- 컬렉션 (Collection) : 여러 객체(데이터)를 모아 놓은 것을 의미
- 프레임워크 (Framework) : 표준화, 정형화된 체계적인 프로그래밍 방식
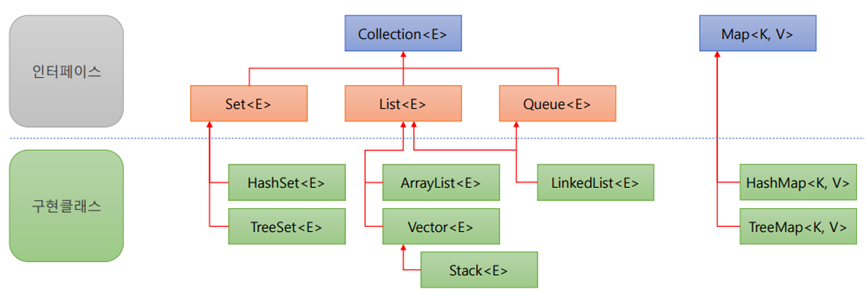
컬렉션 프레임워크 (Collection Framework)
- 여러 데이터를 쉽고 효과적으로 처리할 수 있도록 제공하는 클래스
- 자료 구조(Data Structure)와 알고리즘(Algorithm)을 구조화한 클래스
- 자바의 인터페이스(interface)를 구현한 형태로 작성된 클래스
| List | Set | Map | |
|---|---|---|---|
| 관리 | 목록 관리 | 집합 관리 | 데이터를 쌍으로 관리 |
| 순서 여부 | O | X (주머니에서 랜덤으로 꺼내서 사용) | X (Entry별로 저장 (key값 : Value값)) |
| 배열 대신 사용 | 교집합 / 합집합 / 차집합 등 | Value : 데이터 | |
| 요소 | 요소 추가 / 삭제 / 수정 | 요소 추가 / 삭제 / 수정 | 요소 추가 / 삭제 / 수정 |
| 중복값 여부 | O | X | key : X / value : O |
| 종류 | Vector, ArrayList, LinkedList, Stack, Queue | HashSet, TreeSet | HashMap, TreeMap, HashTable, Properties |
Collection 인터페이스의 메소드
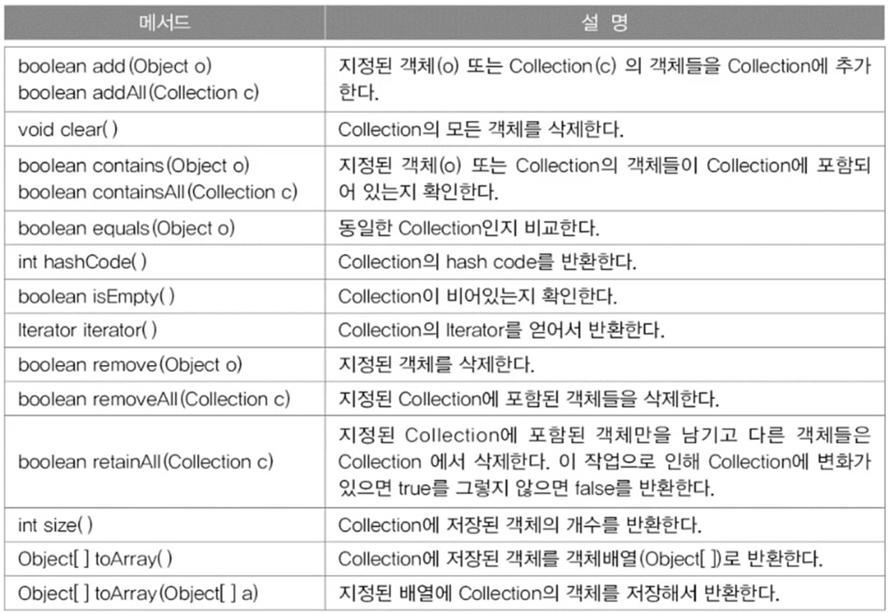
ArrayList <E> 주요 메소드 - 순서O, 중복O
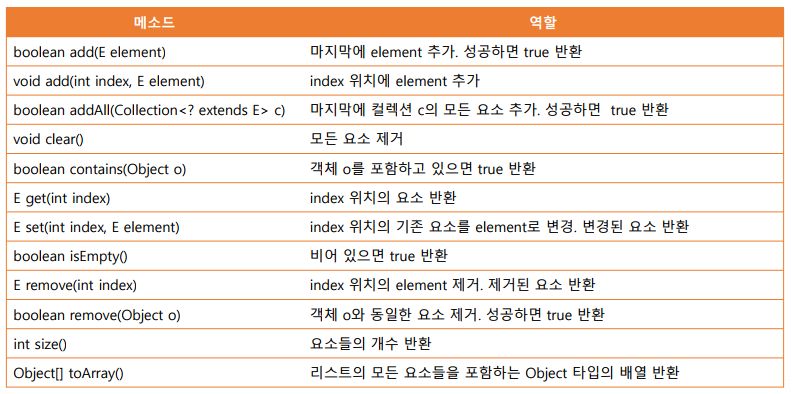
HashSet <E> 주요 메소드 - 순서X, 중복X
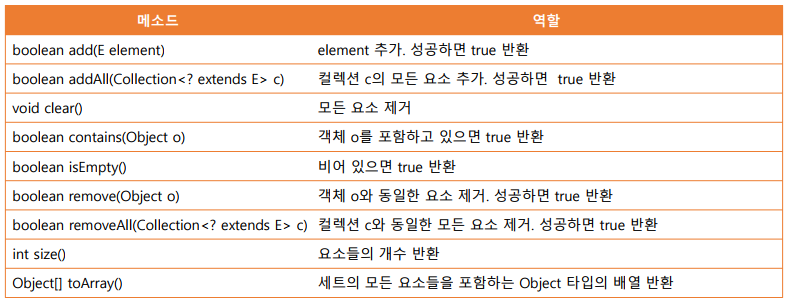
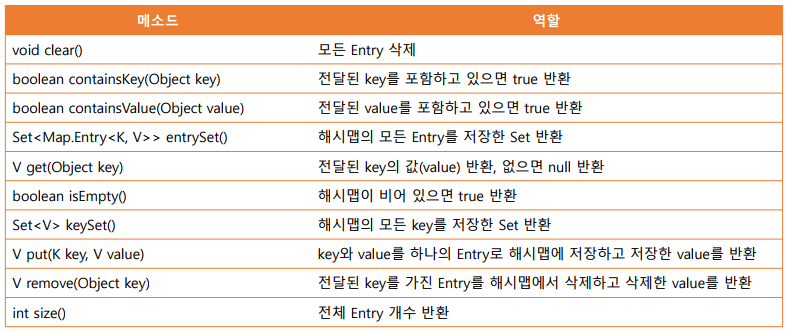
HashMap <K,V> 주요 메소드 - 순서X, 중복(키X,값O)
ArrayList
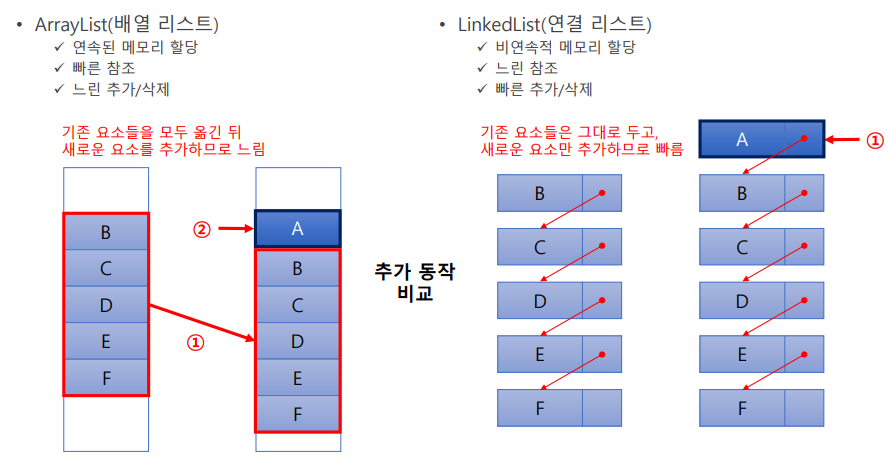
- ArrayList는 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
ArrayList 동기화X , Vector 동기화O - 배열(Array)을 List로 구현하므로, 저장순서가 유지되고 중복을 허용한다.
- 데이터의 저장공간으로 배열을 사용한다. (배열기반)
- 연속된 메모리 할당
- 배열처럼 인덱스를 참조하므로 검색 성능이 좋다.
- 배열은 크기를 미리 정하지만, ArrayList는 크기를 정하지 않는다.
ArrayList 객체 생성
- 제네릭(Generic) 기반 ex.
<String> - 생성할 때 데이터 타입을 결정 (구체화) →
< >안에 데이터 타입 기재
List<String> list = new ArrayList<String>();ArrayList 초기화
- 배열을 리스트로 변환하는 과정 = 리스트의 초기화 과정
- 고정된 크기를 가진다.
List<String> list = Arrays.asList("일", "월", "화", "목");Arrays.asList(String... a): 값이 여러개
Arrays.asList(String a): 값이 1개
ArrayList 요소 추가
- 인덱스 지정이 없으면 순서대로 저장
- 인덱스 지정도 가능
add(값)add(index, "값")
List<String> list = new ArrayList<String>();
list.add("월");
list.add("화");
list.add(2, "수");
list.add(0, "일");
// [일, 월, 화, 수]ArrayList 요소 제거
2가지 방법이 있다.
1. boolean remove(Object obj) : obj 제거. 성공하면 true반환
2. Object remove(int index) : index위치의 요소 제거. 제거한 요소를 반환
List<String> list = new ArrayList<String> (Arrays.asList("일", "월", "화", "수"));
list.remove(0); // [월, 화, 수]
list.remove("화"); // [월, 수]
System.out.println(list);ArrayList 요소 수정
List<String> list = new ArrayList<String> (Arrays.asList("월", "화", "수"));
list.set(0, "일");
System.out.println(list); // [일, 화, 수]ArrayList 길이
배열은 length를 이용하여 배열의 길이를 구하지만, ArrayList는 size( )를 이용해서 길이를 구한다.
List<String> list = Arrays.asList("일", "월", "화", "수");
int size = list.size();
System.out.println(size); // 4ArrayList 비어있는지 확인
List<Integer> list = new ArrayList<Integer> ();
boolean result = list.isEmpty(); // trueArrayList 요소 모두 제거
넣은 요소를 모두 제거하기 위해서는 clear()를 사용하면 된다.
List<String> list = Arrays.asList("일", "월", "화", "수");
list.clear();ArrayList 와 for 반복문
for문을 이용한 Array 출력
배열을 출력할 때 인덱스 값이 있기 때문에 인덱스의 i를 이용하여 for문을 이용하여 아래와 같이 출력했었다.
String arr[] = {"일", "월", "화", "수"};
for(int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " "); // 일 월 화 수
}for문을 이용한 ArrayList 출력
List<String> list = Arrays.asList("일", "월", "화", "수");
for(int i = 0, length = list.size(); i < length; i++) {
System.out.print(list.get(i) + " "); // 일 월 화 수
} 향상 for문을 이용한 ArrayList 출력
List<String> list = Arrays.asList("일", "월", "화", "수");
for(String element : list) {
System.out.print(element + " ");
}제네릭 (Generic)
- 모든 컬렉션 프레임워크는 제네릭(generic) 기반으로 구현된 클래스
- 어떤 컬렉션 프레임워크를 생성할 때 어떤 타입을 저장할 것인지 구체적으로 명시하는 것
- 제네릭으로 지정 가능한 타입은 오직 참조 타입(Reference Type)만 가능
- 기본 타입(Primitive Type)을 저장하려면 Wrapper Class 타입으로 처리
제네릭 (Generic) 장점
- 제네릭을 사용하면 잘못된 타입이 들어올 수 있는 것을 컴파일 단계에서 방지할 수 있다.
- 클래스 외부에서 타입을 지정해주기 때문에 따로 타입을 체크하고 변환해 줄 필요가 없다. (관리 용이)
- 비슷한 기능을 지원하는 경우 코드의 재사용성이 높아진다.
| 타입 | 설명 |
|---|---|
<T> | Type |
<E> | Element |
<K> | Key |
<V> | Value |
<N> | Number |
Wrapper 클래스
- 자바의 기본 타입(Primitive Type)을 클래스화한 8개의 클래스
- 기본 타입은 값만 저장할 수 있으나, Wrapper 클래스는 기본 타입의 값과 기능을 제공
- 기본 타입을 참조 타입(Reference Type)으로 변경할 때 사용
종류

Wrapper 클래스의 주요 메소드
- 문자열을 기본 타입으로 변환
int a = Integer.parseInt("5");
long b = Long.parseLong("10");
double c = Double.parseDouble("1.5");- 기본 타입을 Wrapper 클래스 객체로 변환(생성자를 대체하는 메소드)
Integer a1 = Integer.valueOf(5);
Long b1 = Long.valueOf(10);
Double c1 = Double.valueOf(1.5);
Integer a2 = Integer.valueOf("5");
Long b2 = Long.valueOf("10");
Double c2 = Double.valueOf("1.5");- Wrapper 클래스 객체를 기본 타입으로 변환
int a = a1.intValue();
long b = b1.longValue();
double c = c1.doubleValue();Boxing과 UnBoxing
- 기본 타입과 Wrapper 클래스 타입은 자동(Auto)으로 변환
- Boxing :
기본 타입 → Wrapper 클래스 타입 - UnBoxing :
Wrapper 클래스 타입 → 기본 타입
public class AutoBoxing {
public static void main(String[] args) {
Integer a = 10; // Auto Boxing
int b = a + 5; // Auto UnBoxing
System.out.println(a); // 10
System.out.println(b); // 15
}
}HashSet
- 집합을 관리하기 위한 자료 구조
- 인덱스가 없어 순서대로 저장되지 않는 특성
- 출력값으로 입력값을 예측할 수 없다.
- Hash 알고리즘을 이용하기 때문에 삽입 / 삭제 / 검색 속도가 빠르다.
HashCode
- 객체의 해시코드(hash code = 객체의 지문)를 반환하는 메소드
- Object클래스의 hashCode( )는 객체의 주소를 int로 변환해서 반환한다.
public class Object {
public native int hashCode( ); // 객체의 주소를 int로 변환해서 반환- equals( )를 오버라이딩하면, hashCode( )도 같이 오버라이딩해야 한다.
equals( )의 결과가 true인 두 객체의 해시코드는 같아야 하기 때문이다.
String str1 = new String("aaa");
String str2 = new String("aaa");
System.out.println(str1.equals(str2)); // true
System.out.println(str1.hashCode()); // 96354
System.out.println(str2.hashCode()); // 96354HashSet 생성
Set<String> set = new HashSet<String>();HashSet 초기화
값을 지정할 때 ArrayList와 같이 Arrays.asList( ) 메소드를 활용한다.
Set<String> set = new HashSet<String>(Arrays.asList("일","월","화","수"));HashSet 요소 추가
Set<String> set = new HashSet<String>();
set.add("일");
set.add("월");
set.add("화");
set.add("수");
set.add("수"); // 중복저장 시도
// [일, 월, 화, 수 ]Hash는 중복 허용하지 않는다.
HashSet 요소 제거
remove( )- HashSet 역시 모두 제거하려면
clear()사용하면 된다.
Set<String> set = new HashSet<String>();
set.add("일");
set.add("월");
set.add("화");
set.add("수");
set.add("목");
boolean result = set.remove("목");
System.out.println(result); // true제거할 값이 존재하지 않는다면 false를 출력하고 제거되지 않는다.
HashSet 길이
ArrayList와 똑같이 size( ) 메소드를 사용한다.
Set<String> set = new HashSet<String>(Arrays.asList("월","화","수"));
int size = set.size(); // 3HashSet for 반복문
HashSet은 인덱스가 존재하지 않고, 비순차적이라 일반 for문을 사용할 수 없다.
Set<String> set = new HashSet<String>(Arrays.asList("월","화","수"));
for(String element : set) {
System.out.println(element); // [ 월, 화, 수 ]
}HashSet 집합
Set<Integer> set1 = new HashSet<Integer>(Arrays.asList(1, 2, 3, 4, 5));
Set<Integer> set2 = new HashSet<Integer>(Arrays.asList(3, 4, 5, 6, 7));
Set<Integer> set3 = new HashSet<Integer>(Arrays.asList(6, 7));- 합집합 addAll( )
set1.addAll(set2); // [1, 2, 3, 4, 5, 6, 7]- 차집합 removeAll( )
set1.removeAll(set2); // [1, 2]- 교집합 retainAll( )
set1.retainAll(set2); // [3, 4, 5]- 부분집합 containsAll( ) T/F 판단
boolean result1 = set1.containsAll(set3);
boolean result2 = set2.containsAll(set3);
System.out.println(result1); // false
System.out.println(result2); // trueHashMap
- 키(Key)와 값(Value)으로 하나의 Entry가 구성되는 자료 구조
- 저장하려는 데이터는 값이고, 값을 알아내기 위해서 키를 사용
- Array / ArrayList의 경우 자동으로 인덱스가 할당되지만, Map의 key 값은 자유롭게 만들면 된다.
- Key는 중복이 가능하지만, Value는 중복이 불가능
- Hash를 이용하기 때문에 삽입 / 삭제 / 검색 속도가 빠르다.
Entry = Key : Value
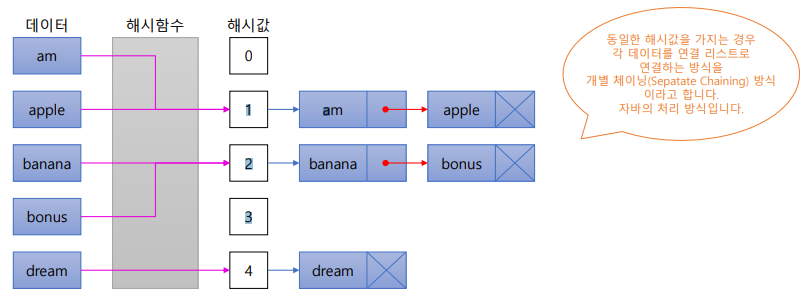
Hash Algorithm
- 해시(Hash)
- 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑(Mapping)한 값
- 어떤 데이터를 저장할 때 해당 데이터의 해시값을 계산해서 인덱스(Index)로 사용
- 어떤 데이터를 검색할 때 해당 데이터의 해시값을 인덱스(Index)로 사용하면 되기 때문에 빠른 조회가 가능
HashMap 생성
- Map은 key값과 value값이 따로 있으니 데이터 타입을 두개 지정해야 한다.
<Object>는 모든 데이터 타입을 받을 수 있다.
Map<String, String> map1 = new HashMap<String, String>();
// 또는
Map<String, Object> map2 = new HashMap<String, Object>();HashMap 요소 추가
put( )을 통해 요소 추가한다.
Map<String, Object> map = new HashMap<String, Object>();
map.put("title", "소나기");
map.put("author", "황순원");
map.put("price", 20000);HashMap 요소 수정
- 기존의 key 값을 사용하면 수정된다.
Map<String, String> dictionary = new HashMap<String, String>() ;
dictionary.put("apple", "사과"); // put(key, value)
dictionary.put("mango", "망고");
dictionary.put("melon", "멜론");
// 수정
// 기존의 key값을 사용하면 수정
dictionary.put("melon", "메론");melon key의 값은 메론으로 수정되었다.
HashMap 삭제
String removeItem = dictionary.remove("mango");
System.out.println(removeItem); // 망고HashMap Entry 단위로 순회
Map<String, Object> map = new HashMap<String, Object>();
map.put("title", "아몬드");
map.put("author", "손원평");
map.put("price", 18000);
for(Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
// author : 손원평
// price : 18000
// title : 아몬드Entry를 기준으로 순회하는 방법 말고도 key를 이용해 순회하는 방법도 있다.
HashMap key를 이용한 순회
Map<String, Object> map = new HashMap<String, Object>();
map.put("title", "아몬드");
map.put("author", "손원평");
map.put("price", 18000);
for(String key : map.keySet()) {
System.out.println(Key + " : " + map.get(key));
}
// author : 손원평
// price : 18000
// title : 아몬드[응용] HashMap을 사용하여 ArrayList에 저장된 요소를 중복값을 제외하고 출력
Map<String, Object> map1 = new HashMap<String, Object>();
map1.put("title", "summer");
map1.put("author", "hisahisijo");
map1.put("price", 10000);
Map<String, Object> map2 = new HashMap<String, Object>();
map2.put("title", "어린왕자");
map2.put("author", "생택쥐베리");
map2.put("price", 12000);
Map<String, Object> map3 = new HashMap<String, Object>();
map3.put("title", "홍길동전");
map3.put("author", "허균");
map3.put("price", 16000);
List<Map<String, Object>> list = new ArrayList<Map<String, Object>>();
list.add(map1);
list.add(map2);
list.add(map3);
for(Map<String, Object> map : list) { // List
for(Map.Entry<String, Object> entry : map.entrySet()) { // Map
System.out.println(entry.getKey() + ":" + entry.getValue());
}
System.out.println();
}tree map
이진트리 (Binary Tree)
- 모든 노드는 2개의 자식을 가질 수 있다.
- 작은 값은 왼쪽, 큰 값은 오른쪽에 저장한다.
TreeMap
- key를 기준으로 왼쪽에 작은 값, 오른쪽에 큰 값이 저장된다.
- key를 기준으로 자동으로 정렬되면서 저장된다.
- 크기 비교 및 범위 연산에 적절하다.
TreeMap 생성
선언하는 방법은 부모 Map을 선언하고, TreeMap 객체를 생성한다.
Map<Integer, String> map = new TreeMap<Integer, String>();TreeMap 요소 추가
put()를 이용해서 요소를 추가- TreeMap에서는 key를 자동으로 정렬해서 출력된다.
map.put(65, "수영");
map.put(85, "윤아");
map.put(35, "태연");
map.put(95, "서현");
// {35=태연, 65=수영, 85=윤아, 95=서현}TreeMap Entry 단위로 for 순회
TreeMap도 Map이므로 Entry 단위로 for 순회를 할 수 있다.
for(Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}TreeMap의 정렬
- 기본정렬 : 오름차순 정렬
- 정렬변경 : decendingMap() 메소드 호출
- 오름차순 정렬 ↔ 내림차순 정렬
- TreeMap은 TreeMap만 사용할 수 있는 메소드가 다수 있으므로 TreeMap 타입으로 생성하는 것이 좋다.
NavigableMap<K, V>: 지정된 검색 대상에 대해 가장 근접한 일치 항목을 반환하는 탐색 메서드와 함께 확장된 정렬된 map이다.SortedMap<K, V>인터페이스를 상속하는 인터페이스이다.- 구현체는 TreeMap을 사용하면 된다.
// 생성중요
TreeMap<Integer, String> map = new TreeMap<Integer, String>();
map.put(65, "수영");
map.put(85, "윤아");
map.put(35, "태연");
map.put(95, "서현");
NavigableMap<Integer, String> map2 = map.descendingMap();
for(Map.Entry<Integer, String> entry : map2.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
// 95 : 서현
// 85 : 윤아
// 65 : 수영
// 35 : 태연
// 다시 decendingMap() 메소드를 호출하면 오름차순 정렬이 된다.
NavigableMap<Integer, String> map3 = map2.descendingMap();
// key값으로 순회
for(Integer key : map3.keySet()) {
System.out.println(key + ":" + map3.get(key));
}
}