참고
인프런 강의 [재고시스템으로 알아보는 동시성이슈 해결방법] 을 공부하고 내용을 복습하며 정리해보는 글 입니다.
동시성 문제란?
동시성 문제란 하나의 공유 데이터를 2개 이상의 쓰레드, 또는 세션에서 동시에 조작할 때 발생하는 문제입니다.
하나의 쓰레드가 데이터를 수정중일 때 아직 변경사항이 반영되지 않은 상태에서 다른 쓰레드가 변경 이전 데이터를 조회해서 변경시킬 수 있어 이러한 문제가 발생합니다.
동시성 문제가 발생할 수 있는 상황에 대해 알아보고 어떠한 방법으로 해결할 수 있을지 정리해 보려 합니다.
문제 상황 예시
Stock Entity
재고를 가지고있는 Stock Entity
@Entity
@Getter
public class Stock {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
public Stock() {
}
public Stock(Long productId, Long quantity) {
this.productId = productId;
this.quantity = quantity;
}
public void decrease(Long quantity) {
if (this.quantity - quantity < 0 ) {
throw new RuntimeException("재고는 0 미만이 될 수 없습니다.");
}
this.quantity -= quantity;
}
}StockService
재고를 감소시켜주는 서비스 로직
@Service
@RequiredArgsConstructor
public class StockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}
StockServiceTest
테스트 코드
@Test
public void 동시에_100개의_요청() throws InterruptedException {
int threadCount = 100;
//ExecutorService - 비동기를 단순하게 처리할 수 있도록 도와주는 java api
ExecutorService executorService = Executors.newFixedThreadPool(32);
//CountDownLatch - 다른 스레드에서 수행이 완료될 때 까지 대기할 수 있도록 도와주는 클래스
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L);
}
finally {
latch.countDown();
}
}
);
}
latch.await();
Stock stock = stockRepository.findById(1L).orElseThrow();
//100 - (1*100) = 0
assertThat(stock.getQuantity()).isEqualTo(0L);
}멀티 쓰레드로 decrease 메소드를 100번 호출하게 된다면 100 -(1*100) 으로 0개의 재고가 남을 것으로 예상되지만, 테스트를 돌려보면 실제로는 다른 값이 출력되는 것을 확인할 수 있습니다.
이러한 이유는 RaceCondition때문에 발생하게 되는데,
RaceCondition이란 하나의 공유 데이터를 여러개의 쓰레드가 동시에 접근할 때 발생하는 문제입니다. 하나의 데이터를 여러개의 쓰레드가 경쟁하며 점유하려고 하기에 Race라는 이름이 붙은 것 같다.
테스트 출력 결과

동시성 문제가 발생하는 과정
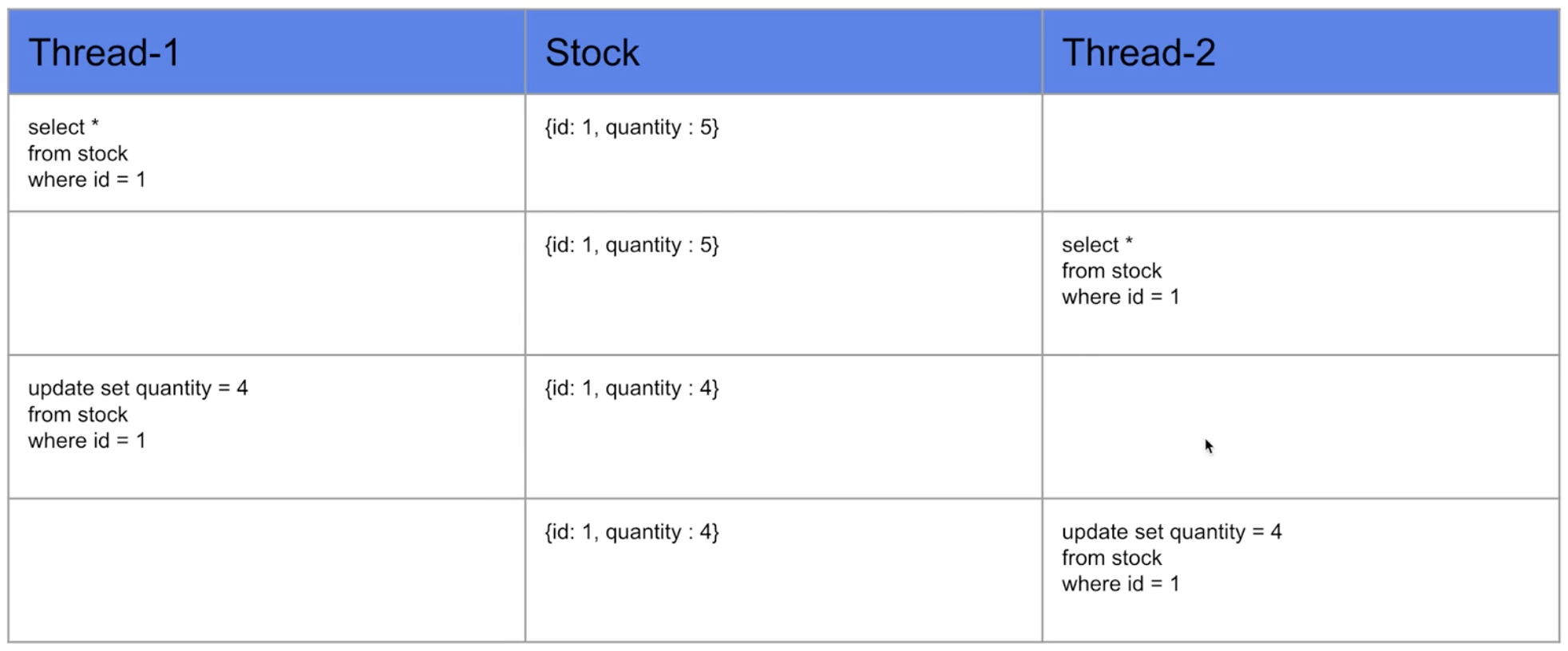
두개의 쓰레드가 하나의 값을 변경할 때 1번 쓰레드가 재고를 조회하고 재고를 감소시키는 과정중에 2번 쓰레드가 아직 감소가 반영되기 전 데이터를 똑같이 조회해서 감소시키기 때문에 결과적으로는 1번만 감소가 일어나는 것을 확인할 수 있습니다.
순수한 Java 코드로 해결 시도하기
🌱 synchronized
// synchronized 키워드를 통해 해당 메소드에는 하나의 쓰레드만 접근가능
@Transactional
public synchronized void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}synchronized 를 서비스 로직에 추가하여 메소드에 하나의 쓰레드만 접근가능하게 하여 테스트를 돌려보면 감소가 더 적용되기는 하지만 여전히 제대로 동작하지 않습니다.
테스트 출력 결과

synchronized 로 해결되지 않는 이유
한번에 하나의 쓰레드만 적용된다면 동시성 문제가 해결되어야 할 것 같지만 해결되지 않는 이유는 @Transactional 의 동작원리에 있습니다.
@Transactional 어노테이션이 붙어있으면 기본적으로 해당 서비스(StockService)에서 로직을 호출하지 않고, StockService를 필드 변수로 주입받은 다른 객체에서 StockService의 메소드를 호출해 작업을 수행하게 됩니다.
// 트랜잭션 생성
stockService.decrease();
// 트랜잭션 커밋
이 과정에서 해당 가짜 객체는 대략적으로 위와같은 방식으로 트랜잭션을 열고, 서비스로직을 수행하고, 해당 변경사항을 반영하는데 decrease()로직이 끝나고 트랜잭션 커밋을 하려는 그 사이에 다른 쓰레드가 decrease()를 호출하며 로직을 수행하기에 여전히 동시성 문제가 발생하게 됩니다.
@Transactional을 주석 처리 후 테스트를 돌려보면 테스트가 통과하는 것을 확인할 수 있습니다.
❗️ synchronized가 가지는 문제점
synchronized는 하나의 프로세스에서만 보장됩니다.
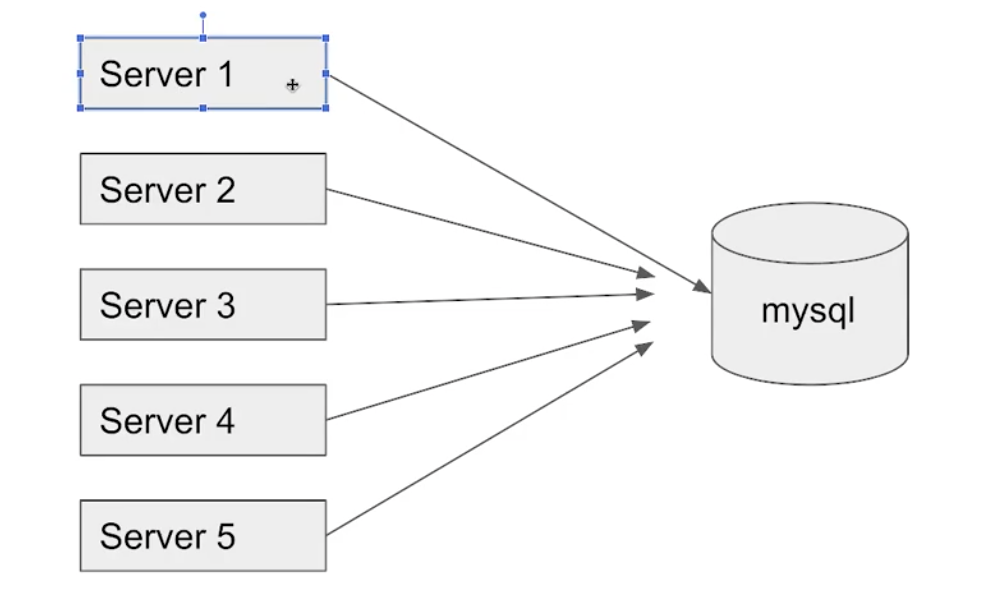
서버가 하나일 경우 괜찮지만 보통은 여러개의 서버를 운영하게 되고, 작업중인 데이터를 다른 서버에서 접근하게 된다면 똑같은 문제가 발생할 것입니다.
MySQL을 활용한 세가지 방법
1. Pessimistic Lock

-
실제 데이터에 접근할 때 락을 걸어 여러개의 쓰레드가 동시에 접근할 수 없도록 하는 방법입니다.
-
데이터에 접근할 때 exclusive lock을 걸게되면 락을 풀기 전까지 다른 요청으로는 해당 데이터에 접근할 수 없습니다.
-
예를들어 Server 1에서 데이터에 처음 접근해 락을 걸게된다면 다른 서버에서는 해당 데이터에 접근하지 못하고 Server1의 작업이 끝나고 락이 풀리면 접근할 수 있게 됩니다.
마치 한 사람이 방에 들어가서 문을 잠그고, 일을 끝내면 잠금을 풀고 나와 다른사람이 들어갈 수 있는 구조라고 생각하면 됩니다.
Pessimistic Lock 사용해보기
Spring Data JPA 에서는 Pessimistic Lock을 사용할 수 있도록 기능을 제공해 주고 있습니다.
아래와 같이 데이터 접근시 락을 걸도록 쿼리를 작성할 수 있습니다.
public interface StockRepository extends JpaRepository<Stock,Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE) // Pessimistic Lock
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithPessimisticLock(Long id);
}Pessimistic Lock의 장점
- 충돌이 빈번하게 일어난다면 롤백의 횟수를 줄일 수 있기 때문에, 버전을 비교하여 정합성을 보장하는 Optimistic Lock 보다는 성능이 좋을 수 있습니다.
Pessimistic Lock의 단점
- 데이터에 직접 락을 걸기 때문에 성능이 떨어질 수 있습니다.
- 데이터를 많이 읽어야 하는 작업일 수록 성능이 더욱 떨어지게 됩니다.
- 데드락에 걸릴 수 있습니다.
데드락
두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태
1번 로직은 1번락을 획득하고 이후에 2번락을 획득해야한다고 가정,
2번 로직은 2번락을 획득하고 이후에 1번락을 획득해야한다고 가정하면. 두개의 로직이 동시에 돌 경우1번 로직 - 1번 락 획득 ------> 2번 락 대기
2번 로직 - 2번 락 획득 ------> 1번 락 대기이렇게 서로 로직을 수행하지 못하고 평생 대기해야하는 것을 데드락이라고 합니다.
2. Optimisitc Lock

- 락을 걸지 않고 버전을 이용함으로써 정합성을 확보하는 방법입니다.
- 데이터를 우선 읽고 update를 수행할 때 현재 내가 읽은 버전과 동일한지 확인한 이후에 업데이트를 실행합니다.
- 내가 읽은 버전에서 수정사항이 생긴다면 수정 작업에 대한 롤백을 수행합니다.
- 롤백이 일어났을 경우 해당 수정사항을 다시 수행할 수 있도록 추가적인 조치를 해줘야 합니다.
Optimisitc Lock 사용해보기
- Stock Entity에 체크할 버전 필드를 추가해 줍니다.
@Entity
@Getter
@NoArgsConstructor
public class Stock {
...
//버전 필드 추가
@Version //javax.persistence.Version
private Long version;
...
}
- Optimisitc Lock또한 Spring Data JPA 에서 기능을 제공해 줍니다.
public interface StockRepository extends JpaRepository<Stock, Long> {
@Lock(LockModeType.OPTIMISTIC) //Optimisitc Lock
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithOptimisticLock(Long id);
}
Optimisitc Lock의 장점
- 충돌이 적게 일어난다는 가정 하에, 별도의 락을 잡지 않기 때문에 Pessimistic Lock 보다는 성능적 이점을 가집니다.
Optimisitc Lock의 단점
- 업데이트가 실패했을 떄, 재시도 로직을 개발자가 직접 작성해 주어야 합니다.
- 충돌이 빈번하게 일어난다면, 롤백 후 다시 조회해서 업데이트를 해야하기 때문에 Pessimistic Lock이 더 성능이 좋을 수 있습니다.
3. Named Lock

- Named Lock은 이름을 가진 metadata Lock 입니다.
- 이름을 가진 락을 획득한 후, 해지될때 까지 다른 세션은 이 락을 획득할 수 없게 됩니다.
- Named Lock은 데이터 자체에 락을 걸지 않고 별도의 공간에 락을 걸게 됩니다.
- 주의할 점은, 트랜잭션이 종료될 떄 락이 자동으로 해지되지 않기 떄문에, 별도로 해지해주거나 선점시간이 끝나야 해지됩니다.
- Mysql 에서는 getLock( ) 을 통해 락을 획득할 수 있고, releaseLock() 으로 락을 해지 할 수 있습니다.
❗️ Named Lock 사용시 주의사항
커넥션 풀이 부족해질 수 있기에, 실제 서비스에서는 DataSource를 분리하여 사용하는것이 좋다고 합니다.
Named Lock 사용해보기
- 편의성을 위해 Stock 엔티티를 사용하지만, 실무에서는 별도의 JDBC를 사용해야 한다고 합니다.
public interface LockRepository extends JpaRepository<Stock, Long> {
@Query(value = "select get_lock(:key, 3000)", nativeQuery = true)
void getLock(String key);
@Query(value = "select release_lock(:key, key)", nativeQuery = true)
void releaseLock(String key);
}- StockService는 부모의 트랜잭션과 별도로 실행되어야 하기 때문에 propergation을 별도로 생성해줍니다.
- 부모의 트랜잭션과 동일한 범위로 묶인다면 synchronized와 동일하게 DB에 수정된 데이터가 반영되기 전에 락이 풀려버릴 수 있습니다.
@Component
@RequiredArgsConstructor
public class NamedLockFacade {
private final LockRepository lockRepository;
private final StockService stockService;
//부모의 트랜잭션과 별도로 실행
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void decrease(Long id, Long quantity) {
try {
lockRepository.getLock(id.toString());
stockService.decrease(id, quantity);
}finally {
lockRepository.releaseLock(id.toString());
}
}
}Named Lock의 장점
- Named Lock은 주로 분산락을 구현할 때 사용합니다.
- Pessimistic Lock과 다르게 Named Lock은 timeout을 비교적 쉽게 구현 가능하다고 합니다.
Named Lock의 단점
- Named Lock은 트랜잭션 종료시에, 락 해제와 세션 관리를 잘 해줘야 합니다.
- 실무에서 사용할 때는 구현방법이 복잡할 수 있습니다.
Redis 사용하기
-
Redis 를 사용하여 동시성 문제를 해결하는 방법은 2가지가 존재합니다.
-
- Lettuce
-
- Redisson
Redis 의존성 추가
//Redis 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-data-redis'1. Lettuce 사용하기
-
setnx 명령어를 사용하여 분산락을 구현합니다.
- setnx는 해당 키가 존재하지 않는다면 생성하고 이미 존재한다면 생성하지 않는 명령어 입니다.
ex) setnx key value
- setnx는 해당 키가 존재하지 않는다면 생성하고 이미 존재한다면 생성하지 않는 명령어 입니다.
-
Spin Lock 방식으로 이루어지며, Lock획득 실패 시 재시도 로직을 개발자가 작성해 주어야 합니다.
-
Lettuce는 MySQL의 NamedLock과 유사하지만, Redis를 사용하기에 성능상의 이점이 있고, 세션관리에 신경쓰지 않아도 됩니다.

Redis로 SpinLock 구현하기
@Component
@RequiredArgsConstructor
public class RedisLockRepository {
private final RedisTemplate<String, String> redisTemplate;
public Boolean lock(final Long key) {
return redisTemplate
.opsForValue()
//setnx 명령어 사용 - key(key) value("lock"), 3초동안 락 설정
.setIfAbsent(generateKey(key), "lock", Duration.ofMillis(3_000));
}
public Boolean unlock(final Long key) {
return redisTemplate.delete(generateKey(key));
}
private String generateKey(final Long key) {
return key.toString();
}
}재시도 로직 작성하기
@Component
@RequiredArgsConstructor
public class LettuceLockStockFacade {
private final RedisLockRepository redisLockRepository;
private final StockService stockService;
public void decrease(final Long key, final Long quantity) throws InterruptedException {
// Lock 획득 시도
while (!redisLockRepository.lock(key)) {
//SpinLock 방식이 redis 에게 주는 부하를 줄여주기위한 sleep
Thread.sleep(100);
}
//lock 획득 성공시
try{
stockService.decrease(key,quantity);
}finally {
//락 해제
redisLockRepository.unlock(key);
}
}
}- whille문을 돌며 lock획득을 실패하게 되어 false를 반환받으면 100ms의 sleep이후 다시 lock 획득 시도를 반복합니다.
- lock을 획득하면 재고를 1 감소시키고 락을 해제하게 됩니다.
Spin Lock 방식은 Lock을 얻을 때 까지 계속 Redis에 요청하기 때문에 Redis에 부하를 줄 수 있다는 단점이 존재합니다.
2. Redisson 사용하기
- Redisson은 Pub-sub 기반으로 Lock을 구현합니다.
- Pub-sub 방식이란, 하나의 채널에서 락을 소유한 쓰레드가 작업을 종료하면 대기중인 쓰레드에게 락이 해제되었음을 알려주고, 대기중인 쓰레드가 락을 점유하는 방식입니다.
- Redisson을 사용하면 별도의 Retry 로직을 작성하지 않아도 됩니다.
Redisson 의존성 추가
//Redisson 의존성 추가
implementation 'org.redisson:redisson-spring-boot-starter:3.23.5'Redisson으로 Lock 구현하기
@Component
public class RedissonLockStockFacade {
private RedissonClient redissonClient;
private StockService stockService;
public RedissonLockStockFacade(RedissonClient redissonClient, StockService stockService) {
this.redissonClient = redissonClient;
this.stockService = stockService;
}
public void decrease(Long id, Long quantity) {
RLock lock = redissonClient.getLock(id.toString());
try {
//10초동안 락을 얻기위해 대기
boolean available = lock.tryLock(10, 1, TimeUnit.SECONDS);
//락 획득에 실패하면 감소하지않고 종료
if (!available) {
System.out.println("lock 획득 실패");
return;
}
//락 획득에 성공하면 재고 감소 로직 실행
stockService.decrease(id, quantity);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//감소 로직이 끝나면 락 해제
lock.unlock();
}
}
}
tryLock()메소드 내부에서 지정한 시간동안 락이 해제되었다고 pub 되기를 기다리는 것으로 이해 했습니다.
Lettuce vs Redisson
Lettuce
- 구현이 간단하다
- spring data redis의 기본이 lettuce이기 때문에 별도의 라이브러리를 사용하지 않아도 됩니다.
- 락 획득 실패시 재시도 로직을 작성해주어야 합니다.
- spinlock 방식이기 때문에 많은 쓰레드가 lock획득을 재시도하고 있다면 redis에 부하가 갈 수 있습니다.
Redisson
- 락 획득 재시도가 기본으로 제공됩니다.
- pub-sub 방식으로 구현되어 있기 때문에 lettuce와 비교했을 때 redis에 부하가 덜 갑니다.
- 별도의 라이브러리를 사용해야 합니다.
- lock을 라이브러리에서 처리하기 때문에 라이브러리 사용법을 공부해야 합니다.
실무에서는?
- 재시도가 필요없는 lock은 Lettuce 사용
- 선착순으로 1명만 물품을 구매할 수 있는 경우
ex) A가 물품을 구매하면 B는 구매할 수 없다.- 재시도가 필요한 경우에는 Redisson 사용
- 일반적으로 물품을 구매할 경우
ex) A가 물품을 구매중이더라도 B도 이후에 구매해야한다.
동시성 문제란 결국 여러개의 요청이 들어오면 순차적으로 받아 처리해야한다.
