Introduction
4주간의 알고리즘 문제 풀이 이후 c언어를 처음 배워봄과 동시에 RBtree, malloc 및 web server 구현을 마치고, pintOS Project에 돌입했다.
초기에 블로그를 잘 정리하겠다는 다짐은 진즉 희석되어 malloc부터 거의 정리하지 못한 것 같다. 그래도 코드에 주석을 최대한 많이 달아놓았기 때문에 늦었지만 추후에 다시 복기하며 작성해볼 생각이다.
PintOS의 01 주차인 Threads과 02 주차인 user program에 대한 간략한 개요와 느꼈던 점들을 적어볼 생각이다.
사실 프로젝트를 진행하면서 팀 노션을 만들어 코드 설명과 이론들을 대부분 작성했기 때문에 따로 작성하는 것을 등한시 한 것 같다. 코드 내용은 노션을 참고하면 될 듯 하다.
본론으로 들어가서 PintOS는 2004년 스탠포드에서 만들어진 교육용 운영체제로 이번 프로젝트는 이를 기반으로 KAIST 권영진 교수님 주도 하에 만들어진 KAIST PintOS로 진행되었다.
Project 01에 대해 서술하기 전에 현재 thread 구조가 pintOS 내에서 어떻게 구현되어 있는지 내 생각을 간략히 정리할 생각이다. 물론 현 시점에서 잘못 이해하고 있는 부분들이 있을 수 있지만 앞으로 남은 3, 4주차를 통해 보완할 생각이다.
User and Kernel virtual memory
현재 핀토스의 가상 메모리는 user virtual memory와 kernel virtual memory 두 영역으로 나뉜다. 사용자 가상 메모리는 가상 주소 0에서 include/threads/vaddr.h에서 정의되고 있는 것과 같이 0x8004000000까지고, 나머지는 커널 가상 메모리이다.
핀토스에서 커널 가상 메모리는 KERN_BASE에서 시작하여 물리적 메모리에 일대일로 mapping하고, base & bound 방식과 흡사하게 physical memory에 접근할 수 있다. kernel 또한 process와 비슷하게 protected mode에서 동작하여 page table을 통한 virtual address transition으로 메모리에 접근해야 하며, 직접적인 read/write 또는 프로세스에게 메모리를 할당하기 위한 목적으로 physical memory에 접근할 시 다음과 같이 물리 메모리에 접근할 수 있다.
ex) 가상 주소 KERN_BASE(물리 메모리 0에 접근) + 0x1234는 physical address 0x1234에 접근
위와 같은 방법으로 시스템의 physical memory 크기만큼 접근할 수 있다.
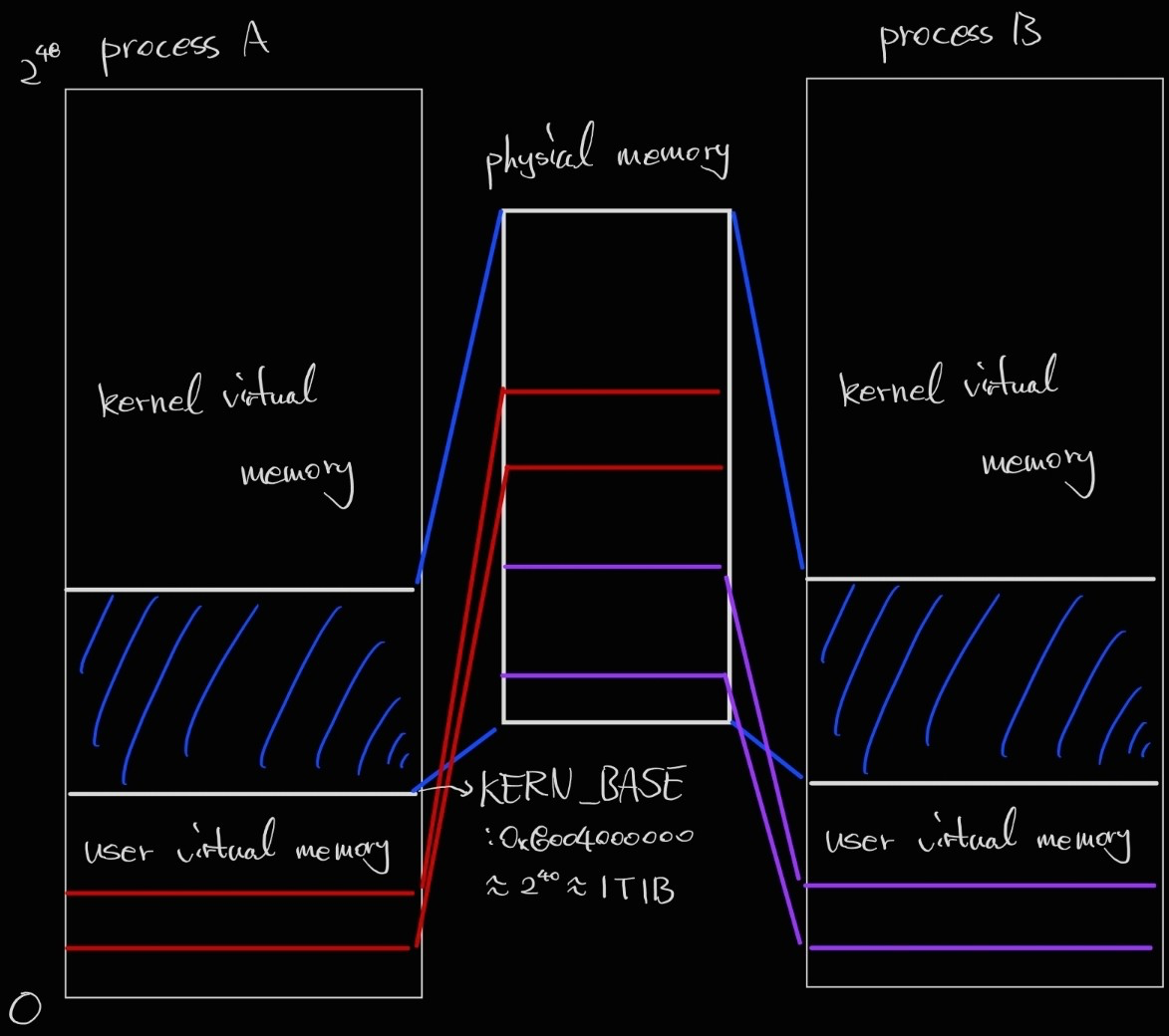
그림을 통해 user/kernel virtual address space와 physical memory간의 mapping이 어떻게 이루어지는지 확인할 수 있다.
user virtual address space와 physical memory간의 mapping은 페이지 테이블을 통해 수행된다.
아직 가상 메모리 프로젝트를 진행하기 전이지만 현재 갖고 있는 지식으론 가상 주소는 VPN과 offset으로 이루어져 있고, VPN을 통해 페이지 테이블에서 해당 페이지의 PFN(physical frame number)에 offset을 더해 물리 주소에 접근할 수 있는 것으로 알고 있다. 또한 페이지 테이블 엔트리에는 PFN 뿐만 아니라 현재 페이지의 상태를 나타낼 수 있는 protection bit, valid bit, reference bit 등이 존재하고, 이를 통해 현재 페이지가 유효한 페이지인지 접근할 수 있는 권한(예를 들어 쓰기, 읽기 등)이 무엇인지 확인하여 예외 처리를 수행할 수 있다. 자세한 내용은 추후 가상 메모리 프로젝트 시 더 자세하게 공부할 계획이다.
Threads in memory
thread의 모든 정보는 single page(4kB)에 저장되고, struct thread는 page의 맨 아래(offset 0)에 위치한다. page의 나머지 부분은 kernel stack을 위해 사용되며 page의 위쪽에서 아래쪽으로 확장된다(offset 4kB).
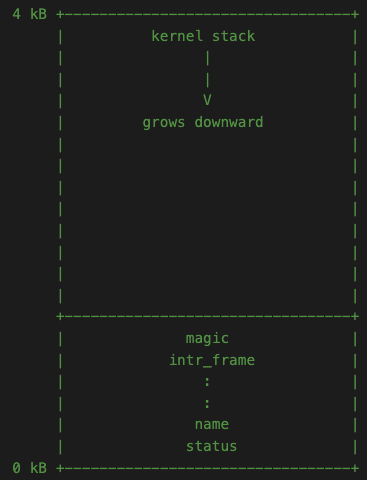
여기서, 주의해야 할 내용은 두 가지가 존재한다.
- 커널 스택의 충분한 공간을 위해 struct thread가 너무 커서는 안된다. 기본적으로 해당 구조체는 크기가 얼마 안되기 때문에 1kB 이하로 잘 유지되어야 함.
- 커널 스택이 너무 커서 오버플로가 발생하면 thread 구조체가 손상될 수 있기 때문에 커널 함수는 큰 구조체나 배열을 비정적 지역 변수로 선언하면 안되고, malloc()이나 palloc_get_page()으로 동적 할당해서 사용해야 함.
만일 thread_one이라는 함수를 실행하는 thread를 생성한다고 가정하면 thread_create() 호출 시 thread_one을 매개변수로 전달할 것이다.
그 후 thread create에서는 thread를 위한 page를 할당하고, tid 결정 및 필요한 여러 인자들을 초기화하는 작업을 수행한다.
이 과정중에 해당 thread의 interrupt_frame 내부 register 값 또한 다음 코드와 같이 초기화를 해준다.
/* Call the kernel_thread if it scheduled.
* Note) rdi is 1st argument, and rsi is 2nd argument. */
t->tf.rip = (uintptr_t) kernel_thread;
t->tf.R.rdi = (uint64_t) function;
t->tf.R.rsi = (uint64_t) aux;
t->tf.ds = SEL_KDSEG;
t->tf.es = SEL_KDSEG;
t->tf.ss = SEL_KDSEG;
t->tf.cs = SEL_KCSEG;
t->tf.eflags = FLAG_IF;여기서 첫번째, 두번째 인자에 해당하는 rdi, rsi에 create thread 호출 시 전달받은 thread가 수행할 함수 및 필요한 인자가 들어가는 것을 확인할 수 있다.
또한, program counter를 의미하는 rip에 kernel_thread라는 함수의 주소가 들어간 것을 확인할 수 있고, 해당 코드는 다음과 같다.
static void
kernel_thread (thread_func *function, void *aux) {
ASSERT (function != NULL);
intr_enable (); /* The scheduler runs with interrupts off. */
function (aux); /* Execute the thread function. */
thread_exit (); /* If function() returns, kill the thread. */
}코드에서 나타낸 것과 같이 스레드의 메인 함수를 kernel_thread가 실행하는 것을 확인할 수 있다. 이를 정리하면 다음과 같다.
thread_one이라는 함수를 실행시키는 스레드를 가정했을 때 해당 thread의 첫번째 entrysms main 함수인 thread_one이 아닌 kernel_thread라는 pintOS 함수에 대한 entry이고, 이는 thread의 main function의 wrapper 함수의 역할로 메인 함수가 반환되는 즉시 스레드가 종료되는 것을 보장하는 함수이다.
이를 그림으로 나타내면 다음과 같다.
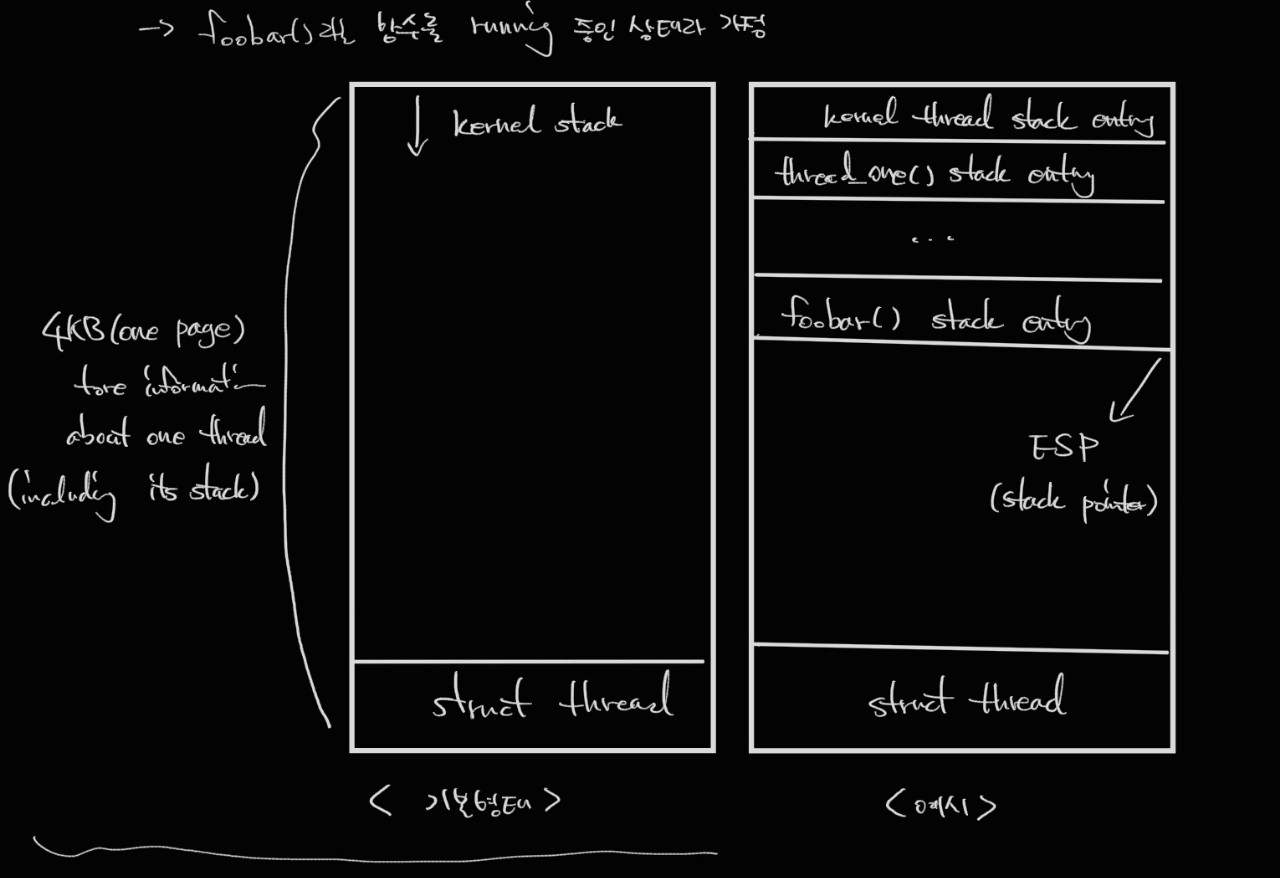
PintOS main program
핀토스 코드 내 threads/init.c에서 main 함수를 보면 PintOS 프로그램이 처음 구동되어 실행하는 instruction들을 확인할 수 있다. 전체 코드 내용을 이해하진 못했지만 thread와 관련된 함수는 다음과 같다.
main(void){
...
thread_init()
...
thread_start()
...
thread_exit()pintOS 초기화 동안(main 함수) command line을 파싱하여 처리하고, 특정 함수들을 특정 interrupt(ex= timer init과 timer interrupt)와 연결하는 등의 기능들이 있지만 우선 thread 관련 내용들을 살펴보면 다음과 같다.
thread_init은 scheduling에 필요한 ready_list와 같은 global thread context들을 초기화 하고 init_thread를 호출하여 initial thread를 초기화한다.
init_thread(initial_thread, "main", PRI_DEFAULT)여기서, initial_thread는 정적 전역 변수로 선언된 thread 구조체이고, "main"은 thread의 이름, PRI_DEFAULT는 우선순위(현재 핀토스에서 우선순위 값은 min=0에서 max=63) 값으로 default인 31을 주었다.
thread 초기화 작업을 마친 후 thread status를 running 상태로 저장하고, tid를 부여받는다.
그 다음 thread_start에서 thread_create를 통해 idle thread를 생성하고, 처음으로 ready_list로 들어간다. 이 때, idle thread의 priority는 min 값인 0이다. 그 이후 thread_start는 idle_thread가 idle 함수를 실행할때까지 기다리기 위해 sema_down해서 기다린다.
idle thread는 실행할 준비가 된 다른 스레드가 없을 때 즉, ready_list에 어떤 thread도 없을 때 실행되는 thread이다. 처음에 thread_start를 통해 ready_list로 들어가 한번 스케줄링되며 idle_thread를 초기화하고 thread_start가 계속 진행하여 run_action을 수행할 수 있도록 전달된 세마포어를 업한 후 즉시 block된다. 그 이후 idle thread는 ready list에 나타나지 않고, 해당 리스트가 빈 경우 특별한 케이스로 next_thread_to_ruen에 의해 return된다.
idle_thread는 CPU가 무조건 하나의 thread는 실행하고 있는 상태를 만들기 위함인데 이는 실행하는 스레드가 하나도 없을 경우 시스템이 멈출 수 있기 위함이고 다시 실행시키는데 자원이 많이 소모되기 때문으로 들은 것 같은데 정확한 이유는 모르겠다..
아무튼 본 과제에 대해 설명하기 전에 어느정도 생각나는 배경지식들을 얘기해보았다. 아직 부족한게 많지만 지금은 어느정도는 정리가 되었는데 사실 초기엔 이게 다 무슨 소리인지 전혀 이해가지 않아서 사실 글을 쓸 엄두가 나지 않았다. 최대한 정확한 정보를 알려주고 싶단 생각을 핑계로 글을 미뤄왔던 것 같아 비록 틀린 부분이 있거나 미흡한 부분이 있더라도 계속 작성을 해야겠다는 생각이 들었다. 추후 과제를 수행하면서 추가적으로 깨닫는 시간을 가졌으면 좋겠다.
현재 PintOS 프로젝트 01 및 02는 모두 마친 상황이며 해당 내용들은 대부분 팀 노션에 기록되어 있지만 내가 따로 정리를 한번 하는건 다른 얘기일 것 같아 추가적으로 회고록을 작성해볼 계획이다. 코드에 대한 상세한 내용들은 노션 링크를 달아놓을 생각이다.
그 외 keywords
-
synchronization
- thread 간 resource가 제대로 통제되지 않으면 결과가 크게 안좋을 수 있는데 이는 특히 운영 체제 커널에서 발생하며, 잘못된 공유로 인해 전체 시스템에 충돌할 수 있음
- 동기화를 수행하는 가장 거친 방법은 인터럽트를 사용하지 않도록 설정하는 것으로 즉, CPU가 인터럽트에 일시적으로 응답하지 않도록 하는 것이다.
- 인터럽트가 해제된 경우, 다른 스레드는 실행 중인 스레드를 선점하지 않는데 이는 선점이 타이머 인터럽트에 의해 구동되기 때문이다. 인터럽트가 켜져 있는 경우, 실행 중인 스레드는 두 c instruction 또는 심지어 하나의 instruction 내에서도 언제든지 다른 스레드에 의해 선점될 수 있다.
- 인터럽트를 disable하는 주된 이유는 커널 스레드를 sleep 시킬 수 없는 외부 인터럽트 핸들러와 동기화하기 위해서이며 따라서 대부분의 다른 형태의 동기화를 사용할 수 없음.
- 일부 외부 인터럽트는 인터럽트를 비활성화하더라도 연기할 수 없는데 NMI(Non-maskable interrupt)라고 불리는 이러한 인터럽트는 비상시에만 사용되어야 한다. 핀토스는 이를 처리하지 않는다.
-
이전 기수의 interrupt disable 관련 질문에 대한 조교님의 답변 발췌(https://velog.io/@cjy13753)
- interrupt를 disable하는 것은 cpu의 제어권을 interrupt가 다시 enable될 때 까지 넘겨주지 않겠다는 의미와 흡사합니다. 이러한 interrupt는 scheduling에 중요한 timer interrupt나 입출력 장치에 의해 발생하는 I/O interrupt등이 포함될 수 있습니다. interrupt disable을 남발하는 행위는 OS 자체의 response time을 증가시키는 등의 이유로 좋지 않은 디자인으로 평가받습니다. 이에 일반적으로 interrupt disable 대신 semaphore나 lock과 같은 synchronization primitive를 주로 사용하지만, project 1에서 다루는 do_schedule 함수 등 scheduling에 직접적으로 연관된 함수들이나, lock/semaphore를 사용할 수 없을 때 (예를들면 lock/semaphore를 구현해야 할 때)는 interrupt disable로써 synchronization을 확보합니다.
- interrupt disable/enable과 이에 관련된 assert가 전부 없을때 발생할 수 있는 bug case 중 하나를 들어보겠습니다. 현재 thread가 thread_yield 함수를 통해 다른 thread에게 cpu 제어권을 넘기려고 시도합니다. 이 thread는 ready_list에 삽입되어 다음 scheduling을 대기합니다. 이때 ready_list에 thread를 삽입하기 위한 함수 list_push_back 은 여러 instruction으로 구성되어 있습니다. (https://github.com/casys-kaist/pintos-kaist/blob/ee7443d7ae850c7cb704db6e8213c5cb67cacd0b/threads/thread.c#L306) timer interrupt가 발생합니다. scheduling을 위해 intr_handler -> timer_interrupt -> thread_tick 함수가 호출되고, scheduler가 현재 thread가 yield가 필요하다고 판단하여 intr_yield_on_return 함수를 통해 interrupt handler 종료와 함께 thread를 yield하려 시도합니다. thread_yield 가 다시한번 호출되고, 여기서부터 많은 문제가 발생할 수 있습니다. 우선 현재 thread가 ready_list에 두번 삽입되어 logical bug를 일으킬 수도 있고, 최악에는 thread가 ready_list에 완전히 삽입되지 않은상태에서 (즉 list의 fd/bk가 완전히 연결되어있지 않은상태에서) 다시 ready_list에 접근하여 invalid memory access에 의한 kernel panic등이 발생할 수 있습니다.
- 앞선 document의 설명에 추가적으로 설명드리면, lock/semaphore와 같은 synch primitive들은 thread/thread 간의 race condition을 방지하기 위해서 사용될 수 있으나, 위에 예시로 든 것과 같이 thread/interrupt handler 간의 race condition은 방지할 수 없습니다. 이러한 경우에는 interrupt disable을 사용하여 synchronization을 확보할 수 밖에 없습니다.
-
semaphore
- 0으로 초기화된 세마포어는 정확히 한 번 발생할 이벤트를 대기하는 데 사용될 수 있다.
실제로 project 02의 system call을 수행하는 함수 중에서 process_wait와 process_exit가 있는데 여기서 0으로 초기화 된 세마포어를 사용한다.
예를 들어, wait에서 부모 프로세스가 자식 프로세스가 종료할 때까지 대기하는 과정에서 자식 프로세스의 semaphore를 down 시키면서 block 상태가 되고, 자식 프로세스가 exit 하는 과정에서 자신의 세마포어를 up하면서 부모 프로세스가 진행할 수 있도록 한다. - 1로 초기화된 세마포어는 일반적으로 resource에 대한 접근을 제어하는 데 사용됨. 리소스를 사용하기 전에 세마포어를 down한 다음 리소스를 다 사용한 후 해당 세마포어를 up하여 다른 스레드가 해당 자원을 사용할 수 있게 한다. 이 경우 lock과 동일한 기능을 한다.
- 세마포어의 경우 lock과 다르게 다른 thread가 sema_up을 해줄 수 있음.
- 0으로 초기화된 세마포어는 정확히 한 번 발생할 이벤트를 대기하는 데 사용될 수 있다.
-
Lock
- Lock은 초기값이 1인 semaphore와 동일하다. "up"은 "release"와 동일하고, "down"은 "acquire"와 동일하다.
- 세마포어와 비교했을 때, lock은 추가적인 제한이 있는데 lock을 획득한 thread만 release 할 수 있다. 따라서, 이러한 제한이 문제라면 세마포어를 사용해야 한다.
-
spinLock
- 입구에서 공유 자원에 진입할 수 있는지 계속 물어보는 방법으로 busy-waiting에 해당한다.
- 이는 논외로 mutex를 배울 때 알게된 기법인데 이걸 쓰는 이유에 대해 고민한적이 있었다. semaphore의 경우 자신이 resource에 대한 접근 권한이 없을 경우 block되어 waiting list에 들어가 대기하게 되는데 이 경우 아무래도 일련의 과정에서 CPU의 자원을 더 할애한다고 생각했다. 따라서, 짧은 코드에 사용할 경우 semaphore 로 감싸는 대신 spinLock을 사용해도 괜찮지 않을까라는 생각을 했다. 혹은 context switching 시간이 짧을 경우 사용할 수 있을거라 생각했다.
