[parent], self.items[i] = self.items[i], self.items[parent]
i = parent # 부모 노드로 index 변경
parent = i // 2
def insert(self, k):
self.items.append(k) # 배열 -> 가장 마지막 삽입
self._percolate_up()추출 (시간복잡도: O(logn))
최소 or 최대 값 추출 -> 루트 노드 추출
최소(min Heap) or 최대(max Heap) 값을 추출하는 것은 간단하다.
루트 노드를 추출하면 된다. 따라서 시간복잡도는 O(1)인 것 같지만,
추출 이후 다시 힙을 구성해줘야 하기 때문에 시간복잡도는 O(logn)이다.
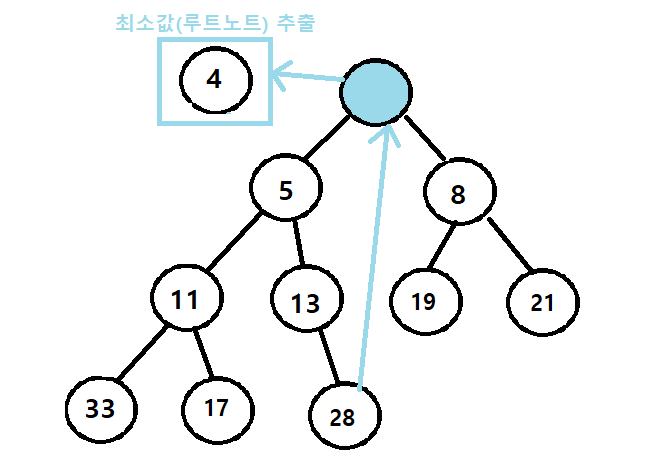
최소 힙 추출 예시
1. 최소값(루트 노드) 추출
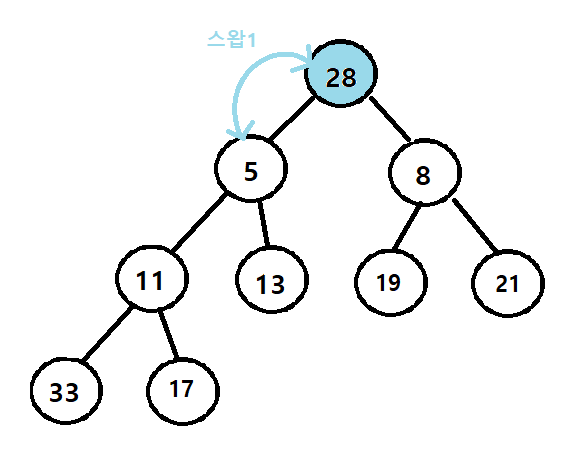
2. 스왑1
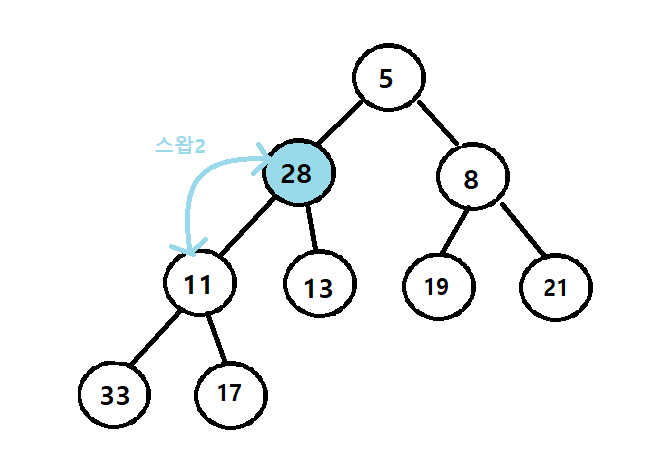
3. 스왑2
4. 스왑3
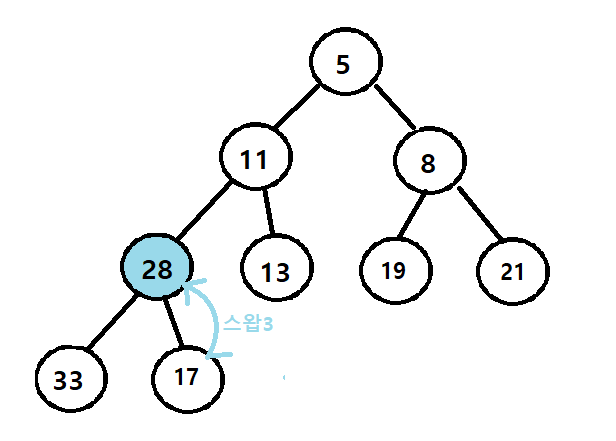
5. 힙 재구성 완료

# 시간복잡도: log(n)
# 추출, 재귀 구현
def _percolate_down(self, idx):
left = idx * 2
right = idx * 2 + 1
smallest = idx
# left 노드 값이 더 작은 경우 smallest 변경
if left <= len(self) and self.items[left] < self.items[smallest]:
smallest = left
# right 노드 값이 더 작은 경우 smallest 변경
if right <= len(self) and self.items[right] < self.items[smallest]:
smallest = right
# left or right 노드 값이 더 작아 smallest가 변경된 경우 swap 처리
if smallest != idx:
self.items[idx], self.items[smallest] = self.items[smallest], self.items[idx]
# 재귀 -> 탐색
self._percolate_down(smallest)
def extract(self):
extracted = self.items[1]
self.items[1] = self.items[len(self)] #마지막 요소, root Node에 할당
self.items.pop() # 할당 처리 후 필요없는 마지막 요소 제거
self._percolate_down(1)
return extractedReference)
파이썬 알고리즘 인터뷰
https://baeharam.github.io/posts/data-structure/heap/
https://devlog-wjdrbs96.tistory.com/43
https://galid1.tistory.com/485
https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
