진행중인 프로젝트에서는 특정 아이템에 대한 리뷰를 작성할 수 있고 흔한 배달앱처럼 평점을 남길 수 있다.
처음에는 단순하게 API 요청마다 DB의 Sum, Count와 같은 집계함수를 이용하여 처리하였다.
그러다 우연히 다른 기능의 테스트를 하다가 1000만건 정도의 더미 데이터를 넣게되었는데 성능적으로 부하가 발생함을 볼 수 있었다.
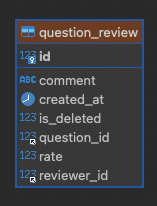
리뷰 시스템의 테이블 구조는 위 사진과 같다. question이란 아이템의 리뷰를 저장하고 있다.
select count(qr.id), sum(qr.rate), qr.question_id
from question_review qr
where qr.question_id = 1기존에는 사용자가 특정 question을 조회 할 때는 위와 같이 count, sum 함수를 사용하여 계산하여 응답으로 주었다.
explain select count(qr.id) , sum(qr.rate), qr.question_id
from question_review qr
where qr.question_id = 1 // question1의 평균 평점
explain을 사용하여 탐색되는 예상 rows를 확인해보면 단건 조회 시에는 question_id를 where문으로 question_review를 한번 필터하면서 들어가기에 1000만건의 데이터중 240만건의 데이터만 접근하여 처리함을 볼 수 있었다.

현재 question1의 리뷰는 1000만건중에 100만건정도이며 위 sql이 수행되는데 약 1.6초 정도 걸렸다.
근데 사실 쿠팡과 같은 대규모 이커머스 서비스가 아니라면 한 상품에 리뷰가 100만건이 있을 확률은 없을 것이긴 할 것이다.
(심지어 쿠팡에서 그나마 제일 높게 본게 10만건 리뷰)

그런데 문제는 현재 서비스에서 question 상품의 목록을 조회 하는 페이징 API가 있는데 평점 순으로 페이징하여 조회할 수 있도록 해야한다.
select sum(qr.rate) / count(qr.id) as average_rate, qr.question_id
from question_review qr
group by qr.question_id
order by average_rate DESC
limit 10
offset 1따라서 평점순 페이징 요구사항을 만족시키는 sql은 위와 같을 것이다.
이 sql을 잘 생각해보면 order by를 통해 average_rate 순으로 정렬해주고 있다. 그럼 당연히 db 입장에서는 평균 평점 순으로 정렬을 해야하기에
question_review에 있는 모든 question_id를 그룹화해서 question_id 별로 sum, count 연산을 하여 모든 question의 평균 평점을 계산을 해야한다는 것이다.
만약 현재 question_review에 question1부터 question100까지의 리뷰들이 있다고 가정해보자
그리고 현재 페이징 조건이 평균 평점이 10등 ~ 19등이라면 (0ffset 10, limit 10)
question1부터 question100까지 평균 평점을 전부 구해야만 10번째~20번째로 높은 평점의 question이 무엇인지 알 수 있다는 것이다.

단건 조회는 1.6초였지만 페이징 시 2.9초정도 소요되었다.

그리고 explain을 해보면 offset,limit와 관계없이 페이징 sql를 수행하는데 탐색되는 rows가 거의 모든 행임을 알 수 있다.
따라서 question 리스트 조회 시 평점순으로 정렬을 하는 상황에서는 단건 조회보다 훨씬 DB적인 부하가 심함을 알 수 있었다.
첫번째 시도 방안 - Index 걸기
집계함수와 관련해서 성능 관련 포스팅들을 보다가 알아낸 것이였다. 아직 DB에 관련해서 깊은 공부는 하지 않았지만 index를 걸면 탐색에 좋은 효과가 있다는 것은 얕게나마 알고 있었지만 어떤 방식으로 효과가 좋은지는 몰랐고 그냥 그렇구나 하면서 index를 사용하고 있었다.

현재 리뷰 테이블에 걸고 있는 index들이다. pk, question_id, reviewer_id이다. pk키를 제외한 나머지 키는 외래키 대용으로 사용하고 있는 것인데 실무에서는 종종 외래키를 사용하지 않고 직접 index만을 걸어서 사용한다는 것을 알았기에 도입한 방식이다.

여기서 question_id와 sum에 사용되는 rate를 복합 index로 걸어주면 성능이 향상됨을 알 수 있다.
select count(qr.id), sum(qr.rate), qr.question_id
from question_review qr
where qr.question_id = 1기존에 위 sql은 question_id가 index로 걸려있음에도 1.5초 이상이 소요되었었는데 그 이유는 question_id가 인덱스로 걸려있을지라도 qr.rate 즉 특정 row의 rate값을 알아내기 위해선 해당 row로 접근하여 값을 가져와야하고 이 행위는 I/O 작업이기 때문에 시간 소요가 걸렸던 것이다.
따라서 question_id와 rate를 같이 복합 index로 설정한다면 question_id에 해당하는 rate 값을 직접 접근해서 가져올 필요가 없기에 I/O 작업이 줄어들어 처리 시간이 줄어든 것이다.

테스트 결과 단건 조회의 경우 1.6초 소요되던 것이 0.166초로 줄어들었다.

페이징을 위한 정렬 조회의 경우도 2.9초에서 1.4초정도로 줄어들었지만 그래도 부하가 있는 처리시간이라고 생각한다.
아마 정렬을 위해선 모든 평균 평점을 구해야하기 떄문이라고 생각한다.
따라서 단건 조회에서는 굉장히 유의미한 효과였지만 페이징이라는 요구사항에는 결국 완벽한 해결책이 될 수는 없었다.
두번째 시도 방안 - 특정 시간마다 Batch 작업 수행
이 방법은 실제로 진행하진 않았고 고민만 해보았던 방안이다.
대규모 데이터를 처리할 때 Batch를 이용하기도 한다는 것은 자주 들었다. 그래서 생각했던 방안은 1분 혹은 3분 간격으로 특정 시간이 지날 때 마다
select count(qr.id) , sum(qr.rate), qr.question_id
from question_review qr
where qr.question_id = 1batch를 통해 위와 같은 통계 sql을 이용하여 평균 평점의 값을 구하고 업데이트 하는 방식이다.
장점
API 요청 횟수와 관계 없이 정해진 시간에만 통계 배치 작업이 수행되기에 부하 유발이 적다.
단점
배치 작업 시간이 되기전까진 갱신이 되지 않기에 실시간으로 변화하는 데이터일 경우 사용자가 기다려야한다.
장점은 어느정도 부하가 오는 작업을 비교적 적은 방식으로 처리할 수 있다는 점이다. 하지만 이것이 아주 큰 장점인지는 알 수가 없었다. 왜냐하면 결국 특정 시간대마다 부하가 발생한다는 것은 변함이 없기 때문이다.
그리고 단점이 좀 컸는데 문제가 되는 것은 평점 순으로 페이징 정렬이 필요로 했는데 데이터가 실시간으로 갱신되지 않는다면 의미가 없는 것이라고 생각했다.
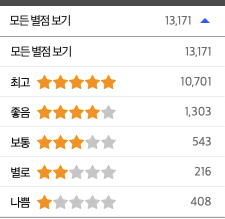
그래서 다른 이커머스 서비스를 확인해보았는데 쿠팡 같은 경우 1점 2점 3점 4점 5점의 리뷰 개수가 사용자 UI에 보여지는 것과 일치했고
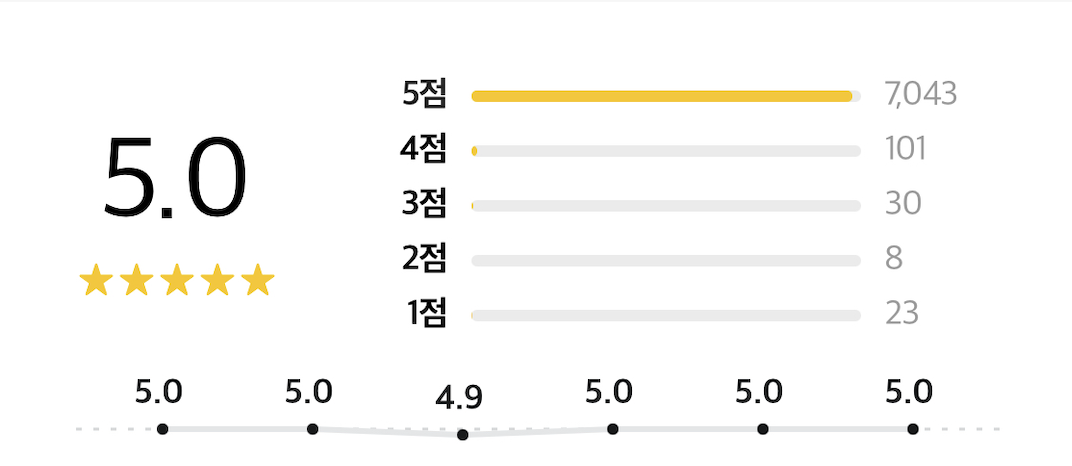
배달의 민족 같은 경우도 각 평점의 개수와 실제 보여지는 개수와 일치한 것으로 보아 이런 대규모 서비스에서도 평점은 실시간으로 갱신되는 것이라고 예상할 수 있었다.
따라서 배치 작업을 통한 방안은 적절하지 않다고 판단했다.
세번째 시도 방안 - 통계 관련 테이블 추가
이 방법이 내가 프로젝트에 도입한 방식이다.
제일 문제점은 sum과 count와 같은 집계 함수들이 DB에 부하를 일으킨다는 것이였고 그렇다면 sum과 count를 이용하지 않고 처리하면 되지 않을까해서 생각한 방식이다.
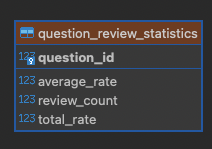
일단 위와 같이 리뷰 통계 테이블을 만들었다
question_id는 특정 question 상품을 의미하고 review_count는 해당 상품의 리뷰 개수, total_rate는 해당 상품의 평점의 총합, average_rate는 말 그대로 평균 평점이다.
새로운 리뷰가 작성 / 수정 될 때 마다 누적되어 있는 totalRate, reviewCount, averageRate를 갱신하는 방식이다.
예를 들어 question1에 대한 새로운 리뷰가 작성된다면
기존 totalRate에 새로운 리뷰의 평점을 +
기존 reviewCount를 +1
기존 averageRate를 갱신 해주는 방식이다.
만약 기존 리뷰의 평점이 수정된다면
기존 평점과 변경되는 평점의 차 만큼 totalRate에 더해준다
예를 들어 3점 -> 5점 변경이라면
5-3= 2이기에 2를 더해준다.
만약 5점 -> 3점 변경이라면
3-5= -2이기에 -2를 더해준다.
그리고 averageRate를 갱신해준다.
위와 같은 방식을 사용한다면 리뷰 작성 / 수정 시에만 특정 컬럼의 값을 update해주기만 하면 되고 평균 평점에 관련해서
sum, count와 같은 집계함수를 사용하지 않아도 되게 된다.
select question.*
from
question
left join
question_review_statistics on question_review_statistics.question_id = question.id
group by
question.id
order by
question_review_statistics.average_rate desc,
question.id desc
limit 10
offset 0따라서 question을 평점순으로 정렬한다면 위와 같은 sql로 간단하게 처리할 수 있게 되었다.
리뷰 시스템 평점에 대한 최적화?는 원하는 방향에 맞게 잘 완료 된 것 같다.
그러나 예상되는 문제점은 question_review_statistics 테이블의 totalRate, reviewCount, averageRate의 동시성 이슈가 발생할 것이라고 예상한다.
같은 question에 대해 Review 작성 / 수정 요청이 동시에 들어오게 되면 각 컬럼의 데이터 동시성 이슈가 발생할 수 있기 때문에 이 부분에 대해서는 검증 및 보완을 진행해야겠다.
