암호학, 로그인 방식의 역사

생활코딩 암호학
https://youtube.com/playlist?list=PLuHgQVnccGMD-9lk4xmb6EG1XK1OmwC3u
로그인의 역사
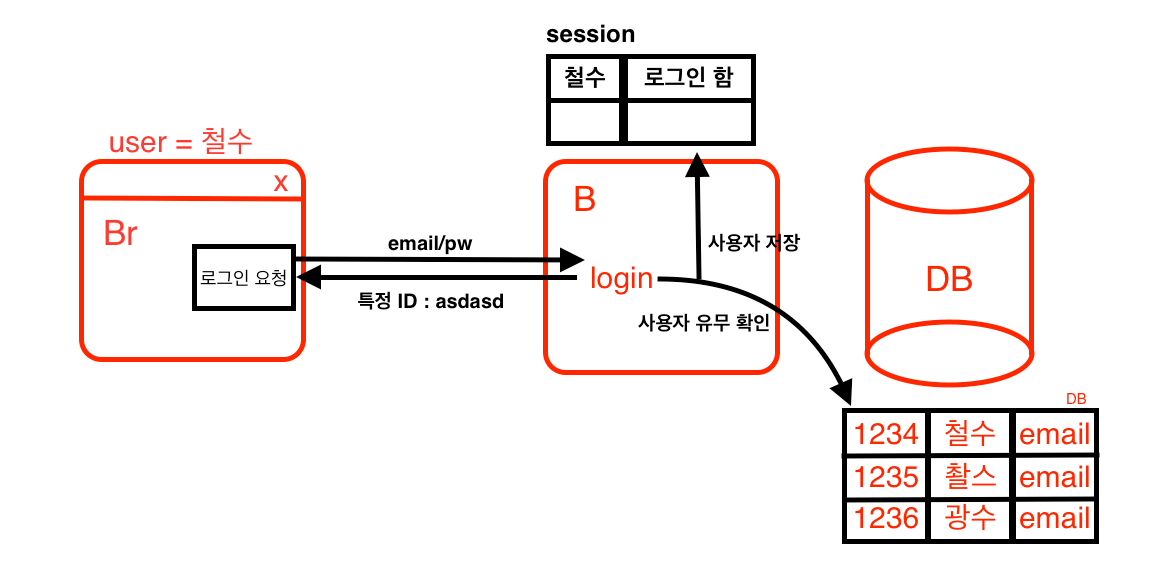
브라우저에서 특정 email, PW를 가지고 로그인을 하게되면 백엔드로 LoginApi 요청이 날아가게 되고, 백엔드에서 해당 유저가 있는지 DB에서 확인 후 있으면 session에 저장 → 특정한 id를 부여해서 부러우저에게 보여준다.
→ 유저의 ID를 백엔드 서버로 받다보니 한번에 여러명의 정보를 받기엔 한계가 있음.
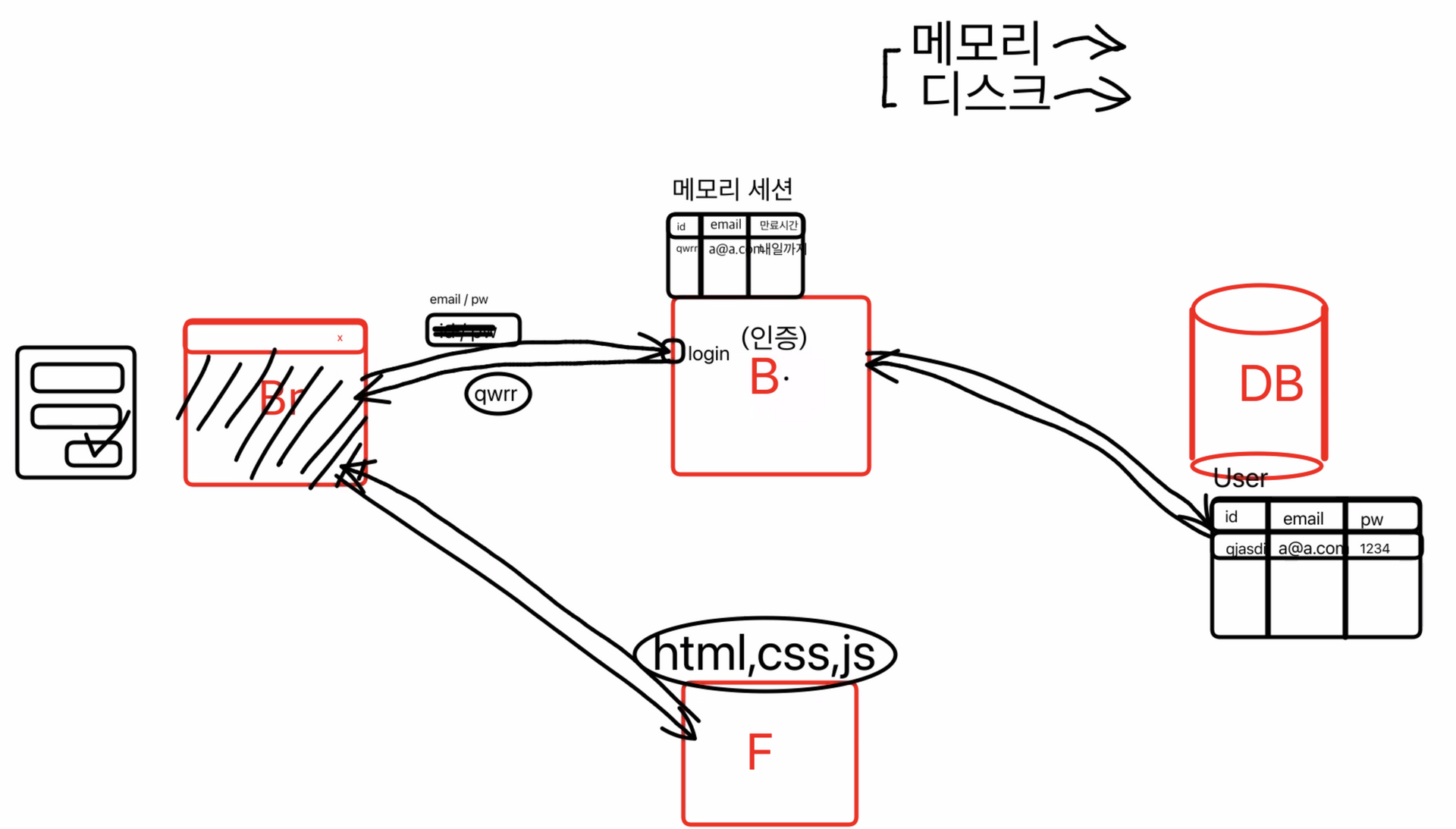
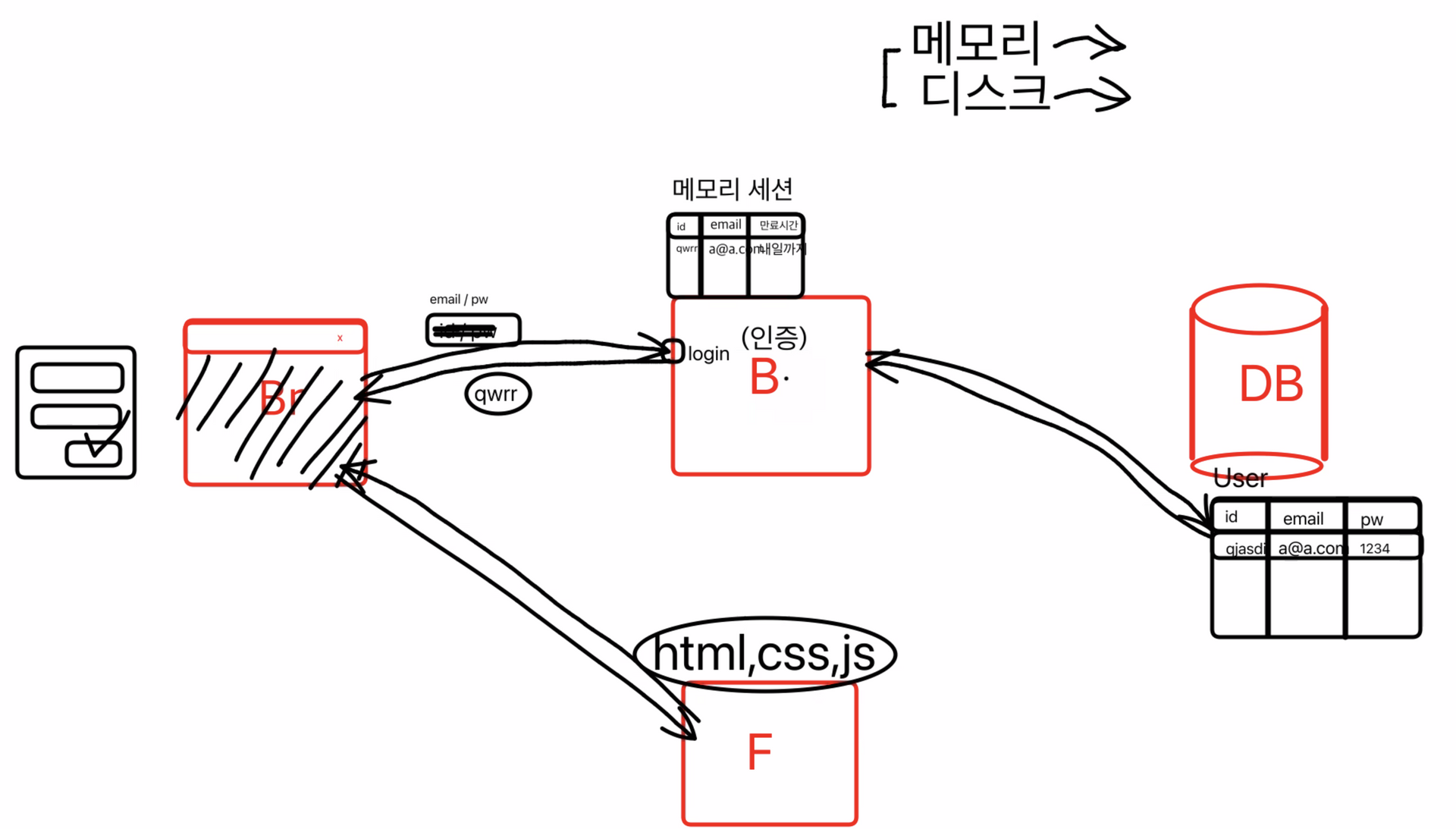
인증 (Authentication)
로그인 하기를 클릭하면 로그인 api를 요청하고 있는지 확인하고 없다면 에러 있다면
메모리에다가 세션정보를 저장해놓고 세션의 아이디를 브라우저로 돌려준다
- 브라우저는 받아온 아이디를 변수로써 저장해놓는다
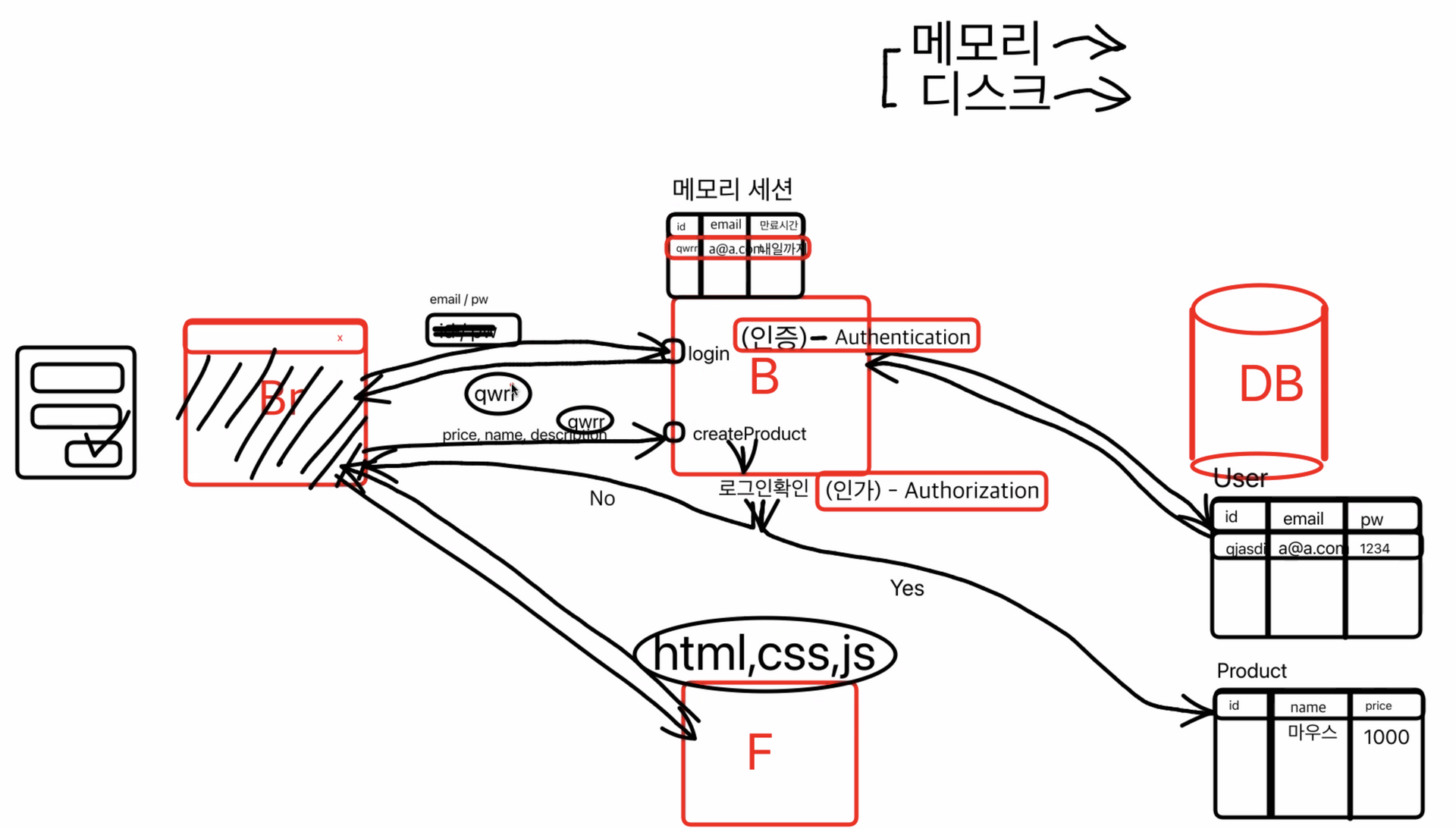
인가 (Aythorization)
상품등록할때 회원일 때만 물건을 등록할 수 있게 만들기
createProduct 에 물건을 등록요청을 하고 메모리 세션에 저장된 로그인을보고 검증 (로그인 확인)
백엔드쪽에서 사용량이 늘어나면 어떤 문제가 일어날까?
→ 서버의 부하를 초래.
해결방법은 백엔드 쪽의 성능을 증가시키는 것이다. (scale-up)
두번째 로그인의 역사
백엔드 컴퓨터의 성능을 올려줘도 많은 유저가 동시에 접속하면. 여전히 서버의 부하
그래서 나온게 백엔드 컴퓨터를 복사하는 이 방법
유저의 정보가 담기는 백앤드 컴퓨터를 복사해 여러대의 컴퓨터로 서버의 부하를 분산
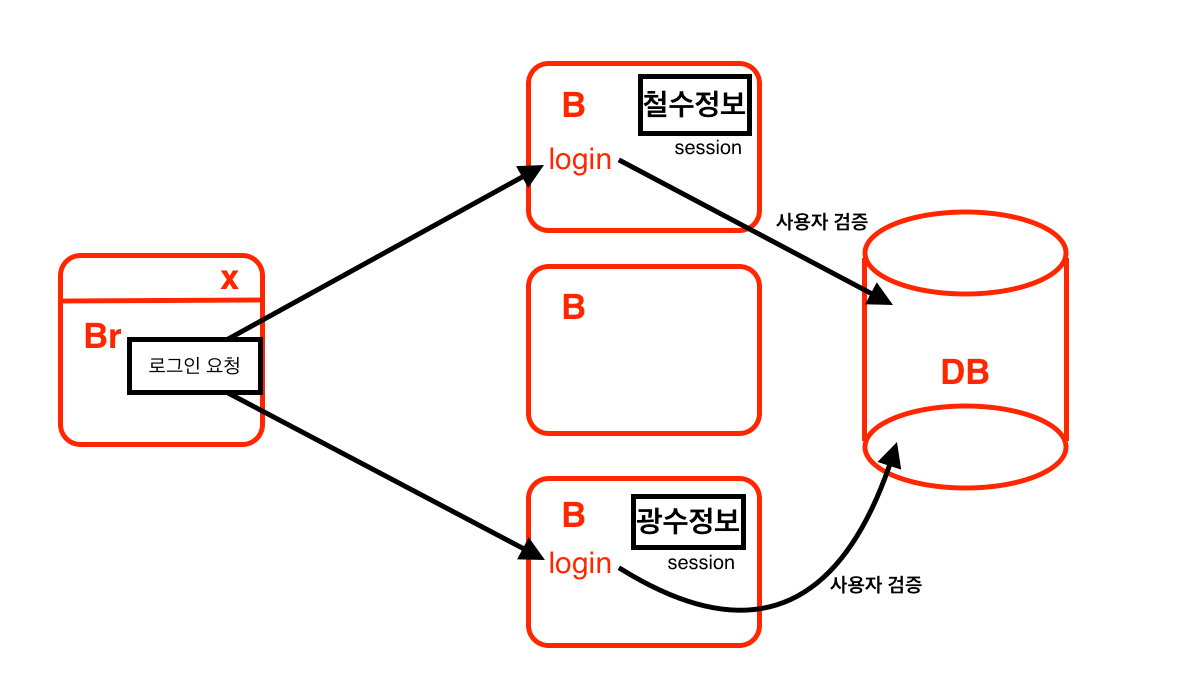
문제점: 컴퓨터를 복사할때는, 세션까지 scale out이 안되기 떄문에 기존의 로그인 정보를 가지고 있던 백엔드 컴퓨터가 아니면 로그인 정보가 없음
scale off - 똑같은 성능의 컴퓨터를 추가
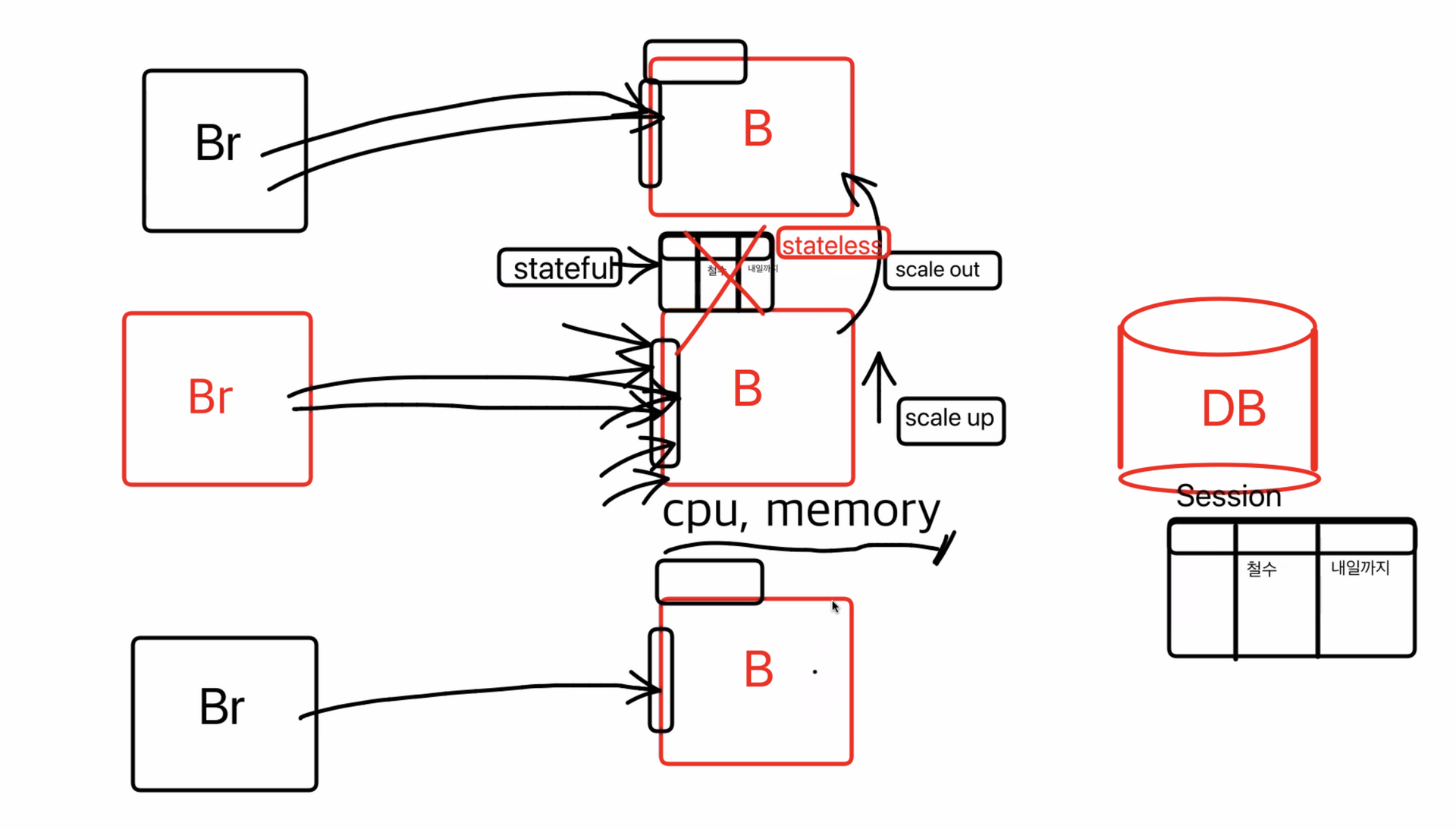
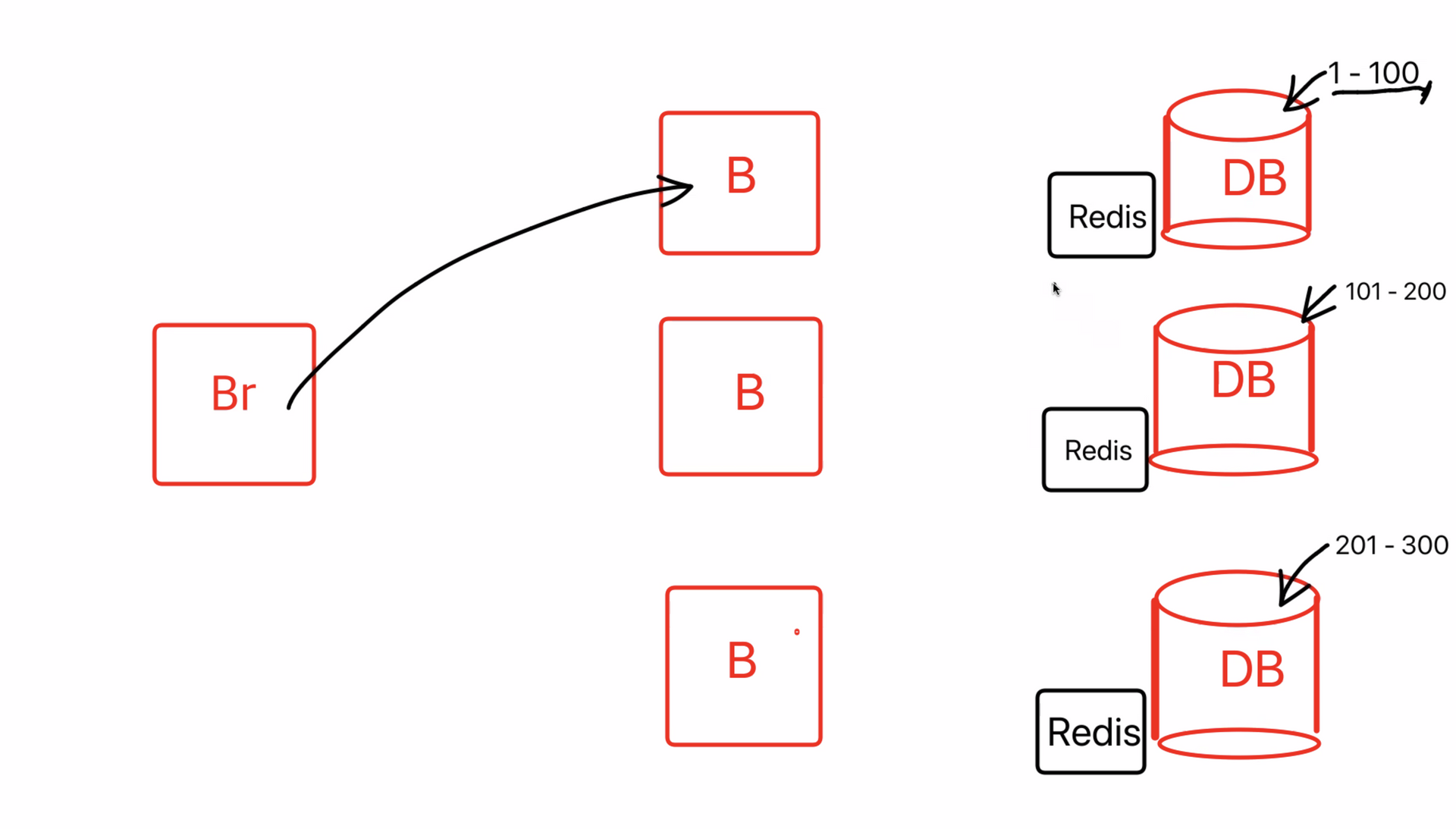
그래서 세션정보를 DB에 저장하고 stateless 상태로 만들어서 scale out을 해준다.
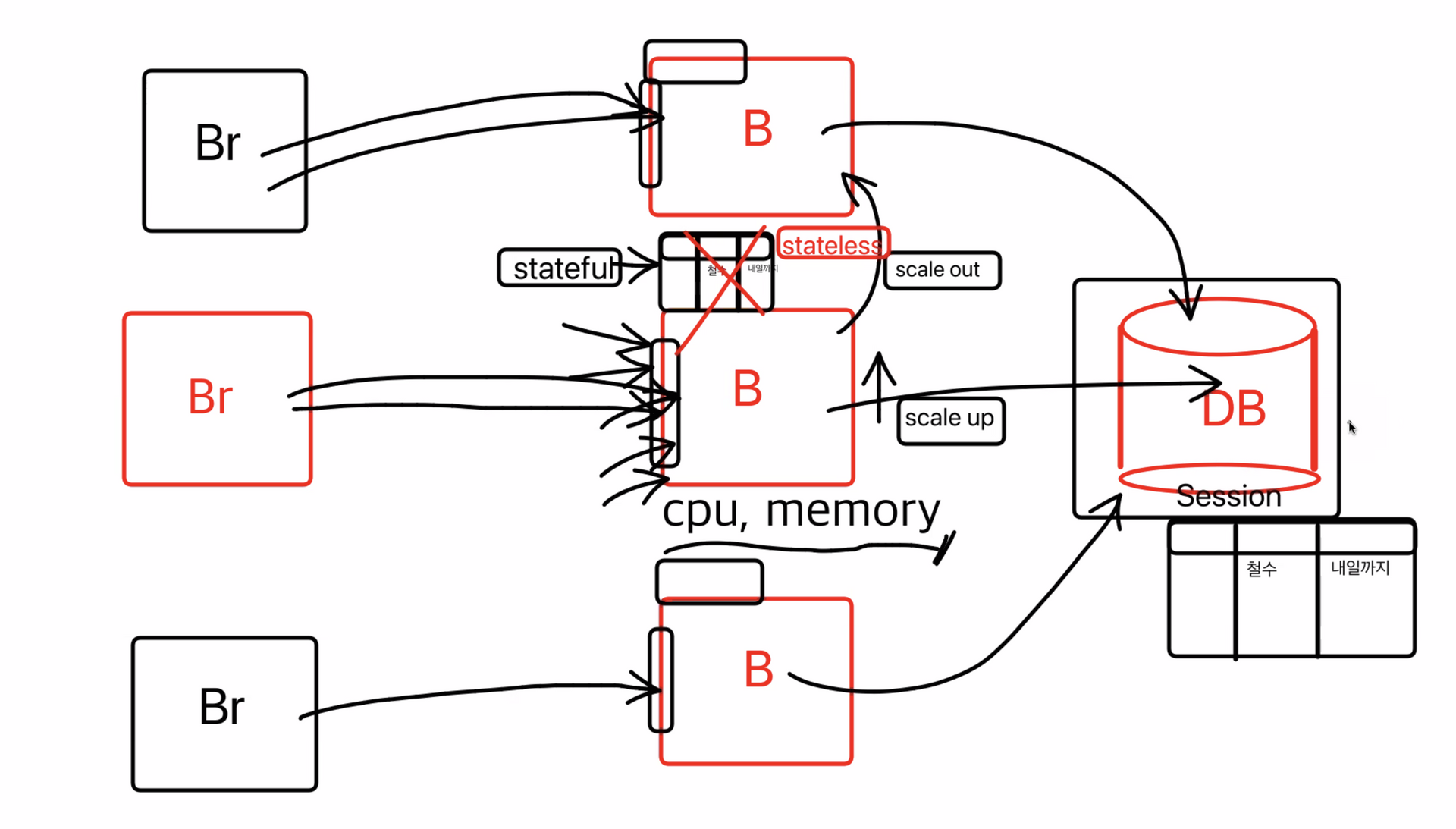
그렇다면 이제 DB로 트레픽이 몰릴텐데 DB는 어떻게 할것인가?
→ DB를 여러개 만드는 것은 힘들다(비용문제, 비효율적), 데이터를 쪼개면서 해결하게 된다
세번째 로그인의 역사
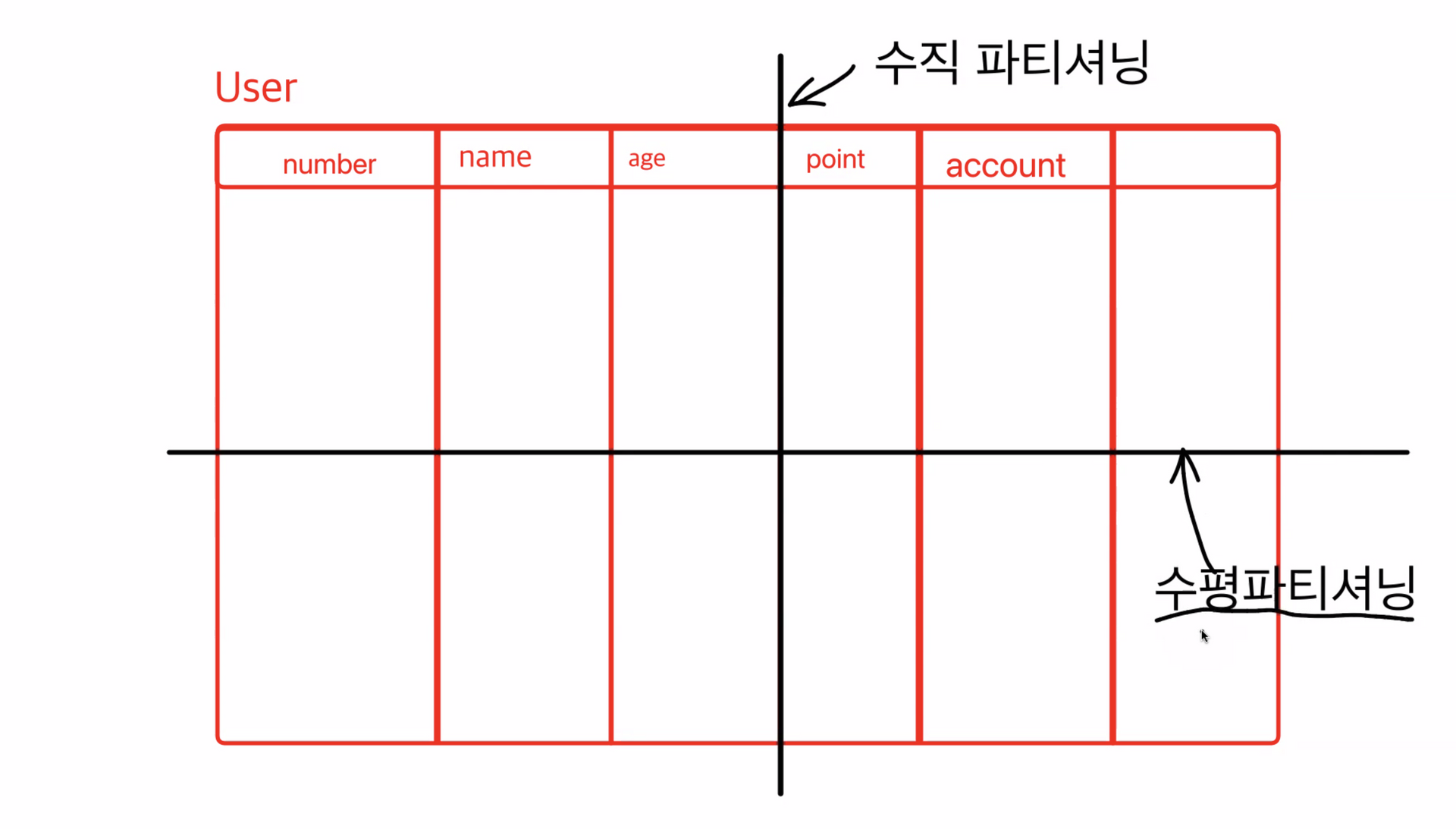
💡 데이터베이스를 쪼개는데는 2가지의 방법이 있습니다
- 수직으로 쪼개는 수직파티셔닝
- 수평으로 쪼개는 수평파티셔닝(샤딩)
DB는 컴퓨터를 껏다 켜도 데이터들이 disk에 저장되어 날아가지 않아서 안전함! 하지만 느리다.
disk에 저장된 데이터를 추출해 오는 현상 → DB를 긇는다 (scrapping) 이라고 표현
이를 해결하기 위한 방법은 Redis라는 데이터베이스에 저장. redis는 메모리에 저장하기 떄문에 문제점해결가능.
💡 Redis
→ 메모리에 저장해두는 임시 데이터 베이스
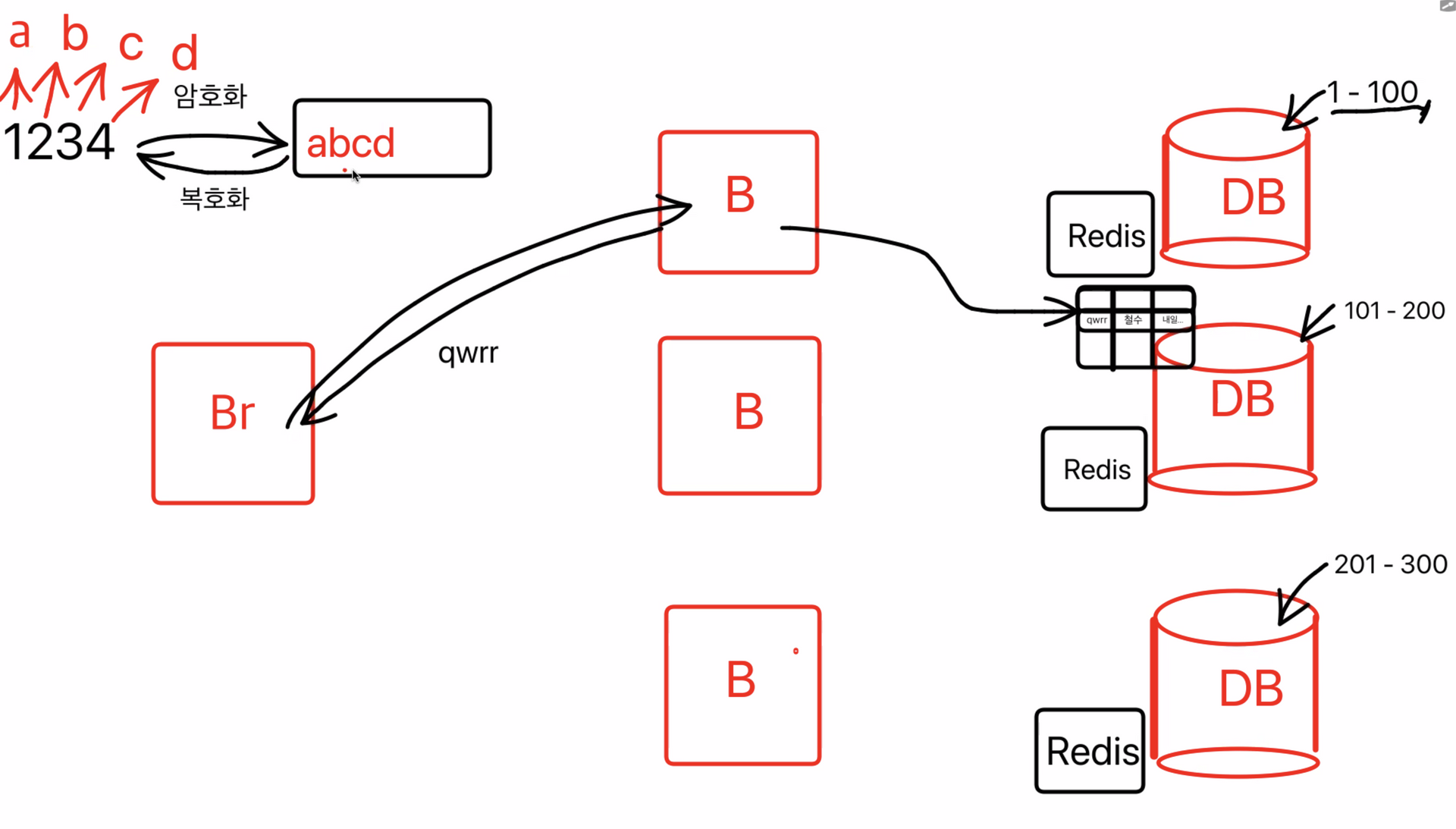
이렇게 저장된 특정 ID를 (토큰)을 다시 브라우저로 돌려주게 됨
돌려받은 토큰은 브라우저 저장공간에 토큰을 저장하고 어떤 행동을 할때 토큰을 같이 보내주어 사용자 식별
- stateless ⇒ 백엔드 컴퓨터에 상태를 가지고 있는 것은 아님.
JWT 로그인
똑똑한 사람들은 “로그인 정보를 굳이 서버나 DB에 저장해야 할까?” 생각을 했습니다.
그렇게 탄생한 것이 JWT 토큰입니다.
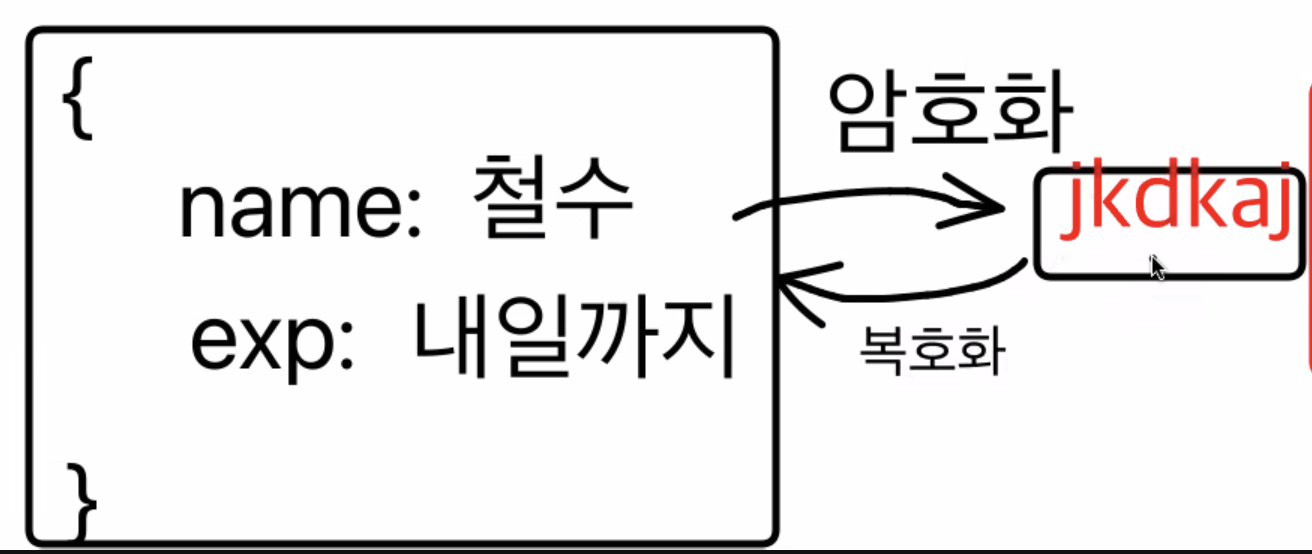
객체를 암호화
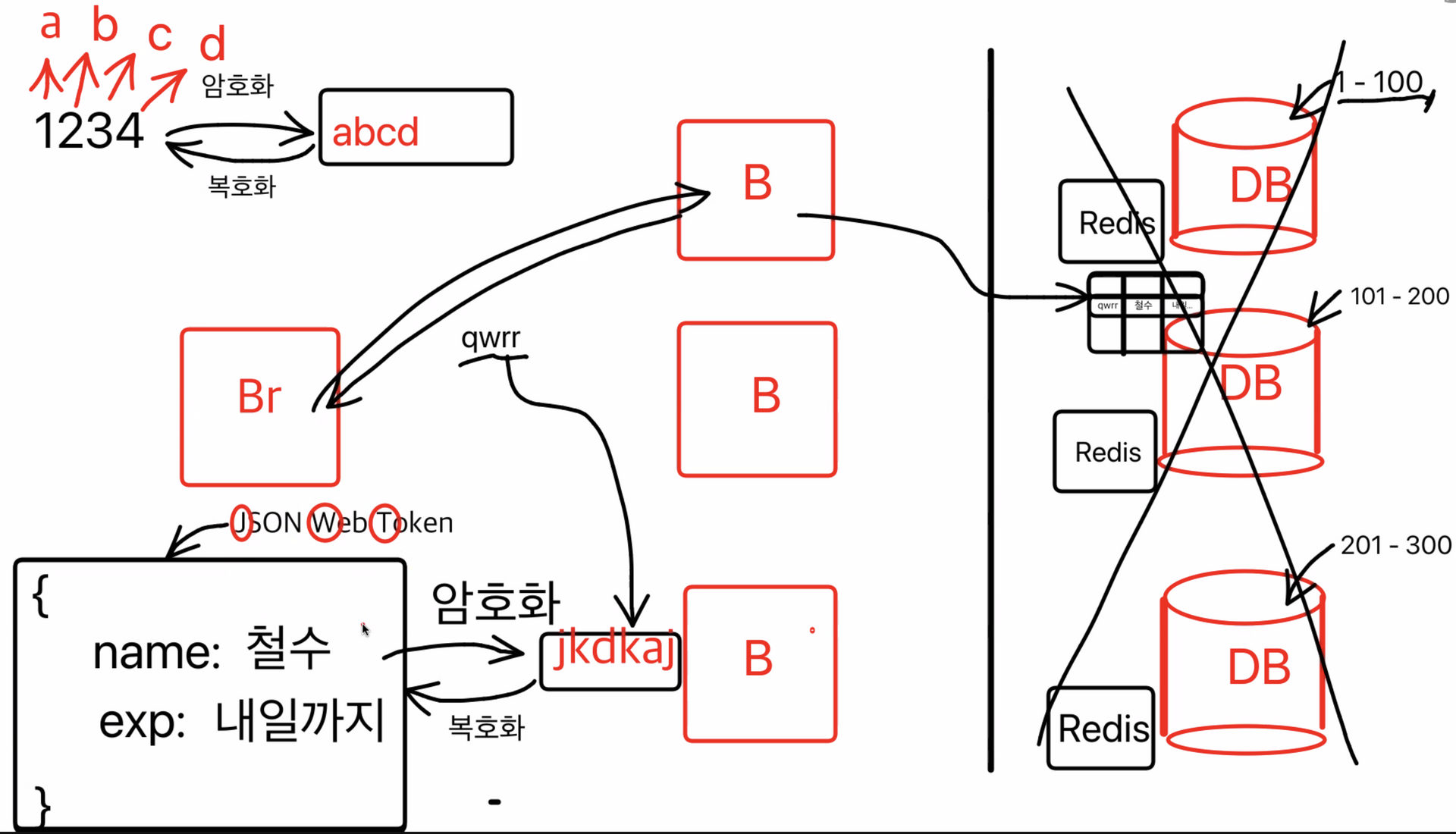
qwrr을 복호화 시키면 JWT가 나오는..
굳이 Redis와 DB까지 가지 않고도 유저의 정보를 암호화 해서 볼 수 있는 것

JWT 토큰은 유저정보를 담은 객체를 문자열로 만들어 암호화한 후 암호화된 키(accessToken)를 브라우저에 준다.
받아온 암호화된 키는 브라우저 저장소에 저장해두었다가 유저의 정보가 필요한 API를 사용할 때 보내주게 되면, 해당 키를 백엔드에서 복호화해서 사용자를 식별한 후에 접근이 가능하도록 한다
JWT 토큰에는 해당 토큰이 발급 받아온 서버에서 정상적으로 발급을 받았다는 증명을 하는 signature 를 가지고 있다.
사용자의 정보를 DB를 열어보지 않고도 식별할 수 있게 됨.
