퍼셉트론
퍼셉트론은 인간의 신경, 뉴런을 모델링 한 것.
다수의 입력으로부터 하나의 결과를 내보내는 알고리즘
신경망(딥러닝)의 기원이 되는 알고리즘이다.
x: 입력값
y: 출력값
w: weight, 가중치
b: bias, 편향값(기준값)
활성화 함수: (계단 함수, 시그모이드, Relu, softmax)
각 입력값에는 가중치가 붙는데 가중치가 클 수록 해당 입력값이 출력값에 미치는 영향력이 크다는 의미다.
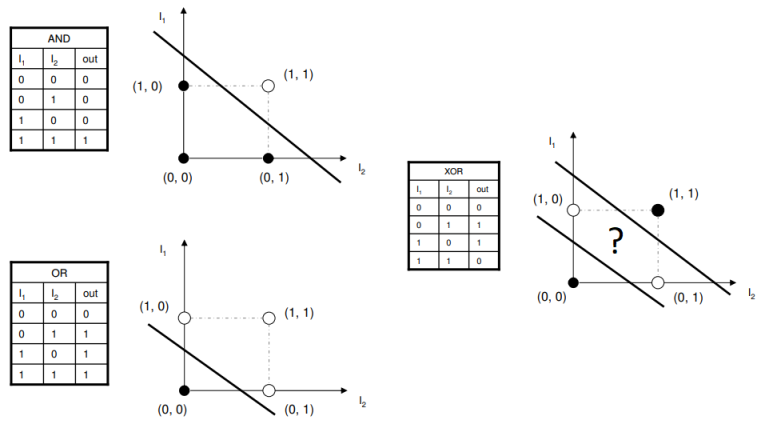
퍼셉트론은 선형모델이기 때문에 경계가 직선 형태이다
단일 퍼셉트론 연산식
y=Step Function(w1x1+w2x2+ ... +wnxn+b)
xor 연산식의 경우 n의 개수는 2개
Step Function 계단 함수
퍼셉트론에서 일반적으로 Step Function에 임계값은 일반적으로 0이다.
Step Function(x)=
{0, if x≤0
{1, if x>0
x가 0이하면 0을 출력, 1초과면 1을 출력
가중치와 bias는 여러가지로 나올수 있는데 AND의 경우 예를 들면
import numpy as np
def AND(x1, x2):
x = np.array([x1, x2]) #입력값
w = np.array([0.4, 0.4]) #가중치
b = -0.7 #편향
tmp = np.sum(w*x) + b
if tmp > 0:
return 1
else:
return 0
def test():
print(AND(0, 0))
print(AND(1, 0))
print(AND(0, 1))
print(AND(1, 1))
# 1*0.4 + 1*0.4 - 0.7 = 0.3 (0초과이므로 출력값은 1)
test()
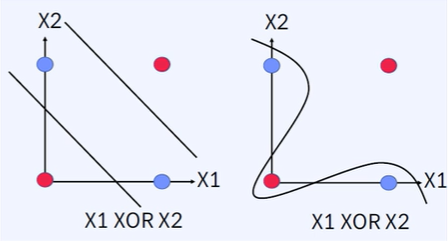
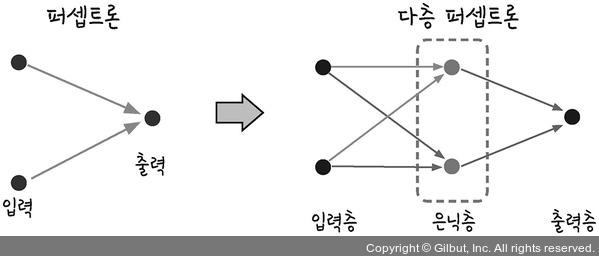
#출력결과: 0 0 0 1퍼셉트론은 선형 형식이기 때문에 직선으로 밖에 표현을 못하는데 xor문제를 해결하려면 한개의 직선으로 결정을 못하기 때문에 비선형 모델인 다층 퍼셉트론을 이용해야 한다.
다층 퍼셉트론 MLP(Multi-Layer Percetron)
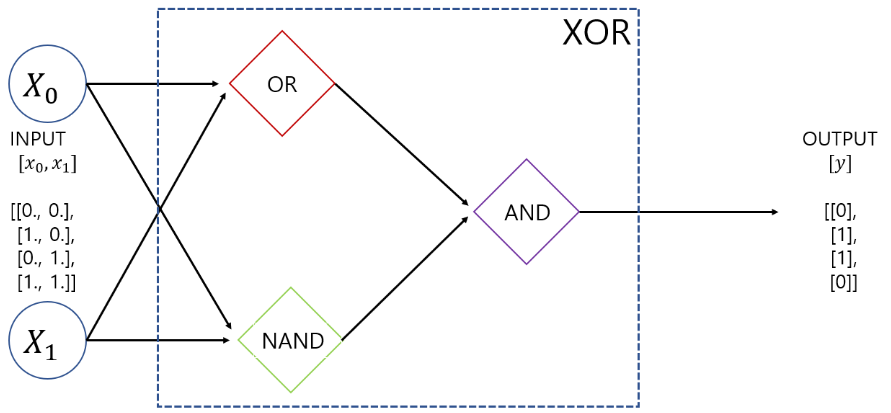
1. 단층 퍼셉트론 두개를 결합해 해결
방법은 입력값을 NAND, OR게이트에 입력한 결과를 AND게이트를 통해 결합하면 된다.
def XOR(x1, x2):
return AND(NAND(x1, x2), OR(x1, x2))예를 들어 x1에 1, x2에0을 입력한다 하면, NAND게이트 결과(s1)가 1, OR게이트 결과(s2)가 1이고, s1와 s2의 AND게이트 결과값은 1이다.
여기서 NAND(x1, x2)과 OR(x1, x2)게이트는 은닉층의 역할, AND게이트는 출력층 역할을 한다.
2. 비선형을 사용해서 해결하는 방법
step function 활성화 함수가 아닌 시그모이드 함수를 사용(학습 기반)
-
순전파: 입력데이터(input_data)로부터 예측값(predict)을 계산하는 과정
예측값 = 가중치 * 입력값 + 편향 -
역전파: 가중치 수정.
출력 오류를 역으로 전파하여 각 가중치와 편향의 기울기를 계산. 신경망의 정확도를 높이기 위해
경사하강법: 계산된 기울기를 바탕으로 가중치와 편향을 최적화. -
역전파 알고리즘과 경사하강법을 사용하여 가중치와 편향을 업데이트
오차를 기반으로 가중치와 편향 업데이트
오차를 출력층에서부터 입력층으로 거꾸로 전파하면서, 각 가중치와 편향이 오차에 얼마나 영향을 미치는지 계산 -
가중치 업데이트
(새로운)가중치 = (기존)가중치 - 학습률 * 기울기 -
그래디언트는 손실 함수의 기울기를 의미하며, 기울기를 따라 가중치와 편향을 업데이트
출력값을 시그모이드의 미분에 적용하여 구할수 있다
-
경사하강법을 기반으로 가중치를 조절
파이썬으로 구현
epoch - 학습 횟수
한번의 epoch는 한번의 forward pass(순전파)와 backward pass(역전파)과정을 거친 것 == 모든 데이터 셋이 한번 학습을 완료
batch size
batch: epoch가 나눠진 데이터 셋
batch size는 한번의 batch마다 주는 데이터 샘플의 크기
iteration
한번의 epoch를 batch size로 나눈걸 한번 학습하는것. 한번의 배치학습

ex) 2000개 데이터가 있고 batch_size=500이면 1epoch당 네번의 iteration으로 나눠진다
- 입력층 노드 2개: x1, x2
- 은닉층 노드 2개
- 출력층 노드 1개(0 or 1)
- 가중치, 편향 초기화(랜덤 값)
- 학습률, 에포크(반복횟수) 설정
- 순전파 진행(각 층에 가중합, 활성화 함수 적용)
- 오차 계산 및 역전파 진행(오차 반영해서 새로운 은닉층, 출력층 기울기 구하기)
- 그래디언트(기울기)와 출력값, 입력값으로 가중치, 편향 업데이트
- 3,4,5 반복(오차 감소 -> 목표값과 비슷해짐)
- 최종 가중치 편향으로 출력값 생성
import numpy as np
# 시그모이드 함수
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 시그모이드 함수의 미분 (학습에 필요)
def sigmoid_derivative(x):
return x * (1 - x)
# 퍼셉트론 학습
def train_xor_perceptron():
# XOR 진리표 데이터
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 학습을 위한 입력값
y = np.array([[0], [1], [1], [0]]) # 출력값 (XOR)
# 가중치 초기화 (랜덤값)
np.random.seed(42)
weights_input_hidden = np.random.rand(2, 2) # 입력층 -> 은닉층 가중치 (2 입력, 2 은닉노드)
weights_hidden_output = np.random.rand(2, 1) # 은닉층 -> 출력층 가중치 (2 은닉노드, 1 출력노드)
bias_hidden = np.random.rand(1, 2) # 은닉층 편향
bias_output = np.random.rand(1, 1) # 출력층 편향
# 학습률 및 에포크 설정
learning_rate = 0.1
epochs = 10000
# 학습 과정
for epoch in range(epochs):
# 순전파
hidden_layer_input = np.dot(X, weights_input_hidden) + bias_hidden # 입력값과 가중치의 가중합 + 편향
hidden_layer_output = sigmoid(hidden_layer_input) # 은닉층에 활성화함수 적용(0~1)
final_input = np.dot(hidden_layer_output, weights_hidden_output) + bias_output # 은닉층 출력값과 가중치의 가중합 + 편향
final_output = sigmoid(final_input) # 출력층에 활성화함수 적용(0~1)
# 오차 계산
error = y - final_output # 목적 값 - 현재 학습된 출력값
# 역전파
d_output = error * sigmoid_derivative(final_output) #활성화함수 미분에 출력값을 적용 #오차를 반영한 출력층의 그래디언트
error_hidden_layer = d_output.dot(weights_hidden_output.T) # 출력층에서의 그래디언트를 은닉층으로 전파
#ㄴ출력층의 오차를 기반으로 은닉층의 각 노드가 학습에 얼마나 기여하는지 #.dot:행렬 곱 #.T: 전치(행과 열의 수를 바꿈)
d_hidden_layer = error_hidden_layer * sigmoid_derivative(hidden_layer_output) # 은닉층오차를 반영한 은닉층 그리디언트
# 가중치 및 편향 업데이트
weights_hidden_output += hidden_layer_output.T.dot(d_output) * learning_rate
#은닉층->출력층 가중치 업데이트 #은닉층 출력값의 전치행렬과 출력층 기울기의 곱에 학습률 곱해서 변화량 조정후 가중치에 더함
weights_input_hidden += X.T.dot(d_hidden_layer) * learning_rate
#입력층->은닉층 가중치 업데이트 #입력값 전치행렬과 은닉층 기울기행렬 곱에 학습률 곱해서 변화량 조정후 가중치에 더함
bias_hidden += np.sum(d_hidden_layer, axis=0, keepdims=True) * learning_rate #은닉층 편향 업데이트
bias_output += np.sum(d_output, axis=0, keepdims=True) * learning_rate #출력층 편향 업데이트
# 일정 에포크마다 출력
if epoch % 1000 == 0:
loss = np.mean(np.abs(error)) # 모든 오차 절대값의 평균
print(f"Epoch {epoch}, Loss: {loss}")
return weights_input_hidden, weights_hidden_output, bias_hidden, bias_output
#최종 학습된 입력층->은닉층, 은닉층->출력층의 가중치, 편향
# 학습된 가중치와 편향으로 XOR 예측
def predict(x1, x2, weights_input_hidden, weights_hidden_output, bias_hidden, bias_output):
# 입력 데이터
inputs = np.array([x1, x2]).reshape(1, 2)
# 순전파
hidden_layer_input = np.dot(inputs, weights_input_hidden) + bias_hidden
hidden_layer_output = sigmoid(hidden_layer_input)
final_input = np.dot(hidden_layer_output, weights_hidden_output) + bias_output
final_output = sigmoid(final_input)
# 출력값 (0.5 이상이면 1, 아니면 0)
return 1 if final_output >= 0.5 else 0
# XOR 퍼셉트론 학습
weights_input_hidden, weights_hidden_output, bias_hidden, bias_output = train_xor_perceptron()
# 학습된 모델로 예측 확인
print("XOR(0, 0):", predict(0, 0, weights_input_hidden, weights_hidden_output, bias_hidden, bias_output))
print("XOR(0, 1):", predict(0, 1, weights_input_hidden, weights_hidden_output, bias_hidden, bias_output))
print("XOR(1, 0):", predict(1, 0, weights_input_hidden, weights_hidden_output, bias_hidden, bias_output))
print("XOR(1, 1):", predict(1, 1, weights_input_hidden, weights_hidden_output, bias_hidden, bias_output))