Python
Variable assignment
va_1 = 0python에서의 변수 선언은 다른 언어(C++, java 등) 과 달리
1. 할당하기 이전에 선언할 필요가 없다.
2. 타입 설정을 해주지 않아도 되고, 다른 타입으로 재할당 해주어도 된다.
Intention
if va_1 > 0:
print("va_1 is positive number")python에서의 조건문이나 반복문에서는 brace로 block을 체크해주지 않는다.
: 다음에 나타나는 구문이 앞에 space를 가진다면 그 구문이 조건문, 반복문의 block에 들어가는 것이다.
Arithmetic
va_2 = "a"
print(va_2 * 4)
# aaaa
print(5/2) # 2.5
print(5//2) # 2
print(5**2) # 25python에서의 +, *는 숫자형 변수의 계산에서만 사용할 뿐만 아니라 문자열에서도 유동적으로 사용할 수 있다.
//는 floor division으로 int를 반환하고
**는 power를 의미한다.
print(min(1,2,3)) #1
print(max(1,2,3))#3
print(abs(-32))#32python에서의 min, max는 C++과 달리 3개이상의 인수가 들어가도 된다.
-32와 같이 숫자 앞에 -를 붙이면 음수 표현이 가능하다.
Function
Docstrings
def least_difference(a, b, c):
"""Return the smallest difference between any two numbers
among a, b and c.
>>> least_difference(1, 5, -5)
4
"""
diff1 = abs(a - b)
diff2 = abs(b - c)
diff3 = abs(a - c)
return min(diff1, diff2, diff3)
Docstring은 함수 선언 바로 다음에 나오는 구문으로
""" """으로 표시된다.
help()로 해당 함수의 정보를 얻고자 할때 나오는 것이 Docstring이다.
Booleans
True or True and False
# Truepython에서의 논리연산자는 not -> and -> or의 순서이다.
그러므로 위의 구문은 True가 나오게 된다.
List comprehensions
squares = [n**2 for n in range(10)]
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]List를 한줄로 만들 수 있는 python의 기법이다.
[ ( 변수를 활용한 값 ) for ( 사용할 변수 이름 ) in ( 순회할 수 있는 값 ) 조건문 ]
의 형태로 이루어 진다.
squared_list = [[n ** 2 for n in row] for row in arr]와 같이 다차원 배열을 만들 수 도 있다.
String Function
str_1.isdigit()
str_1.rstrip('.,')
str_1.split(' ')어떤 string안에 숫자만 들어가 있는지를 확인하기 위해서는 isdigit()을 사용하면 된다.
strip을 사용하면 string의 특정 문자들을 뒤에서, 앞에서 삭제할 수 있다.
split을 사용하면 특정 문자를 기준으로 string을 분해할 수 있다.
Enumerate
for entry in enumerate(['A', 'B', 'C']):
print(entry)
#(0, 'A')
#(1, 'B')
#(2, 'C')
for i, entry in enumerate(['A', 'B', 'C']):
print(entry)
#0 A
#1 B
#2 Cpython에서 반복문을 돌리는 특이한 방식이다.
어떤 변수를 기준으로 반복문을 돌릴때, in 뒤에 enumerate를 써주면
index, value 형태의 tuple을 반환한다.
in 앞에서 i, entry와 같이 unpacking을 해준다면
i는 index, entry는 value의 형식으로 반환한다.
Dictionary
Dic_1 = {} // 선언부
Dic_1["key_1"] = [0,1,2]
del my_dict['key'] //삭제DIctionary의 선언부와 key value를 넣는 방법이다.
Pandas
Dataframe
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])pandas의 자료구조 중 하나인 Dataframe이다.
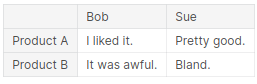
Dictionary의 연속으로 이루어지는 케이스가 가장 흔하며, Dictionary의 key가 열의 index, value가 그 열로 다 들어간다.
인자로 index=[]를 넣어주면 이것은 행의 index가 되며, 넣어주지 않는다면 0부터 시작하는 ascending sequence가 된다.
Series
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
#2015 Sales 30
#2016 Sales 35
#2017 Sales 40
#Name: Product A, dtype: int64series는 Dataframe과 달리 단순한 list로 생각하면 된다.
index를 붙이면 행의 이름이 생긴다.
read_csv
reviews = pd.read_csv("../input/wine-reviews/winemag-data_first150k.csv", index_col=0)csv파일을 Dataframe으로 읽는 구문이다.
index_col을 사용하면 특정 열을 행의 이름으로 넣을 수 있다.
parse_dates
reviews = pd.read_csv("../input/wine-reviews/winemag-data_first150k.csv", index_col=0, parse_dates=True)DataFrame 안에 날짜/시간 데이터가 있을 경우에 사용한다.
자동으로 날짜/시간 데이터를 파싱해 python의 날짜/시간 데이터로 변형한다.
Indexing
Index-based selection
reviews.iloc[0] #1
reviews.iloc[:, 0] #2
reviews.iloc[[0, 1, 2], 0] #3iloc는 index-based selection이다.
iloc의 첫번째 인자는 행, 두번째 인자는 열을 기준으로 하며
#1 과 같은 경우는 0번째 행의 정보를 Series로 반환하기 때문에
country Italy
description Aromas include tropical fruit, broom, brimston...
...
variety White Blend
winery Nicosia
Name: 0, Length: 13, dtype: object
와 같이 나타나게 된다.
#2는 :를 통해 행의 모든 정보, 0을 통해 0번째 열을 나타내는 것으로
0 Italy
1 Portugal
...
129969 France
129970 France
0번째 열인 Country에 대한 정보가 Series로 나오게 된다.
#3같이 사용할 수도 있다.
Label-based selection
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]iloc와 달리 label을 기준으로 한다.
위의 구문과 같이 사용하면 된다.
iloc vs loc
iloc는 index기반이기 때문에 기존에 썼던 언어들의 인덱싱을 기본으로 한다.
그러므로 iloc[:100]을 하게되면 0~99, 100개의 행이 들어가게 된다.
하지만 loc는 label기반이므로 100을 하나의 label로 취급하여 포함하기 때문에 101개가 된다.
Conditional selection
reviews.country == 'Italy' #1
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)] #2
reviews.loc[reviews.country.isin(['Italy', 'France'])] #3
reviews.loc[reviews.price.notnull()] #3#1과 같은 경우는 단순한 boolean 타입의 Series를 반환한다.
0 True
1 False
...
129969 False
129970 False
Name: country, Length: 129971, dtype: bool
#2와 같은 경우처럼 사용하면 그 조건에 해당하는 Dataframe을 반환한다.
#3은 isin, notnull이라는 built-in function을 사용한 경우로, 해당 조건에 맞는 Dataframe을 반환한다.
Map
review_points_mean = reviews.points.mean()
reviews.points.map(lambda p: p - review_points_mean)
n_trop = reviews.description.map(lambda desc: "tropical" in desc).sum()#2map을 이용하여 series의 값을 바꿀 수 있다.
#2 와 같이 desc에 tropical이라는 단어가 들어가 있는 것을 확인하는 것 처럼 조건문으로 응용할 수 있다.
lambda
(lambda x,y: x + y)(10, 20)lambda 매개변수:표현식의 형태로 한줄로 함수를 표현할때 사용한다.
Apply
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')Map과 마찬가지로 사용되지만 DataFrame에 직접적으로 연결된다.
Map과 Apply 모두 새로운 변수를 만들어 낸다는 점에 유의하자.
Groupby
reviews.groupby('points') #1
reviews.groupby('points').points.count() #2
reviews.groupby('points').price.min() #3
reviews.groupby('winery').apply(lambda df: df.title.iloc[0]) #4
reviews.groupby(['country']).price.agg([len, min, max]) #5
best_rating_per_price = reviews.groupby("price")['points'].max().sort_index() #6groupby는 특정한 column을 기준으로 Dataframe을 재정의해준다.
기본적인 형태는 #1과 같은 형태이며
#2와 같이 일반적인 함수를 사용해 줄 수도 있고, #3과 같이 통계량을 계산할 수도 있다.
#4와 같이 apply를 사용해서 나타낼 수도 있고
#5와 같이 agg라는 함수를 이용해서 한번에 다양한 통계량을 나타낼 수 도 있다.
groupby의 return은 groupbySeries이다.
#6
price
4.0 86
5.0 87
6.0 88
7.0 91
8.0 91
..
1900.0 98
2000.0 97
2013.0 91
2500.0 96
3300.0 88
Name: points, Length: 390, dtype: int64
Sorting
countries_reviewed.sort_values(by='len')
countries_reviewed.sort_values(by='len', ascending=False)
countries_reviewed.sort_index() #3DataFrame을 정렬할때는 sort_values를 쓰는게 가장 간편하다.
sort_value의 인자로는 열의 인덱스가 들어오며
ascending = False이면 내림차순이 된다.
다시 이 DataFrame을 index를 기준으로 정렬하고 싶다면 #3에 나오는 대로 sort_index()를 사용하면 된다.
Dtypes
reviews.price.dtype #1
reviews.dtypes #2
reviews.points.astype('float64') #3데이터 타입을 알려준다.
#1처럼 열 하나의 데이터 타입을 알 수도 있고
#2처럼 DataFrame 전체의 데이터 타입을 알 수도 있다.
데이터 타입을 바꾸고 싶다면 #3와 같이 써주면 된다.
Missing Data
reviews[pd.isnull(reviews.country)] #1
reviews.region_2.fillna("Unknown") #2
reviews.taster_twitter_handle.replace("@kerinokeefe", "@kerino") #3python에서 결측값, 결손값은 NaN으로 찍힌다.
이러한 값들을 세세하게 확인하기 위해서는 #1를 사용하면 되고
이러한 값들을 채우기 위해서는 #2
특정 열의 특정 값들을 교체하기 위해서는 #3과 같이 사용하면 된다.
Numpy
np.array
one_dimensional_array = np.array([1.2, 2.4, 3.5, 4.7, 6.1, 7.2, 8.3, 9.5])
print(one_dimensional_array)
two_dimensional_array = np.array([[6, 5], [11, 7], [4, 8]])
print(two_dimensional_array)1차원, 2차원 배열 기본형이다.
sequence_of_integers = np.arange(5, 12)
print(sequence_of_integers)np.array(시작, 마지막, step)으로 사용하며
시작 ~ 마지막의 step에 따른 수를 배열에 넣어준다.
zero = np.zeros(3, dtype = int)
print(zero)
one = np.ones(shape= (10,2), dtype=int)
print(one)zero는 0, ones는 1로 지정하는 shape에 따라서 값을 채워준다.
shape안에 튜플을 넣어 다차원 배열로 생성할 수도 있다.
