
ElasticSearch? OpenSearch ? 뭐가뭐임?
AWS 에 원래는 ElasticSearch 라는 서비스가 있었는데 OpenSearch로 변경이 되었다. 비하인드 스토리는 좀 있는데..간단히 핵심만 말하자면
ElasticSearch 를 오픈소스로 만들었는데 AWS 측에서 그 오픈소스를 기반으로 OpenSearch를 만들었다고 한다.
물론 억울한 ElasticSearch 측에서 항의하고, AWS측은 오픈소스로 만드는게 무슨 잘못이냐.. ElasticSearch 측에선 하지만 사람된 도리로써 그게 맞냐.. 간단히 이런 비하인드가 있는 것 같다.
결국엔 ElasticSearch 측에서도 오픈소스를 포기하고 유료화를 진행하고 있고, AWS에서도 상업적으로 ElasticSearch를 이용할 수 없기에 마지막 버전을 기반으로 OpenSearch로 이름을 사용하게 되었다고 한다.
비슷한 사례로 mongo DB 도 비슷한 케이스로 AWS documentDB 로 서비스를 하고 있는 것 같다. DynamoDB도 mongo DB의 특정 버전 이후로 서비스가 런칭되었다고 한다.
물론 표면적으로 문제가 있는 건 아니지만 이게 맞나 싶긴 하다.
ElasticSearch? OpenSearch ? 뭐가다른데 ?
크게 다른 부분만 간단하게만 기록해보자.
유연성
- ES 는 멀티 클라우드 플랫폼을 지원하기 때문에 각종 클라우드 사이트에서 사용할 수 있지만 OS 는 AWS에 종속됨.(나쁜건 아님)
머신러닝 및 인공지능
- ES 는 기본탑재(좀 무거움), OS 는 플러그인
벡터 검색
- ES 기본탑재(이것때문에도 좀 무거움) , OS 플러그인
특정 기능 검색
- ES 웹크롤러나 내부검색 솔루션같은 검색을 위해 미리 빌드된 도구와 UI가 있음, OS 는 없음
대충 보자면 ES는 여러가지 기능이 포함된 통합 솔루션이고, OS는 통합된 솔루션이 아니라 검색기능만 제공하는 서비스이다. 라고 말하고 있는 것 같다.
내 프로젝트에서는 간단하게 검색기능이 필요하고, ES는 예전 프로젝트에서 한번 경험해봤으니, 이번엔 OS가 조금 더 맞지 않나 싶다.
AWS CloudSearch vs OpenSearch
CloudSearch
-
관리가 쉬움 (aws에서 관리해줌, 수평, 수직확장이 편함)
-
버전이 너무 낮음
-
빠르게 도입가능, 비용은 조금 더 비쌀 수 있음.
OpenSearch
-
CloudSearch 에 비해 관리가 어려움
-
ES 에서 만든 이후에 따로 발전된거라서 안정성이 ES에 비해 좋지 않을 수 있음
둘 다 사용해보도록 하자..
CloudSearch 맛이나 보자
설정은 그냥 default로 가자..
지금은 테스트로 로컬에 있는 파일(서울시 데이터)을 넣어야겠다. 메뉴에 보면 S3랑 DynamoDB도 전부 가능한데 난 아직 만들지 않아서 불가능하다.
뭐 대충 이런 형태를 띄고 있는 데이터임..
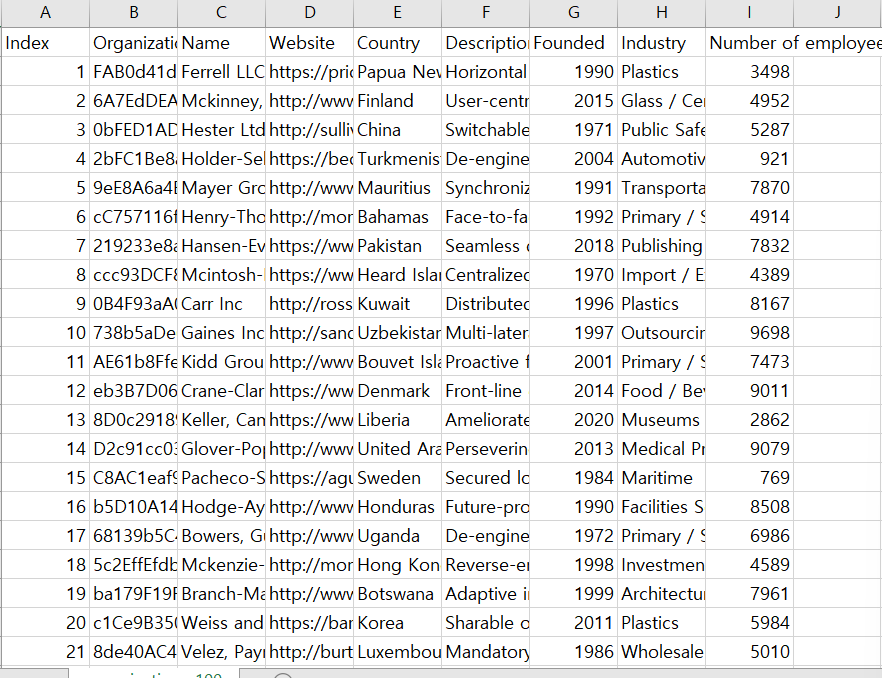
내 데이터의 성격에 맞게 field 들을 셋팅해주자..
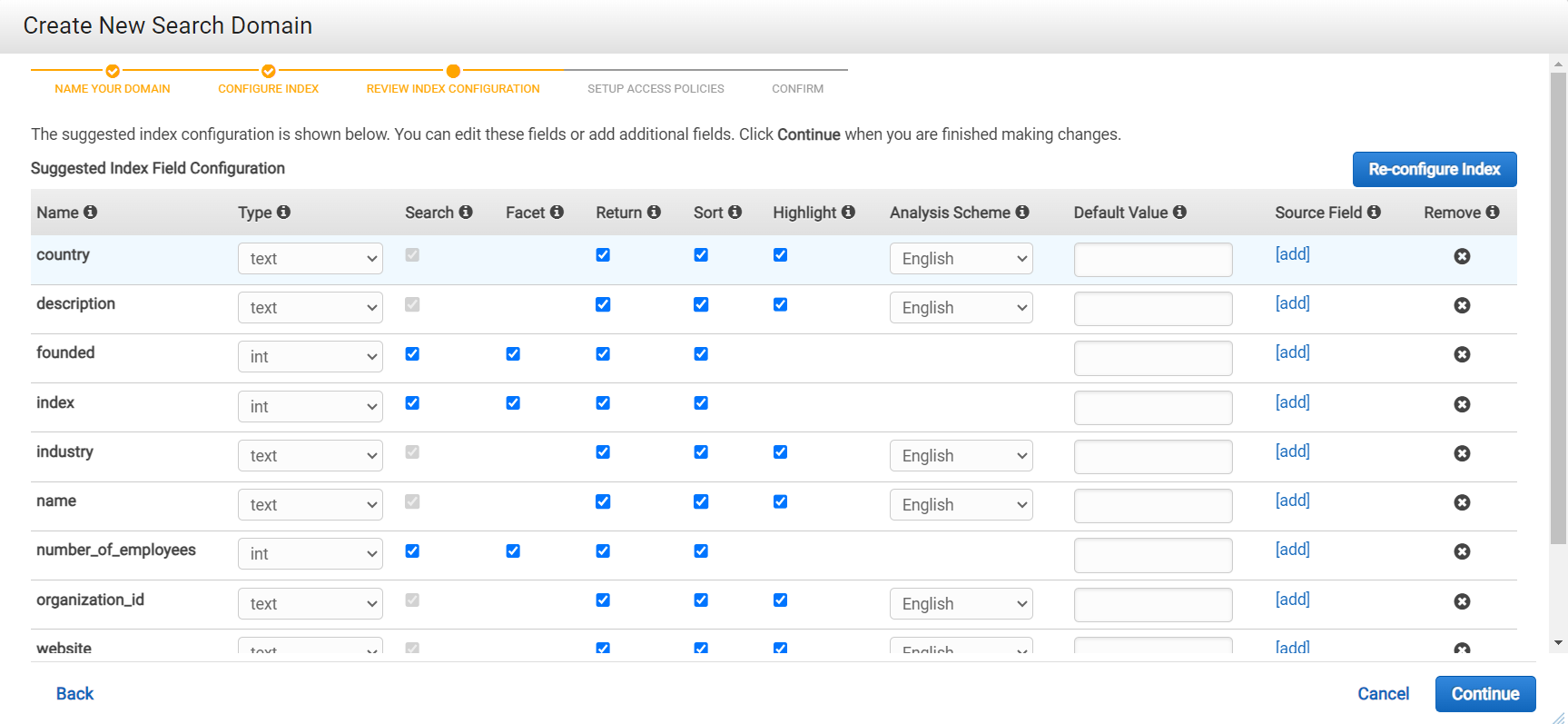
ip block 과 rule 을 추가 하는건데 현재는 테스트니까 넘어가자
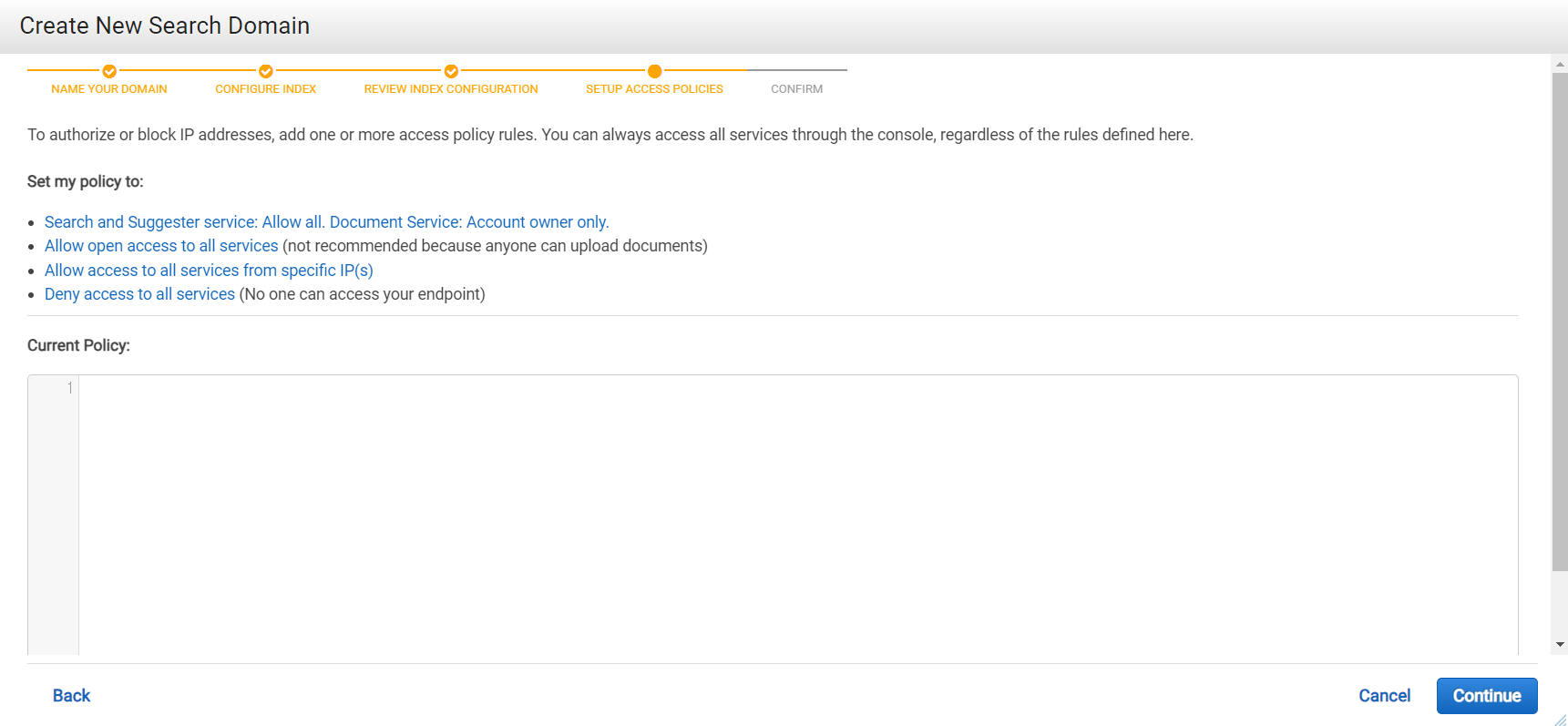
내 대쉬보드가 로딩중임..
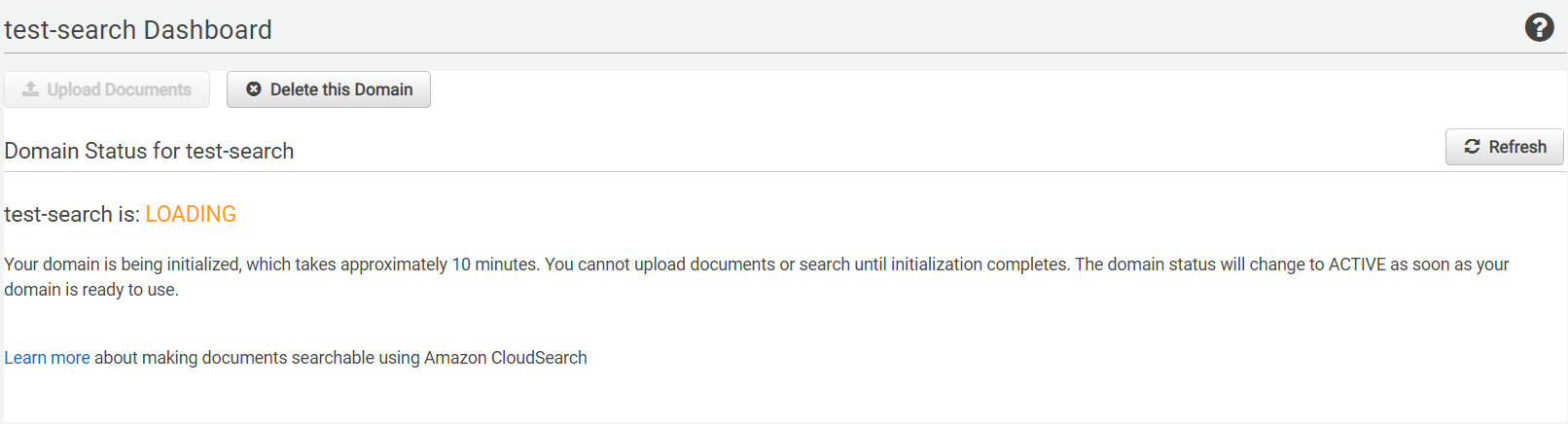
내 대쉬보드가 만들어졌음.. 한 10분 걸린듯?
DashBoard 검색
대충 대쉬보드에서도 검색이 가능하다. Elasticsearch 때 했던 것 처럼 Clouesearch도 역색인 방식을 사용하여 서치를 하는 것 같다.
아래에 Sort by 도 있는걸보아 여러가지 옵션으로 검색이 가능한 것 같다.
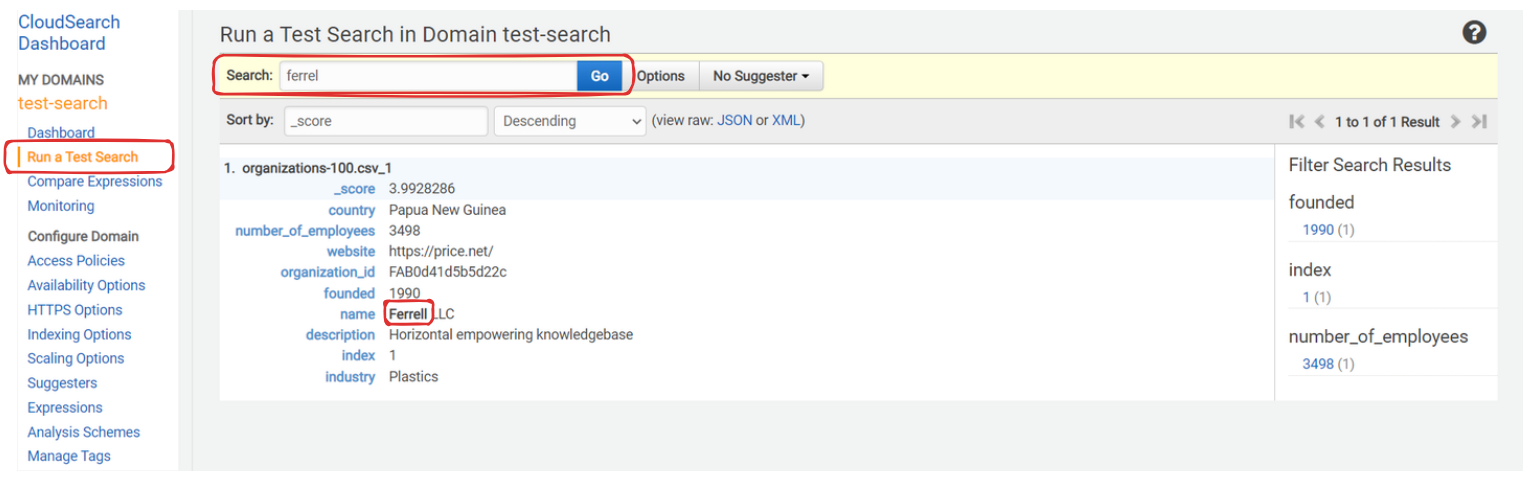
REST API
REST API 로도 검색해보자.
바로 자신감 있게 요청 날렸지만 권한이 없단다.. 설정하고 다시해보자.
https://search-test-search-ki3eft7hxazft3lqlruqaclgmi.ap-northeast-2.cloudsearch.amazonaws.com/2013-01-01/search?q=Ferrell&return=_all_fields{
"__type": "#AccessDenied",
"error":{
"message": "[*Deprecated*: Use the outer message field] User: anonymous is not authorized to perform: cloudsearch:search on resource: test-search"
},
"message": "User: anonymous is not authorized to perform: cloudsearch:search on resource: test-search"
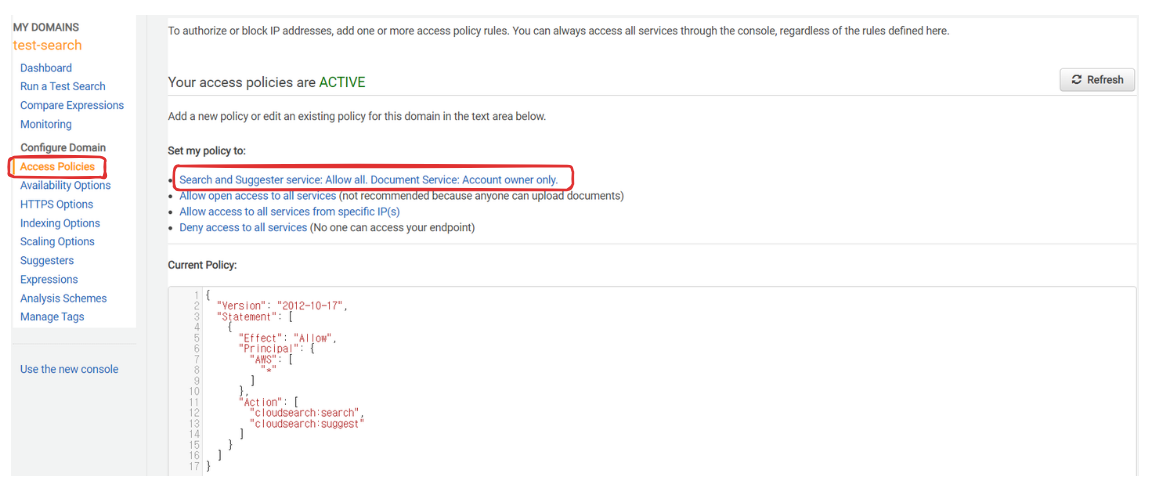
}일단 검색 권한만 풀어줘보자..
Https 옵션도 on으로 주고..
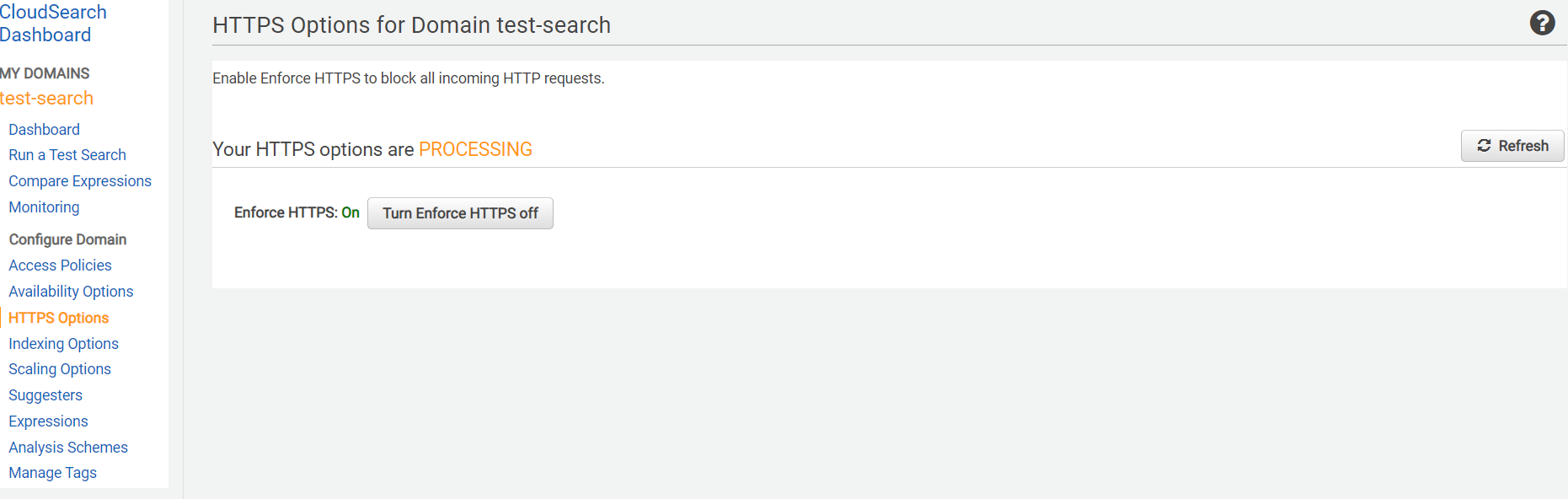
설정이 완료 되고 데이터를 가져오는 모습 (Active 되는데 또 한 10분걸림)
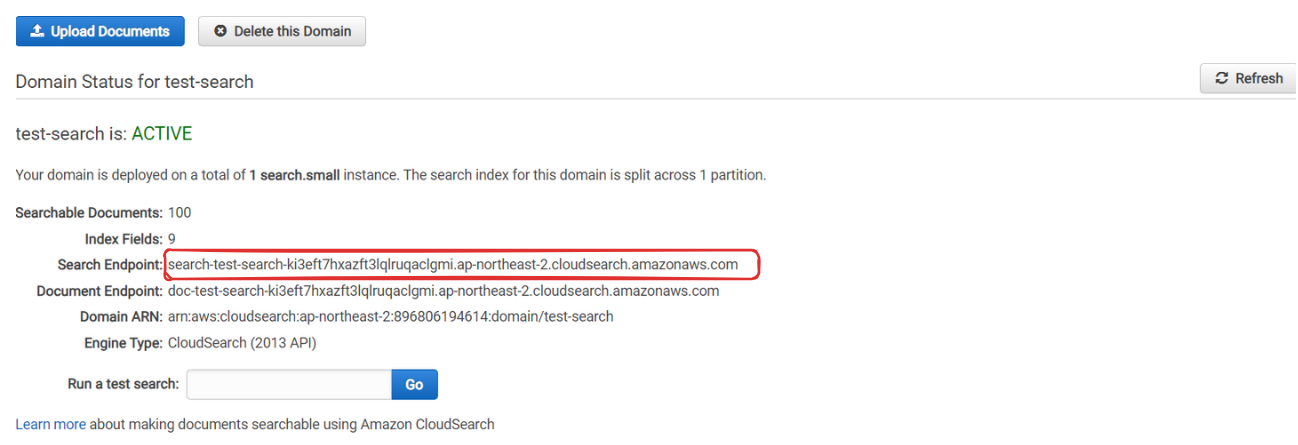
그리고 방금은 Search Endpoint 쪽에 데이터를 쐇는데 그 밑에 Document Endpoint가 있다. 이 쪽은 post 주소임.
front 나 server 둘 다 처리가 가능함. 기존 DB에 넣고 콜백에서 search 쪽으로도 쏴주면 되긴함. 근데 front에서 하기엔 조금 일이 많아질 것 같음. server 에서 처리하는게 좋을 듯.
server 에서도 redis 같은 툴 활용해서, DB적재 잘 되었으면 같이 search 날려주는식으로 하면 될 듯, 근데 server 단에서도 요청이 밀려서 조금 빡세다 싶으면..
람다같은 서버리스 시스템 에서 오토 스케일링이 가능하니까 이벤트로 빼줘도 될 듯.
또는 redis pub/sub 이나 kafka로 처리해도 좋을 듯 함.
아 그리고 삭제는 바로 옆 버튼에 아주 쉽게 노출되어 있음. 난 바로 삭제함.

결론
Opensearch 를 사용해보기 전에 간단하게 사용 가능한 Cloudsearch를 사용해봤는데, Opensearch 보다 비용이 더 비싸다고는 하나, 클릭 몇번으로 바로 구축할 수 있고, REST API도 지원해주고, 단 기간에 빠르게 검색엔진 하나를 적용하기엔 굉장히 효율적이고 좋은 것 같다.
근데 서비스가 조금 옛날 서비스의 느낌이 나긴 하고. 로딩속도가 너무 느림. 아무튼 순식간에 구축하기엔 정말 좋고, aws 내의 dynamoDB 혹은 S3와도 연동이 잘 되는 것 같아서 편한 것 같음.
