⚠️ 들어가기 앞서
경북대학교 컴퓨터학부 COMP0414-001 컴퓨터망 과목을 공부하며 정리한 글입니다.
이전 글 : UDP detail 을 보고 오면 좋습니다.
1. TCP
앞서 살펴본 UDP와 상반되는 프로토콜인 TCP 역시 앞서 많이 다룬 바 있다. TCP는 요약하자면 다음과 같다.
TCP는 handshaking 과정을 통해 연결을 수립하고, 흐름 제어 및 혼잡 제어 기능 등 신뢰성 있는 연결을 제공하는 연결 지향형 프로토콜이다.
TCP의 또다른 특징 중 하나는 데이터 경계가 없다는 것이다. 예를 들어 100비트 짜리 데이터를 3번 받았다고 가정했을 때 이를 한 방에 300비트를 읽어오는 것이 가능하며, 100비트 데이터를 받았을 때 이를 50비트씩 두 번에 걸쳐 읽어오는 것 또한 가능하다.
마치 사탕이 들어있는 사탕 봉지를 받으면, 그 봉지를 뜯어 사탕을 낱개로 관리하고 있다고 보면 된다.
2. TCP segment structure
이제 TCP에서 주고받는 segment의 구조에 대해 살펴보자. 꽤나 힘든 여정이 될 것 같다...
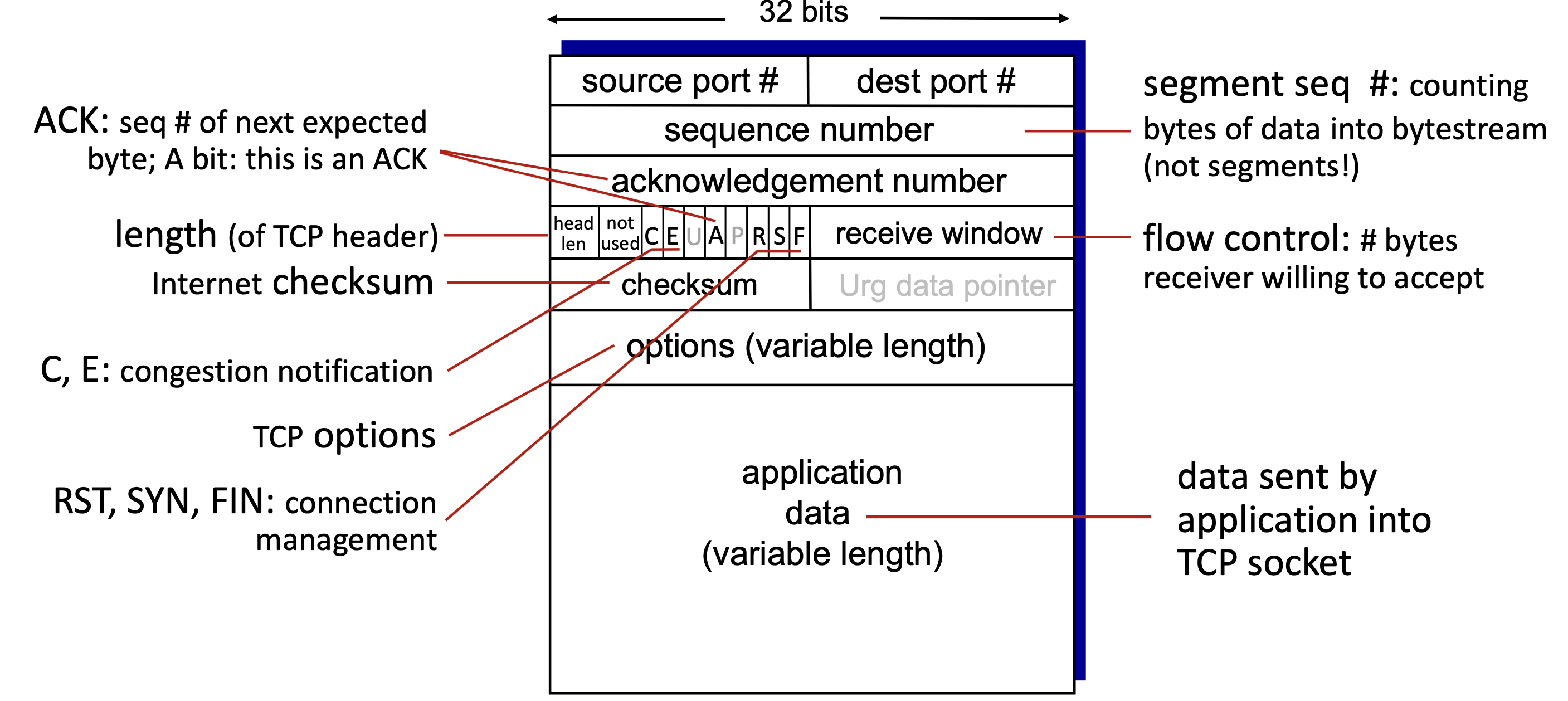
순서 보장, 흐름 제어, 혼잡 제어 등 TCP가 UDP에 비해 더 많은 기능을 제공하는 만큼 훨씬 더 복잡하다... 위에서부터 하나씩 차근차근 뜯어보자!
-
먼저
source port #와destination port #는 UDP와 동일하며, 송신, 발신자의 소스 번호를 나타내고 있다. -
sequence number의 경우 segment 안의 데이터의 위치를 가리킨다.
말이 좀 어려운데 예를 들어보면 간단하다. 10,000 bit 짜리 데이터를 1,000 bit의 10개의 segment로 나누어 보냈다고 가정했을 때, 어떤 segment는 원본 데이터의 0~999번째 비트를, 또 어떤 segment는 원본 데이터의 1000~1999번째 비트를, 또 어떤 segment는 원본 데이터의 5000~5999번째 비트를 담고 있을 것이다. 그러한 segment 위치의 시작점을 나타낸다. 즉segment끼리의 순서 보장에 필요한 필드인데, 여기서 중요한 것은segment의 번호로써 1, 2, 3번... 이 붙는 것이 아니고byte counting의 개념으로써0바이트, 1000바이트, 2000바이트...이런 식으로 비트 단위의 offset을 나타낸다는 점이다. -
acknowledgement number는 수신자가 다시 송신자에게ACK를 보낼 때 사용하는 필드로,다음에 받기를 원하는 데이터의sequence number를 의미한다. 즉 아까와 같은 예시 상황에seq. number가 0인 segment를 잘 받았으면ack. number에는1000이 들어가 있다. -
그 다음 부분은 16bit가 더 세부적으로 쪼개져 있다.
headlen: 헤더의 크기를 나타낸다. 조금 다르게 말하면 어디서부터 데이터가 시작되는지 offset을 담고 있다.not used: 미래에 사용하기 위해 비워둔 곳으로 사용되지 않음C,E: 혼잡 제어에 사용되는 부분이며,C는 현재 네트워크 상황이 혼잡하여 데이터 양을 줄였다는 사실을 알리기 위해 송신자 측에서 설정하는 필드이며,E는현재 네트워크가 혼잡하다는 사실을 알리기 위해 수신자 측에서 설정하는 필드이다.U: queueing 되어 있는 다른 데이터보다 먼저 처리되어야 하는 urgent message 여부를 나타낸다.A: 1로 세팅되어 있으면이 segment는 ACK이다를 나타낸다.P:push에 대한 요청 여부이며, threshold까지 기다리지 말고 바로 전달하라는 의미이다.R, S, F: 각각RST, SYN, FIN을 나타내며 각각의 비트가 1이면 reset, connection initiation, connection finish 를 나타낸다.
-
receive window: 수신 측의 window 크기, 즉 받아들일 수 있는 데이터의 크기를 나타낸다. 16비트 필드이므로2^16bits가 받아들일 수 있는 데이터의 최대 크기라고 생각할 수 있는데, 곱해지는scaling factor가 존재하여 더 큰 크기를 표현할 수 있다. -
checksum: 앞서 UDP 글에서 다루었던 오류 검증 필드이다. -
Urg data Pointer: 긴급 데이터의 위치를 나타낸다. 해당 데이터를 우선 처리한다. -
options: options 위까지가 고정적인 header 크기이며 이 부분은 선택사항이다. 기타 유용하게 사용할 수 있는 정보가 들어있으며 위의headlen에 의해 이 부분의 길이가 정해진다. -
Application data: 실질적으로 전달되는 데이터. 응용 계층으로 전달된다.
3. 기타
TCP RTT와 timeout
RTT는 송신자가 데이터를 보내고 그에 대한 응답을 받을 때까지 걸리는 시간이다. (RDT 정리 5번 단락 참조)
그리고 일정 시간을 기다려도 ACK를 받지 못하면 timeout을 발생시켜 재전송한다. 이전 글에서는 적절한 시간 이라고 하였지만 이번 소챕터에서는 보다 자세히 다룬다.
먼저, timeout 기준 시간은 당연히 RTT에 기반하여 설정되어야 한다. 정상적인 전송일 때 데이터에 대한 응답이 오는 시간보다 짧게 timeout을 설정하면 당연히 안 된다. ACK가 오기도 전에 timeout을 발생시킬 만큼 너무 짧게 설정하게 되면 불필요한 재전송이 많아지는, 이른바 premature timeout (섣부른 타임아웃) 이 발생하며, 너무 길게 설정하게 되면 segment loss에 대해 빠른 대처가 어려워지고 성능이 저하된다.
그렇다면 어떻게 RTT를 예상하고 적절한 시간을 설정할까?
송신자가 이전에 보냈었던 RTT 기록을 참조할 수 있을 것이다.
지금까지의 RTT들을 본 결과 평균 1ms 정도 걸렸다등의 추론이 가능하다. 그러나 지금까지 RTT가 낮았다고 이번에 보낼 segment의 RTT가 똑같이 낮을 것이라는 보장은 없다.
여기서 두 가지의 변수가 등장한다. sampleRTT 와 estimatedRTT 이다.
sampleRTT는 segment가 송신되고 ACK가 올 때까지의 시간, 즉 현재의 RTT다.
estimateRTT는 지금까지 측정한 RTT들의 평균이다.
이 두 변수에 고려 비중을 적절히 곱하여 이번에 보낼 segment의 estimatedRTT를 구한다.
estimatedRTT= (1-α)estimatedRTT+ αsampleRTT
보통 실험적 결과로써 α 값은 0.125를 많이 사용한다.
α 값이 높다는 것은 예전에 구한 평균값보다 가장 최근에 구한 것에 더 큰 비중을 두겠다 라는 뜻이다.
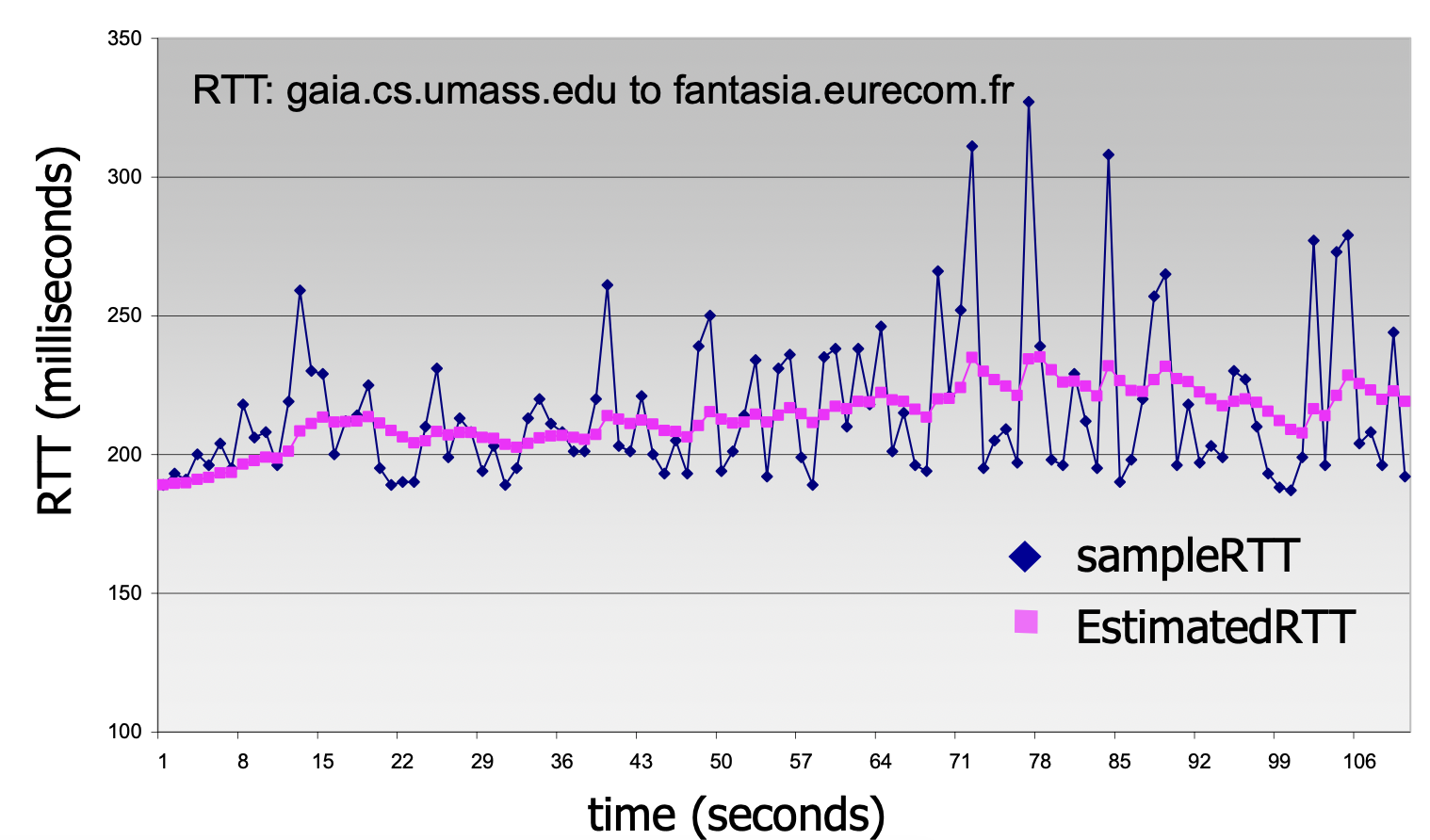
그리고 우리가 구하는 timeout interval은 이렇게 구한estimatedRTT 에다 4 * DevRTT(sample - estimatedRTT, 즉 오차의 평균)를 더해준다. 이는 safety margin 으로, 소위 말하는 '안전빵', 즉 널널하게 잡는 것이다.
TimeoutInterval = EstimateRTT + 4 * DevRTT
retransmission 예시
다음은 segment를 재전송하는 몇 가지 예시 사례이다.
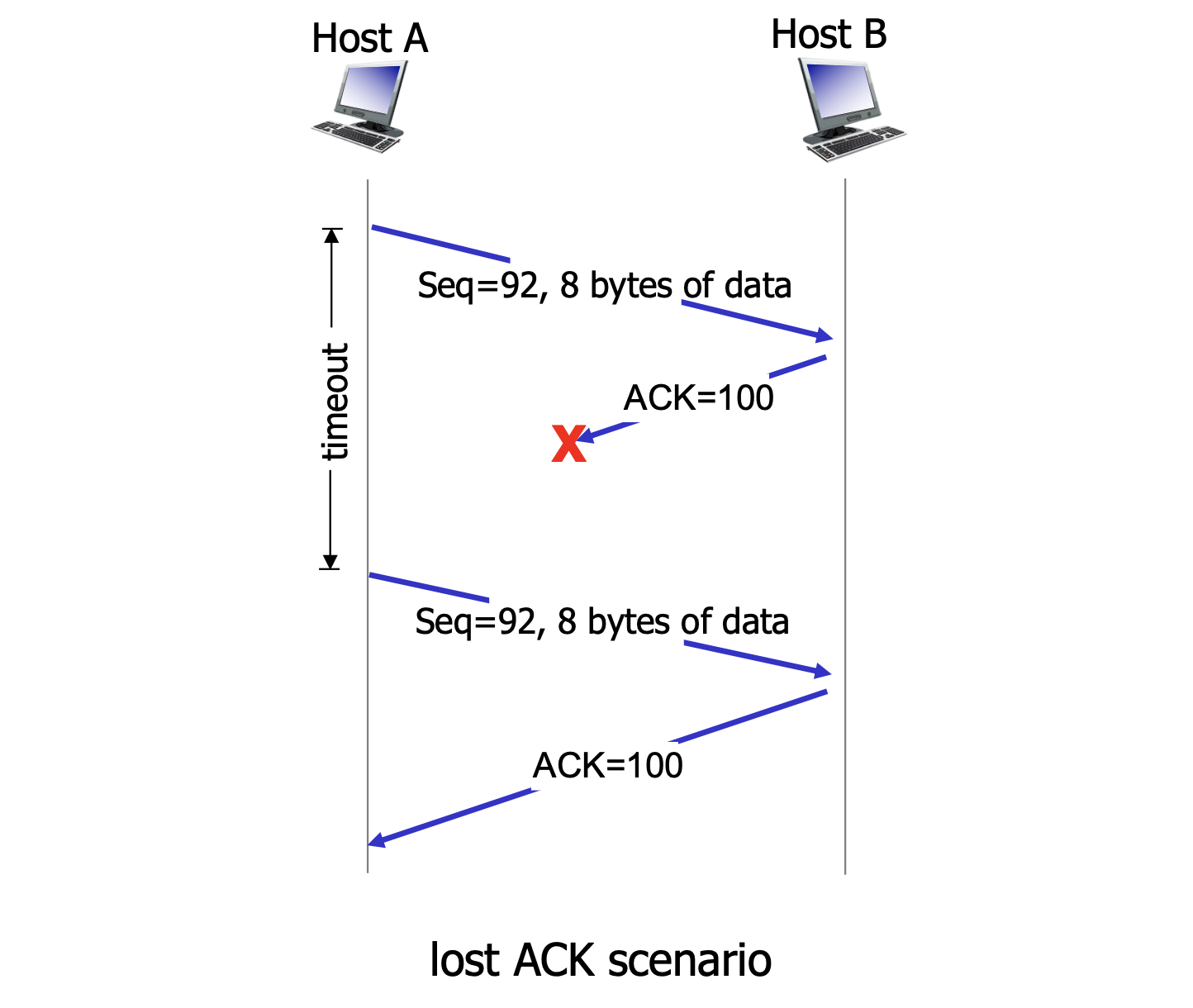
ACK loss
premature timeout
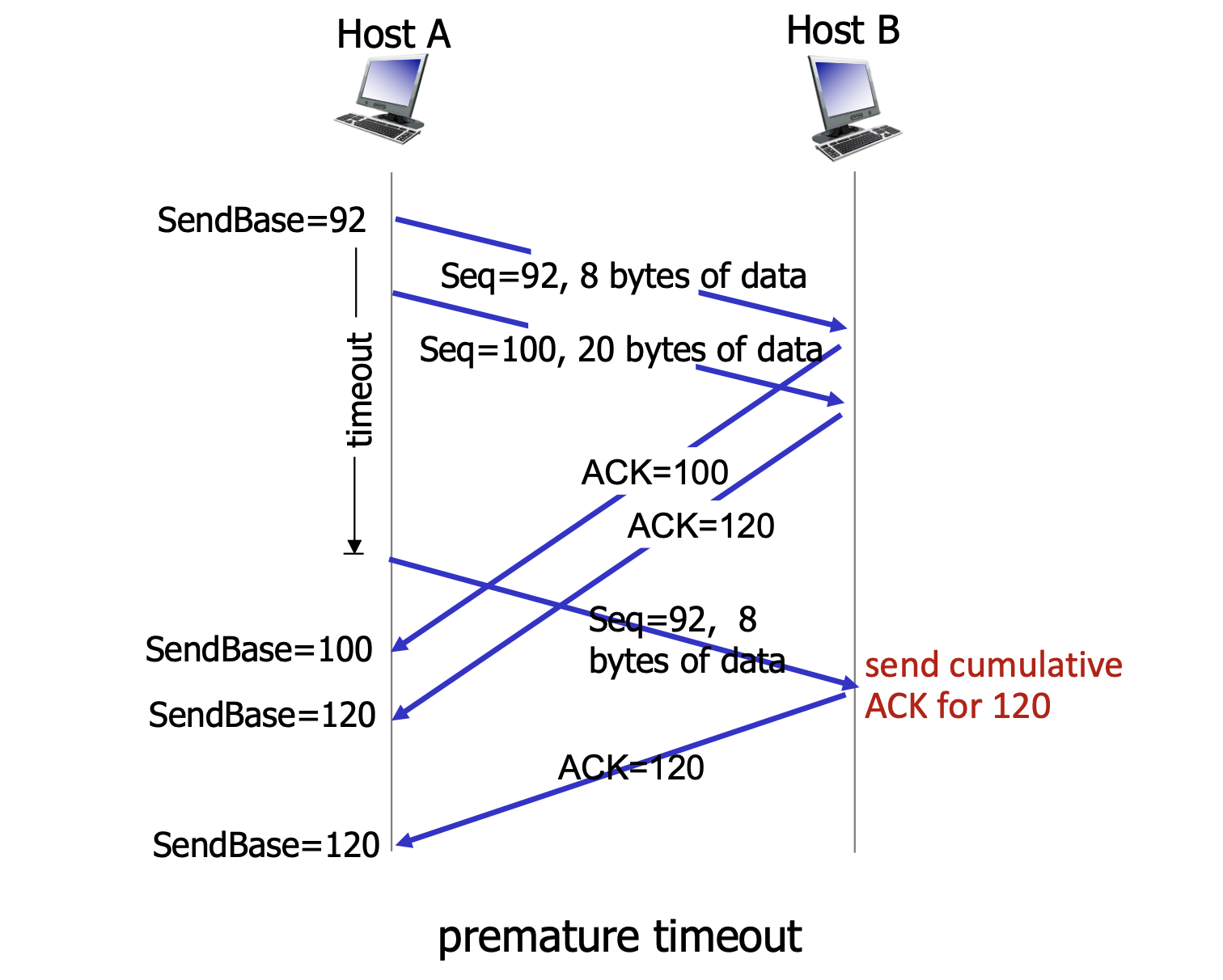
수신자에게서 ACK를 받고 나서야 sendbase 를 증가시키는 것을 볼 수 있다.
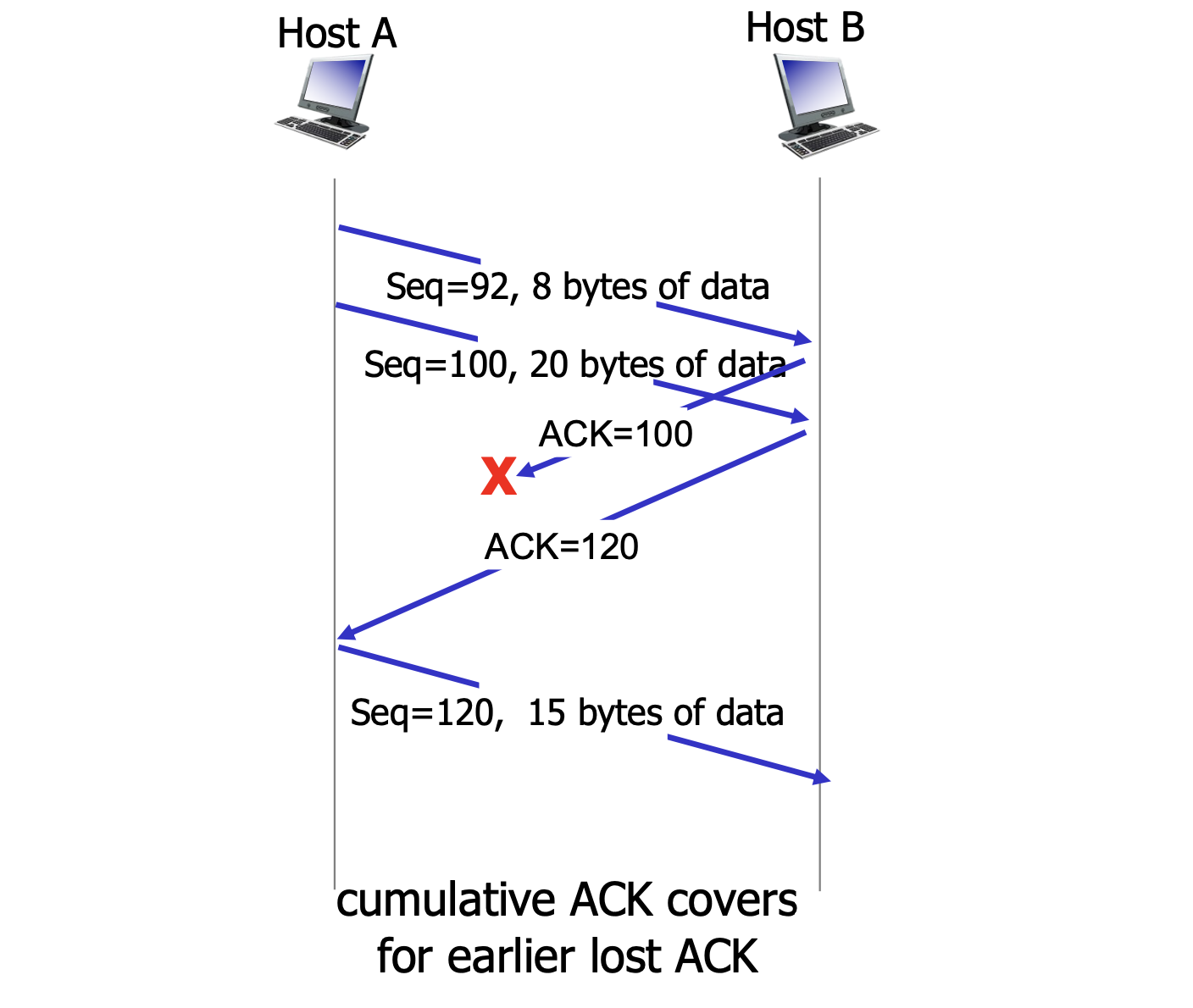
두 개의 연속된 segment를 둘 다 잘 받았는데 첫 번째 segment에 대한 ACK가 유실되어도 cumulative ACK를 통해 timeout이 발생하지 않고 앞의 segment도 ACK를 받았다고 간주하는 모습이다. 즉 하나의 ACK로 여러 segment를 처리할 수 있는 장점이 있다.
fast retransmit
timeout이 되기 전에 segment의 유실 여부를 판단하고 재전송(retransmit)할 수 있는 방법이 있다.
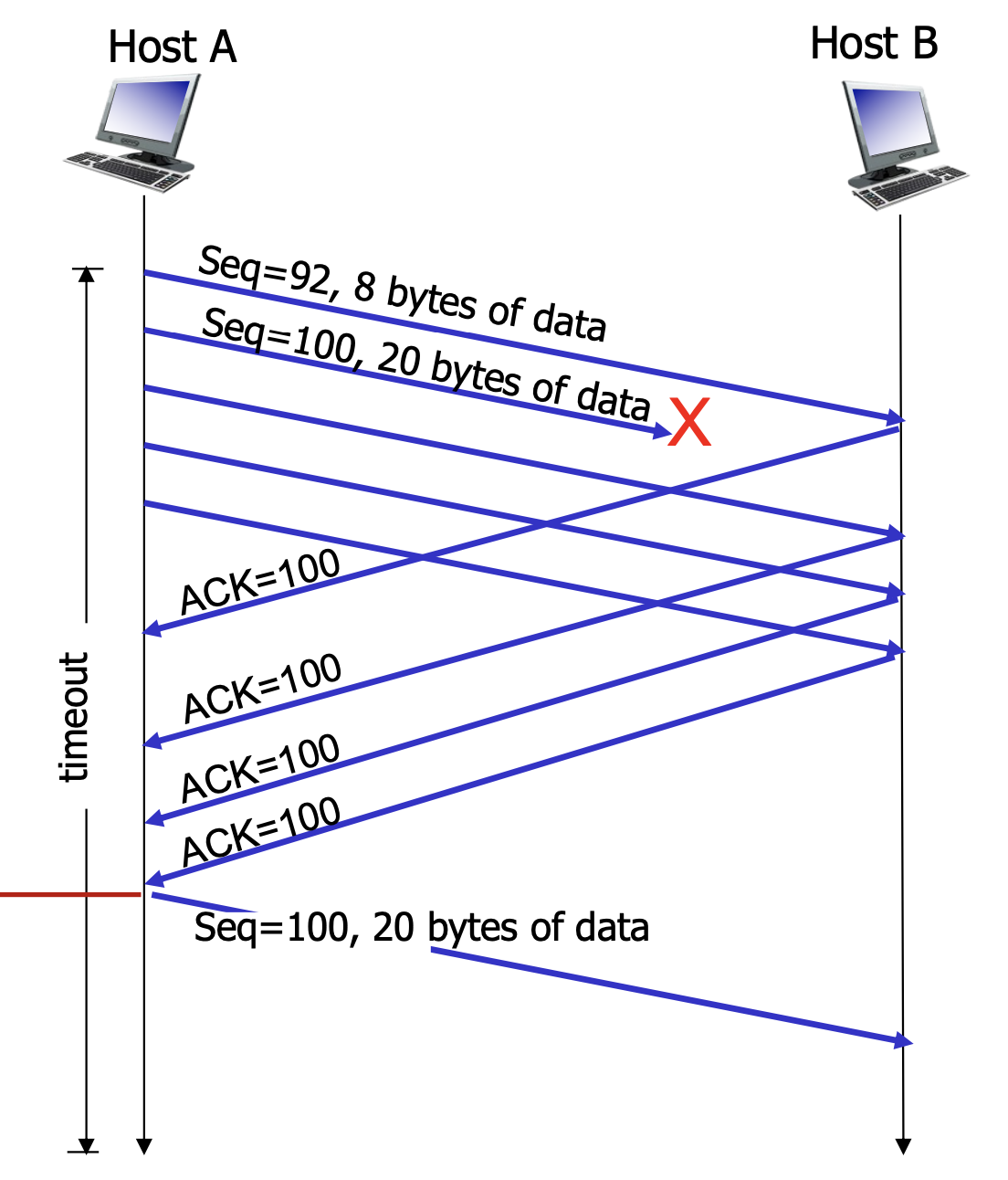
바로 중복된 ACK를 여러 번 받는 것 이다.
🖥️ : 야! 임마! 이거 못 받았다고!
seq 번호가
100인 segment의 timeout interval이 길게 설정되어 있어도ACK(100)을 4번째 받을 때, 즉 중복ACK가 3개 쌓이면 그 segment를 즉시 재전송한다.
flow control
네트워크 계층이 데이터를 전송해주는 속도보다 응용 계층이 데이터를 처리하는 속도가 더 느리면 어떡할까?
이전에 queueing delay 부분을 다루면서 언급했었던 부분이며, 처리하는 속도보다 데이터가 쌓여가는 속도가 더 빠르면 큐가 계속해서 차게 되고 결국 packet loss가 발생한다.
그렇다면 보내는 측에서 데이터를 받는 상대방의 버퍼 여유 공간을 보고 데이터를 전송해 주는 속도를 조절하면 좋지 않을까?
TCP 수신자는 자기가 갖고 있는 버퍼의 여유 공간을 송신자에게 알려, 송신자로 하여금 데이터 전송 속도를 늦추게 할 수 있다. 이러한 과정을 거쳐 수신자의 버퍼가 overflow 나지 않게 한다.
이 때 free buffer space를 rwnd 라고 한다.
여유 공간 정보는 TCP segment의 receive window 부분에 명시되어 송신자에게 되돌아간다.
rwnd = RcvBuffer - (LastByteRcvd - LastByteRead)
= RcvBuffer - (수신했지만 상위 계층으로 전송하지 않은 데이터들)
handshaking
TCP는 (양방향) 연결 지향형 프로토콜로서, 데이터의 교환 이전에 handshaking을 통해 연결을 수립한다.
두 호스트 간에 "우리 이제부터 서로 통신을 하자" 라고 얘기하는 과정이라고 할 수 있다. 이렇게 연결을 수립/해제하는 과정을 handshaking 이라고 한다.
그리고 두 호스트는 handshaking 과정을 통해 서로 연결되었음을 합의하는 것 뿐만 아니라 starting sequence number 또한 알 수 있다. (서로 간에 SYN 메시지로 특정 sequence number를 명시해서 보내고, 상대방은 이에 알았다는 뜻으로 +1 한 값을 ACK에 보낸다)
2-way handshaking?
그렇다면 연결을 수립할 때 handshaking은 어떻게 이루어져야 할까? 다음과 같은 대화를 보자.
A : 우리 이제부터 연결하자.
B : 오케이.
이 대화는 문제가 없어 보이지만 잠재적인 문제가 있다.
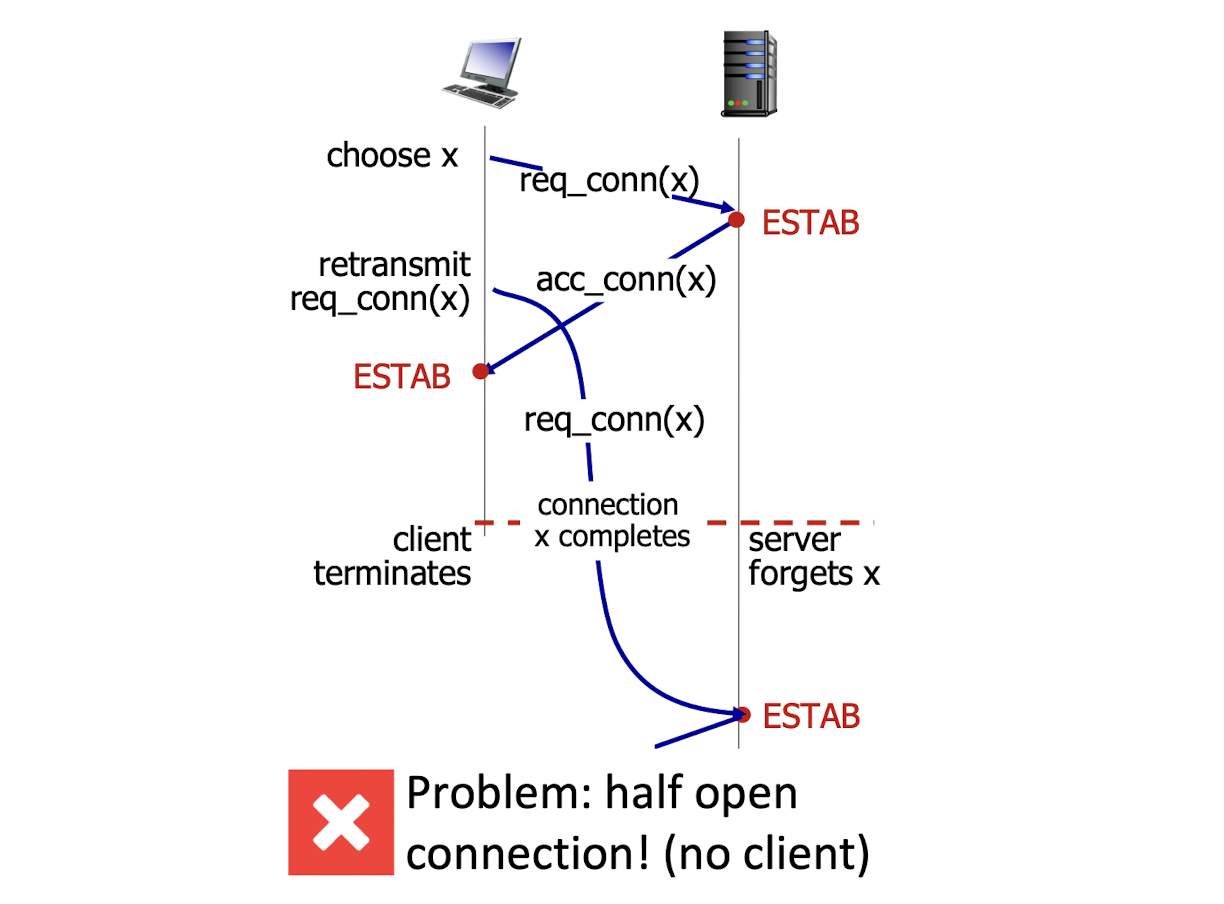
첫 번째로, A의 SYN에 대해 B의 ACK가 도달하기 전에 timeout이 발생하는 경우이다.
A가 seq 100으로 SYN을 보냈을 때 B가 이에 대한 응답으로 ACK 101을 보냈는데, 이 ACK가 도착하기 전에 A의 timeout 발동으로 인해 seq 200으로 다시 SYN을 보내는 상황이 발생했다. 이러면 A는 자기의 seq number가 200으로 바뀌었으니 101에 대한 ACK를 무시한다. 그리고 B가 생각하고 있는 A의 seq number와 실제 A가 다르게 되는 것이다.
두 번째로, B는 본인의 ACK가 잘 전송되었는지 알 수 없다.
B의 ACK에 A도 "잘 받았다" 라는 응답을 해 주어야 양방향 통신을 표방하는 TCP가 신뢰성을 보장해 줄 수 있을 것이다.
3-way handshaking
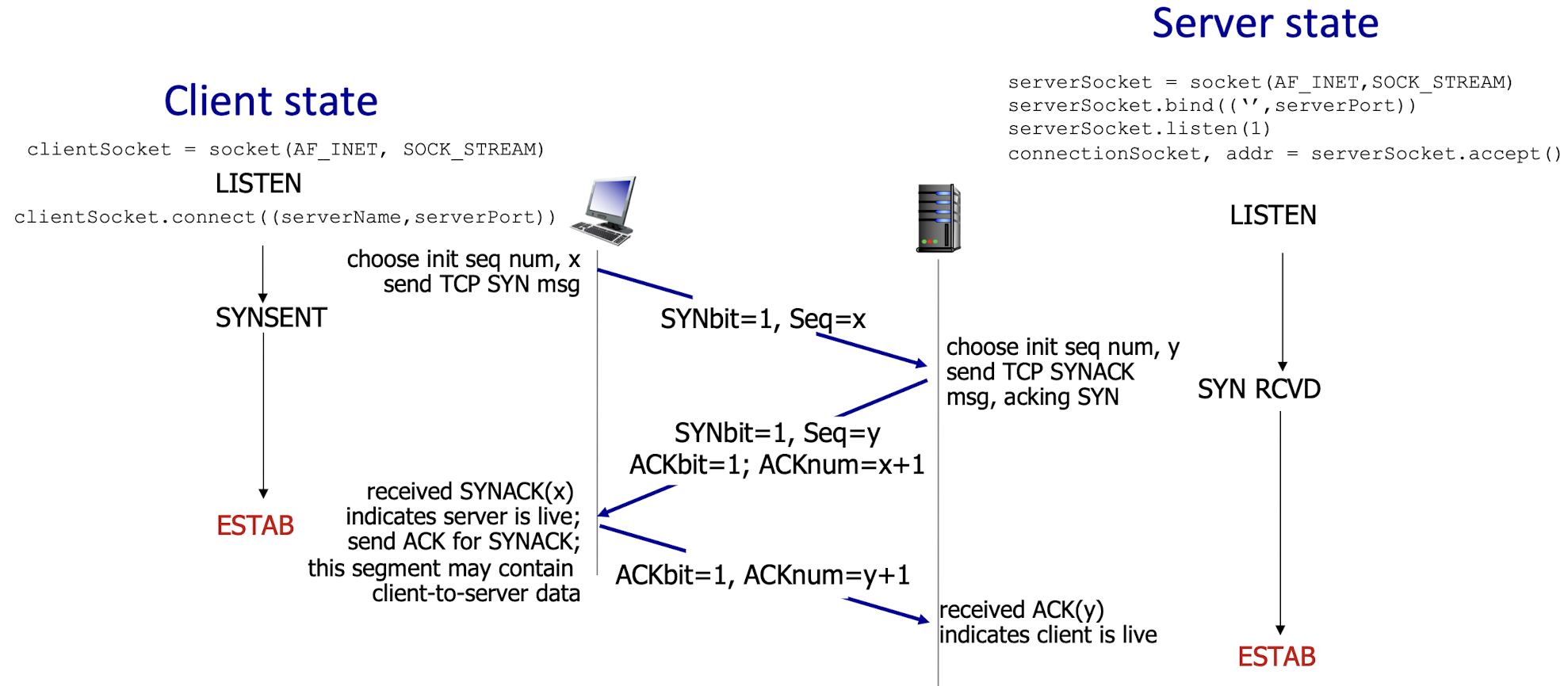
앞서 2-way handshaking에 대한 문제점을 살펴보았고 따라서 마지막 A의 ACK의 필요성을 알게 되었다. 마지막 A의 ACK로서 끝나는 handshaking이 바로 온전한 연결 수립, 3-way handshaking이다.
그리고 두 호스트는 각각의 메시지 교환 시점에 따라 상태가 바뀌게 된다.
먼저 송신자를 살펴보면, 맨 처음 SYN을 보낸 직후부터 ACK를 받기 전까지 SYN_sent 상태가 되며, ACK를 받은 뒤로는 Established 상태가 되어 연결 준비를 마치게 된다.
그리고 수신자는 SYN을 받기 전까지는 송신자의 메시지를 기다리고(듣고) 있는 listen 상태였다가, ACK를 보낸 후에는 SYN_received 상태가 되며, 본인의 ACK에 대한 상대방의 ACK를 받은 후에는 Established 상태가 되어 연결 준비를 마치게 된다.
4-way handshaking
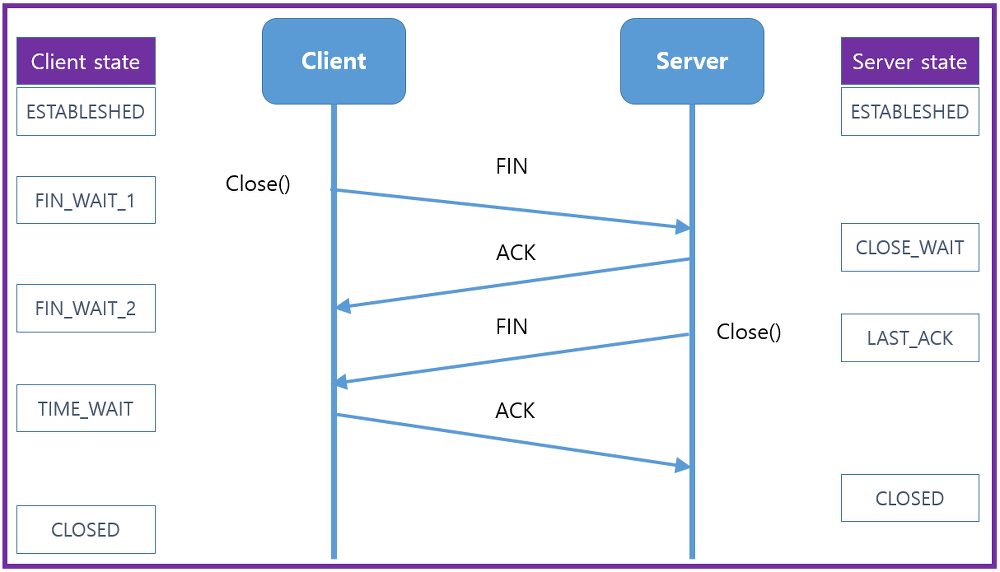
두 호스트 간의 연결을 끊을 때에도 handshaking이 필요하다.
만약 송신자 측에서 "나는 보낼 거 다 보냈음" 하고 연결을 끊어버리면, 수신자가 아직 보낼 데이터가 남아 있을 수도 있는데 일방적으로 끊는 셈이 된다. 반대도 마찬가지.
즉 상호 간에 "나는 너한테 보낼 데이터 다 보냈고 더이상 보낼 것은 없다" 라고 확인이 되어야 연결을 끊을 수 있다.
즉, 송/수신자 간에 연결을 끊자는 뜻의 FIN 과 거기의 응답인 ACK가 두 번 오간다.
마찬가지로 두 호스트는 각각의 메시지 교환 시점에 따라 상태가 바뀌게 된다. (위 그림 참조)
