Producer 메시지 전송
@Component
public class TopicConfig {
public final static String communityMember = "communityMember";
@Bean
public NewTopic communityMemberTopic() {
return new NewTopic(communityMember, 1, (short)1);
}
}위와 같이 Topic 을 만들어주고 생성하고..
@Service
@RequiredArgsConstructor
public class CommunityMemberProducer {
private final KafkaTemplate<String, CommunityMemberReqeust> kafkaTemplate;
public void send(CommunityMemberReqeust communityMemberReqeust) {
kafkaTemplate.send(TopicConfig.communityMember, communityMemberReqeust);
}
}template를 만들어서 kafkaTemplate 에서 제공해주는 send 메소드를 통해 topic과 전달하고자 하는 값을 전달하였음.

또는 위와 같이 key 를 이용한 방식으로도 가능함.
프로듀서의 기본 흐름
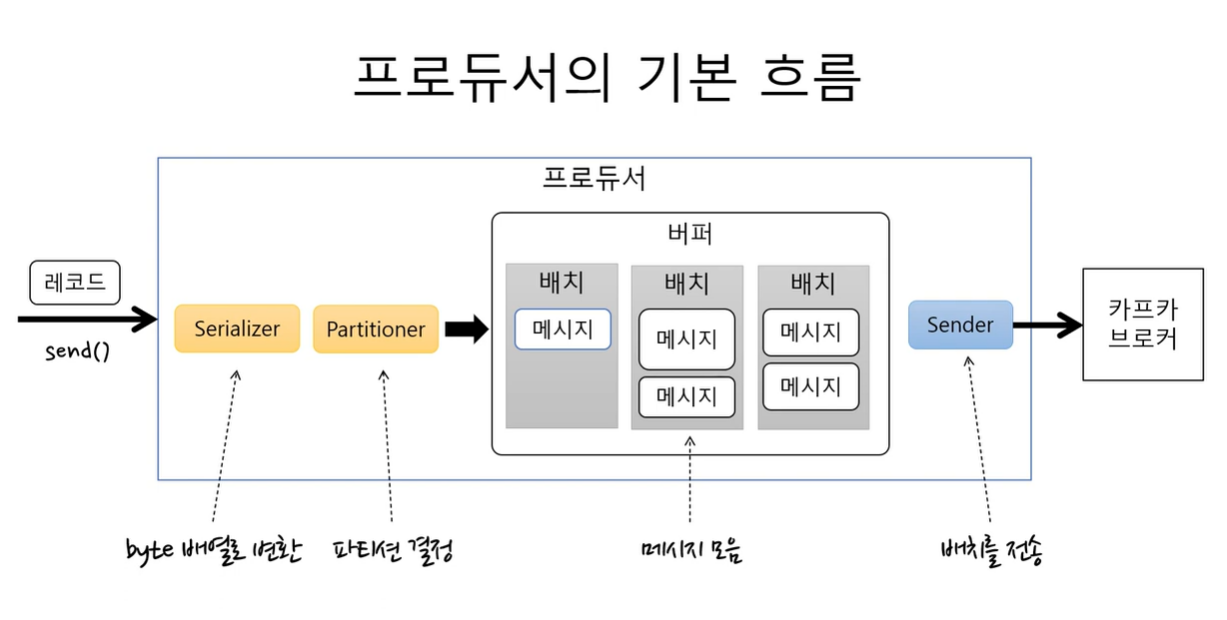
-
Serializer로 byte배열로 먼저 변환 하고 Partitioner를 이용해서 어느 토픽의 파티션으로 보낼지 결정을 하게 된다.
-
변환된 byte배열을 버퍼에 저장한다. 이 때 버퍼에 바로 저장하는게 아니라 배치로 묶어서 저장하게 됨. ( 이전 게시글에서 카프카의 성능이 좋은 이유 중 하나가 여러 메시지를 묶어서 저장하기 때문이라는 점을 이야기함.)
-
sender가 배치를 차례대로 가져와서 카프카브로커에 전송함.
Sender 의 기본동작
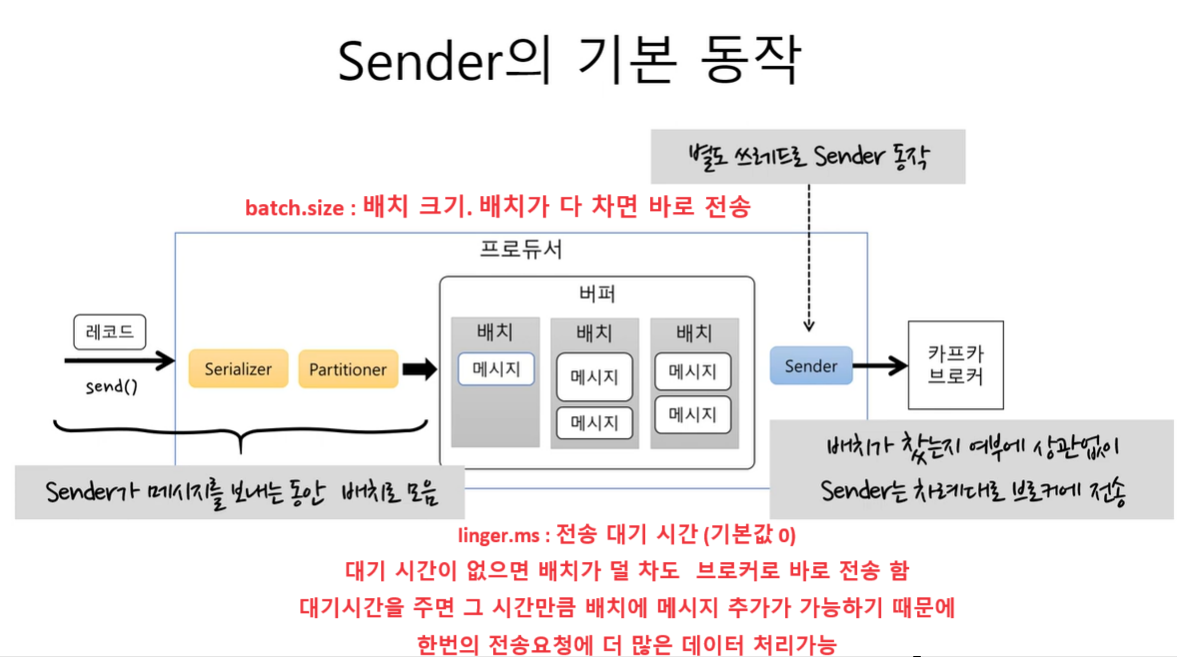
-
배치를 차례대로 꺼내서 브로커로 보내는데 배치가 다 찻는지 여부에 상관없이 브로커로 보낸다.
-
sender 가 배치를 브로커에 보내는 동안 send 메소드를 통해서 들어오는 데이터는 계속 배치에 누적해서 쌓이게 된다.
-
send 는 계속 해서 버퍼에 쌓고, sender는 계속해서 브로커에 데이터를 전송하게 된다.
-
이는 각각 다른 쓰레드로 동작하기 때문에 sender 가 보내는 도중에 send 가 데이터를 버퍼에 누적하지 못한다거나 혹은 그 반대의 경우는 일어날 수 없음.
-
batch size 가 너무 작으면 한번에 보낼 수 있는 메시지의 개수가 줄기 때문에 전송횟수가 많아져서 처리량이 떨어지게 됨..
-
linger.ms 는 전송 대기 시간을 의미함. 대기 시간에 따라 데이터 처리량을 컨트롤 할 수 있음.
전송 결과
-
일반적으로 send 메소드는 전송결과를 알려주지 않는다.
-
전송 결과를 필요로 하지 않으면 그냥 send 메소드를 사용하면 된다.
전송결과를 알아야 할 경우 Future 사용.

-
send 메소드가 return 하는 future 를 사용한다.
-
하지만 future 의 get 을 사용하게 되면 그 시점에서 blocking이 된다. 만약 루프를 돌면서 이 코드를 실행하게 되면? 메시지 하나 보내고 block 되고 또 하나 보내고 block 이 된다.
-
따라서 이런 경우 batch 에 메시지가 쌓이지 않고 한개씩만 들어가게 된다.
-
이는 즉 처리량 저하를 의미하지만 건 별로 확실하게 결과를 알 수 있긴 하다.
-
따라서 높은 처리량을 요구하는 곳에서는 사용하기 힘듬
@Service
@RequiredArgsConstructor
@Slf4j
public class CommunityMemberProducer {
private final ProducerFactory<String, CommunityMemberReqeust> producerFactory;
public void send(CommunityMemberReqeust communityMemberReqeust) {
KafkaProducer<String, CommunityMemberReqeust> kafkaProducer = new KafkaProducer<>(producerFactory.getConfigurationProperties());
// ProducerRecord는 메시지의 내용을 나타내는 객체이며, 각 메시지마다 다른 내용을 가질 수 있기 때문에 쓸 때 마다 new 를 해줌.
Future<RecordMetadata> send = kafkaProducer.send(new ProducerRecord<>(TopicConfig.communityMember, communityMemberReqeust));
try {
RecordMetadata recordMetadata = send.get();
log.info("Kafka 전송 성공: {}", recordMetadata);
} catch (Exception e) {
log.error("Kafka 전송 중 오류 발생: {}", e.getMessage(), e);
}
}
}
communityMember 는 topic 을 의미하고, 0은 partition번호, @6은 offset 번호를 의미한다.
@Service
@RequiredArgsConstructor
@Slf4j
public class CommunityMemberProducer {
private final ProducerFactory<String, CommunityMemberReqeust> producerFactory;
public void send(CommunityMemberReqeust communityMemberReqeust) {
if (shouldThrowException()) {
log.error("Kafka 전송 중 오류 발생: 예외 조건이 만족됨");
throw new RuntimeException("Kafka 전송 중 오류 발생: 예외 조건이 만족됨");
}
KafkaProducer<String, CommunityMemberReqeust> kafkaProducer = new KafkaProducer<>(producerFactory.getConfigurationProperties());
Future<RecordMetadata> send = kafkaProducer.send(new ProducerRecord<>(TopicConfig.communityMember, communityMemberReqeust));
try {
RecordMetadata recordMetadata = send.get();
log.info("Kafka 전송 성공: {}", recordMetadata);
} catch (Exception e) {
log.error("Kafka 전송 중 오류 발생: {}", e.getMessage(), e);
}
}
private boolean shouldThrowException() {
// 예외를 발생시킬 조건을 여기에 구현
// 네트워크 연결 문제, Kafka 브로커 장애, 메시지 큐 꽉 참 등
return true; // 예외 발생 조건을 만족하는 경우
}
}
네트워크 연결 문제, Kafka 브로커 장애, 메시지 큐 꽉 참 등 여러가지 이유로 에러가 낫을 시 후처리 해줄 수 있음.

- 또는 send 메소드의 CallBack 객체를 전달할 수 있음. 전송이 완료되면 onCompletion 메소드로 받게 되는데, 이때 Exception 객체를 받게 되면 전송에 실패한 것이다.
- 이 방식은 blocking 이 되지않아서 처리량 저하가 없음
@Service
@RequiredArgsConstructor
@Slf4j
public class CommunityMemberProducer {
private final ProducerFactory<String, CommunityMemberReqeust> producerFactory;
public void send(CommunityMemberReqeust communityMemberReqeust) {
if (shouldThrowException()) {
log.error("Kafka 전송 중 오류 발생: 예외 조건이 만족됨");
throw new RuntimeException("Kafka 전송 중 오류 발생: 예외 조건이 만족됨");
}
KafkaProducer<String, CommunityMemberReqeust> kafkaProducer = new KafkaProducer<>(producerFactory.getConfigurationProperties());
kafkaProducer.send(new ProducerRecord<>(TopicConfig.communityMember, communityMemberReqeust), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
log.info("Kafka 전송 성공: {}", metadata);
log.error("Kafka 전송 중 오류 발생: {}", exception);
// exception 에 대한 핸들링..
}
});
}
private boolean shouldThrowException() {
// 예외를 발생시킬 조건을 여기에 구현
// 네트워크 연결 문제, Kafka 브로커 장애, 메시지 큐 꽉 참 등
return false; // 예외 발생 조건을 만족하는 경우
}
}

전송 보장과 ack
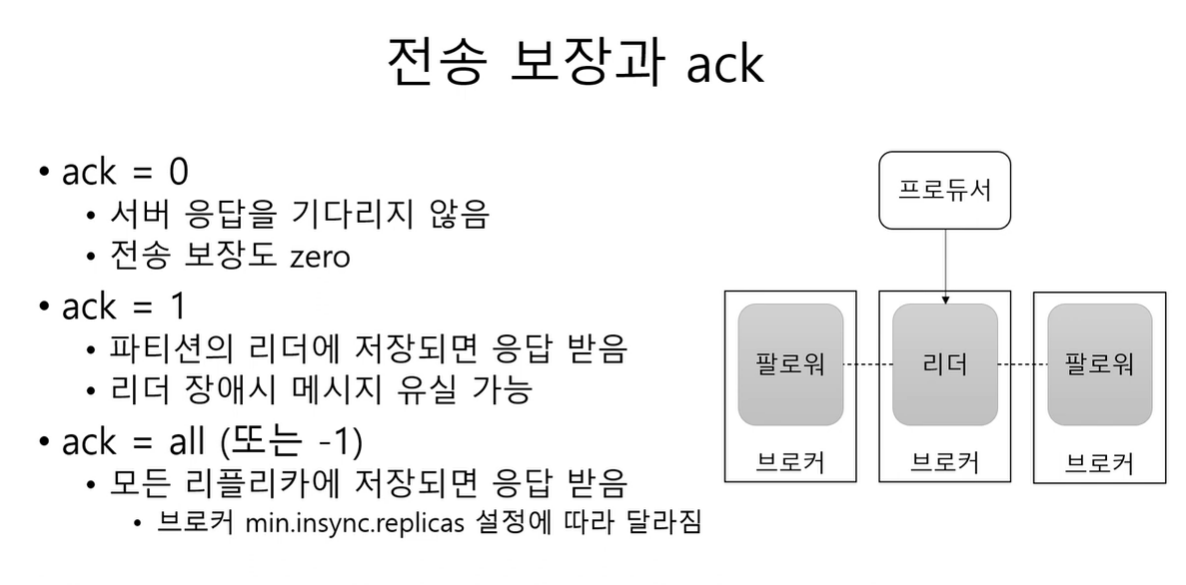
producer 는 전송을 보장하기 위해서 ack 라는 설정을 사용을 한다.
-
ack 0 이면 ? 서버로 부터 성공 실패 응답을 기다리지 않는다. 즉 전송을 보장하지 않는다. 처리량은 높지만 메시지 유실 가능성이 있음.
-
ack 1 이면 ? 파티션의 리더에 저장되면 성공 응답을 받게됨. 하지만 팔로워에 아직 복제되지 않았는데 리더가 장애날 시 ..? 유실 가능성 있음.
-
ack all 이면 ? 모든 레플리카에 저장 되었을 때 성공응답을 받게 됨.
ack + min.insync.replicas
-
이 옵션은 브로커의 옵션이다. 이 옵션은 프로듀서의 ack 옵션이 all 일 때 저장에 성공했다고 응답할 수 있는 동기화된 레플리카의 최소 개수다.
-
예를들어 레플리카 개수가 3일때 프로듀서가 ack 가 all로 설정되어 있고 브로커에 min.insync.replicas 를 2로 줬다면 ?
-
리더에 성공적으로 저장되면 두개의 팔로워중 한개에 저장이 성공되면 동기화된 레플리카 개수가 2가된다. 그렇게 되면 성공 응답함.
-
조금 조심해야 할 옵션으로는 레플리카 개수가 3일때 프로듀서가 ack 가 all로 설정되어 있고 브로커에 min.insync.replicas 를 3으로 줬다면 ?
-
리더 저장 성공, 팔로워 2개도 저장 성공 하면 응답을 받게 되지만 , 팔로워 중 하나라도 장애가 발생 시 레플리카 부족으로 저장에 실패하게 된다. 따라서 갯수 설정을 신중히 설정한다.
에러 유형
전송 과정에서의 에러
-
전송 타임아웃 에러
-
리더 다운 후 새로운 리더 선출 중
-
브로커에서 설정한 메시지 크기 한도 초과 등
전송 전의 실패
-
직렬화 실패, 프로듀서 자체 요청 크기 제한 초과
-
프로듀서 버퍼가 다 차서 타임아웃 등
실패대응 1 : 재시도
-
재시도 가능한 에러는 재시도를 처리한다. ( 브로커 응답 타임아웃 혹은 일시적인 리더없음)
-
프로듀서 자체적으로 브로커 전송 과정에서 에러가 발생하면 재시도 가능한 에러에 대해서는 재시도를 한다. (retrires 속성)
-
send 메소드의 Exception 종류에 따라 수동 설정
-
특별한 이유가 없다면 무한 재시도는 하지 않는다. (일정 횟수도 두는게 좋음) 다음 메시지가 밀리기 때문
실패대응 2: 기록
-
추후 처리를 위해 별로 파일이나 DB에 저장 후 후처리
-
send 에서 Exception 발생이나 콜백에서 Exception 받거나 future.get 메소드에서 Exception 발생 시 시도하면 될 듯 하다.
재시도 메시지 중복 전송 가능성
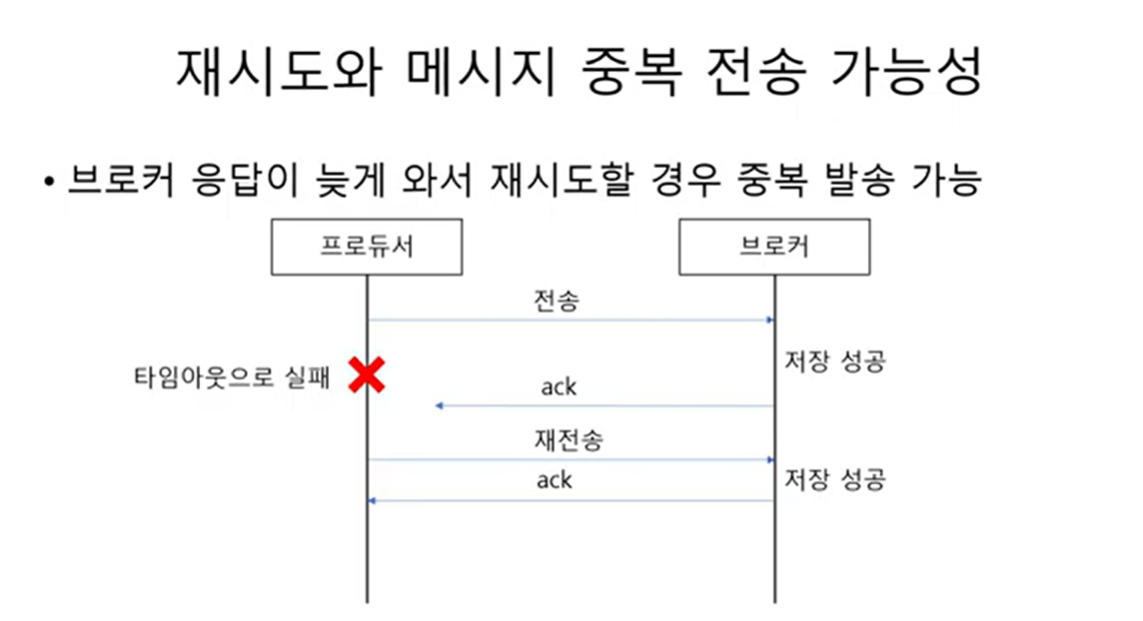
재시도 할 때 메시지 중복 전송에 대해 주의해야 함
-
프로듀서가 보낸 메시지가 브로커에 성공적으로 저장이 되었지만 성공응답인 ack 가 늦게 도착하고 그 사이에 프로듀서가 타임아웃으로 실패하게 되고 재전송을 하면 ? 브로커는 또 다시 저장에 성공하게 된다.
-
따라서 재시도를 할때 이 점에 유념해야하고 enable.idempotence 라는 속성을 사용하면 중복에 대해 어느정도 해결이 된다고 한다. 자세한 건 찾아보자.
재시도와 순서
재시도는 전송순서를 바꾸기도 한다.
-
max.in.flight.requests.per.connection
-
블록킹없이 한 커넥션에서 전송할 수 있는 최대 전송중인 요청 개수
-
이 값이 1보다 크다면? 재시도 시점에 따라 메시지 순서가 바뀔 수 있음
-
전송순서가 중요하면 이 값을 1로 설정하자.
