import pandas as pd
import numpy as np
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head()| Species | Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 29.0 | 34.0 | 12.4440 | 5.1340 |
print(pd.unique(fish['Species']))['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
# fish_input = fish[fish.columns[1:]].to_numpy()print(fish_input[:5])[[242. 25.4 30. 11.52 4.02 ]
[290. 26.3 31.2 12.48 4.3056]
[340. 26.5 31.1 12.3778 4.6961]
[363. 29. 33.5 12.73 4.4555]
[430. 29. 34. 12.444 5.134 ]]fish_target = fish['Species'].to_numpy()fish_targetarray(['Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream',
'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream',
'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream',
'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream',
'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream', 'Bream',
'Roach', 'Roach', 'Roach', 'Roach', 'Roach', 'Roach', 'Roach',
'Roach', 'Roach', 'Roach', 'Roach', 'Roach', 'Roach', 'Roach',
'Roach', 'Roach', 'Roach', 'Roach', 'Roach', 'Roach', 'Whitefish',
'Whitefish', 'Whitefish', 'Whitefish', 'Whitefish', 'Whitefish',
'Parkki', 'Parkki', 'Parkki', 'Parkki', 'Parkki', 'Parkki',
'Parkki', 'Parkki', 'Parkki', 'Parkki', 'Parkki', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Perch',
'Perch', 'Perch', 'Perch', 'Perch', 'Perch', 'Pike', 'Pike',
'Pike', 'Pike', 'Pike', 'Pike', 'Pike', 'Pike', 'Pike', 'Pike',
'Pike', 'Pike', 'Pike', 'Pike', 'Pike', 'Pike', 'Pike', 'Smelt',
'Smelt', 'Smelt', 'Smelt', 'Smelt', 'Smelt', 'Smelt', 'Smelt',
'Smelt', 'Smelt', 'Smelt', 'Smelt', 'Smelt', 'Smelt'], dtype=object)from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(fish_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))0.8907563025210085
0.85# 아스키 코드 순서로 출력
print(kn.classes_)['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']print(kn.predict(test_scaled[:5]))['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']# predict_proba : 각 클래스별 확률값을 반환해 주는 메서드
# 각 행은 샘플 순서, 각 열은 classes_ 메서드로 반환되는 클래스 순서를 따름
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))[[0. 0. 1. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]]distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])[['Roach' 'Perch' 'Perch']]- 로지스틱 회귀
: 분류 알고리즘의 기본. 딥러닝에서 배울 인공신경망의 기초가 되는 알고리즘
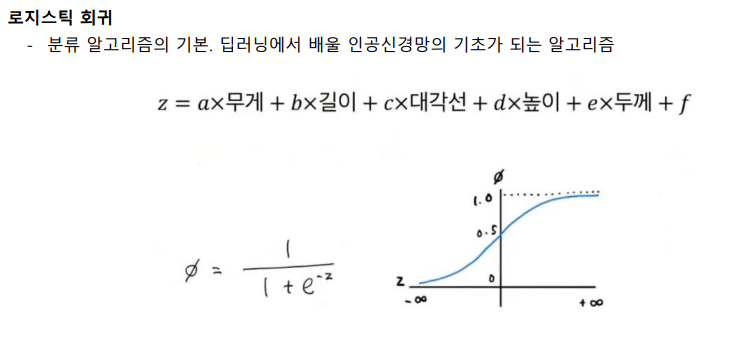
import matplotlib.pyplot as plt
z = np.arange(-5,5,0.1)
phi = 1 / (1 + np.exp(-z)) # 시그모이드 함수
plt.plot(z, phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()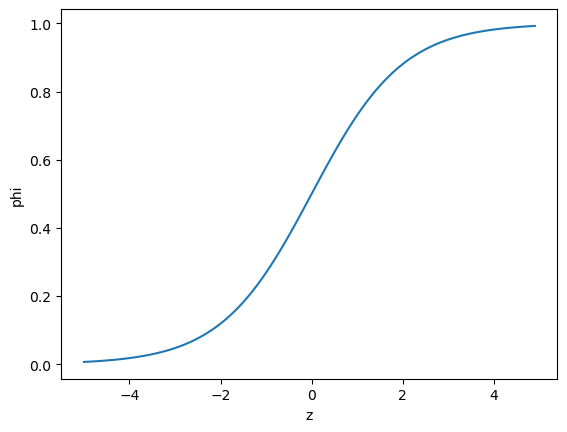
name = np.array(['foo','bar','baz','quz','quux'])
print(name)['foo' 'bar' 'baz' 'quz' 'quux']bol = np.array([True, False, True, True, False])
print(bol)[ True False True True False]name[bol]array(['foo', 'baz', 'quz'], dtype='<U4')char_arr = np.array(['A','B','C','D','E'])
print(char_arr[[True, False, True, False, False]])['A' 'C']# 분리형 인덱싱
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
print(lr.predict(train_bream_smelt[:5]))
print(lr.predict_proba(train_bream_smelt[:5]))
# [Bream일 확률 Smelt일 확률]['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
[[0.99746125 0.00253875]
[0.02849095 0.97150905]
[0.99461153 0.00538847]
[0.98515891 0.01484109]
[0.99754417 0.00245583]]print(lr.classes_)['Bream' 'Smelt']print(lr.coef_, lr.intercept_) # 각 특성에 곱해지는 가중치, 절편
# z = a*무게 + b*길이 + c*대각선 + d*높이 + e*두께 + f[[-0.42060794 -0.60027616 -0.68776093 -1.00279303 -0.74505586]] [-2.19130847]# decision_function: 양성 클래스에 대한 z값을 계산
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)[-5.97354273 3.52926408 -5.21809007 -4.19540298 -6.00682974]# 시그모이드
from scipy.special import expit
print(expit(decisions))[0.00253875 0.97150905 0.00538847 0.01484109 0.00245583]print(lr.predict(train_bream_smelt[:5]))['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']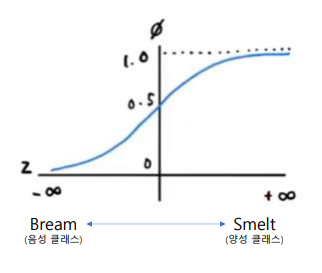

# 로지스틱 회귀로 다중 분류 수행하기
lr = LogisticRegression(C=20, max_iter=1000) # C: 규제값 - 클수록 완화
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
0.9243697478991597
0.925print(lr.predict(test_scaled[:5]))['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=3))[[0. 0.015 0.84 0. 0.136 0.007 0.003]
[0. 0.003 0.046 0. 0.008 0.944 0. ]
[0. 0. 0.035 0.935 0.017 0.014 0. ]
[0.012 0.034 0.316 0.007 0.556 0. 0.075]
[0. 0. 0.899 0.002 0.094 0.002 0.001]]print(lr.classes_)['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']print(lr.coef_.shape, lr.intercept_.shape)(7, 5) (7,)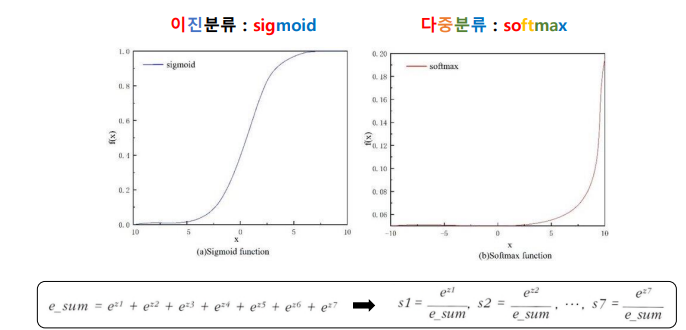
# 각각의 z 값
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals=2))[[ -6.26 1.05 5.1 -2.83 3.27 0.33 -0.66]
[-10.49 1.95 4.69 -2.58 2.92 7.72 -4.22]
[ -4.03 -6.13 3.08 6.37 2.34 2.16 -3.78]
[ -0.62 0.41 2.63 -1.2 3.19 -5.6 1.19]
[ -6.11 -1.92 5.71 -0.24 3.45 -0.2 -0.69]]# 소프트 맥수 함수
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))[[0. 0.015 0.84 0. 0.136 0.007 0.003]
[0. 0.003 0.046 0. 0.008 0.944 0. ]
[0. 0. 0.035 0.935 0.017 0.014 0. ]
[0.012 0.034 0.316 0.007 0.556 0. 0.075]
[0. 0. 0.899 0.002 0.094 0.002 0.001]]# 각 클래스에 속할 확률
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=3))[[0. 0.015 0.84 0. 0.136 0.007 0.003]
[0. 0.003 0.046 0. 0.008 0.944 0. ]
[0. 0. 0.035 0.935 0.017 0.014 0. ]
[0.012 0.034 0.316 0.007 0.556 0. 0.075]
[0. 0. 0.899 0.002 0.094 0.002 0.001]]# 확률적 경사 하강법
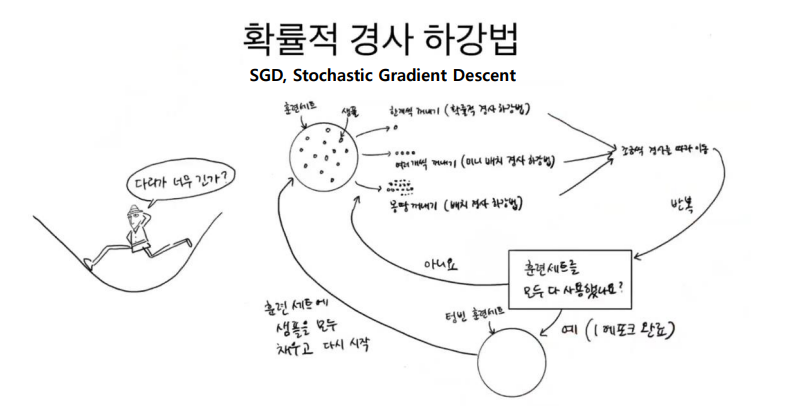
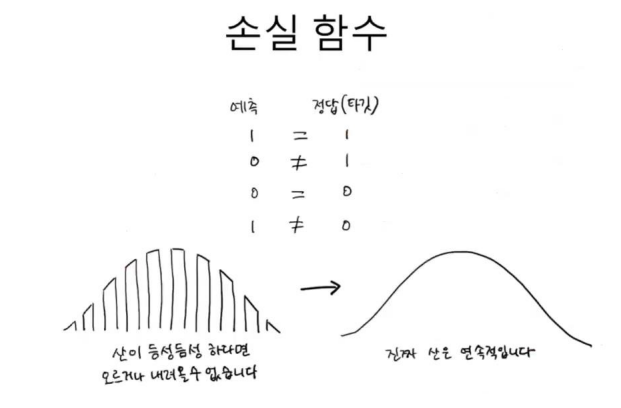

로지스틱 손실 함수 = 이진 크로스엔트로피 손실 함수
타겟이 양성일때는 그대로, 음성일때는 1에서 뺌 ---> 마이너스
양성클래스가 될 확률 - 로지스틱
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head()| Species | Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 29.0 | 34.0 | 12.4440 | 5.1340 |
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)# 확률적 경사 하강법 - 점진적 학습이 필요할 때
from sklearn.linear_model import SGDClassifier# loss 손실함수 - log_loss 로그 적용, max_iter 수행할 에포크 횟수(에포크: 한 사이클)
sc = SGDClassifier(loss='log_loss', max_iter=10, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
# 테스트가 더 높음 - 과소적합
# 경고: 에포크 늘려라0.773109243697479
0.775
c:\ProgramData\anaconda3\envs\ML\Lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:744: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
warnings.warn(# partial_fit: 에포크를 한 번씩 추가로 이어서 훈련 가능
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))0.8151260504201681
0.85
import numpy as np
sc = SGDClassifier(loss='log_loss', random_state=42)
train_score = []
test_score = []
classes = np.unique(train_target)for _ in range(0,300):
# 클래스 종류에 뭐가 있는지 미리 알려줘야 실행 가능
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))import matplotlib.pyplot as plt
plt.plot(train_score)
plt.plot(test_score)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()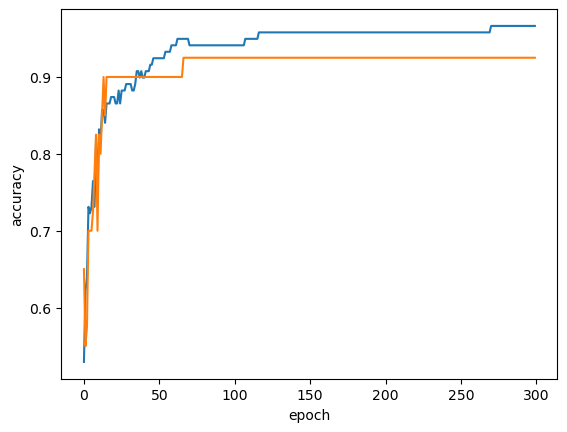
# tol: 이전 에포크와 이번 에포크의 차이가 tol이 지정해준 실수보다 작으면 반복을 멈춰라
sc = SGDClassifier(loss='log_loss', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))0.957983193277311
0.925
sc = SGDClassifier(loss='hinge', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))0.9495798319327731
0.925선형 - 로지스틱/ 비선형 - svm

공부 노트