스트림이란
데이터를 연속적으로 처리하는 개념으로 데이터의 흐름을 나타내는 추상화된 모델이다.
쉽게 말하면 데이터가 한 곳에서 다른 곳으로 이동하는 통로라고 이해하면 된다.
스트림은 일반적인 컬렉션과 다르게 데이터 흐름에 초점을 맞춘 개념이다.
오라클 공식 문서에 따르면 자바 스트림은 순차 및 병렬적인 집계 연산을 지원하는 연속된 요소로 정의된다고 하는데.. 이렇게 말해서는 모르겠다.
스트림은 데이터의 집합보다는 flow, 즉 데이터 흐름으로 생각할 때 이해가 더 쉬워짐.
Stream의 개념
- 스트림은 데이터를 물처럼 흐르게 하는 개념이다.
- 데이터는 한 번에 모든 것을 처리하는 것이 아니라 순차적으로 한 조각씩 흐르면서 처리된다.
- 데이터를 읽고 쓰는 방식에서 입출력(I/O) 연산을 효율적으로 수행할 수 있도록 설계되었다.
강물(Stream)을 떠올려 보자면
데이터는 물과 같고, 스트림은 강물의 흐름처럼 데이터를 전달하는 통로!!
한 번 지나간 물(데이터)은 다시 돌아오지 않고 순차적으로 처리된다.
스트림 구조
스트림을 세 파트로 분류하자면 생성, 가공, 소비로 분류할 수 있다.
생성
생성은 리스트, 맵과 같은 컬렉션에서 시작할 수 있고, 배열이나 파일에서도 생성할 수 있다.
컬렉션과 달리 스트림은 무한을 생성할 수 있고, 서드파티 라이브러리를 활용할 수 있다.
가공
가공 단계에서 중간연산자에는 필터, 맵, 리밋 등, 소스로부터 값을 조정한다.
중간연산자는 새로운 스트림을 반환하는데 이를 통해 lazy evaluation이 가능하다.
Lazy evaluation은 최종 연산이 들어오기 전까지 중간 연산이 실행되지 않음을 의미!!]
이는 새로운 스트림 인스턴스를 돌려주는 것에 그친다.

왼쪽과 같이 람다식의 프린트문을 작성했고, 오른쪽 결과물과 같이 모든 요소가 각 단계를 한 번에 거치는게 아니라 개별적인 요소가 하나씩 단계를 순차적으로 거쳐가는 모습이 반복문이 합쳐진 것 같다고 해서 이걸 루프 퓨전이라고 표현한다.
스트림 파이프라인이란 개념은 루프 퓨전의 활용으로 더욱 실감할 수 있다.
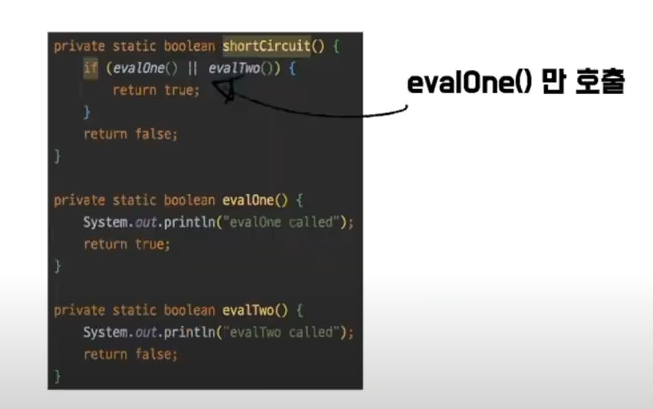
쇼트 서킷은 모든 논리 연산을 수행하지 않고, 결과가 확실할 경우 나머지 연산을 생략하는 것을 의미한다.
코드에서 OR 조건을 이용해 특정 메서드가 불필요하게 호출되지 않도록 하고, 스트림에서도 limit을 걸어주면 불필요한 연산이 줄어드는 것을 확인할 수 있다.
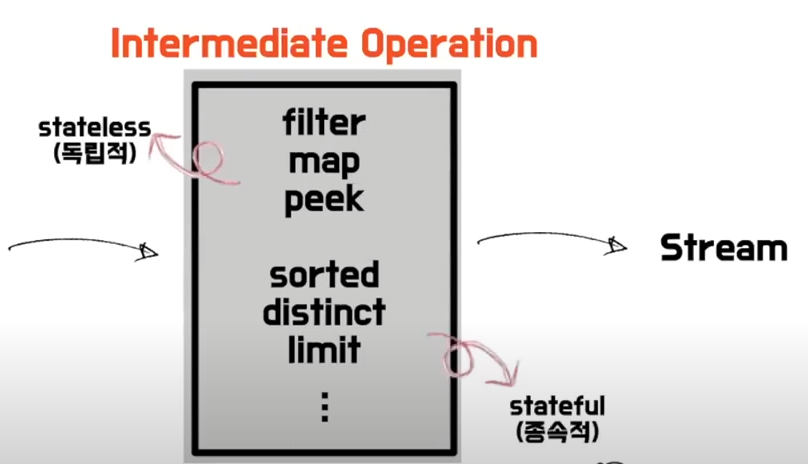
또 중간 연산자는 stateless와 stateful로 구분된다.
Stateless는 특정 행위를 수행할 때 다른 요소에 독립적으로 처리될 수 있음을 의미한다.
예를 들어서 맵 연산에서는 현재 바라보고 있는 값에만 신경을 쓰면 된다.
반면, stateful은 선행된 연산에 영향을 받고, 특정 상태를 알고 신경을 써야 한다.
Sorted와 distinct와 같은 중간 연산자가 이에 해당된다.
소비
마지막으로 최종 연산자는 결과를 생성하거나 사이드 이펙트를 만들기 위해 사용되고, 자주 사용되는 예시로는 collect, findAny, findFirst가 있다.
특히 collect의 경우 스트림패키지 내부에 있는 collectors라는 것을 이용하면 활용성이 정말 다양한데, 근데 소비하는 방법에 대해서는 종류가 너무 많고 다양하기 때문에 모두 다루기는 어렵다!! 그래서 여기서 최종 연산자에서는 두 가지 주의점만 짚고 넘어갈 것임.
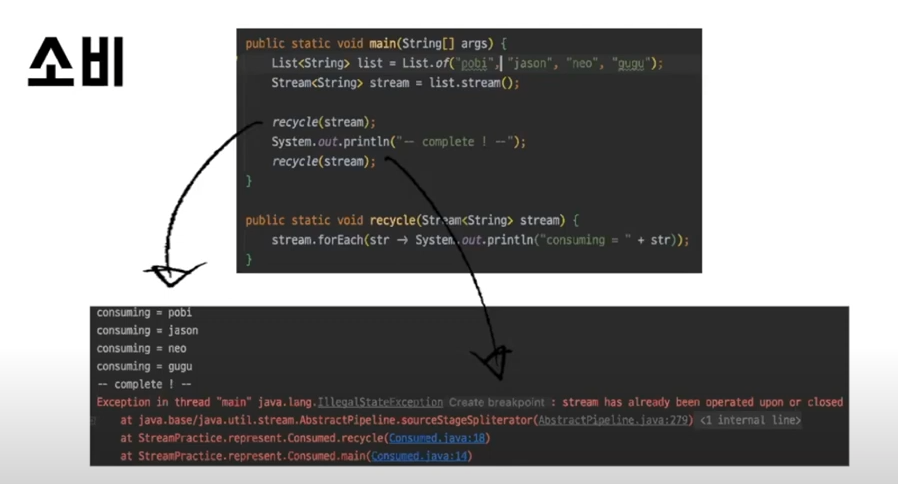
첫 째는 최종 연산자가 수행되면 스트림 파이프라인은 소비된 것으로 간주되어서 다시 사용하려면 새로운 스트림을 만들어야 한다.
이미지처럼 recycle이라는 메서드를 두 번 호출했는데, 첫 번째 recycle은 정상적으로 수행이 됐는데, 두 번째 recycle은 이미 소비되었다는 예외를 던지는 모습이 나온다.
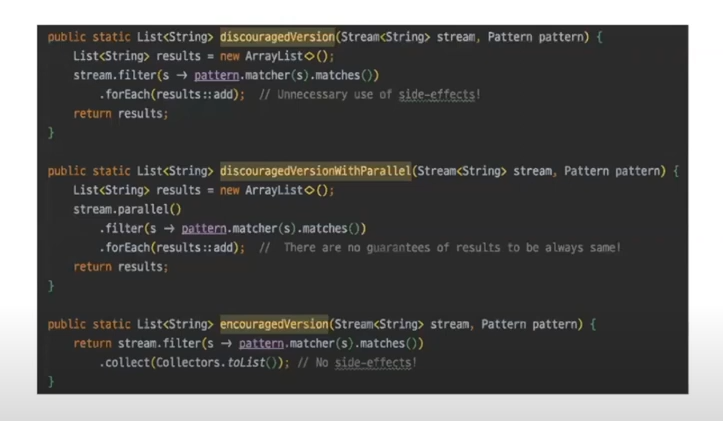
두 번째 forEach는 주로 로그나 디버깅 출력 용도로 사용할 것을 권장하고
또 이펙티브 자바에서는 forEach가 "덜 스트림스럽다"고 이야기한다.
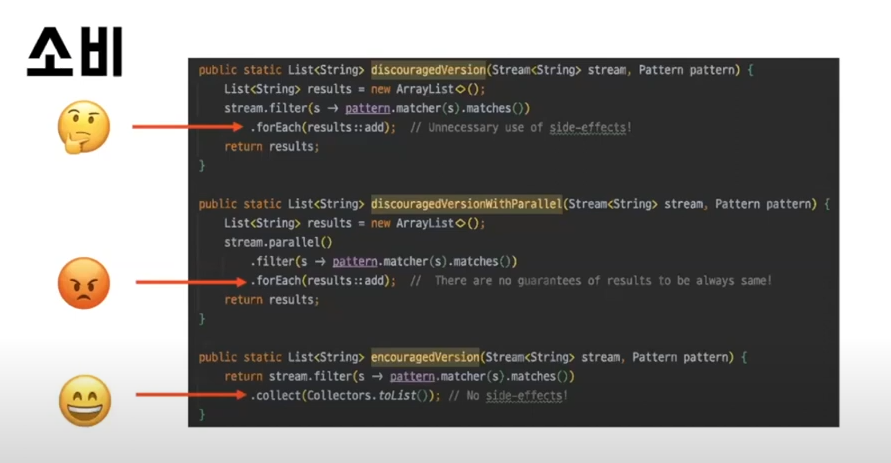
공식문서를 보면 알 수가 있는데, 첫 번째 메서드와 같이 forEach 내부에서 값을 할당할 경우 불필요한 사이드 이펙트를 발생시킬 수 있다.
또 이어서 두 번째와 같이 병렬처리가 추가될 경우에는 올바른 결과값을 기대하기 어렵다.
제일 하단에 있는 것과 같이 안정적인 collect 메서드를 활용하는 것이 바람직하다!!
사이드 이펙트를 통한 연산은 신중하게 사용해야 한다.
스트림의 장단점
장점
-
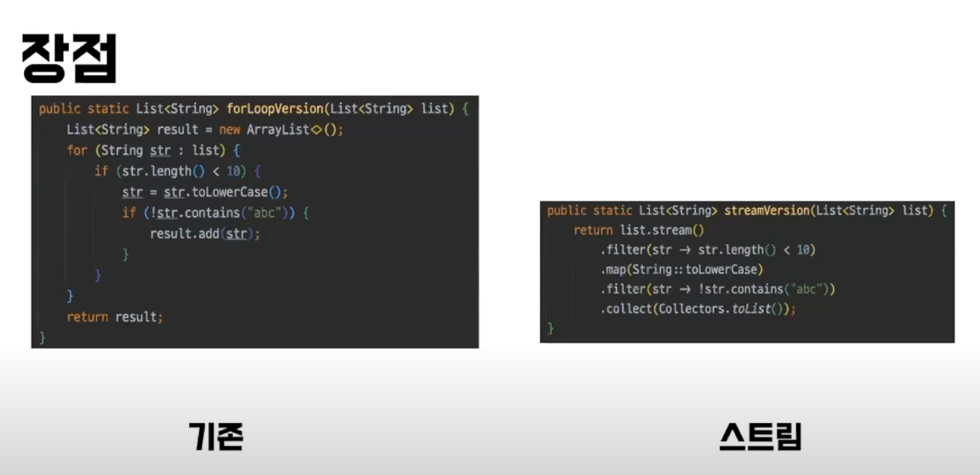
스트림을 사용하면 가독성이 높아져, 코드를 쉽게 이해할 수 있다.
예를 들어서 필터와 같은 메서드 네이밍 및 람다식을 이용해 코드의 동작을 간단히 파악할 수 있다. -
코드의 변경이 쉽고 유연하다.
메서드의 순서만 바꾸는 것으로 필터링의 순서를 조정할 수 있어 간단하게 수정할 수 있다.
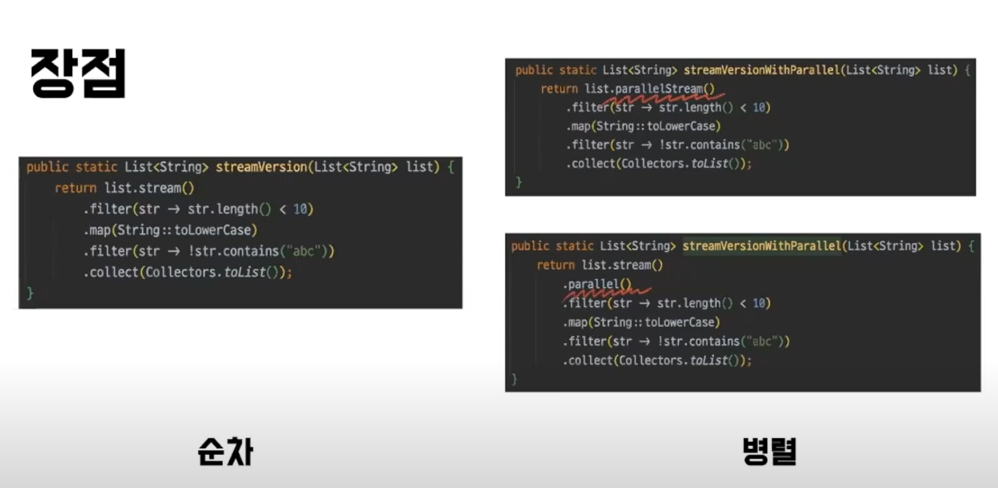
- 병렬처리의 용이성도 장점이다.
parallelStream이나 parallel 키워드를 추가하기만 하면 병렬처리를 지원할 수 있다.
단점
스트림의 첫 번째 단점은 높은 컴퓨팅 비용이다.
내부적으로 다양한 조건에서 연산을 처리하기 때문에 생성 비용이 많이 든다.
두 번째 단점은 인지 비용이다.
내부 반복이 일어나기 때문에 코드가 정상적으로 동작하지 않을 경우 원인을 파악하기 어려운 문제를 초래할 수 있다.
와.. 스트림은 겉핥기 식으로 데이터가 한 곳에서 다른 곳으로 이동하는 통로라고만 생각을 했는데
이렇게 깊게 얘기하니까 뭔말인지 하나도 모르겠다..
