어느덧 개발은 끝을 나아가지만 만드는 것보다 중요한 것은 유지보수일 것이다.
따라서 이번 팀 프로젝트의 목표는 개발과 더불어 성능 측정을 하고 자원 누수를 찾거나 개선을 위한 부분을 찾아내는 것이 목표일 것이다.
하지만 어떻게 성능을 측정할 것인가? 직접 하나하나 기능을 구현하고 시간을 측정할 수도 없고 부하 테스트를 위해 많은 양의 프로세서를 돌리는 것도 어렵다. 여기에 사용할 수 있는 툴이 Jmeter다.

Jmeter를 처음으로 다룰려고 하면 어렵다... 쓸것도 많고 할것도 많고 하지만 찬찬히 마법의 소라고동님의 도움을 받아 하나씩 해보면 어렵지 않다. 오히려 대량의 데이터를 입력하거나, 로그인 사용자 1000명이 동작을 하는 놀라운 결과가 나타나면 경이롭다... 마치...

Jmeter 간단 사용 방법
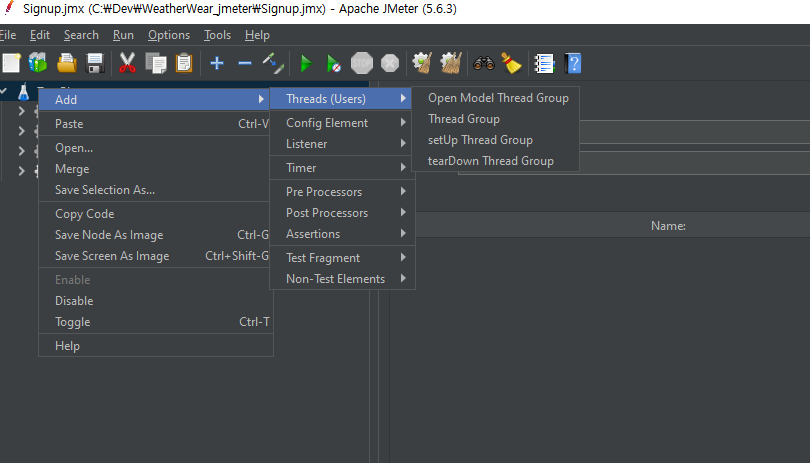
기본적으로 하나의 작업 단위를 Thread Group으로 만들게 된다.
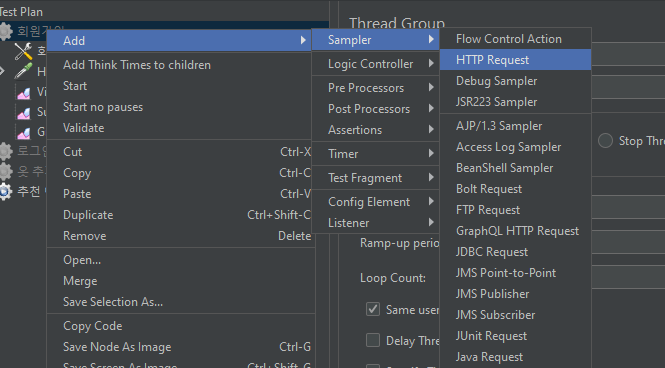
또한 요청은 HTTP Request로 생성한다.
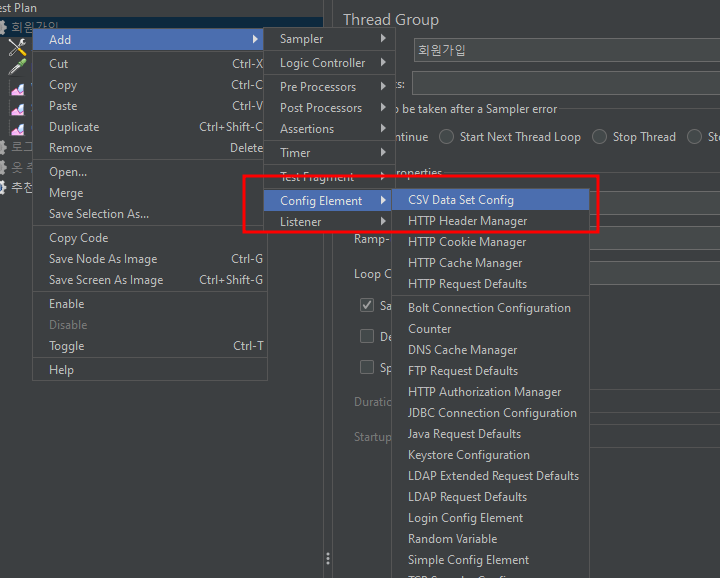
특정한 값들을 넣도록, 예를 들어 로그인을 위한 아이디와 비밀번호 데이터 같은 경우는 CSV Data Set Config으로 처리한다.
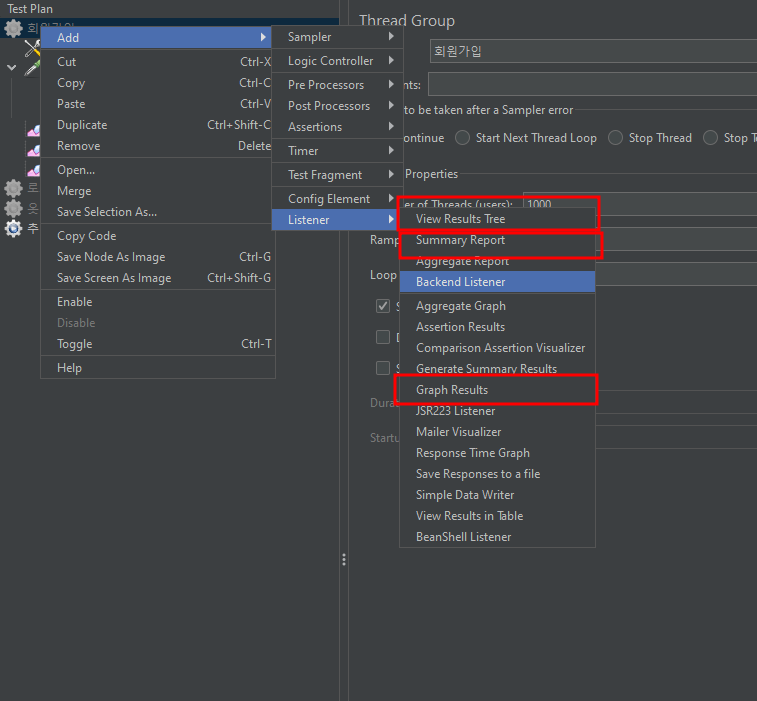
Listener 에서는 요청에 대한 결과를 확인할 수 있다. Result Tree에서는 요청와 반환 값을 확인할 수 있고, Summary Reoport 에서는 오류율이나 전체 요청량 등 수치적 통계를, Graph Result에서는 그래프 결과를 볼 수 있다. 아직 다른 기능들은 확인해보지 않았지만 해당 3개를 가장 많이 사용하는것 같다.
회원 가입
약 1000명에 대해 회원 가입을 하기 위해서 먼저 랜덤한 정보를 만들었다.
import random
import string
from faker import Faker
import json
import secrets
fake = Faker()
Faker.seed(0)
random.seed(0)
def generate_unique_nickname(existing_nicknames, name):
"""Generate a unique nickname by appending a random number to the name."""
while True:
nickname = f"{name.lower()}{fake.random_int(1, 9999)}"
if nickname not in existing_nicknames:
return nickname
def generate_secure_password():
"""Generate a secure password with 8-15 characters including at least one letter, one number, and one special character."""
special_characters = "@$!%*?&"
while True:
# At least one letter
password = [
secrets.choice(string.ascii_letters),
# At least one digit
secrets.choice(string.digits),
# At least one special character
secrets.choice(special_characters)
]
# Fill the rest of the password length (8-15 characters) with random choices
length = random.randint(5, 12) # Remaining length to make total 8-15
password += [secrets.choice(string.ascii_letters + string.digits + special_characters) for _ in range(length)]
# Shuffle to ensure random order
random.shuffle(password)
# Convert list to string
password = ''.join(password)
# Validate password length
if 8 <= len(password) <= 15:
return password
def generate_user(existing_nicknames):
name = fake.first_name()
nickname = generate_unique_nickname(existing_nicknames, name)
email = f"{nickname}@gmail.com"
password = generate_secure_password()
gender = random.choice(["Male", "Female"])
birthday = fake.date_of_birth(minimum_age=17, maximum_age=30).strftime("%Y-%m-%d")
return {
"email": email,
"nickname": nickname,
"password": password,
"passwordCheck": password,
"gender": gender,
"birthday": birthday
}
users = []
existing_nicknames = set()
for _ in range(1000):
user = generate_user(existing_nicknames)
users.append(user)
existing_nicknames.add(user['nickname'])
with open('users.json', 'w') as f:
json.dump(users, f, indent=2)
usernames = [user['nickname'] for user in users]
with open('usernames.json', 'w') as f:
json.dump(usernames, f, indent=2)
다음과 같은 파이썬 파일을 만들었는데 두 개의 json 파일을 만들게 된다.
사용자 이름은 faker 라이브러리를 통해 뽑고 이를 랜덤한 번호와 조합해 이메일과 아이디를 만들며, 비밀번호의 경우 조건에 맞는 정규식을 통해 제작했다.
import csv
import json
# Load JSON data
with open('users.json') as f:
users = json.load(f)
# Write to CSV
with open('users.csv', 'w', newline='') as csvfile:
fieldnames = ['email', 'nickname', 'password', 'passwordCheck', 'gender', 'birthday']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for user in users:
writer.writerow(user)이제 이 정보를 csv로 변환하도록 만들어서 하나의 csv로 만들었다.
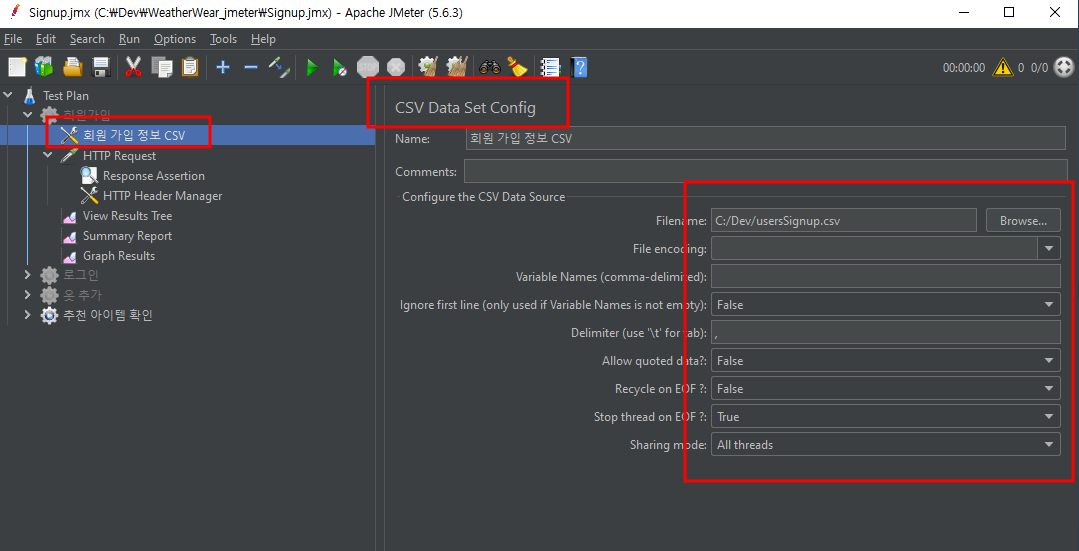
이렇게 csv 정보를 추가하고 설정하면 첫 줄부터 하나씩 사용하게 된다. 이 각각의 값을
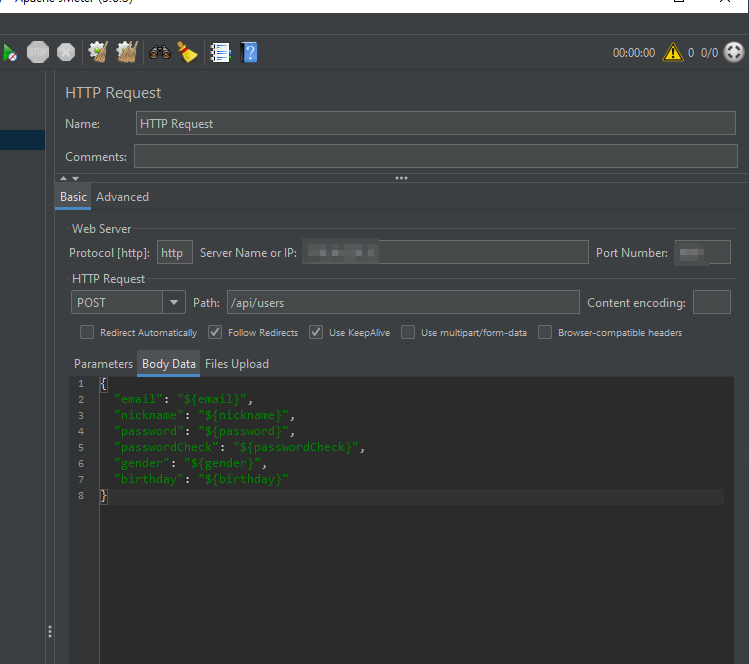
다음과 같은 설정으로 HTTP Request에 적용한다. 이제 각 데이터가 요청 전에 여기 적용될 것이라는 의미다.
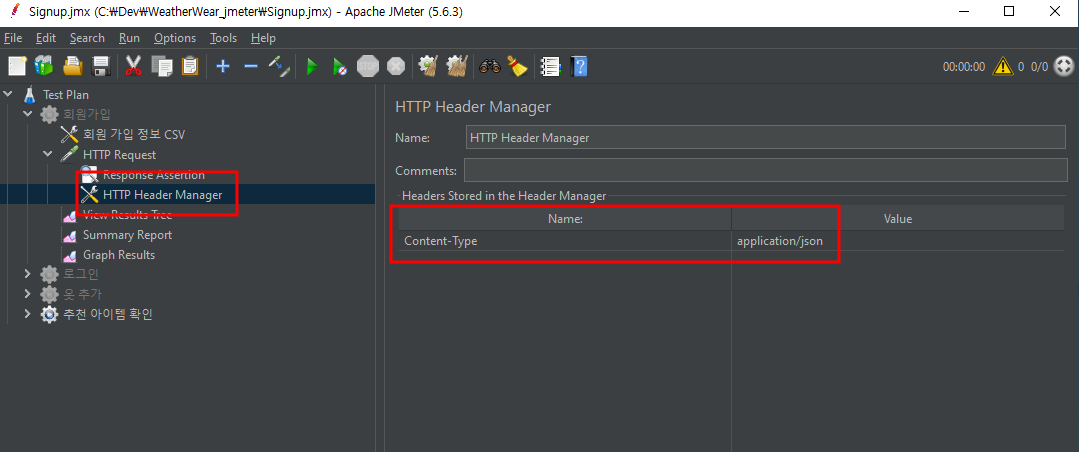
여기서 중요한 것은 요청에 Content-Type을 넣어줘야 잘 작동한다. 이는 {key: value}의 형태로 전송한다는 의미로 DTO에 잘 들어갈 수 있도록 연결된다.
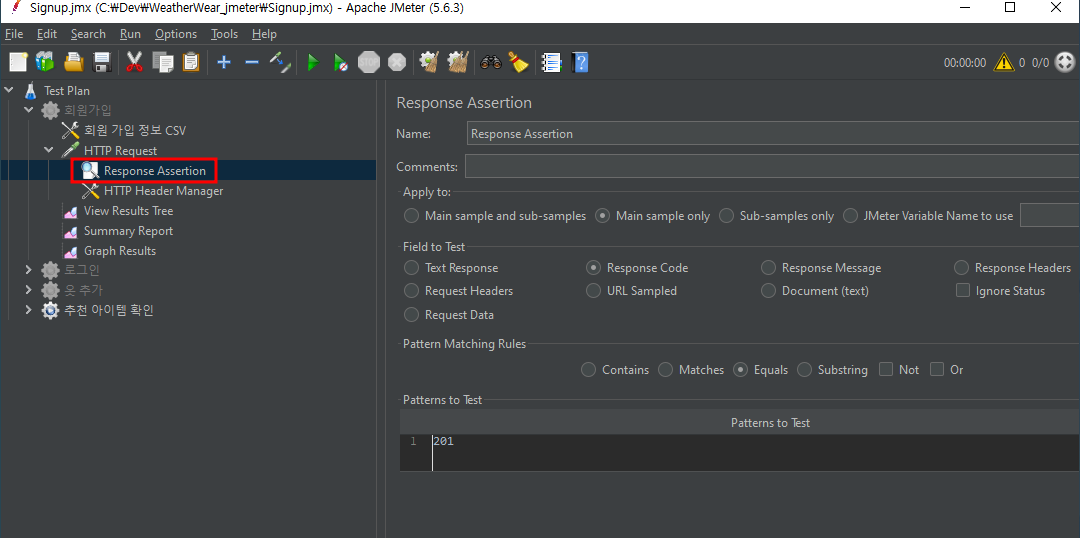
Response Assertion은 응답 코드를 확인해주는 방식이다.
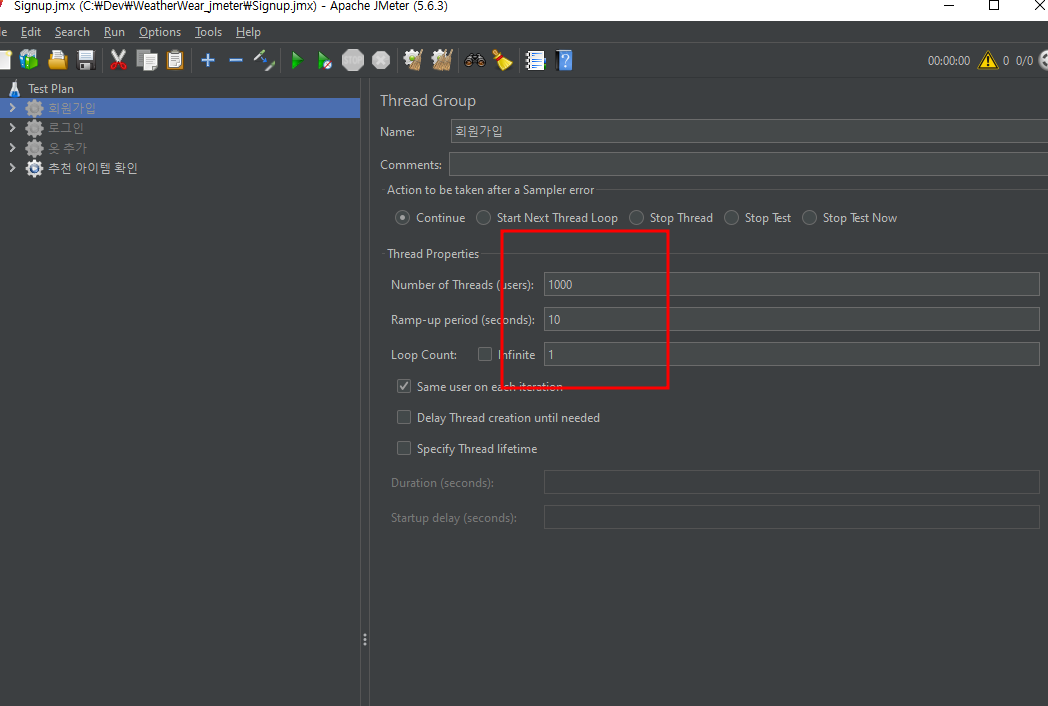
여기까지 하고 그냥 돌리면 1명이 작업하는 양이 된다. 여러 사람이 작업을 하는 방식을 위해선 Threads를 설정해야 한다. Thread Group에서 설정해주면 된다.
- Number of Threads (users):
각 스레드는 독립된 사용자를 나타낸다. 많이 넣으면 한 번에 많은 사용자라는 의미이다. - Ramp-Up Period (in seconds):
모든 스레드를 시작하는 데 걸리는 시간을 설정한다. 각 스레드 순차적으로 시간을 나눠서 시작한다. - Loop Count:
각 스레드가 샘플러를 몇 번 실행할지를 설정한다.
로그인과 데이터 추가
여기서 많이 고생을 했는데 로그인 과정과 데이터 추가 과정을 모두 넣었기 때문이다.
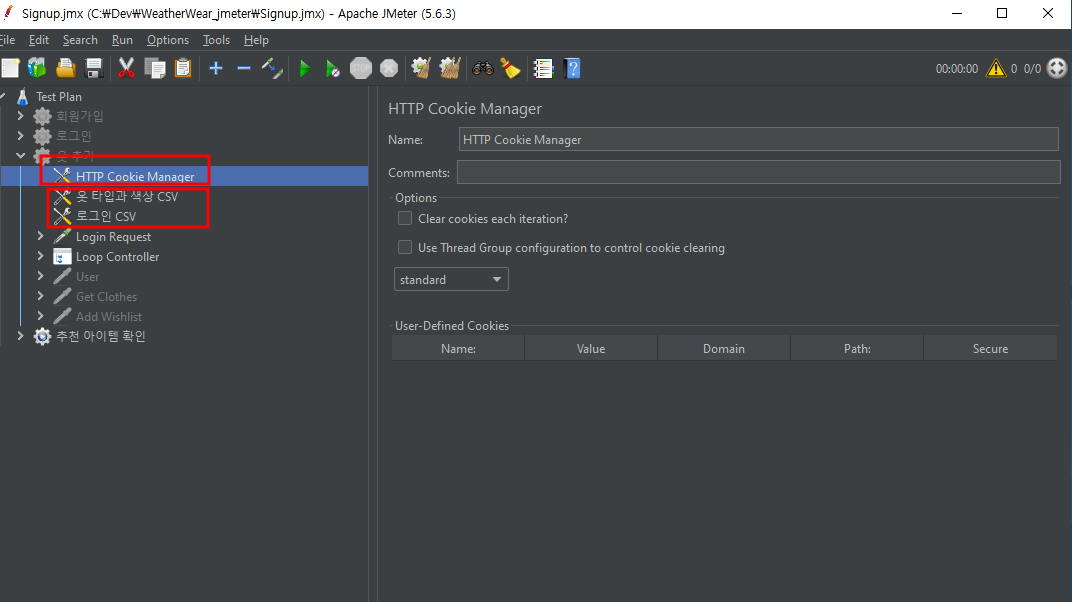
먼저 Cookie Manager가 있는데 로그인에 대한 쿠키를 여기 저장한다. 다른 csv에서는 사용자 이메일과 비밀번호를, 그리고 입력 데이터를 저장했다.
먼저 로그인부터 해보자
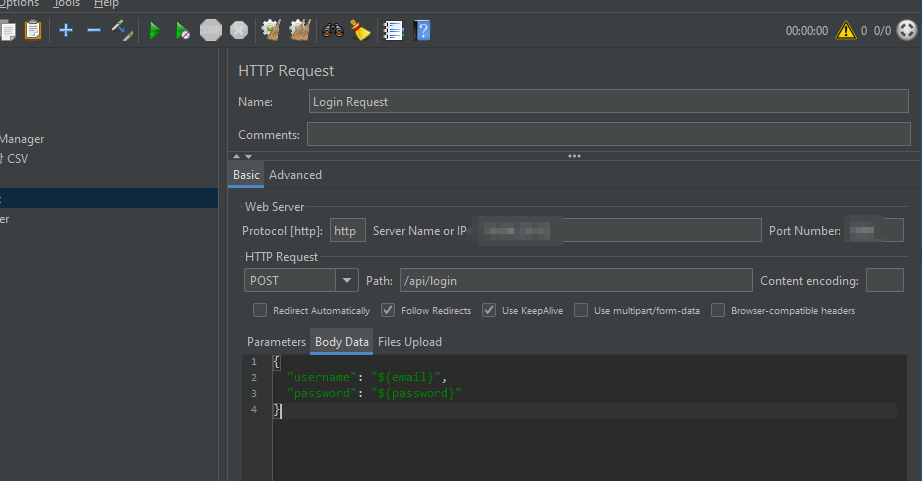
당연히 로그인 경로로에 대해 요청을 보내면 되는데
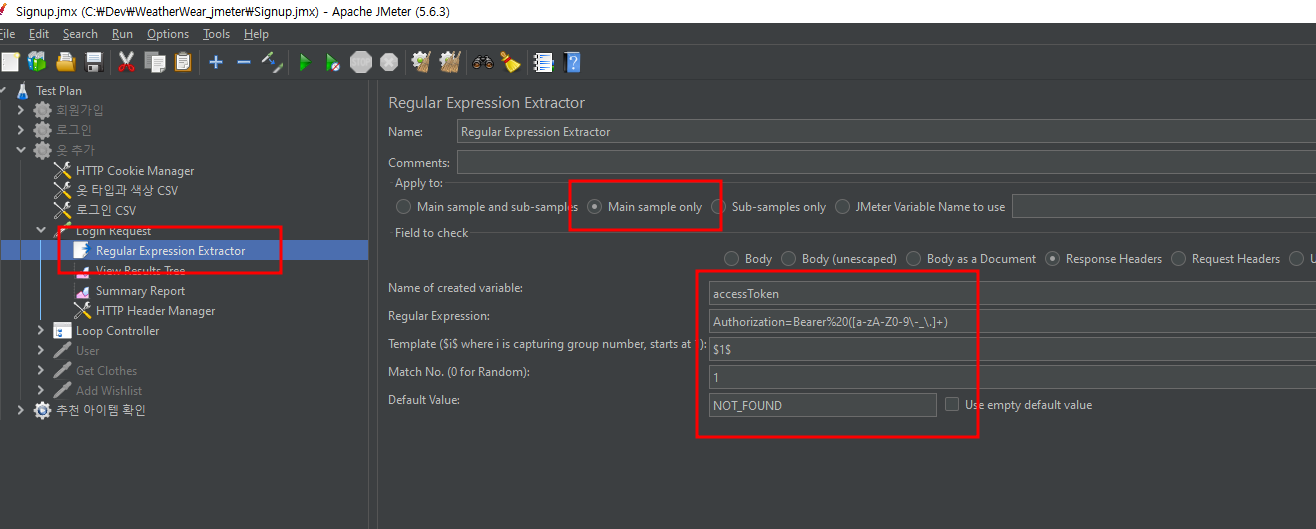
추가적인 설정이 필요하다. 해당 설정과 Regular Expression Extractor가 쿠키에 저장하고 토큰을 추출해서 요청에 보내는 역할을 해준다.
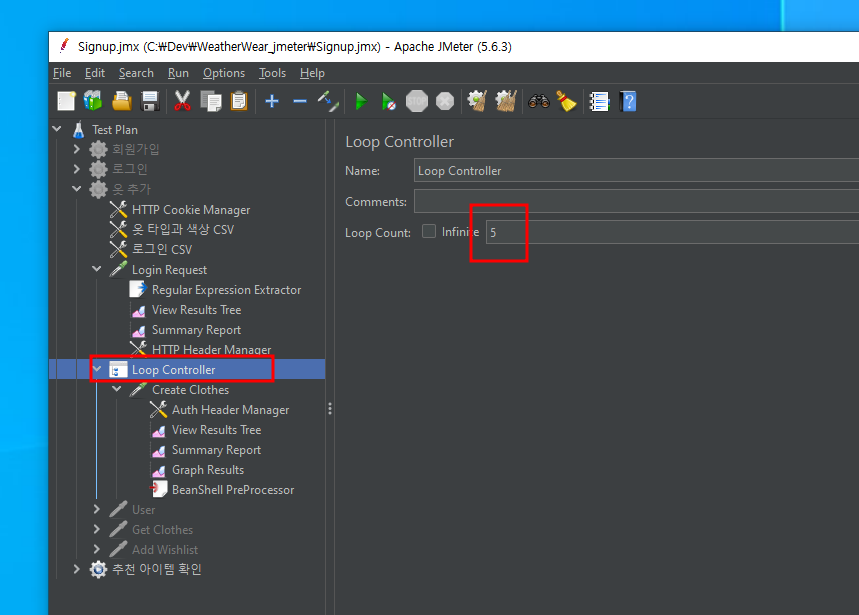
여기서 Loop를 넣었는데 로그인 후 5개씩 데이터를 넣도록 하기 위해 추가했다. Group에서 루프를 넣으면 로그인 과정도 계속 반복하기 때문이다.
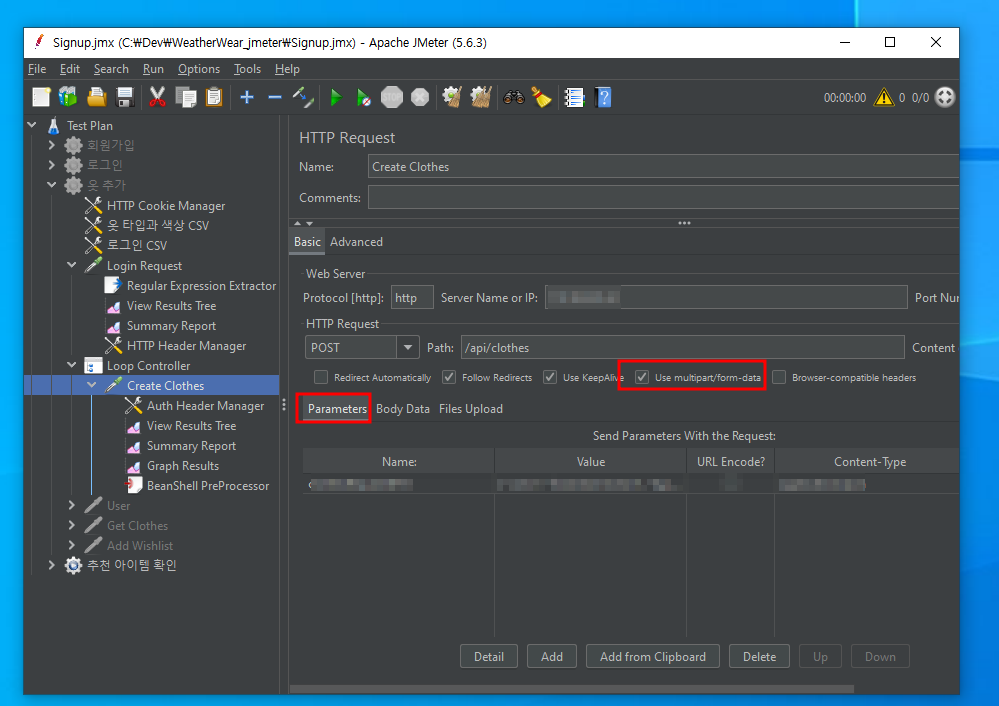
데이터의 경우 다음과 같이 넣었는데 파일과 json타입 데이터 모두를 추가해야 했기 때문이다. 따라서 form-data의 파라미터에 텍스트를 넣고
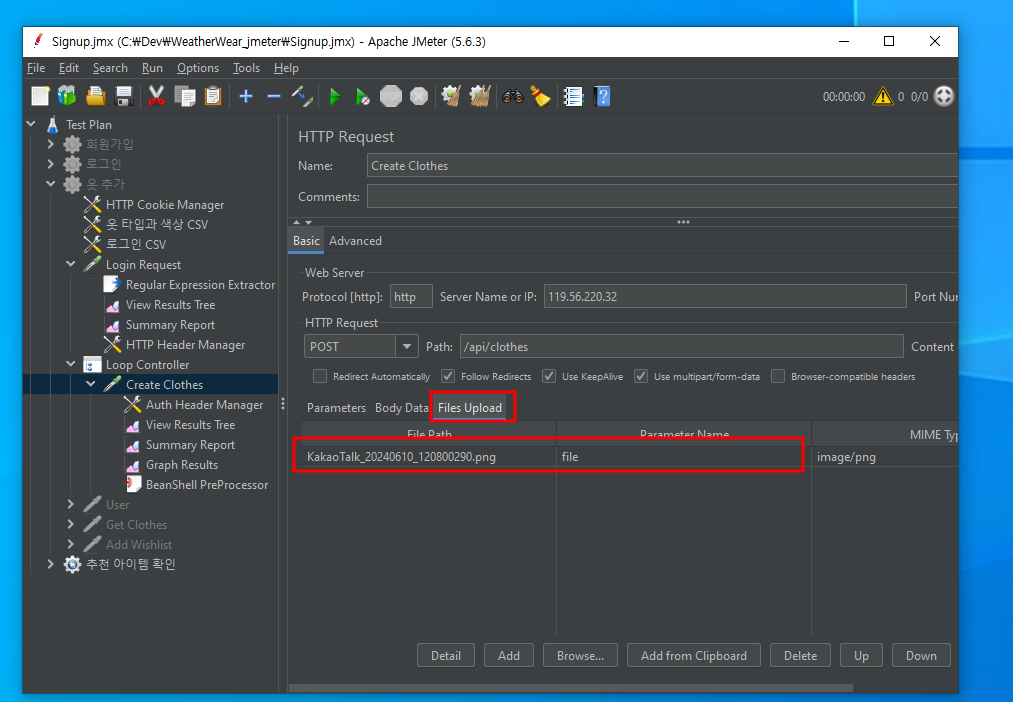
파일 데이터에 파일 경로와 파라미터 이름을 넣게 된다. 경로는 jmeter 경로를 기본으로 하는데 절대 경로를 넣어도 된다.
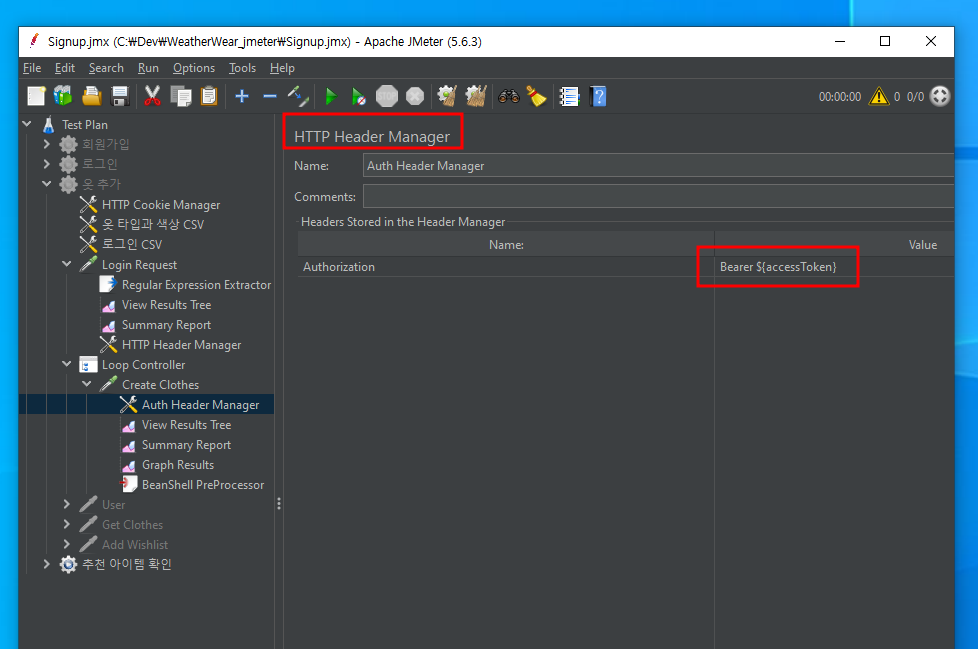
당연히 로그인한 사용자의 토큰을 쿠키에 넣어 보내야 처리가 되기 때문에 Header Manager를 선언하고 토큰 값을 넣도록 구현한다.
아직 궁금한점은 얼마나 요청해야하는가? 어떻게 부하를 측정하는가? 등 다양한 수치 선정과 결과 해석에 대해서 배워 볼 필요가 있을것이라 생각한다.
