Executor,ExecutorService, ThreadPoolExecutor
자바는 ThreadPool을 위해 java.util.concurrent패키지에서 ExecutorService interface와 Executor 클래스를 제공
Executor의 다양한 정적 메소드를 이용해 ExecutorService 구현 객체를 만들 수 있음
ExecutorService(스레드풀)에서는 작업 처리를 위해 두 가지 메소드가 제공됨
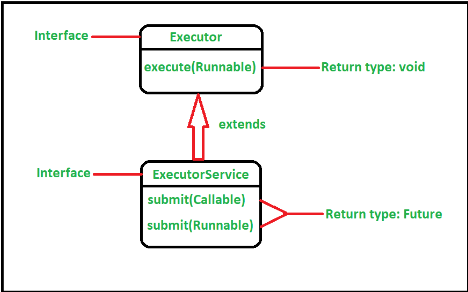
execute()와 submit()
1)execute()
- 리턴값이 없는 Runnable객체를 작업큐에 저장 -> 작업처리 결과를 받지 못함
- 작업 처리 도중에 예외가 발생하면 스레드가 종료되고 해당 스레드를 스레드풀에서 제거한 뒤 다른 작업처리를 위해 새로운 스레드를 생성함
2)submit()
- 작업처리결과를 받을 수 있도록 Future를 리턴
- 작업처리 도중에 예외가 발생하더라도 스레드는 종료되지 않고 다음 작업을 위해 재사용됨
--> 스레드 생성 오버헤더를 줄이기 위해 submit()사용하는 것이 좋음1) Executor
- 아주 다양한 여러 가지 종류의 작업 실행 정책을 지원
- 유연하면서도 강력한 비동기적 작업 실행 프레임워크의 근간을 이룸
- 작업 등록(task submission), 작업 실행(task Execution)을 분리하는 표준적인 방법
- 각 작업은 Runnable의 형태로 정의
< Executor 인터페이스를 구현한 클래스의 기능>
- 작업의 라이프 사이클을 관리하는 기능
- 몇 가지 통계값을 추출하거나 애플리케이션에서 작업 실행 과정을 관리하고 모니터링하기 위한 기능
<구조>
-
프로듀서-컨슈머 패턴에 기반
-
작업을 생성해 등록하는 클래스가 프로듀서(처리해야할 작업을 생성하는 주체)
-
작업을 실제로 실행하는 스레드가 컨슈머(생성된 작업을 처리하는 주체)
-
일반적으로 프로듀서-컨슈머 패턴을 애플리케이션에 적용해 구현할 수 있는 가장 쉬운 방법이 Executor Framework를 사용하는 것
1) Executors.newFixedThreadPool(100); //100개의 스레드
- 처리할 작업이 등록되면 그에 따라 실제 작업할 스레드를 하나씩 생성
- 생성할 수 있는 스레드의 최대 개수는 제한되어 있음
- 제한된 개수까지 스레드를 생성하고 나면 더 이상 생성하지 않고 스레드 수를 유지함
2) Executors.newCachedThreadPool();
- 캐시 스레드풀은 현재 풀에 갖고 있는 스레드의 수가 처리할 작업의 수보다 많아서 쉬는 스레드가 많이 발생할 때 쉬는 스레드를 종료시켜 훨씬 유연하게 대응할 수 있음
- 처리할 작업의 수가 많아지면 필요한 만큼 스레드를 새로 생성함
- 스레드의 수에 제한을 두지 않음
3) Executors.newSingleThreadExecutor();
- 단일 스레드로 동작하는 Executor로서 작업을 처리하는 스레드가 단 하나
- 만약 작업 중에 Exception이 발생해 비정상적으로 종료되면 새로운 스레드를 하나 생성해 나머지 작업을 실행함
- 등록된 작업은 설정된 큐에서 지정하는 순서(FIFO, LIFO, 우선순위)에 따라 반드시 순차적으로 처리됨
4) Executor.newScheduledThreadPool(100);
- 일정시간 이후에 실행하거나 주기적으로 작업을 실행할 수 있으며, 스레드의 수가 고정되어 있는 형태의 Executor.Timer 클래스의 기능과 유사함2) ExecutorService
- 서비스를 실행하는 동작주기와 관련해 Executor를 상속받은 ExecutorService interface에는 동작주기를 관리할 수 있는 여러가지 메소드가 추가되어있음
- newFixedThreadPool, newCachedThreadPool 팩토리 메소드는 일반화된 형태로 구현되어 있는 ThreadPoolExecutore 클래스의 인스턴스를 생성함
- 생성된 ThreadPoolExecutor 인스턴스에 설정값을 조절해 필요한 형태를 갖추고 사용할 수 있음
- Executor를 구현한 클래스는 대부분 작업을 처리하기 위한 스레드를 생성하도록 되어있음, 하지만 JVM은 모든 스레드가 종료되기 전에는 종료하지 않고 대기하기 때문에 Executor를 제대로 종료시키지 않으면 JVM자체가 종료되지 않고 대기하기도 함
- Executor는 작업을 비동기적으로 실행
-> 앞서 실행시켰던 작업의 상태를 정확히 파악하기 어려움
-> 어떤 작업은 이미 완료, 몇몇 작업은 실행, 또 다른 작업은 큐에서 대기할 수 있을 수 있음
-> 애플리케이션을 종료하는 과정을 보면 안전한 종료방법과 강제적인 종료 방법이 있음 - Executor가 애플리케이션에 스레드 풀등의 서비스를 제공한다는 관점
-> 안전한 방법이든 강제적인 방법이든 종료절차를 밟아야할 필요가 있음
-> 종료절차를 밟는 동안 실행 중이거나 대기중인 작업을 어떻게 처리했는지 알려줄 의무가 있음
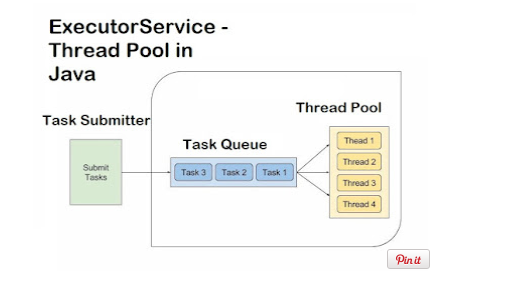
3) ThreadPoolExecutor
-Executors 클래스에 들어있는 newCachedThreadPool ,newFixedThreadPool,newScheduledThreadPool과 같은 팩토리메소드에서 생성해 주는 Executor에 대한 기본적인 내용이 구현되어 있는 클래스
- 팩토리메소드를 사용해 만들어진 스레드 풀의 기본 실행 정책이 요구 사항에 잘 맞지 않는다면 ThreadPoolExecutor 클래스의
- 생성자를 직접 호출해 스레드 풀을 생성할 수 있으며, 생성자에 넘겨주는 값을 통해 스레드 풀의 설정을 마음대로 조절할 수 있다.
