
⭕️ Today I Learned
매일 할 일 ✅ ❌
✅ 1일 1커밋
❌ 1일 1알고리즘 문제 풀이
✅ 1일 2기술면접 개념 정리
✏️ 오늘 한 공부
알고리즘 문제풀이
백준
- 14502 연구소
기술 면접 대비 개념 공부
[ 기술 면접 대비 개념 정리 통합본 ]
- Annotation이란 무엇이고 구체적으로 어떤 것이 있는지 예시를 들어 설명해주실 수 있을까요?
자바 애너테이션(Java Annotation)은 자바 소스 코드에 추가하여 사용할 수 있는 메타데이터의 일종입니다. 보통 @ 기호를 앞에 붙여서 사용하고, JDK 1.5 버전 이상에서 사용 가능하다. 자바 애너테이션은 클래스 파일에 임베디드되어 컴파일러에 의해 생성된 후 자바 가상머신에 포함되어 작동합니다.
어노테이션도 종류가 존재합니다.
표준(내장) 어노테이션 : 자바가 기본적으로 제공해주는 어노테이션
- @Override - 오버라이딩할 때, 메서드의 이름을 잘못적는 실수를 방지해주는 어노테이션
- @Deprecated - 앞으로 사용하지 않을 것을 권장하는 필드나 메서드에 붙이는 어노테이션
- @SuppressWarnings- 컴파일러의 경고메세지가 나타나지 않게하는 어노테이션
메타 어노테이션 : 어노테이션을 위한 어노테이션
- @Taget - 어노테이션을 정의할 때, 적용대상을 지정하는데 사용
- @Retention - 어노테이션이 유지되는 기간을 지정할 때 사용
SOURCE : 소스 파일에만 존재.
RUNTIME : 클래스 파일에 존재. 실행시에 사용가능
사용자정의 어노테이션 : 사용자가 직접 정의하는 어노테이션
- Spring Security의 구조와 JWT 발급 과정에 대해 설명해주실 수 있을까요?
Spring Security는 기본적으로 여러개의 필터가 이어져 인증 및 인가를 처리하는 구조로 되어있습니다.
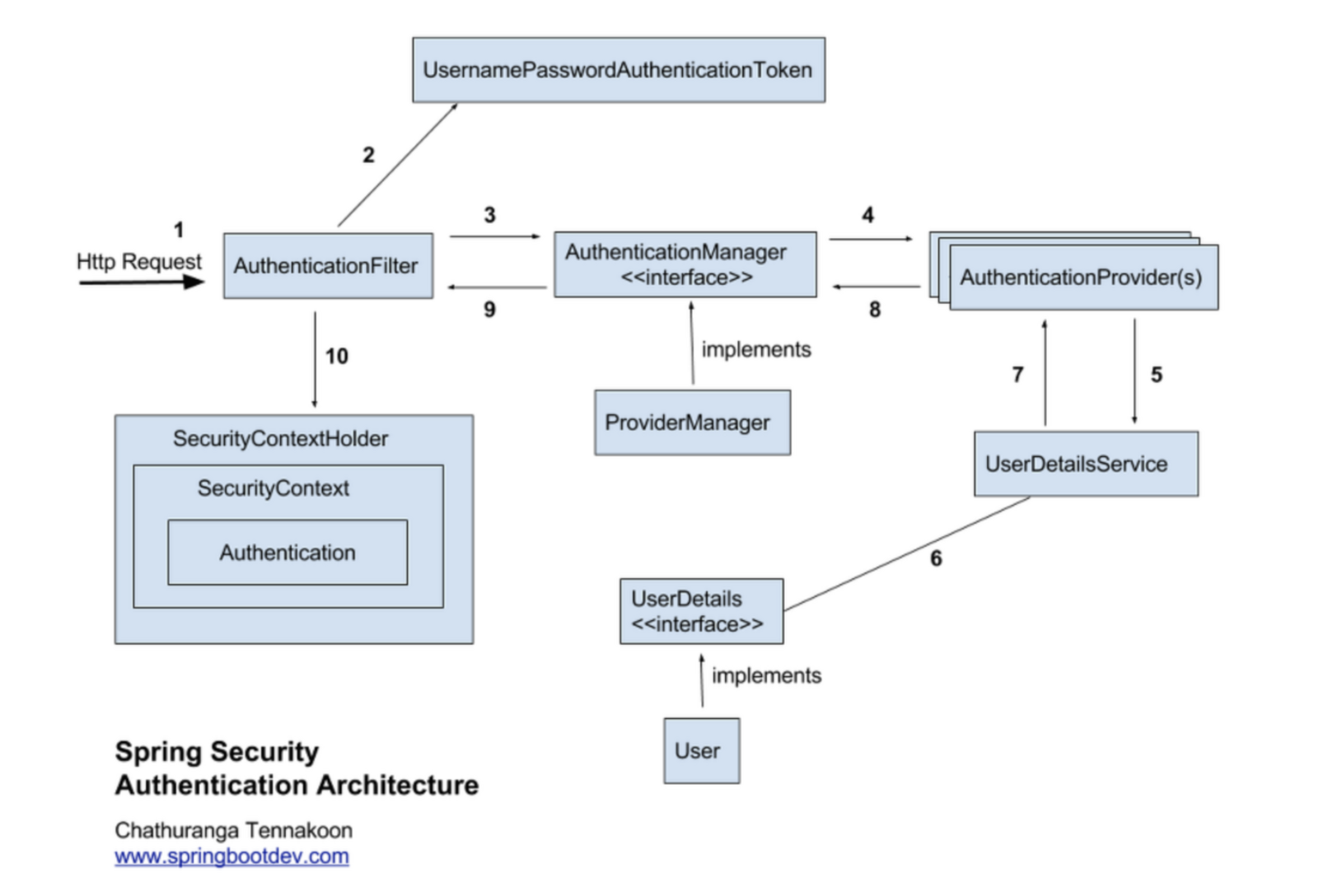
Spring Security의 인증 구조는 이런 형태로 이루어져 있습니다.
1. Http request (인증요청)
2. AuthenticationFilter를 거침(여기서는UsernamePasswordAuthenticationFilter).
HttpServletRequest를 인터셉트하여 AuthenticationManager에 Authentication 객체를 만들어 (UsernamePasswordAuthenticationToken) 전달
3. AuthenticationFilter로부터 인증객체 전달 받음.
4. 해당 인증 객체를 통해 인증을 진행하는 AuthenticationProvider를 찾아 인증 객체(UsernamePasswordAuthenticationToken)를 전달하고 인증을 요청
5. 6. 7 Provider에서 Service를 호출하여 UserDetails를 통해 인증을 진행( DB 데이터 조회 및 검증 )
8. 9. 10. 인증 성공시 사용자 데이터가 담긴 Authentication 객체를 SecurityContextHolder에 저장하고 AuthenticationSuccessHandle를 실행. (실패시 AuthenticationFailureHandler 실행)
JWT가 발급되는 과정은 아래와 같습니다.
처음 로그인을 시도하고 유저정보 인증에 성공하면, 서버에서 사용자가 인증토큰을 관리하도록 JWT를 쿠키나 헤더에 담아 반환해줍니다.
JWT를 발급해주는 서버는 JWT Secretkey를 가지고 있습니다. 해당 키를 가지고 있어야 JWT를 생성하고, 인증할 수 있게 됩니다.
- N+1 문제의 발생 이유와 해결 방법에 대해 설명해주실 수 있을까요? 해결 방법은 3가지 이상 말씀해주시면 좋습니다.
N+1 문제는 1개의 데이터를 조회했을 때, 그 개수만큼(N) 쿼리가 날아가 데이터를 조회해 오면서 발생하는 문제입니다. 보통 즉시로딩으로 일대다 관계의 데이터를 조회하거나, 지연로딩으로 조회한 데이터와 연관된 데이터를 사용할 때 추가적으로 조회해오면서 발생하게 됩니다.
해결방법으로는
1. Fetch Join 사용
JPQL (Java Persistence Query Language)로 쿼리를 작성할 때, JOIN FETCH를 사용하면 관련 엔터티를 함께 가져올 수 있습니다.
관련된 테이블 간의 조인을 사용해서 필요한 모든 데이터를 한 번의 질의로 가져올 수 있습니다.
이 방법을 사용하면 복잡한 질의가 필요할 수 있지만 질의의 수를 크게 줄일 수 있습니다.
-
@EntityGraph 어노테이션 사용
@EntityGraph 의 attributePaths에 쿼리 수행시 바로 가져올 필드명을 지정하면 Lazy가 아닌 Eager 조회로 가져오게 됩니다. Fetch join과 동일하게 JPQL을 사용하여 query 문을 작성하고 필요한 연관관계를 EntityGraph에 설정하면 됩니다.
-
BatchSize 설정
application.yml에서 Batchsize를 설정해주거나, @BatchSize 어노테이션을 이용하여 설정해주면, 연관된 엔티티를 조회할 때 지정된 size 만큼 SQL의 IN절을 사용해서 조회하게 됩니다.
- 즉시로딩과 지연로딩은 각각 언제 사용하면 좋은지 설명해주실 수 있을까요?
즉시로딩 (Eager Loading)
즉시로딩은 조회시 관련된 모든 데이터를 한 번에 로드하는 방식입니다. JPA에서는 일대일, 다대일관계일 경우 기본적으로 즉시로딩을 수행합니다. 주로 관련된 데이터가 항상 함께 사용되는 경우 유용합니다.
그러나 프로젝트의 규모가 커지면서 데이터들의 연관관계가 복잡해 질 경우 쿼리가 예상하지 못한 형태로 날아갈 수 있기에 주의해야 합니다.
지연로딩 (Lazy Loading)
-
지연로딩은 조회시 해당 객체와 연관된 데이터들을 프록시 객체로 가져와 임시로 담아두고, 해당 데이터를 호출할 경우 추가적으로 쿼리문을 DB에 날려 데이터를 가져오는 방식입니다.
-
많은 양의 데이터를 로드하지 않고 필요한 데이터만 로드하므로, 메모리 사용을 최적화할 수 있습니다.
-
일대다 또는 다대다 관계에서는 지연로딩이 기본적으로 사용됩니다.
-
지연로딩은 N+1 문제를 발생시킬 수 있기에 즉시로딩이 더 좋은 방법으로 보이지만, 지연로딩으로 데이터를 불러오고, 추가적으로 사용될 데이터는 fetch join을 사용해 함께 불러오는것이 더 나은 방법이라고 알고 있습니다.
- Spring bean container 생성부터 스프링 종료까지의 사이클에 대해 알려주실 수 있을까요? @PostConstruct, @PreDestroy 어노테이션의 역할도 함께 알려주시면 좋습니다.
스프링이 시작되어 스프링 컨테이너가 생성되면 크게 아래와 같은 흐름으로 흘러갑니다.
스프링 컨테이너 생성 -> 스프링 빈 생성 -> 의존관계 주입 -> 초기화 콜백 -> 사용(메소드 호출) -> 소멸전 콜백 -> 스프링 종료
- 스프링 IoC 컨테이너가 생성되고, @Component, @Bean을 통해 스프링 빈들을 생성합니다.
- 스프링 빈들의 의존관계에 맞게 의존관계를 주입해 줍니다.
- 이후 스프링 빈들마다 지정해두었던 초기화 코드가 실행됩니다.
- 스프링이 종료되기 전에 스프링 빈들은 소멸전 코드를 실행시키고 소멸하며 스프링이 종료됩니다.
@PostConstruct - 스프링 빈 생성 이후, 의존관계 주입 이후 호출할 초기화 코드를 지정할 수 있습니다.
@PreDestroy - 스프링 빈 소멸 직전에 호출할 코드들을 지정할 수 있습니다.
- 위의 콜백 방식은 스프링에서 가장 권장하는 방법입니다.
- 자바 표준 기술이어서 스프링이 아닌 다른 컨테이너에서도 동작합니다.
- 컴포넌트 스캔과 잘 어울립니다.
- 유일한 단점은 외부 라이브러리에는 적용하지 못합니다. 외부라이브러리의 경우 @Bean(initMethod ="", destory="")설정정보 기능을 사용해서 처리 가능합니다.
- AOP, Interceptor, Filter 의 차이점, Request가 들어올때 거치는 순서, 각 역할들의 장점을 설명해주실 수 있을까요?
실전 프로젝트 공부해야 할 것들
- Kafka
- ELB, Nginx - 로드밸런싱
- blue green 배포
실전 프로젝트
- 추가 기능 API 구현
- 주문 생성 API 재고감소 동시성 처리
⭐️ 하루 생각 정리 ⭐️
로드밸런싱, 메시지 큐 처리 해보자악
