현재 file system 주차까지 대부분 끝났고, 정글 교육의 마지막인 나만의 무기를 앞두고 있다. virtual memory 프로젝트는 틈틈히 글을 작성하기로 그렇게 마음을 먹었는데...
결론적으로 구현하느라 정신이 없어서 잘 기록을 못해서 블로그 작성은 오랜만이지만 VM 주차가 끝난 후 extra 과제를 제외한 전 과정에서 다뤘던 함수들을 모두 그려보며 내 생각을 정리하는 시간에 하루를 투자한 것 같다.
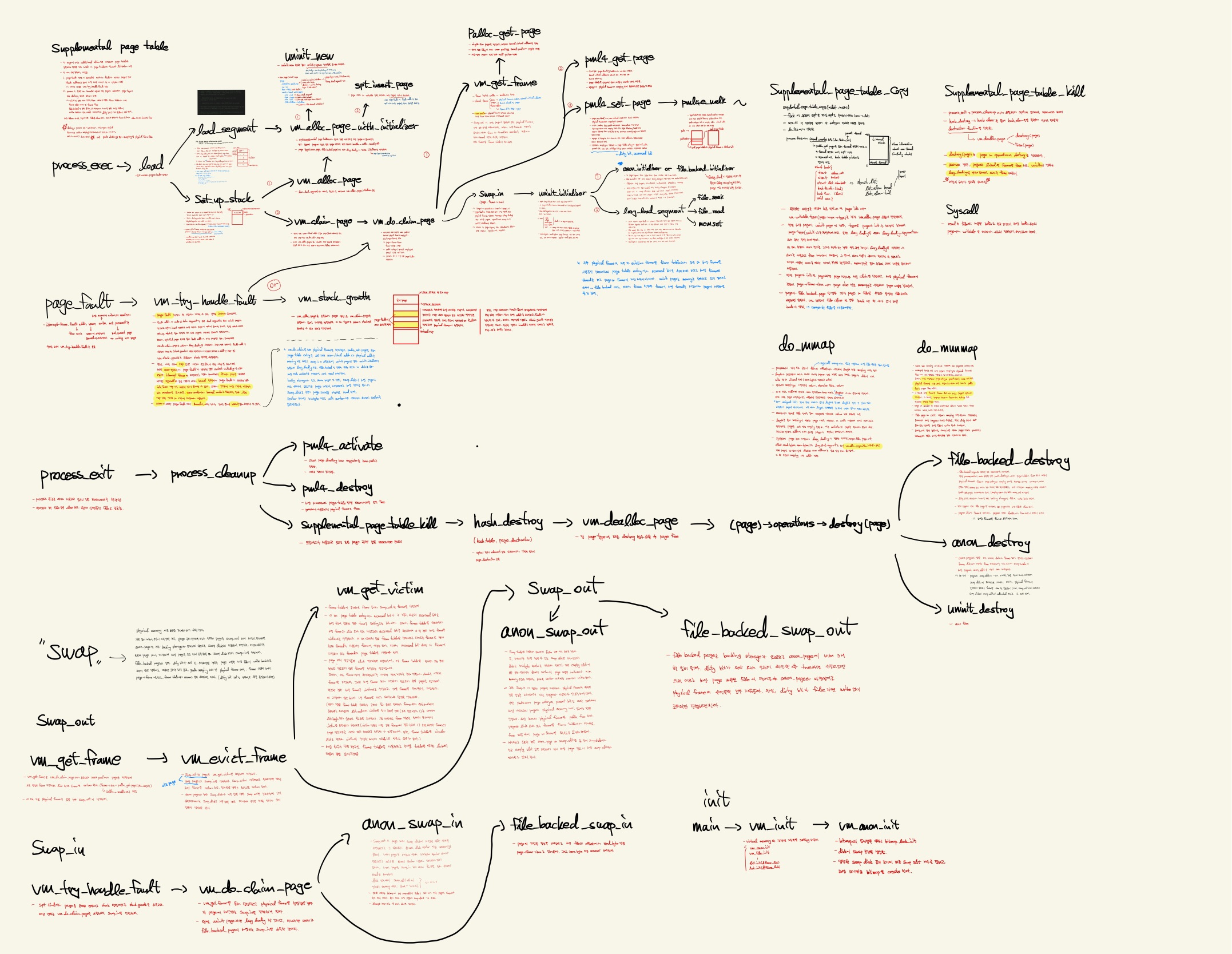
위의 과정에는 프로젝트 03을 진행하면서 호출했던 함수들을 모두 관계도를 그리고, 그에 대한 설명과 내 생각이 포함되어 있다. 전체 모습을 담으려니 함수 관련 설명들은 글자가 너무 작아서 잘 안보인다...
아무튼 의식의 흐름과 생각대로 적었기 때문에 다소 혹여 잘못된 부분들이 있을 수 있지만 다른 누군가의 설명을 보고 적는건 도움이 안될 것 같아 내가 함수를 작성하면서 고려했던 부분들이 어떤게 있고, 정리하다보면서 아 이런 경우도 고려할 수 있었을텐데 하는 부분들도 작성했다.
우선 크게 갈래를 보면 다음과 같다.
- 프로세스 시작 시, 실행 파일의 데이터를 어떻게 메모리로 load하는지
- 프로세스 종료 시, 프로세스가 사용하던 resource들을 어떻게 정리하는지
- Page fault 발생 시 처리 절차
- Swap in & out 절차
우선 종합적으로 과제를 돌이켜보면 정말 코드를 작성하는 사람이 메모리 관리를 하기 위해 할당 받은 메모리들을 적절한 때에 free 해주지 않으면 끝도 없이 메모리 누수가 발생할 것이란 점이다... 심지어 인지 못하는 경우도 있을 수 있다.
어떻게든 많은 프로세스가 한정된 메모리 자원을 효율적으로 사용하기 위한 시스템인데 만일 코드를 잘못 작성해서 프로세스가 생성되고 종료될때마다 관련된 메모리들이 해제되지 않고 끝난다면 그 결과는 생각만해도 끔찍할 것 같단 생각이 들었다.
글을 작성하면서 간단히 생각해보면 기존 VM 이전에는 프로세스가 실행할 때, 로딩 과정은 실행에 필요한 segment들을 모두 메모리에 올려서 사용하는 방식이였다. 이럴 경우 실제로 프로세스가 사용하지 않는 영역들도 모두 미리 적재해버리기 때문에 메모리에는 그만큼 공간이 부족하고, 다른 프로세스들이 사용할 수 있는 공간이 줄어드는 것이다. 따라서, 이번 과제의 핵심은 이러한 loading을 지연시켜서 실제 필요한 시점에서 즉, user가 해당 데이터를 직접 참조할 경우 page fault를 발생시키면서 해당 내용들을 읽어와 메모리에 적재시킨다.
따라서, process가 실행하면 기존의 load에서 읽어야 할 byte 크기를 page단위로 user pool에서 할당해서 전체를 다 읽어버리던 방법과는 다르게 현 과제에서는 동일하게 page 단위로 각 page의 offset, reads_byte, file 등을 구조체로 저장하고, page fault 발생 시 해당 page를 file에서 읽어올 수 있는 함수인 lazy_load_segment 함수와 함께 전달하여 uninit이라는 type의 page를 만들게 된다.
이 경우, 실제로 file의 데이터들이 메모리로 적재되진 않고, 각 파일의 내용들을 담고 있는 page라는 구조체가 만들어지는 것이다. 실제로 process가 접근했을 땐 해당하는 내용을 메모리에 적재해야하므로 page들을 관리할 수 있는 table이 필요하고, 이것이 supplemental table(=spt)이다.
page fault가 발생했을 경우, spt에서 fault address가 속해있는 page를 확인하고, 존재할 경우 user pool에서 page를 할당 받아 page 구조체와 link 시킨 후 swap_in을 호출하게 되는데 이는 각 페이지 구조체의 페이지 타입에 따라 달라지는 operation으로 현 시점에는 loading 되기 전인 uninit page이므로 uninit_initiolize를 호출하게 된다.
이 함수는 uninit page를 만들면서 전달해준 lazy_load_segment를 실행해서 file에서 해당 위치를 메모리로 읽어오며 page의 원래 type에 따라 결정되는 page initializer를 호출하여 실제 로딩된 후 페이지에 필요한 정보들을 초기화하는 과정을 거친다.
page type에는 backing storage가 존재하는 file_backed_page와 존재하지 않는 anon_page가 존재한다.
또한, 가용할 수 있는 메모리가 가득 찬 경우에는 frame table에서 제거할 page를 골라서 disk에 저장하는 swap-out이 존재하는데 file_backed인 경우는 원래 mapping한 file이 있으므로 수정 사항이 있을 경우 다시 write하고 해제해주면 되고, anon의 경우는 storage가 없기 때문에 swap disk라는 저장장소에 해당 페이지를 저장하고 저장한 위치를 page에 저장하게 된다.
이 말은 즉슨, 다시 user가 해당 page를 참조할 경우 disk에서 불러오기 위해 page 정보를 spt에 계속 저장해두어야 한다는 것이다. anon_page는 page에 저장된 swap_slot 위치에서 해당 데이터를 읽어오고, file_backed의 경우에는 page에 저장된 파일, 오프셋, read_byte 정보를 바탕으로 read하면 되는 것이다.
stack은 함수에서 지역변수로 호출되는 인자들이 저장되는 곳으로 미리 해당 공간을 예측해서 할당할 필요가 없다. 또한, page도 만들지 않기 때문에 uninit page로도 존재하지 않는다. 따라서 page_fault handler에서 해당 fault address를 stack 영역인지 확인하여 유효한 주소인 경우 stack growth를 호출하여 필요한 크기만큼 page를 할당해준다.
다만, 프로세스 실행 시 받은 인자들을 stack에 저장하기 위해서는 lazy_loading 할 수 없기 때문에 uninit page를 생성함과 동시에 anon_page로 initialize하고 바로 한 개의 page를 할당하여 사용할 수 있게 한다.
전반적인 내용을 복기해보았을 땐 이렇고, 실제로는 detail한 부분들이 훨씬 더 많다. 특히 page map level 4 관련해서 유저의 가상 주소와 physical frame을 mapping 시켜주는 함수들을 꽤 오래 들여다 보았다.
user virtual address는 page table에서 해당하는 page entry를 찾아가고, page entry에는 해당 page의 physical frame number와 해당 페이지의 상태가 적혀있는 bit들이 존재한다.
따라서, 우리가 swap_out을 위한 page를 선택할 때, page entry의 accessed bit를 확인하거나, file_backed_page의 경우 dirty bit를 통해 수정 유무를 확인하여 다시 file에 write back할지 말지를 결정할 수 있는 것이다.
두서 없이 적긴 했지만 어느정도 전체 그림이 머릿속에 남아있을 정도로 열심히 한 프로젝트 절차였던 것 같다. VM에 너무 힘을 쏟은 나머지 file system때는 나도 모르게 조금 힘들어서 다소 소홀하지 않았나 라는 후회가 들었다.
이 밖에도, fork 시 page 정보들을 모두 복사하는 함수, 프로세스 종료 시 사용하던 resource들을 모두 반납하는 과정 등 여러 항목들이 남아 있지만 해당 설명들은 그림과 함께 정리하였으니 이만 정리하도록 하겠다.
이번 주차는 특히 거의 외부 자료들을 참고하지 않고 만들었기 때문에 더욱 의미있던 프로젝트가 아닌가 싶다. 사실 메모리 부분이 재밌어서 더 의욕적으로 진행했던 것은 사실인듯 하다!
