
# Elastic Search 설치
간단히 보고 넘어가는 Elastic Search 활용 사례
-
고객이 판매하는 제품을 검색 할 수 있는 온라인 웹스토어 운영
- Elastic Search 를 사용하여 전체 제품 카탈로그 및 인벤토리를 저장하고 검색 및 자동완성 제안을 제공한다.
-
로드 또는 트랜잭션 데이터를 수집, 분석 및 조사하여 추세, 통계, 요약 또는 예외를 탐지
-
이 경우 Logstash 를 사용하여 데이터를 수집, 집계 및 구문 분석 한 다음 Logstash에 이 데이터를 Elastic Search에 제공
-
데이터가 Elastic Search 에 저장되면 검색 및 집계를 실행하여 관심 있는 정보를 검색
-
-
가격에 정통한 고객이 "특정 전자 장치를 구입하는데 관심이 있고 다음달 모든 공급 업체 가가젯 가격이 얼마 이하로 떨어지면 알림을 받고싶다" 등과 같은 규칙을 지정할 수 있는 가격 알림 플랫폼 운영
-
이 경우 공급업체 가격을 싹 긁어내서 Elastic Search 로 밀어 넣은 뒤
-
역방향 검색 기능을 사용하여 가격 변동을 고객 쿼리와 비교하고 일치항목을 발견
-
마지막으로 고객에게 알리미 전송
-
-
분석 / 비즈니스 인텔리전스 요구사항이 있으며 많은 데이터에 대해 신속하게 조사, 분석, 시각화 및 임시 질문을 하고싶을때 (수억 또는 수십억건의 레코드)
- Elastic Search 를 활용해 데이터를 저장하고 사용하여 중요한 데이터를 시각화 할 수 있는 사용자 정의 대시보드를 작성 (Logstash, Kibana)
이전 포스팅에서 Elastic Stack 에 대한 이야기를 모두 나눴기 때문에 이번 게시글에서는 먼저 Elastic Search 를 설치하고 실행 해 보도록 하겠다.
실습 환경 (elk 7.2.0)
https://www.elastic.co/kr/downloads/past-releases/elasticsearch-7-2-0
https://www.elastic.co/kr/downloads/past-releases/logstash-7-2-0
https://www.elastic.co/kr/downloads/past-releases/kibana-7-2-0
https://www.elastic.co/kr/downloads/past-releases/filebeat-7-2-0
# Elastic Search CRUD
클러스터 탐색
REST API
-
노드와 통신하는 방법
-
Elastic Search 는 클러스터와 상호 작용하는데 사용 할 수 있는 매우 포괄적이고 강력한 REST API 를 제공
-
API 로 수행할 수 있는 몇가지 작업
-
클러스터, 노드 및 색인 상태, 상태 및 통계 확인
-
클러스터, 노드 및 색인 데이터 및 메타 데이터 관리
-
CRUD 및 인덱스에 대한 검색 작업 수행
-
페이징, 정렬, 필터링, 스크립팅, 집계 및 기타 여러 고급 검색 작업 실행
-
클러스터 상태
-
클러스터가 어떻게 진행되고 있는지 기본 적인 확인
-
HTTP/REST 호출을 수행 할 수 있는 모든 도구를 사용 가능
-
클러스터 상태를 확인하기 위해 _cat API 를 사용
-
녹색 -> 모든것이 좋음 (클러스터 완전작동)
-
노란색 -> 모든 데이터를 사용할 수 있지만 일부 복제본은 아직 할당되지 않음 (클러스터 완전 작동)
-
빨간색 -> 어떤 이유로든 일부 데이터를 사용 할 수 없음 (클러스터가 부분적으로 작동)
데이터베이스가 가진 데이터 확인하기
-
갖고 있는 모든 인덱스 항목 조회
-
index는 일단 RDB 에서의 데이터베이스 역할
-
GET/_cat/indices?v -> db를 모두 확인하기
-
_cat/nodes?v -> node 정보확인 (자원 및 리소스 등)

- _cat/health?v

엘라스틱 서치의 질의방법
-
curl
-
postman
-
Kibana 에서 devTool

데이터 입력/조회/삭제/업데이트 요약
-
입력(PUT, POST)
- http://localhost:9200(es주소)/index1(db-index)/type1(table-type)/1(document) -d(msg) '{"num" : 1, "name" : "lee"}'
-
조회(GET)
-
삭제(DELETE)
-
업데이트(POST)
- http://localhost:9200(es주소)/index1(db-index)/type1(table-type)/1(document)/_update -d '{doc : {"age" : 99}}'
인덱스 만들기
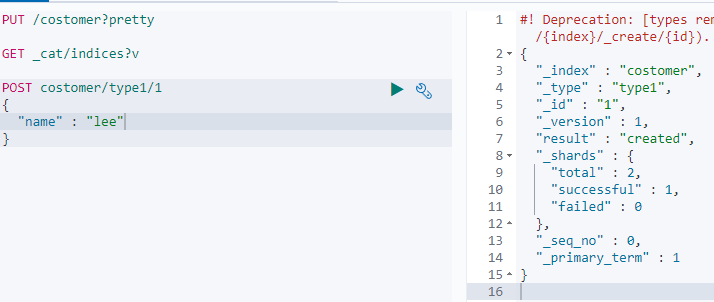
- costomer 라는 index를 만들었고 pretty 옵션을 주었다. 오른쪽 응답화면은 원래 JSON형식이 지저분하게 나오지만 pretty 옵션을 주면 정돈되서 나옴. 하지만 이건 Kibana 여서 정리되서 나온거임. pretty 빼도 똑같음

- index 정보를 모두 불러와보았다. Kibana의 기본정보 index와 방금 추가한 내 index가 나왔다. status는 yellow 로 확인된다.

-
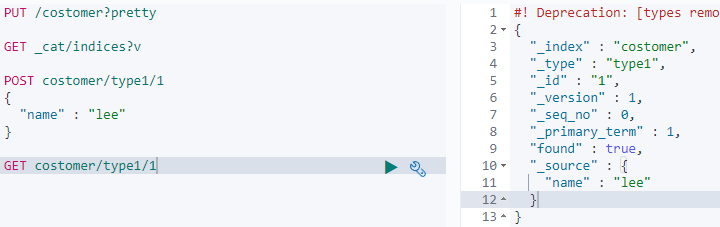
인덱스에 타입과 doc 를 추가 해보았다. doc 번호를 안적으면 랜덤으로 생성된다고 한다.
-
_version 은 수정할 시 올라감'
-
필드 매핑이 필요하지 않을 시 굳이 index 만들고 type 만들고 할 필요없이 바로 데이터 넣을 수 있음.
-
- 방금 추가한걸 조회 해보자. 보통 _source 에 data 가 들어있음.
-
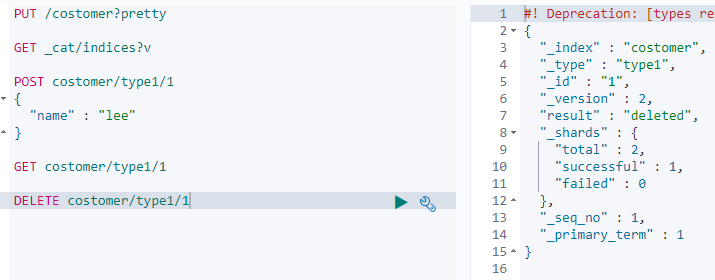
삭제도 진행해보도록 하겠다.
- Result 를 보니 정상적으로 삭제 되었고 업데이트가 되어서 _version 이 2로 올라갔다. 삭제되었다 해도 이 doc 번호로 추가 했을 시 version이 올라감. 완전 초기화 하고 싶다면 index를 삭제 하고 다시 해야함.
- 업데이트
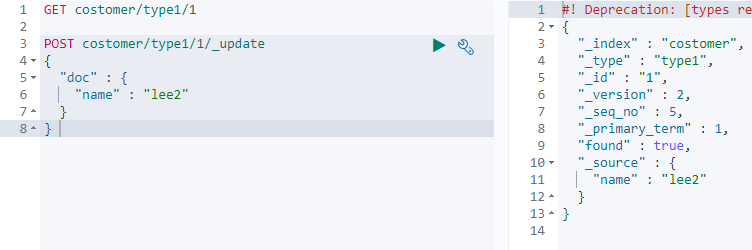
- 기초 스크립트 작성 (나이 1살 올리기)
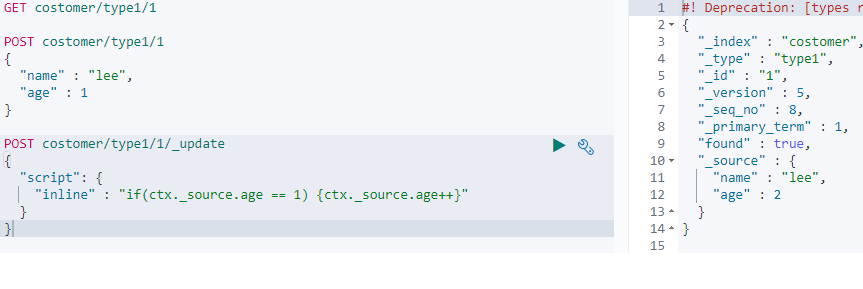
QUIZ 시나리오
-
TourCompany에 오신걸 환영합니다 ! 이 여행사는 열분이 고객명단을 잘 관리해주리라 믿고 의뢰합니다. 다음 시나이로에 따라 여러분들의 작업을 진행하시면 됩니다.
-
이 회사에는 엘라스틱서치가 새로 도입되서 아무런 데이터도 없습니다. 고객관리를 위해 다음 데이터를 입력 하십시오. (index: tourcompany, Type: coustomerlist)
-
다음 임무를 수행하기 위해 쿼리문을 작성하고 데이터베이스 적용 하십시오.
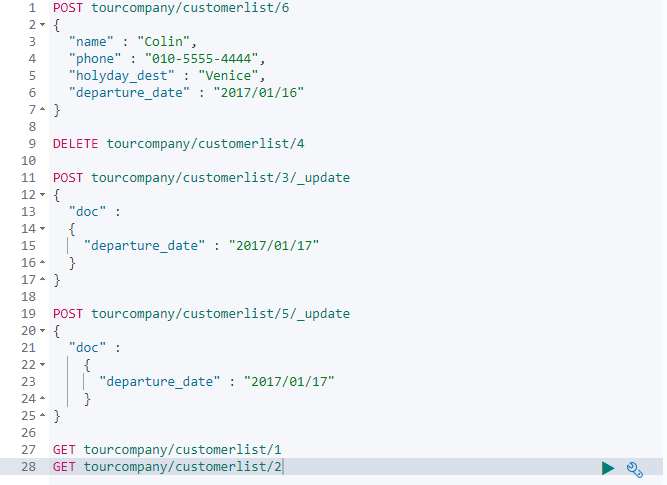
1. BoraBora 여행은 공항테러 사태로 취소되었습니다. BoraBora 여행자의 명단을 삭제 해주십시오.
2. Hawaii 단체 관람객의 요청으로 출발일이 조정 되었습니다. 2023/07/10 에 출발하는 Hawaii 의 출발일을 2023/07/17일로 수정해주세요.
3. 휴일 여행을 디즈니랜드로 떠나는 사람들의 핸드폰 번호를 조회 하세요.
# if 문이나 핸드폰번호 만 뽑아오는 부분은 제외하고 단순 CRUD만 실행해보기

# Elastic Search 배치 프로세스
Batch Processing
-
_bulk API 를 사용하여 위에서 한번씩 실행했던 작업들을 일괄적으로 수행 가능
-
이 기능은 최대한 적은 네트워크 왕복으로 가능한 한 빨리 여러 작업을 수행할 수있는 매우 효율적인 매커니즘을 제공한다.
- http 통신이 한번 요청하면 한번 응답을 해주는 특징 때문에 단순 조그마한 데이터를 주고 받더라도 다른 데이터들이 많이 왔다갔다 함.
-
다음 예제에서는 일괄작업으로 두개의 문서(ID 1 - Lee 및 ID 2 - Lee2) 를 인덱싱
-
HTTP 바디 부분 끝에 반드시 엔터 추가 입력 필요!
POST /customer/type1/_bulk?pretty
{"index" : {"_id", "1"}}
{"name" : {"Lee"}}
{"index" : {"_id", "2"}}
{"name" : {"Lee2"}}
[엔터]
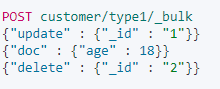
- 이 예제에서는 첫번째 문서 (ID - 1)를 업데이트 한 다음 두번째 문서(ID - 2)를 일괄작업에서 삭제
POST /customer/type1/_bulk?pretty
{"update" : {"_id" : "1"}}
{"doc" : {"name" : "LEE2023"}}
{"delete" : {"_id" : "1"}}
- Bulk API 는 트랜잭션 개념이 적용되지 않음.
_Bulk API
- 2건의 데이터 한번에 넣기

- update 하고 delete 하기
# 검색 API
검색을 실행하는 기본적인 두 가지 방법
-
REST 요청 "URI" 를 통해 검색 매개 변수를 보내기
-
REST 요청 "본문" 을 통해 검색 매개 변수를 보내기
요청 본문 메서드를 사용하면 표현력을 높이고 더 쉽게 읽을 수 있는 JSON 형식으로 검색을 정의
검색 용 REST API 는 _search 엔드 포인트에서 엑세스
#### bank 인덱스의 모든 문서를 반환 하는 예제를 살펴보자
GET /bank/_search?q=*&sort=account_number:asc&pretty
-
bank 라는 인덱스 에서
-
q=* 매개 변수는 Elasticsearch 가 인덱스의 모든 문서와 일치하도록 지시
-
sort=account_number:asc 각문서의 account_number 필드를 사용하여 오름차순 정렬
검색 API 결과 확인하기
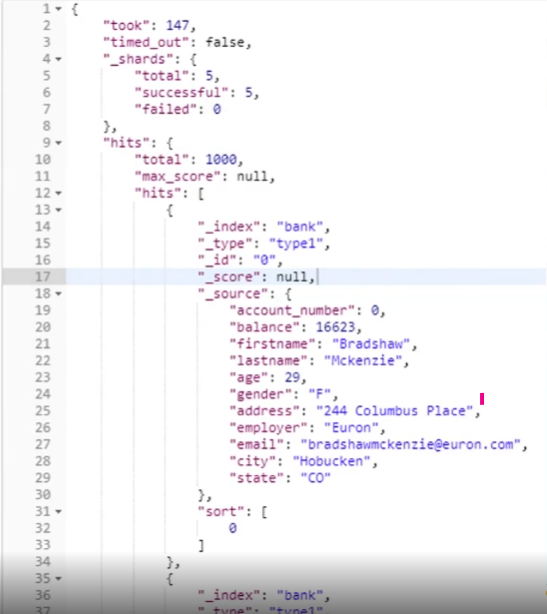
-
took : 검색에 걸린 시간
-
timed_out : 검색 시간이 초과되었는지 여부
-
shards : 검색된 파편의 수와 성공 / 실패한 파편의 수를 알림 (정상적이면안뜸)
-
hits : 검색결과
-
hits.total : 검색조건과 일치하는 총 문서 수
-
hits.hits : 검색결과의 실제 배열
-
hits.sort : 결과 정렬 키
Query DSL
-
Elasticsearch 는 쿼리를 실행하는데 사용할 수 있는 JSON 스타일 도메인 관련 언어를 제공
-
GET /bank/_search?q=*&sort=account_number:asc&pretty 이거랑 같음.
-
size : 1 = 결과를 한개만 (Default : 10)
-
from : 10 = 다음 페이지를 검색할때 10페이지 - 결과의 10번째 항복부터

- match_all 을 수행하고, 계정 잔액별로 결과를 내림차순으로 정렬하고 상위 10개(기본크기)의 문서를 반환

-
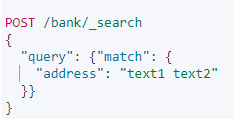
Adress가 text1 또는 text2 와 일치하면 반환 (text1 이랑 text2를 검색함 2개다 일치하면 검색점수가 올라가서 먼저노출)
-
전체적으로 일치하면 match_phrase 사용
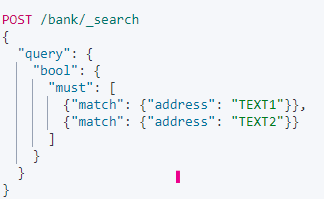
- adress 에 text1과 text2가 반드시 들어가야한다.
기본적인 Elasticsearch 의 사용 및 개념에 대해 알아보았고 다음 포스팅에서는 Kibana에서 Sample data 를 통한 _search 위주로 사용해보도록 하겠다.
