
검색 프로세스 이해 (ES, Redis 등)
프론트쪽에서 검색기능은 간단하지만 백엔드에서 어떻게 처리되고 있는지 알아야 백엔드와의 소통할때 수월할 것이다.
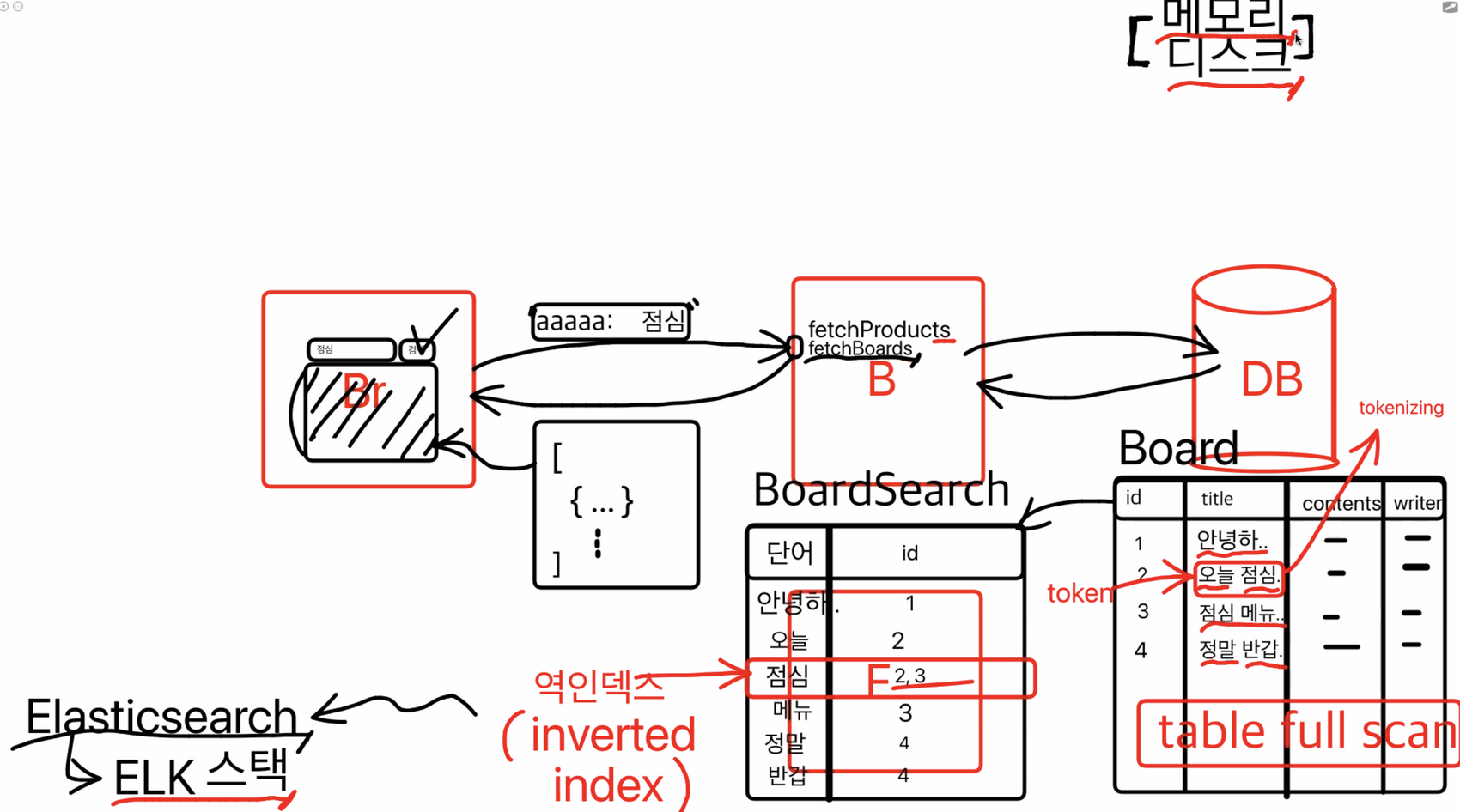
Browser에서 검색을 요청하면 Back-end에서 DB 내부의 수 많은 Data 들 속에서 요청받은 keyword를 가지고 full-scan 하게 된다. Data가 많을 수록 속도가 느리겠져? 이러한 방식을 변경할 수 있다.
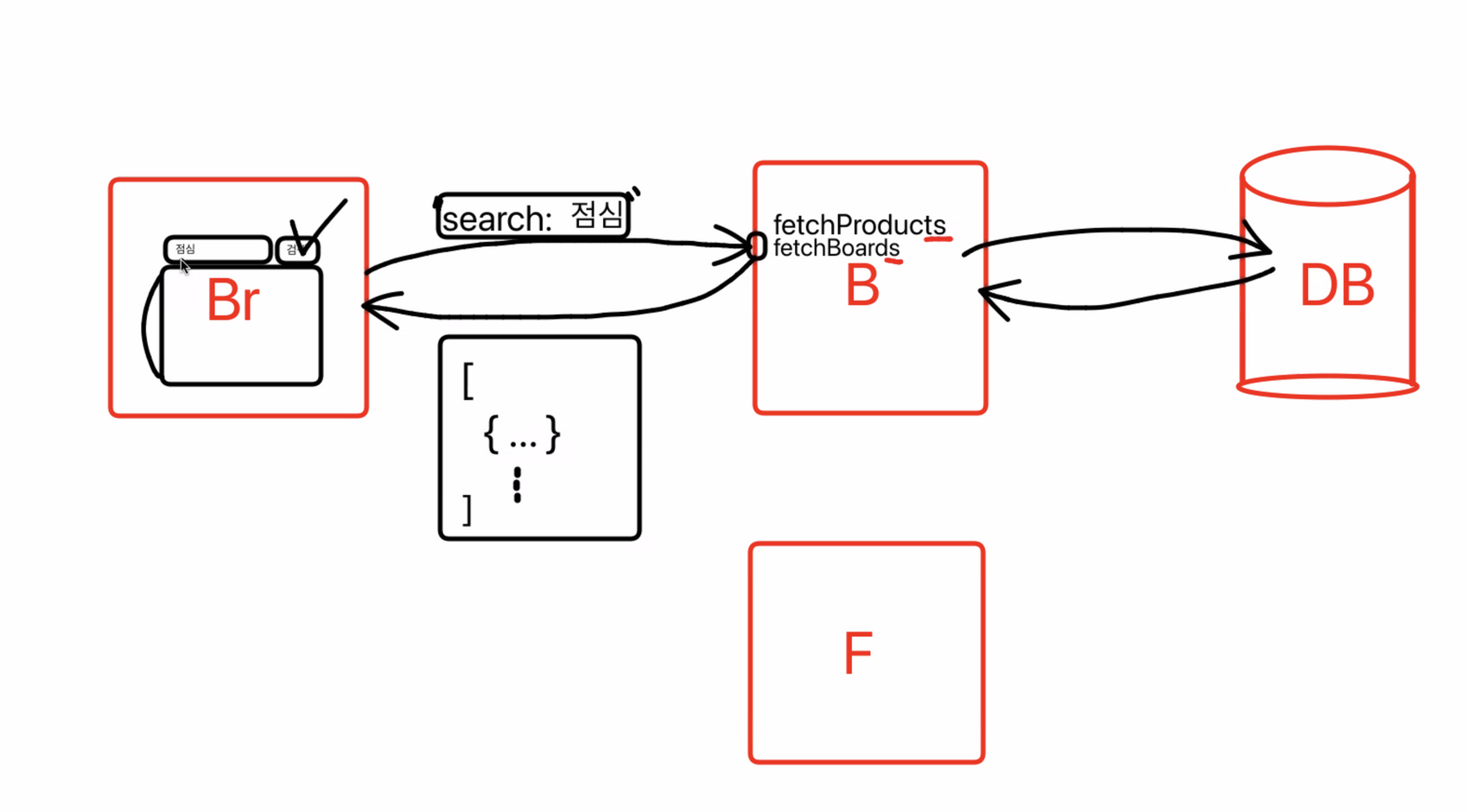
특정게시판 목록이 있고 검색어 입력하기 창이있고 검색버튼이 있다.
점심을 검색해서 버튼을 누르면 fetch를 요청을 하게 된다.
이후에는 백엔드에서 다 처리를 하고 우리에게 배열로 데이터를 출력해준다. (refetch)
search: 점심 → 약속된 명령어가 아닌 백엔드에서 정해준 것.
우리에겐 요청하고 받아오는 것 뿐이지만 백엔드 쪽에서는 힘듬을 느낀다고 한다. 그래서 소통이 안되는 경우가 종종 있다.

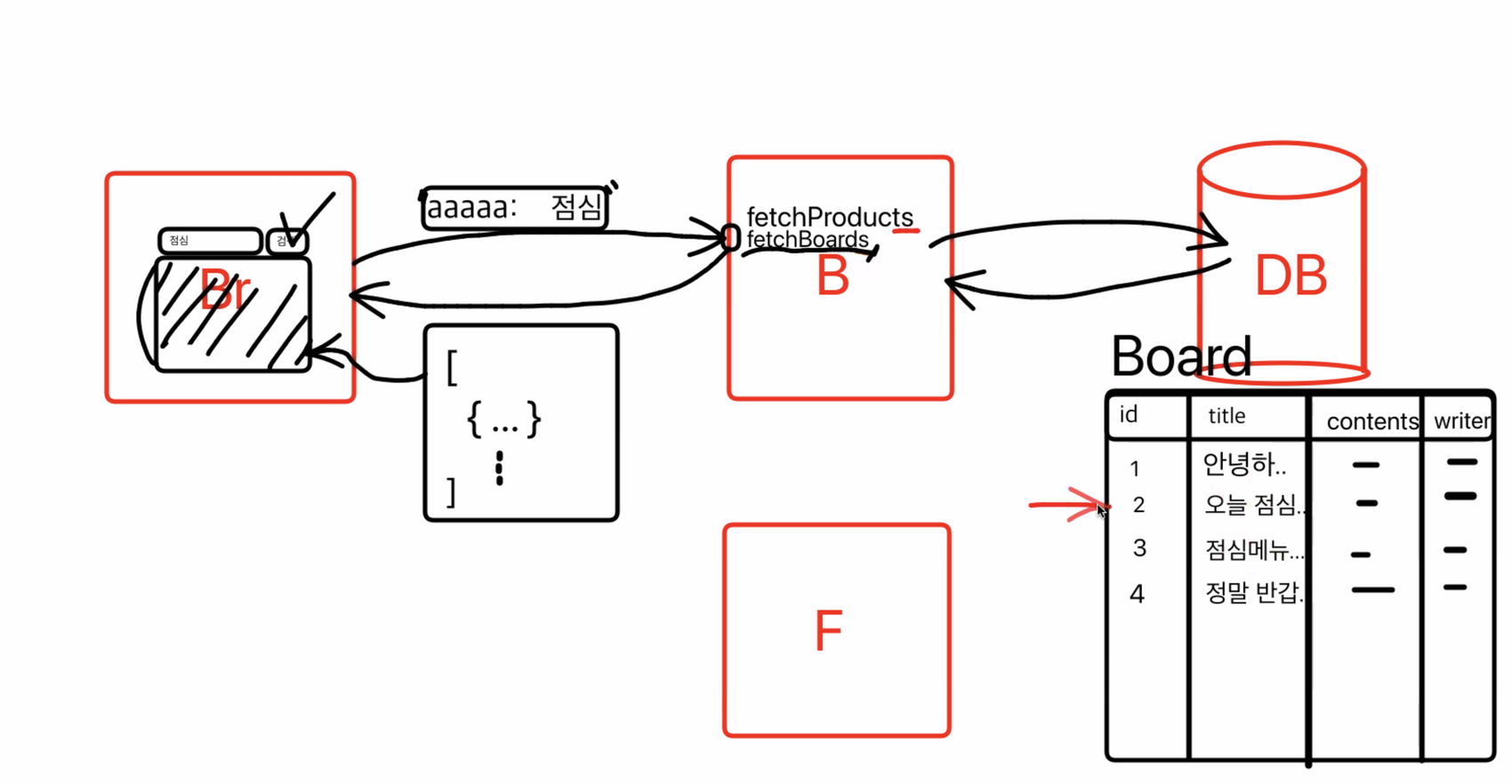
백엔드에서는 데이터베이스에서 데이터를 찾아오는데, 검색하기 위해서 해당하는 table을 찾고.
점심이 들어간 부분을 그 table에서 찾게 된다. 근데 테이블이 많을 경우 점심이라는 단어가 들어간 부분만 찾기 위해서 그 테이블을 모두 스캔하게 되면 속도가 굉장히 느리게 된다.
table full scan : table 전체를 스캔.
이런 것을 잘하는 회사 → Google 은 어떻게 해결했나?
띄어쓰기 기준으로 다 잘라버리는 것이다. → 테이블을 하나 더 만들어서 저장하는데.
단어와 id로 저장
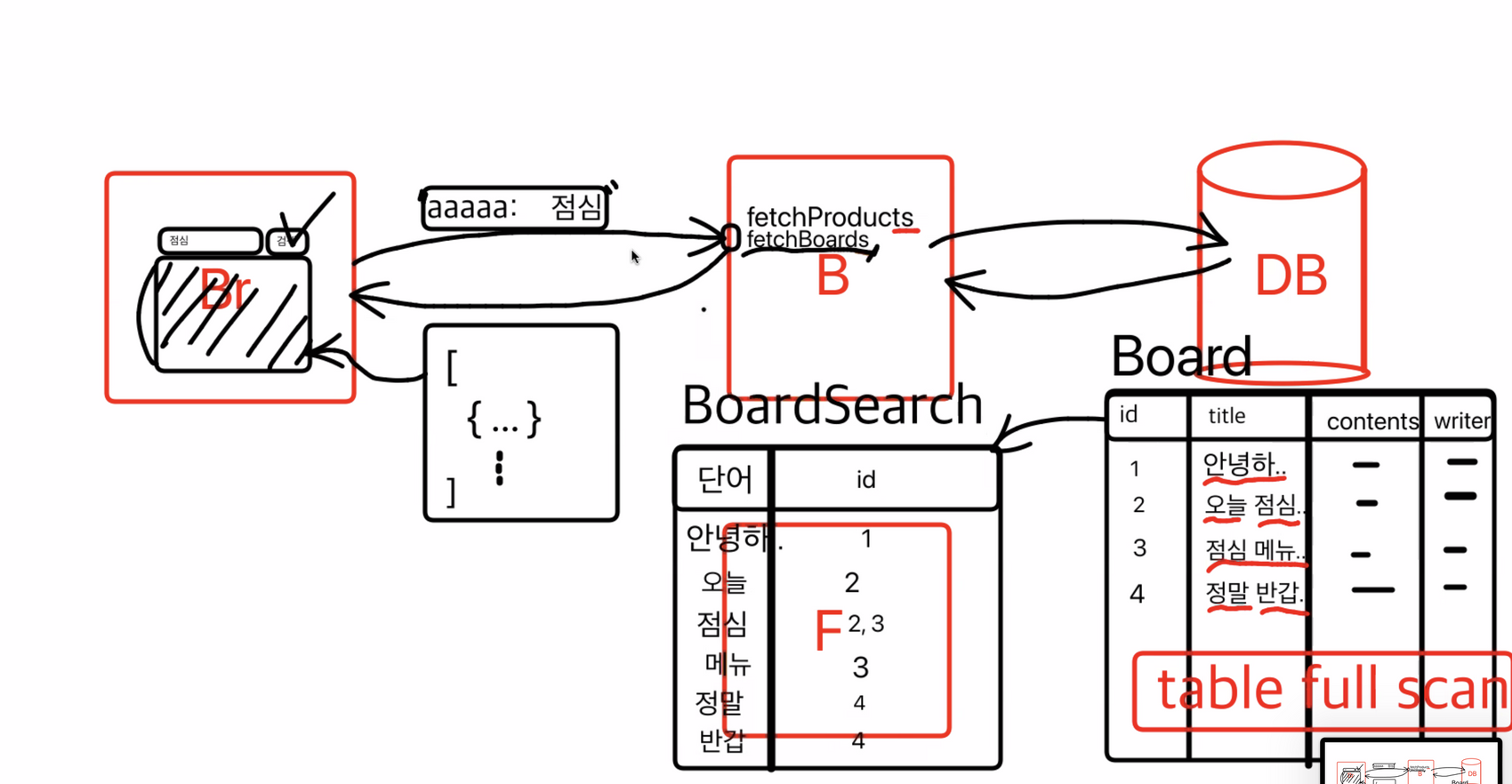
테이블을 하나 더 만든 것을 가지고 검색요청이 들어오면 search 테이블을 먼저 검색하는 것이다. 그러고 거기서 뽑아온 id 를 가지고 Board에서 가져오는 것! → 이것이 Google 초창기 로직이였다.
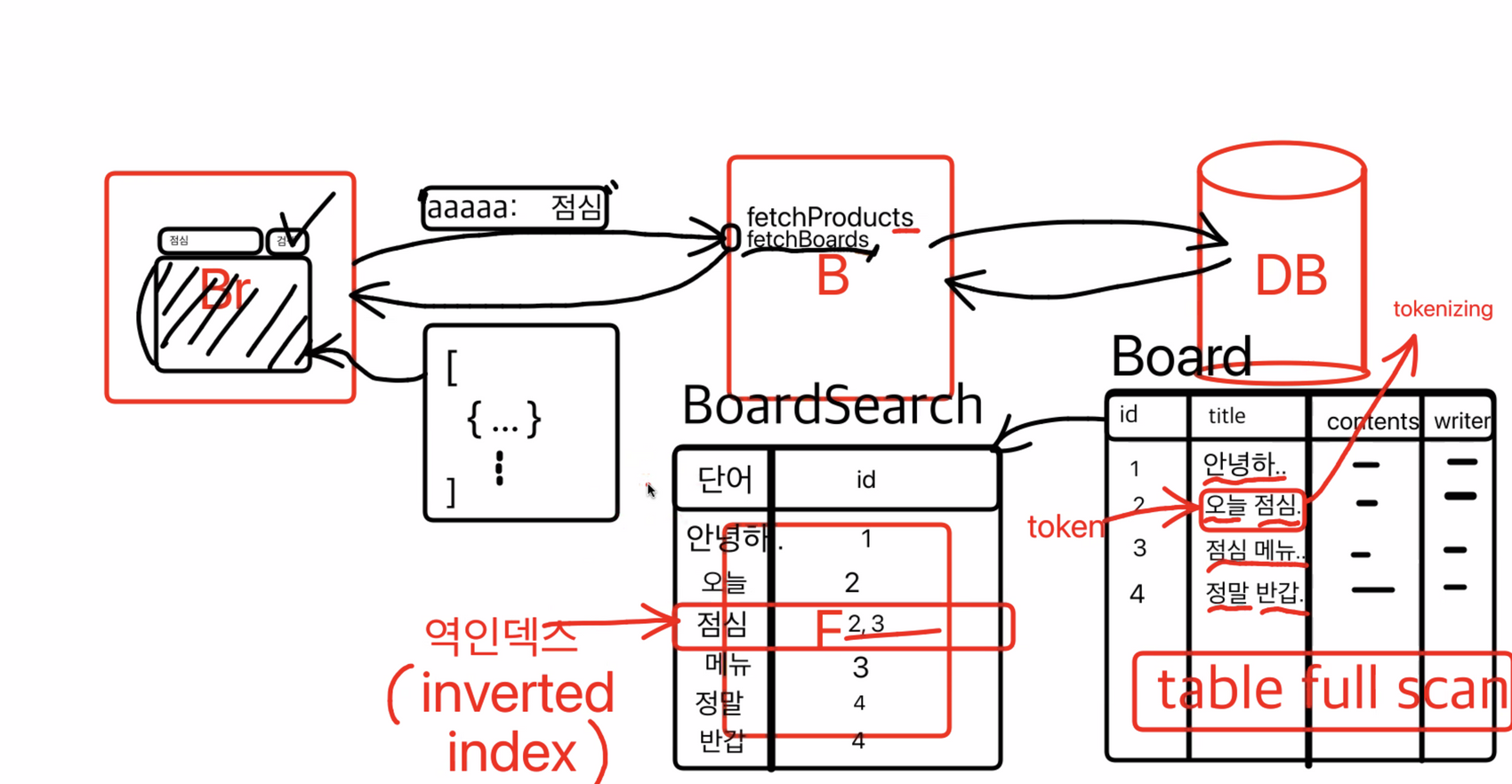
이 방식을 역인덱스(inverted index), 책의 뒷부분이랑 비슷한 구조
여기서 단어를 token 이라고 부르고, 단어 단위로 쪼개는 작업을 tokenizing 이라고 부른다
근데 매번 이렇게 테이블을 만들게 된다면 일이 더 늘어나는 것 → 이것을 위해 새로운 데이터 베이스가 나오는데 그것이 바로 Elastic Search 이다.
이 방식은 Disk에 저장되는 방식으로 컴퓨터가 꺼져도 저장이 유지됨. 분명 안전하지만 속도는 조금 떨어지게 된다.
느린 이유: 데이터를 저장하는 도구에는 메모리와 디스크가 있는데 디스크에 저장되기 때문
ELK 스택
반면, memory 에 저장되는 방식도 존재. 메모리저장기반 방식으로는 Redis
검색어와 검색결과를 저장해서 통째로 보내주는 것 (임시저장: 캐싱 , 영구저장x)
임시저장방식으로 Disk저장보다는 안정성이 떨어지지만 속도가 빠름
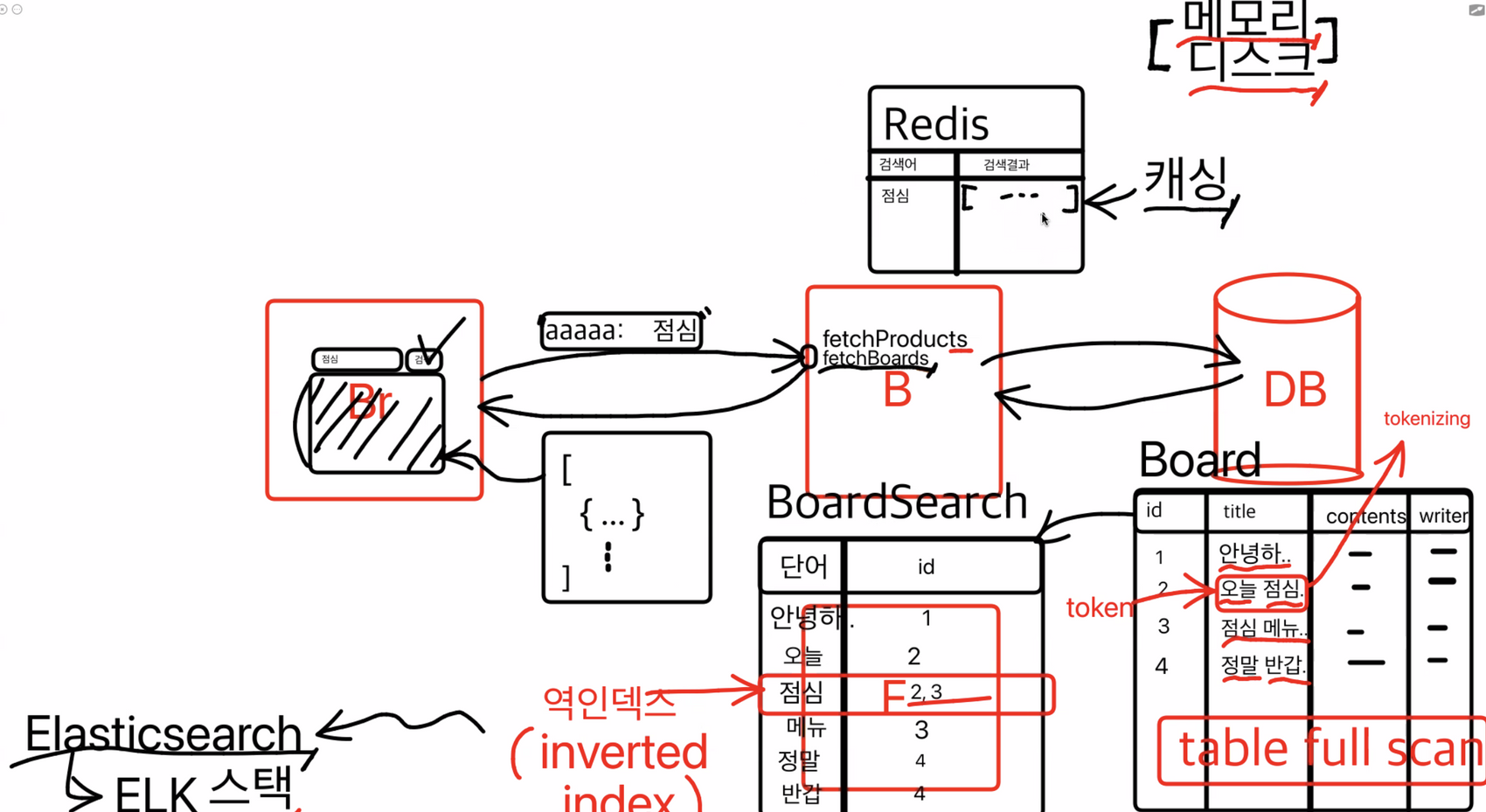
어떤 것들을 쓰나 ?? → 사람들이 많이 검색하는 것들을 캐싱해놓는 것이다.
서비스를 제공하고 시간이 흐르면, 사람들의 검색에 대한 어느정도 일정 패턴이 생기게 되는데, 그렇다면 사람들이 자주 검색하게 되는 것들은 검색마다 Disk에 가서 꺼내오는것보다는 Memory 기반 DB에 넣어두면 그때 그때 마다 더 빠르게 제공할 수 있기 때문. → 검색로그 캐싱
💡 즉, 검색이 진행될 때, 캐싱이 되어있다면
Redis, 캐싱되어 있지 않은 기록은Elastic Search방식이 사용되는 것
