LSTM
.
이전에 LSTM을 이용하여 이더리움 차트를 예측해보았다.
그러나 주식 가격을 주식 차트를 분석하는 것으로 예측하는 것은 무의미하다.
앞선 이더리움 가격 분석 시에는 이더리움 가격을 1~7일의 일주일 치를 모아 하나의 시퀀스 데이터로 이용했고 다음 날인 8일의 주식 가격을 레이블로 사용해 학습했다.
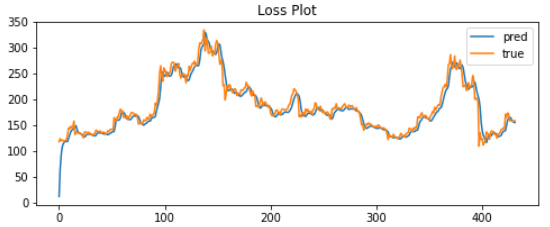
근데 사실 해당 그래프를 확대해 보면 다음 날의 예측 값을 전날의 실제 값으로 돌려주는 게 대부분이라고 한다.
그 이유는 LOSS가 가장 작은 결과를 예측 값으로 주려고 하다보니 발생하는 문제이다. 즉, 다시 말해 완전히 과적합된 의미 없는 예측 결과라는 것이다.
실제로 우리가 주식을 한다고 생각해도 보통 전날의 가격이 다음 날의 가격에 어떤 영향을 미친다고 생각하지 않는다.
오히려 전날 거래량, 전날 나스닥지수 증감량, 관련 업종 주가추이, 해당 기업 긍/부정 이벤트 발생 등의 fearture들이 주식 가격에 의미 있는 영향을 미친다.
따라서 이 feature들을 데이터화(벡터화)하여 학습에 이용하는 것이 의미가 있다.
하지만 추가적으로 이더리움 가격은 Random성이 상당히 높기 때문에 LSTM을 통해서 분석하는 것은 큰 의미가 없다고 한다.
농산물 가격 예측 논문 리뷰
그렇다면 LSTM을 공부하기 위해서 분석해봄직한 데이터가 뭐가 있을까 고민해보았다.
시간의 흐름에 관련이 있는 데이터로 Random성이 약한 데이터로 '농산물 가격'데이터를 분석해보면 좋을 것으로 생각했다.
구글을 서치하여 한국과학기술정보연구원에서 지원하여 진행된 LSTM 네트워크를 활용한 농산물 가격 예측 모델이라는 논문을 발견해 분석, 학습해보았고 해당 내용을 간단하게 리뷰한다.
한국과학기술정보연구원, LSTM 농산물 가격 예측 모델
연구의 목적
기상으로 인해서 많은 기업들이 영향을 받고 뿐만 아니라 우리 주변에도 밀접한 영향을 주어 연구를 시작한 것 같다.
극심한 날씨 변화로 인해서 자연 재해의 형태로 우리에게 피해를 주는데 소비자 물가 변화도 그 중 하나라고 보는 초점이다.
논문은 자연 재해로 인해서 농산물 가격이 변하는 것을 예측한다면 정부가 소비자 가격을 안정시키는 것에 도움이 될 것으로 판단한다.
가격 예측 연구
가격 변화는 일정한 시간상에서의 변화를 예측하는 것이므로 시계열 분석 기법을 사용했다고 한다. 주식, 석유 가격 예측에 대한 연구는 많이 진행되지만 농산물은 그렇지 않다고 한다. 그래서 더 연구가치가 있는 것 아닐까 싶다.
연구 설계, 실험 및 결과
1.변수 선정
앞서 이야기했듯이 단순히 가격만으로는 나중의 가격을 예측할 수 없다. 다른 요소들이 많은 영향을 미치기 때문이다.
가격에 영향을 미치는 요소로 기상, 과거 가격 변화, 생산량/지배면적, 공급량, 유가, 농가소득을 꼽았다.
여기서 농가소득에 관한 데이터를 구하는 것이 어려워 제외했다고 한다.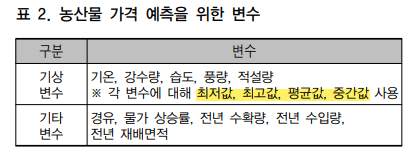
학습을 위해 수집한 데이터를 1차 전처리하는 과정을 수행.
데이터를 전부 모아 겹치는 기간의 데이터만 활용하고, 데이터가 비어있는 경우에 앞, 뒤의 데이터의 평균 값으로 채웠다고 한다.
전년 생산량과 같은 값은 그 해의 모든 일자를 동일한 데이터로 채워주었다.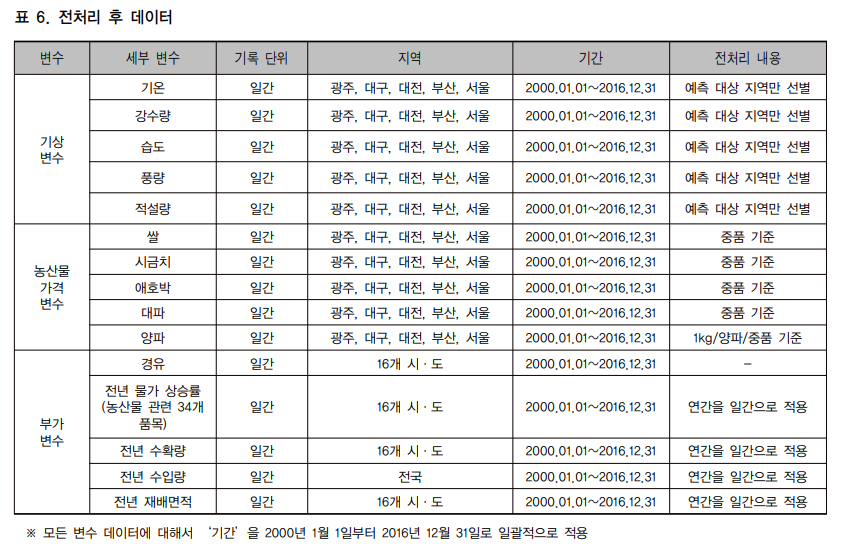
2차 전처리로 각 피처의 값의 범위가 제각각이므로 0~ 1사이의 값으로 정규화를 해줬다고 한다.
사이킷-런과 같은 라이브러리 사용하지 않고 직접 함수를 작성하여 정규화했다.
2. 알고리즘 선정
시계열 분석 기법을 사용해야 하므로 RNN 계열의 알고리즘을 사용해야 하는데
RNN은 장기 기억에 대한 단점을 가지고 있기 때문에 장기 기억 능력이 좋은 LSTM을 선정했다고 한다.
총 21일간의 데이터를 하나의 시퀀스로 만들고 이후 7일간의 데이터를 레이블로 사용하는 형태의 학습을 진행했다.
실험에서 사용한 LSTM의 구조는 아래와 같다.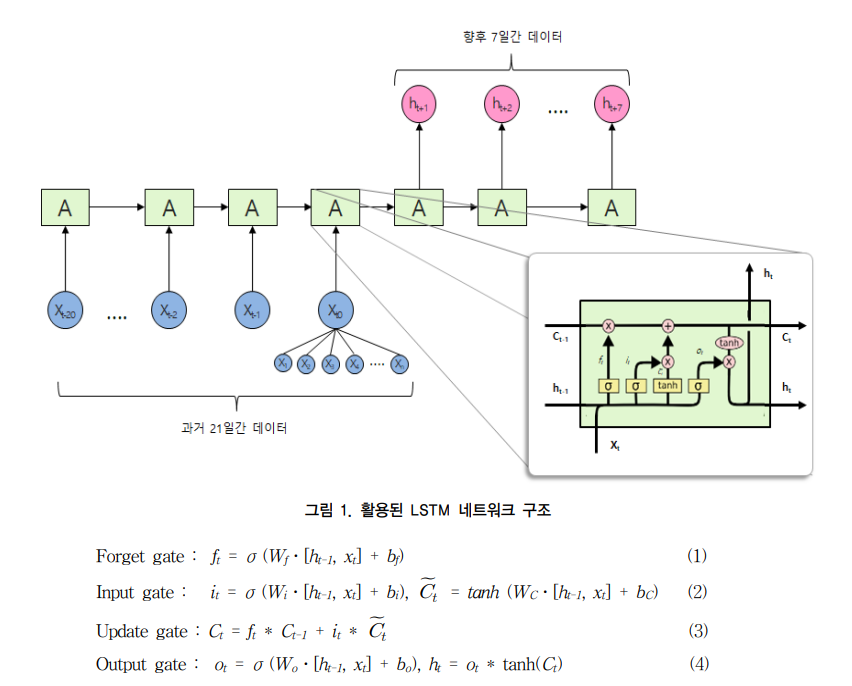
Forget gate: 셀 상태에서 버리고 유지할 정보 결정
Input gate: 새로운 정보를 셀 상태에 저장할지 결정
Update gate: 셀 상태 값은 input gate와 forget gate를 결합하여 결정
Output gate: 업데이트 된 셀 상태 값에 tanh를 적용하여 결정
3. 하이퍼 파라미터 선정
하이퍼 파라미터는 아래와 같이 선정했다.
과적합 문제에 대한 보정책으로 drop-out을 선택하여 사용한 모습이다.
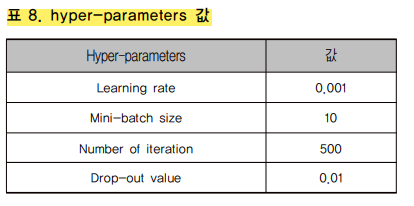
최적화 함수로는 adam optimizer를 선택했다.
모델 예측 성능을 평가하기 위해 오차는 RMSE를 사용해 계산했다.
4. 결과
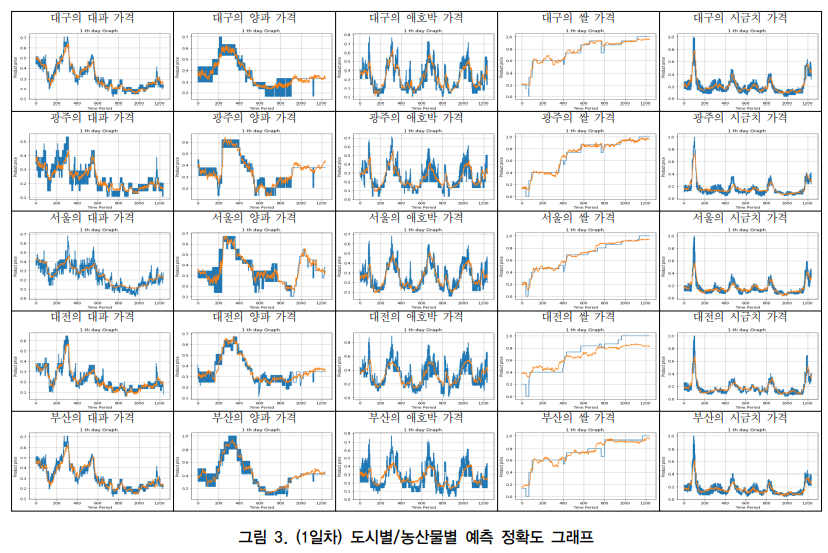
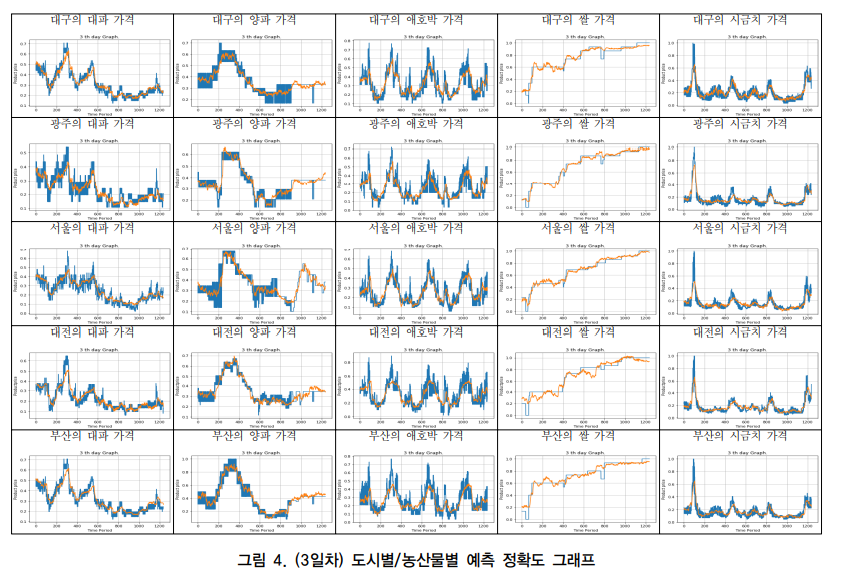
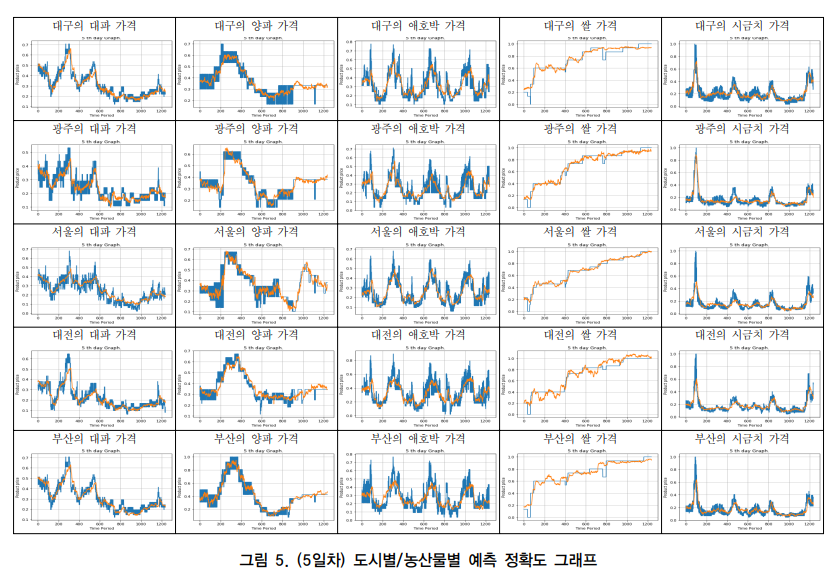
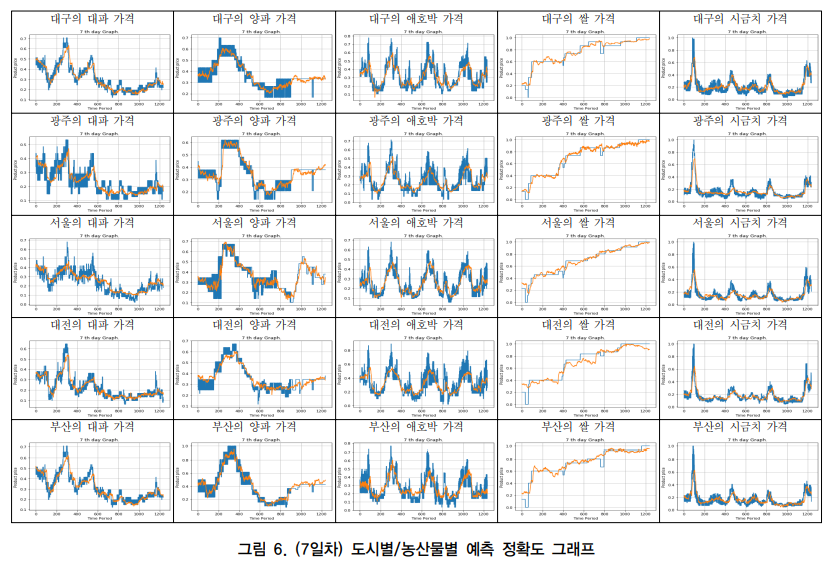
결론
LSTM을 공부하고 유의미한 활용을 해보고 싶어서 이더리움 가격을 분석, 예측해보려고 했다.
하지만 이더리움은 랜덤성이 큰 데이터로 LSTM을 통한 분석 의미가 없다고 한다...
최대한 의미있는 분석을 하고 싶어서 데이터를 검색 및 선정하는 과정에 있고 그 과정에서 농산물 데이터를 분석한 논문을 공부해보았다.
꽤나 의미있는 연구인 것 같고 다른 데이터를 통해서 결과를 내려고 할 때 참고할만한 자료인 것 같다.
