네이버 주가 데이터 처리
import pandas as pd
import requests
import warings
warings.filterwarings('ignore')
# 0단계-크롬 개발자 도구를 통해 사이트에서 target url을 얻어야 됨
# 1단계-url 획득
code, page, pagesize = 'KOSPI', 1, 20
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={pagesize}&page={page}'
# 2단계-서버에 데이터 요청 : request(url) > response : json(str)
response = requests.get(url)
response
:<Response [200]>
->정상인지 확인
reponse.text
->json인지 html인지 확인
#3단계-데이터 형태를 변경 ;json(str) > list, dict > DataFrame
data = response.json()
kospi = pd.DataFrame(data)[['localTradedAt', 'closePrice']]
#4단계-함수로 만들기
def stock_crawling(code='KOSPI', page=1, pagesize=60):
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={pagesize}&page={page}'
response = requests.get(url)
data = response.json()
return pd.DataFrame(response.json())[['localTradedAt', 'closePrice']]
1, 2, 3 단계를 하고 그냥 가져온거임.
#5단계-객체 생성
kospi_df = stock_crawling()
kosdaq_df = stock_crawling('KOSDAQ') 원달러 환율 데이터 처리
page, pageSize = 1, 60
url_2 = f'https://m.stock.naver.com/front-api/v1/marketIndex/prices?page={page}&category=exchange&reutersCode=FX_USDKRW&pageSize={pageSize}'
response=requests.get(url_2)
data = response.json()['result']
usd_df = pd.DataFrame(data)[['localTradedAt', 'closePrice']]데이터 분석
- 코스피, 코스닥, 원달러환율의 상관분석
- 가설 : 코스피가 높으면 원달러 환율은 낮고, 코스피가 낮으면 원달러 환율은 높다.
- 가설 맞음 > 환율이 낮으면 달러를 사고, 환율이 높으면 달러 팔아서 코스피 산다.
시각화
#1단계-전처리 : data, kospi, kosdaq, usd 칼럼이 있는 데이터 프레임으로 변경, 값을 obj -> float로 변경해주기 위해서 ,를 제거
df = kospi_df.copy()
df.columns = ['date', 'kospi']
df['kospi'] = kospi_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
df['kosdaq'] = kosdaq_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
df['usd'] = usd_df['closePrice'].apply(lambda data: float(data.replace(',', '')))
df.head()
date kospi kosdaq usd
0 2023-08-24 2537.68 901.74 1325.0
1 2023-08-23 2505.50 882.87 1335.0
2 2023-08-22 2515.74 893.33 1339.5
3 2023-08-21 2508.80 888.71 1341.0
4 2023-08-18 2504.50 877.32 1343.0
#2단계-그래프
%config InlineBackend.figure_formats = {'png', 'retina'}
#해상도 올리는 거임
plt.figure(figsize=(20, 5))
plt.plot(df['date'], df['kospi'], label = 'kospi')
plt.plot(df['date'], df['kosdaq'], label = 'kosdaq')
plt.plot(df['date'], df['usd'], label = 'usd')
plt.xticks(df['date'][::5])
plt.legend()
plt.show()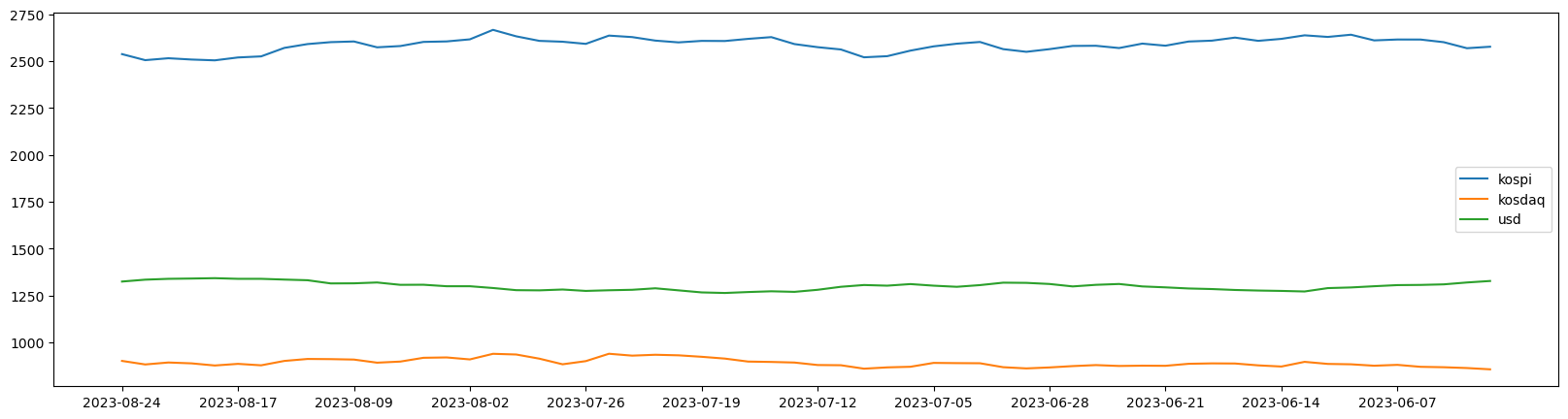
- 데이터의 상관관계를 파악하기가 힘듬 -> 데이터 스케일링이 필요
#3단계-데이터 스케일링, 그래프
-데이터 스케일링 : min-max 스케일링
from sklearn.preprocessing import minmax_scale
minmax_scale(df['kospi'])
plt.figure(figsize=(20, 5))
plt.plot(df['date'], minmax_scale(df['kospi']), label='kospi')
plt.plot(df['date'], minmax_scale(df['kosdaq']), label='kosdaq')
plt.plot(df['date'], minmax_scale(df['usd']), label='usd')
plt.xticks(df['date'][::5]) -> x축 눈금 값이 5단위로 올라감
plt.legend()
plt.show()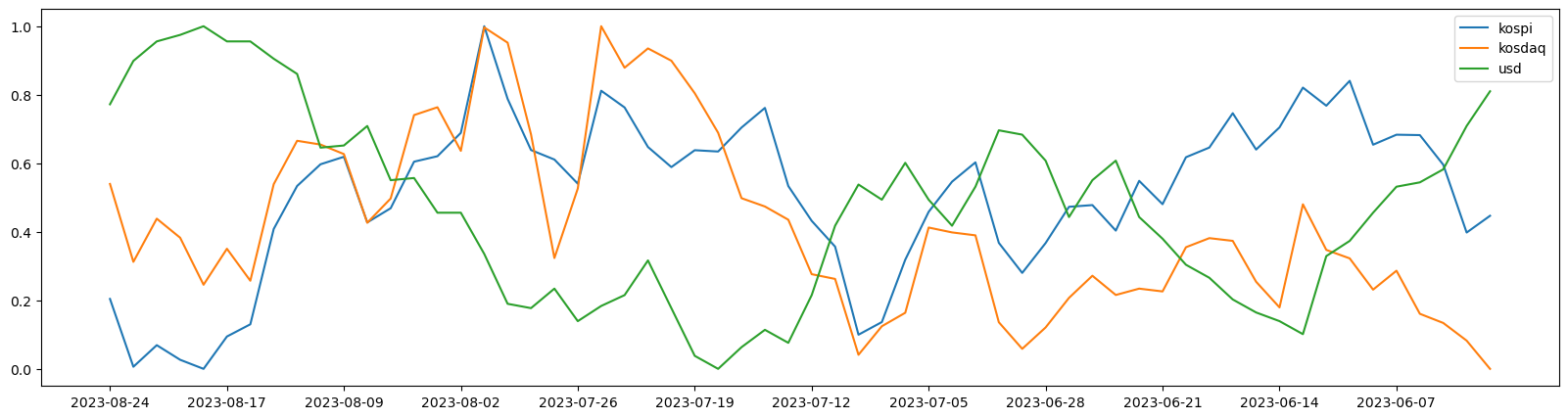
4단계-상관관계 분석
df.corr()
kospi kosdaq usd
kospi 1.000000 1.000000 -0.736086
kosdaq 1.000000 1.000000 -0.736086
usd -0.736086 -0.736086 1.000000-> 강한 상관관계가 있음을 확인할 수 있다.
daum 환율 데이터-response 오류
response = requests.get(url)
response
<Response [403]>- 이러한 상황이 발생했을 때는
1) header의 User-Agent 값을 변경
2) Referer 값을 변경
- 이러한 작업을 headers로 묶어서 저장 하고 requests에 post 형식처럼 넣어서 보낸다.
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
'Referer' : 'https://finance.daum.net/exchanges',
}
response = requests.get(url, headers=headers)
response
<Response [200]>API
requests 형식은 post 방법을 사용한다. api는 client_id와 client_secret을 웹 페이지에서 얻어 와야 한다.
post 방법이기 때문에 params도 지정을 해줘야 된다. 네이버 같은 경우 사용해야하는 params를 알려주기 때문에 맞춰서 작성해주면 된다.
만약 params에 입력된 데이터는 영문, 특수문자, 숫자만 사용가능 하며, 한글이 포함되어 있으면 인코딩 해서 사용해야 한다.
ko_txt = '데이터 크롤링은 돈 됨' params = { 'source' : 'ko', 'target' : 'en', 'text' : ko_txt, } headers = { 'Content-Type' : 'application/json', 'X-Naver-Client-Id' : client_id, 'X-Naver-Client-Secret': client_secret, } headers import json response = requests.post(url, json.dumps(params), headers=headers)
직방 데이터 처리
- 복잡하다.
- 정리하기가 애매하여, 파일로 복습하도록

큐브가 필요하다...!!!