# Kibana 초기 설정
키바나 소개
-
Kibana 는 Elasticsearch 와 함께 작동하도록 설계된 오픈소스 분석 및 시각화 플랫폼
-
Kibana 를 사용하여 Elasticsearch 색인에 저장된 데이터를 검색, 보기 및 상호 작용
-
고급 데이터 분석을 쉽게 수행하고 다양한 차트, 테이블 및 맵에서 데이터를 시각화
-
간단한 브라우저 기반의 인터페이스를 통해 실시간으로 Elasticsearch 쿼리의 변경 사항을 표시하는 동적 대시 보드를 신속하게 만들고 공유 가능
Kibana 의 상태보기
현재 할당중인 메모리 및 여러가지 데이터, 기본 플러그인 들이 나와있음.
Elasticsearch 와 Kibana 연결
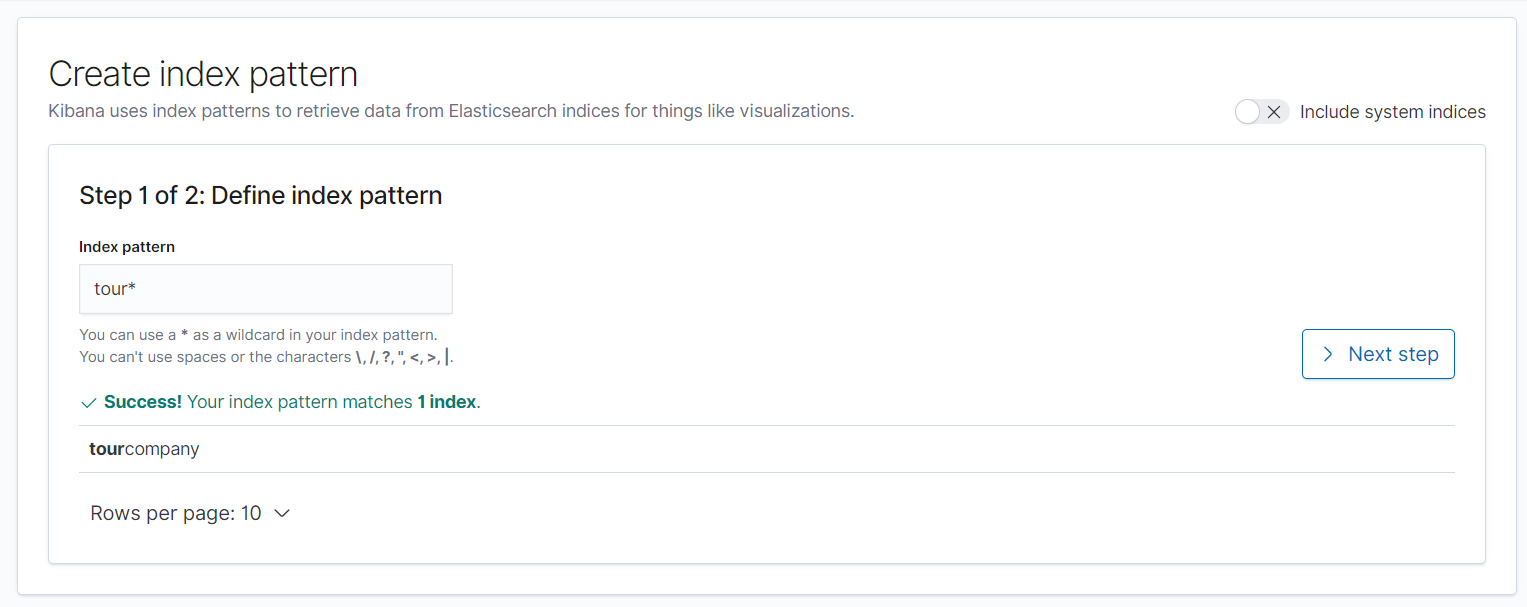
- kibana 의 -> Management 메뉴 -> Kibana Index Patterns
현재 내 index의 상태이다.

이전에 추가한 tourcompany 에 대한 index 의 패턴을 추가 해보겠다.
이전에서는 어떤 인덱스를 설정할 것 인지를 선택 했다면 2step 에서는 Time Filter 를 정의해야 한다.
-
타임 시리즈란? 시계열 이라는 뜻
-
시간에 관련되서 정리를 한 데이터. (시간에 따라 분석을 할 수 있는 데이터)
-
ex) 주식 , 시세, 가상자산 시세, 로그 등 시간이 변함에 따라 의존적인 형태를 보여주는 것.
-
주식의 경우 장이 열리고 데이터가 변형되고 장이 닫히면 움직이지 않고 로그도 사용자가 많을 때 많이 생기고 없을 땐 없고.. 이런느낌
일단 내가 추가한 index 에는 날짜데이터가 없기 때문에 pass 하고 나중에 로그 분석할땐 UTC time 이나 그 외 time 데이터를 기준으로 설정 해줘야 겠다.
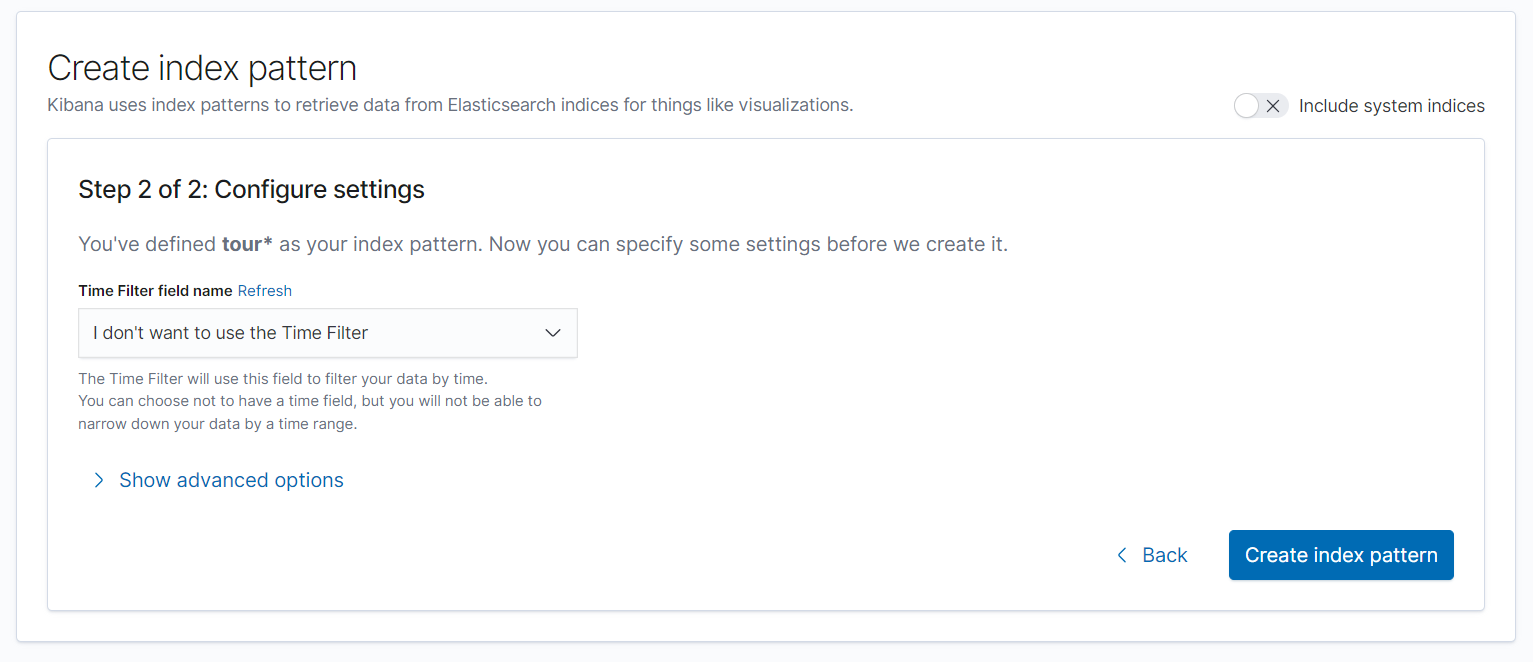
그리고 필요하다 생각이 들 때 추가적으로 설정할 수 있는 옵션이다.
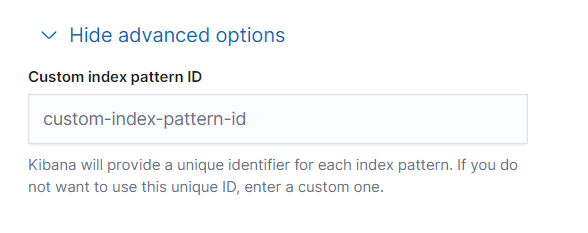
이후 패턴을 만들면 끝이 아니라, 매핑을 뭘로 어떤 타입으로 했는지 까지 다 나오게 된다.
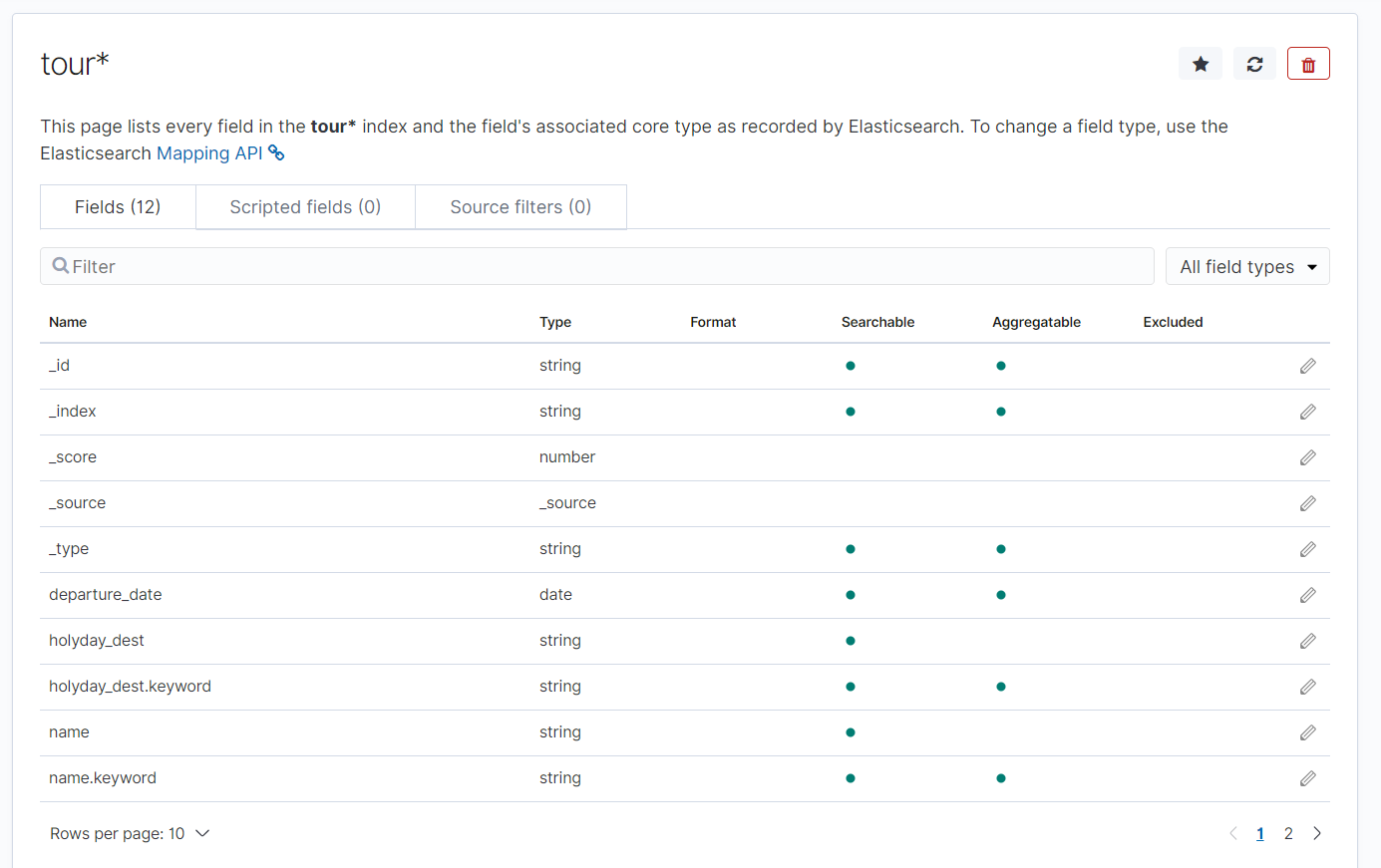
그리고 메인페이지를 가보면.. UI가 완성이 되어있고
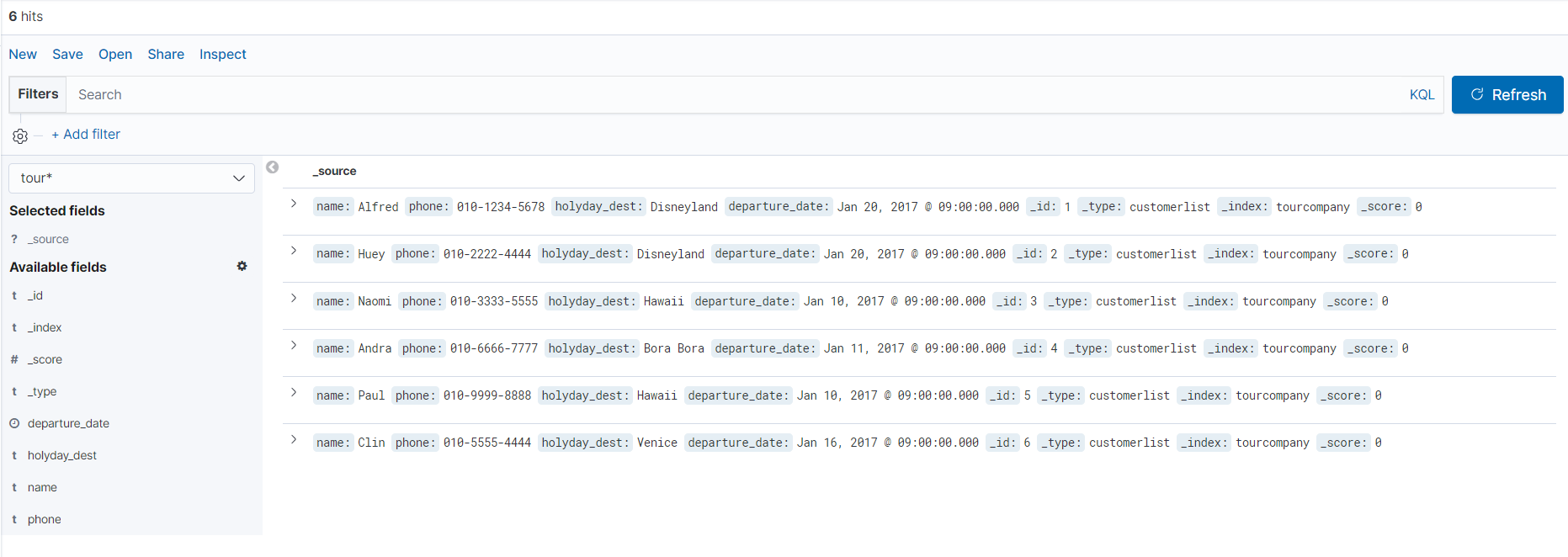
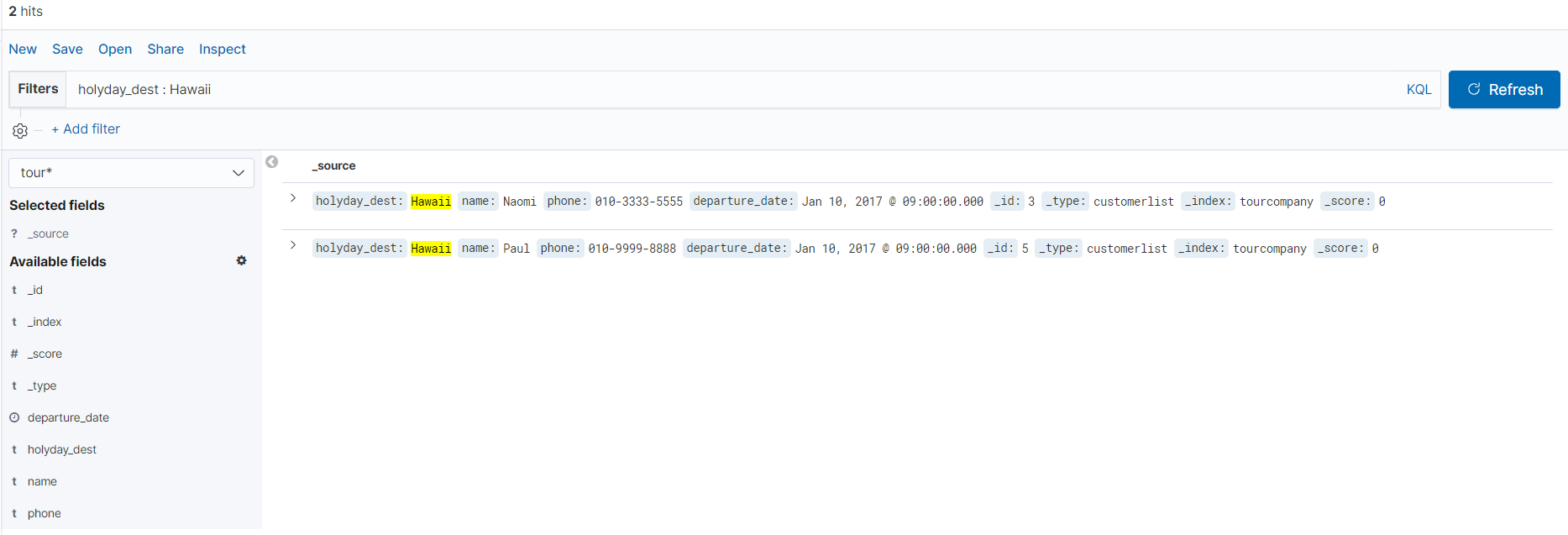
쿼리에서 작성했던 문법도 그대로 검색에 응용이 가능한 것 같다.
# Kibana 시각화 준비
데이터를 로드하기 전에..
- Mapping 이란 작업을 해줘야함..
Mapping 이란 ?
-
인덱스의 문서를 논리적 그룹으로 나누고 필드의 검색 가능성 또는 토큰화 되었는지 또는 별도의 단어로 분리되는지와 같은 필드의 특성을 지정
-
account 데이터 세트에는 매핑 필요없음
여기서 필요한 이유는 geo_point 때문인데 지도상의 경도 위도 좌표이다. 문제는 이 데이터는 소수인데, 매핑 없이 data 를 넣게 되면 geo_point 로 인식하지않고 float 으로 인식하게 되어있다. 따라서 나중에 시각화를 시킬 때 원하는 데이터가 나오지 않을것이다.
Kibana 메뉴 간단 설명
-
Discover : 결과를 탐색하고 Visualize 에서 저장된 검색의 시각화'
-
Visualize : 여러가지 방법으로 데이터를 시각화
-
Dashboard : 각종 시각화자리를 커스터마이징 할 수 있는 대시보드
-
Timelion : 데이터 발생량 타임 라인
-
Management : 인덱스, 오브젝트, 및 각종 기능 관리 탭
-
DevTool : curl 과 같이 쓸 수 있는 기능
Elasticsearch 에 샘플 데이터 세트 로드와 인덱스 패턴 정의
-
일단 데이터를 넣는다. 현재 나는 7.2.0 버전을 사용하고 있기 때문에 그에 맞는 샘플 데이터를 로드 해보자.
-
내가 쓰고 있는 버전의 튜토리얼 문서이다.
https://www.elastic.co/guide/en/kibana/7.2/tutorial-build-dashboard.html#tutorial-load-sample-data
리눅스를 사용중이면 아래의 명령어로 사용하면 될 것다.
나는 window로 실습을 진행하기 때문에 브라우저를 통해서 다운을 받고 압축까지 해제하도록 하였다.
https://download.elastic.co/demos/kibana/gettingstarted/8.x/shakespeare.json
https://download.elastic.co/demos/kibana/gettingstarted/8.x/accounts.zip
https://download.elastic.co/demos/kibana/gettingstarted/8.x/logs.jsonl.gz
샘플데이터의 구조가 어떤 구조로 되어있는지 나와있는 부분이다.
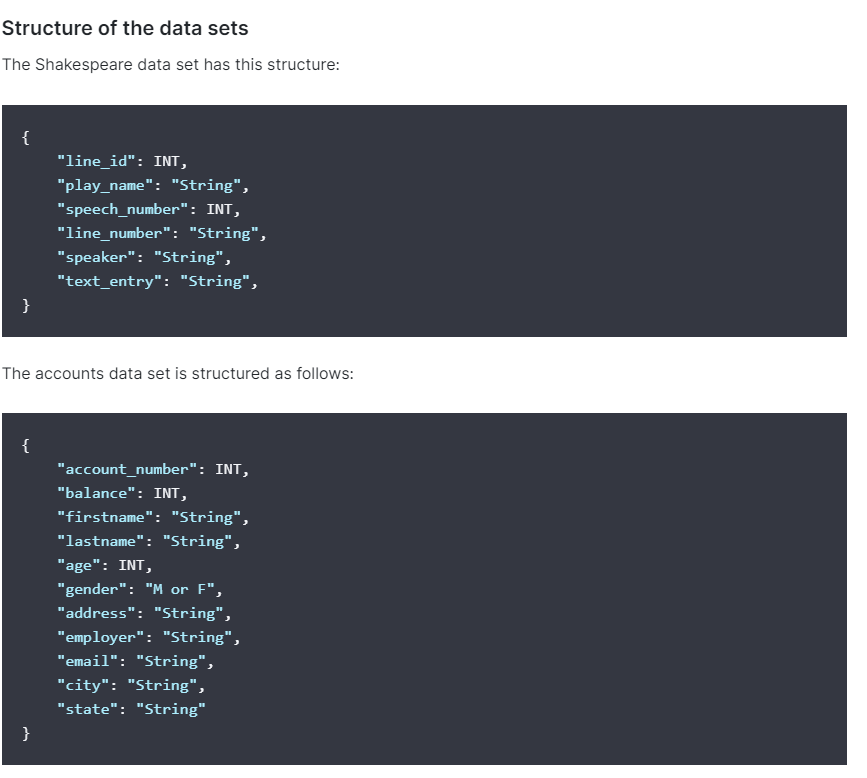
그리고 가장 중요한 geo_point 데이터이다.
그리고 데이터 Mapping 을 먼저 해줘야 한다.
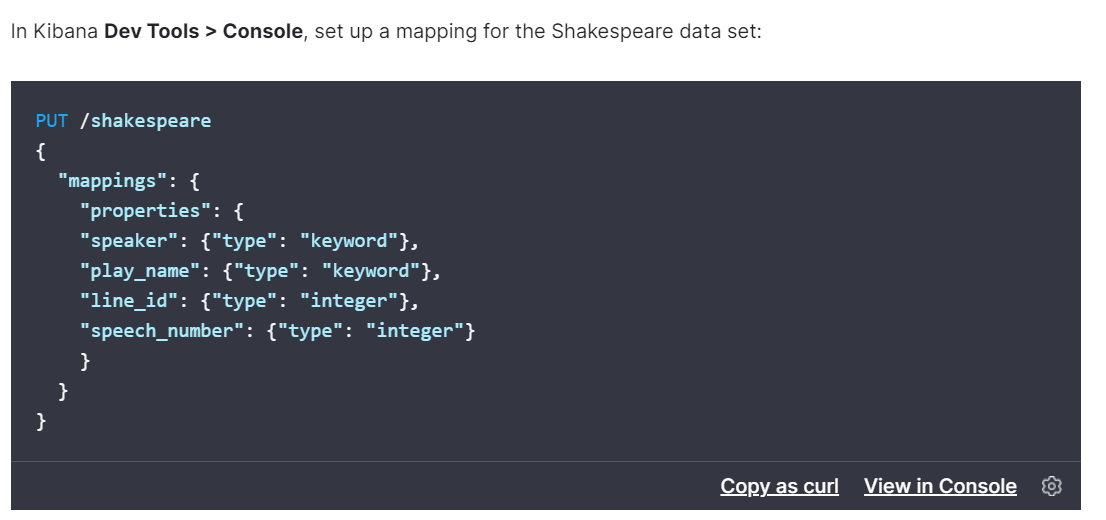
공식 doc 에 있는 데이터를 Mapping 해주자..
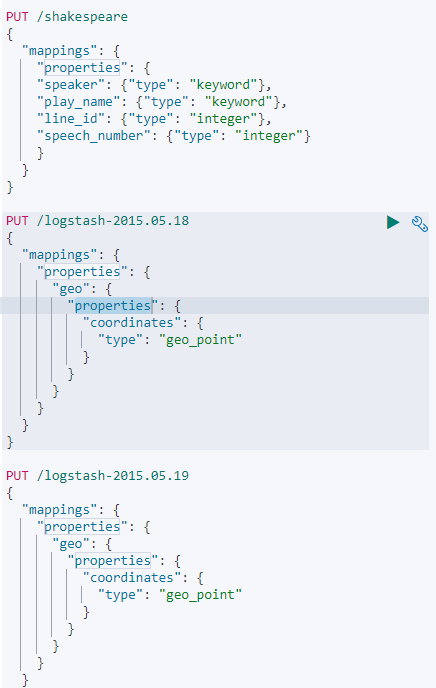
Mapping 을 해준 결과 값. 3일치의 로그데이터 Mapping 성공 응답을 받았다.

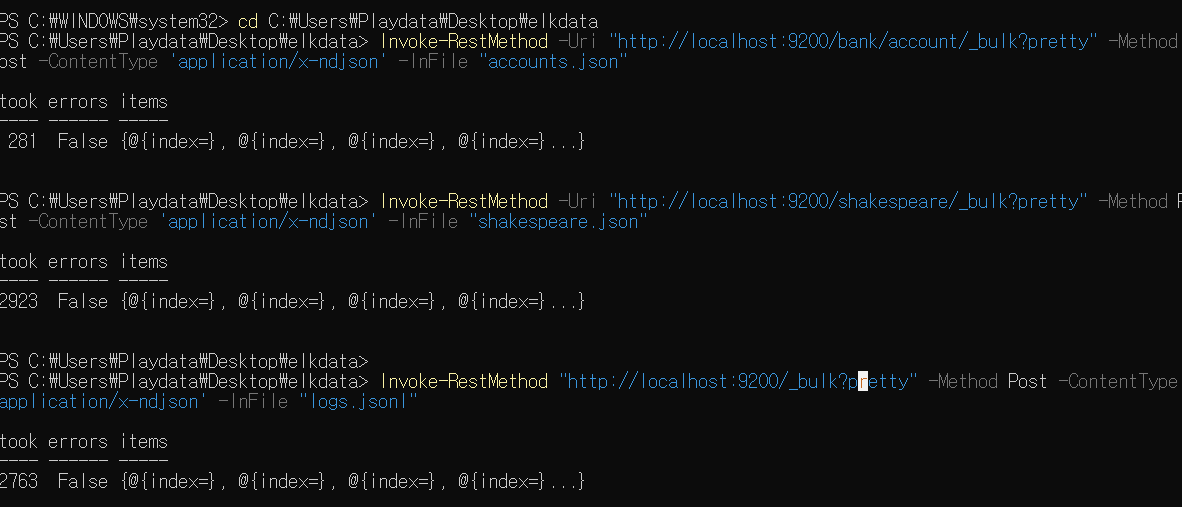
그리고 아래의 명령어를 통해서 전부 다 데이터를 넣어보자. 나는 윈도우환경에서 작업하기 때문에 Invoke 명령어를 이용하자.
Invoke-RestMethod -Uri "http://localhost:9200/bank/account/_bulk?pretty" -Method Post -ContentType 'application/x-ndjson' -InFile "accounts.json"
Invoke-RestMethod "http://localhost:9200/_bulk?pretty" -Method Post -ContentType 'application/x-ndjson' -InFile "logs.jsonl"
status가 201 이 떨어지는지 확인을 꼭 해야하는데.. powershell 이어서 그런지 아래와 같은 결과 화면을 받았다. 그래도 error 가 false니 전부 다 들어간거겠지..
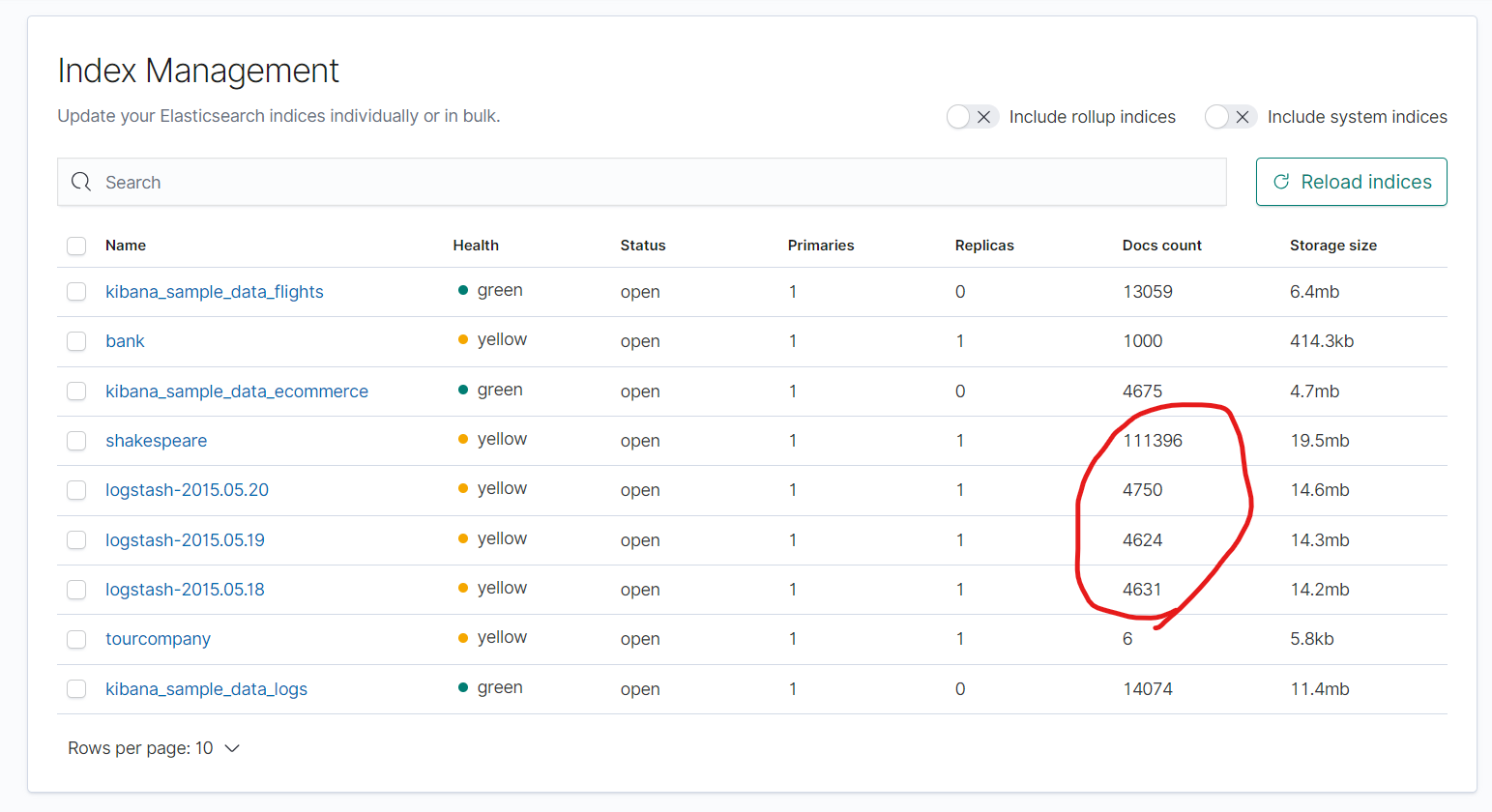
정상적으로 추가가 되었다면 Index Management에 들어가보니 아래와 같은 화면처럼 추가가 되었다.
그리고 나서 index pattern 을 추가해주자..
- ba* : 시계열 데이터 없기 때문에 바로 만들어줌
- shakes* : 시계열 데이터 없기 때문에 바로 만들어줌
- logstash-2015.05.* : logstash 자체가 타임필드를 설정을 해야만 한다. 실시간으로 데이터를 수집하면서 시간에 대한 기록을 남기기 때문이다.
- @timestamp 라는 것 이 있는데, @의 의미는 logstash 가 수집한 시간이다. 일반적으로는 @timestamp 랑 UTC time 이랑 일치한다.
- 나의 실습환경은 UTC time 으로 진행 할 것 이다.
인덱스 패턴을 정의하고 아까 전에 주의 깊게 Mapping 했었던 geo_point 값도 잘 Mapping 이 되었는지 확인하자.. 여기서 geo_point 가 없다면 Mapping 이 잘못된것이다.

데이터가 잘 올라갔고 노출되는지 확인하자.
샘플 데이터의 시각화 설정
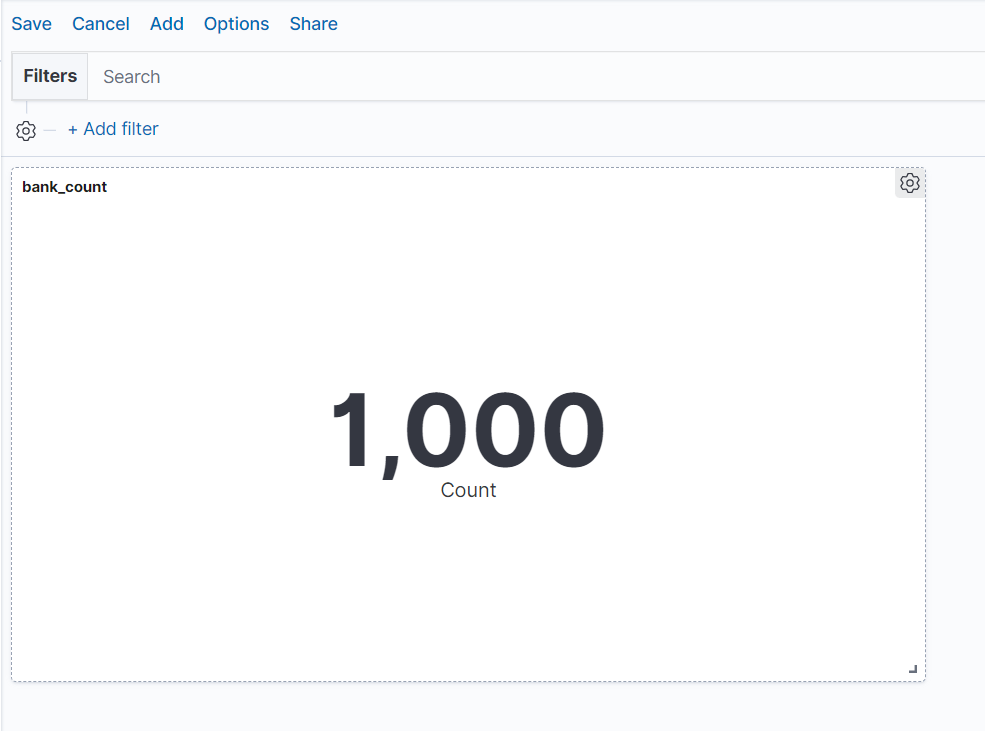
데이터의 시각화를 위하여 Visualize 메뉴로 들어가서 새로운 시각화 자료를 만들어보자.. 일단 비교적 가장 간단하다고 하는 Matric(그림을 그리기 전 숫자 계산을 먼저 해줌) 메뉴 먼저 설정하려고 한다 bank 데이터로 진행 예정..
갯수가 몇갠지 나타내주는 시각화를 하기위해 먼저 저장을 해 주자..
Visualize 메뉴에 다시 들어가보면 내가 저장한 데이터가 있을 것 이다.
그리고 Dashboard 를 만들어주자. 그리고 내가 만든 데이터를 추가 해주면 Dashboard에 내 데이터가 나올 것 이다.
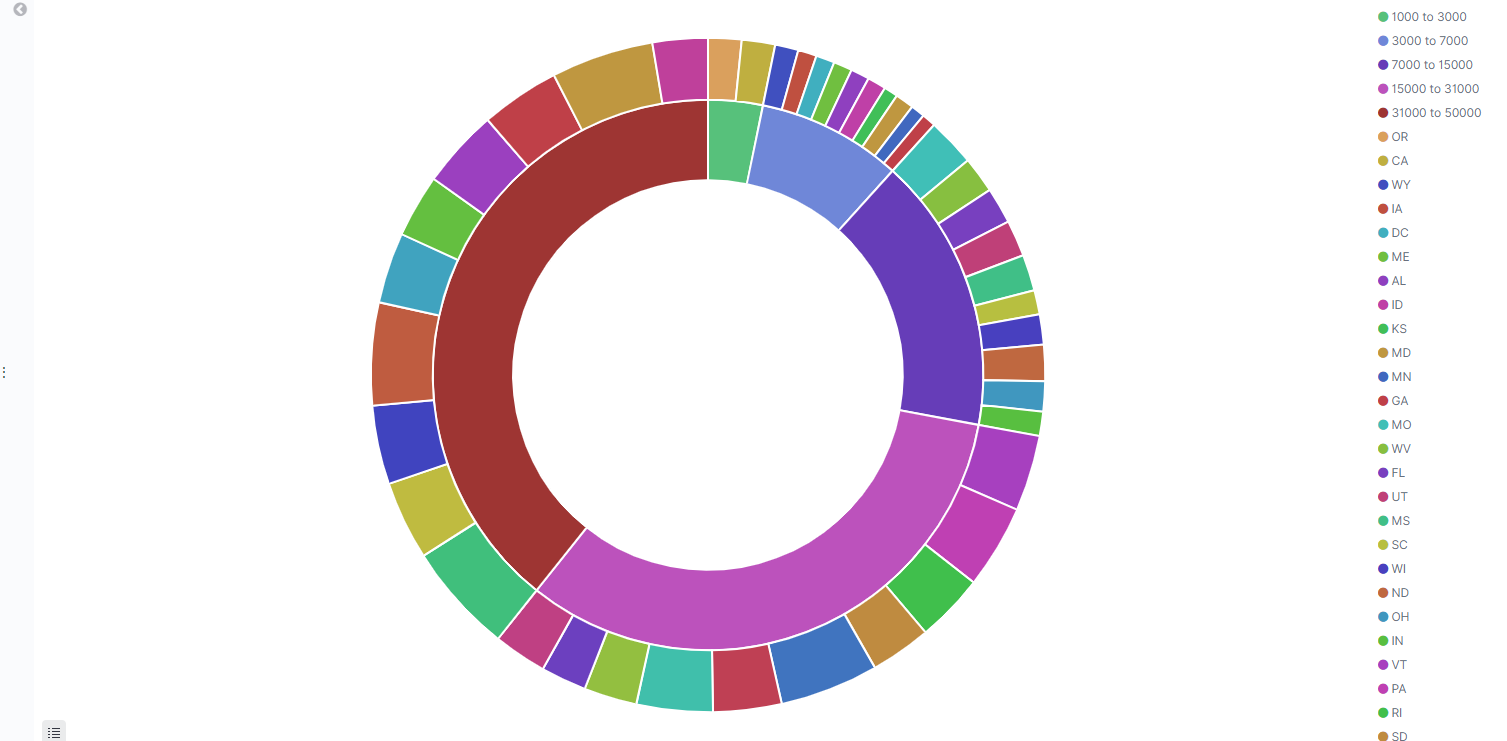
그리고 같은 데이터로 Pie chart 도 한번 만들어보자. 그리고 옵션이 고루고루 나올 수 있도록 범위 데이터를 넣어주자.
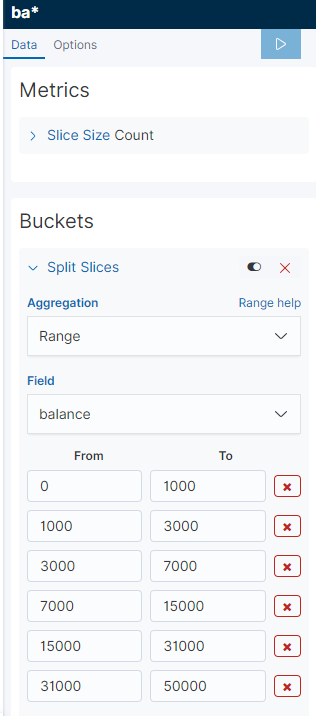
그리고 Split Slices 메뉴로 바깥쪽에 이 잔액을 가진사람들의 분포도 차트도 한번 더 추가해보자.
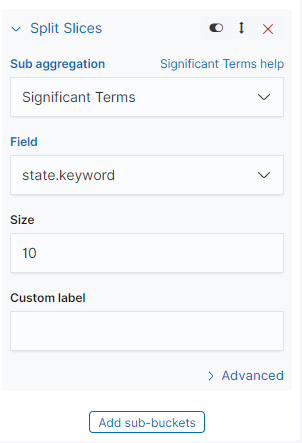
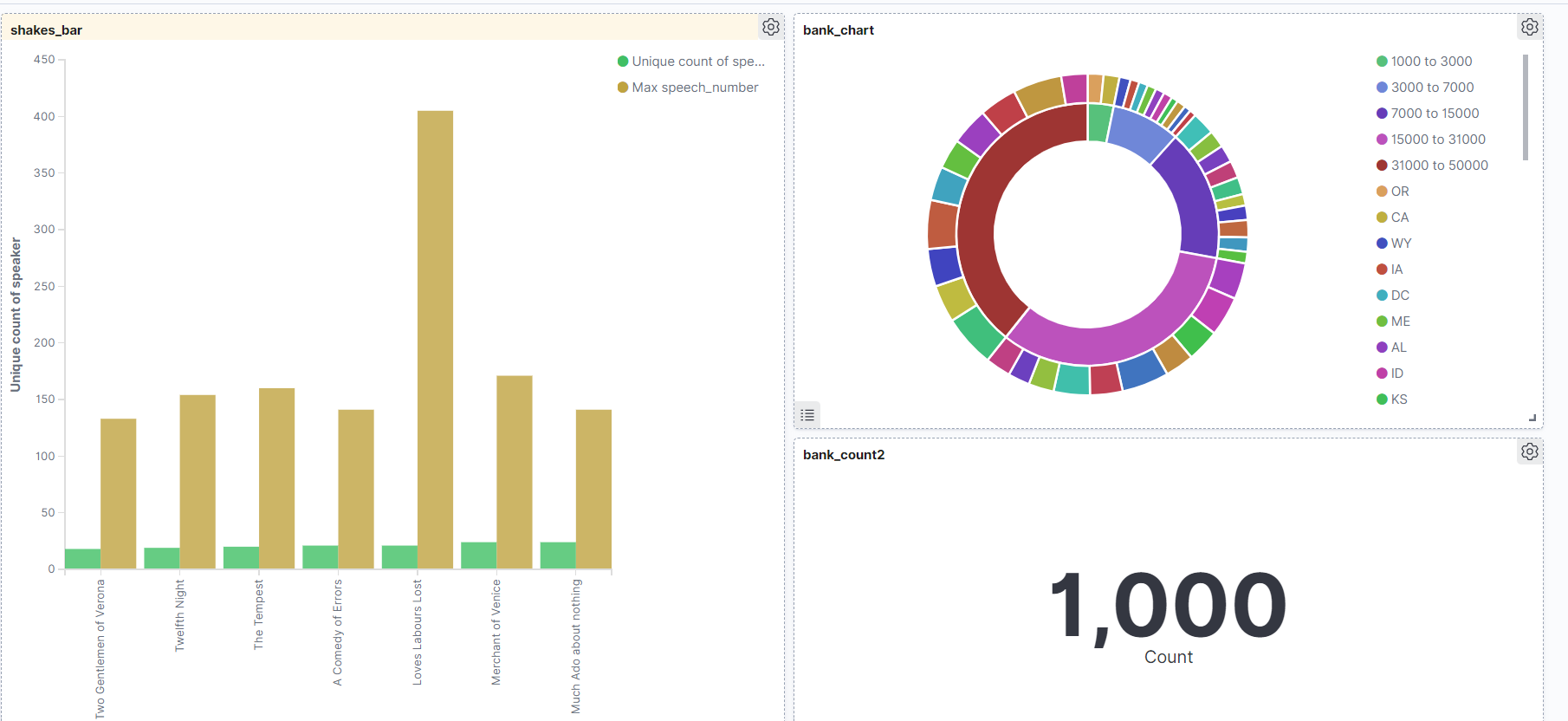
다시한번 chart 를 Vertical Bar 로 shakes* 데이터를 이용하여 연극별 등장인물의 출연빈도 를 시각화 해보자.
x축에는 연극의 이름을 나타내자
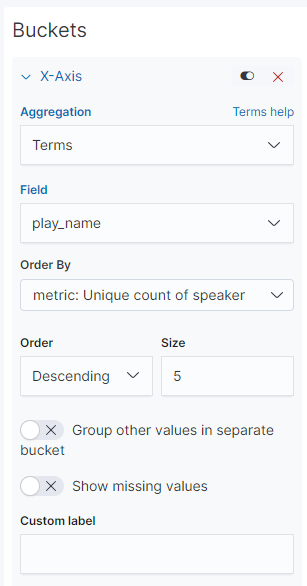
y축은 speaker 들의 숫자 를 중복제거 하고 나타내보자.
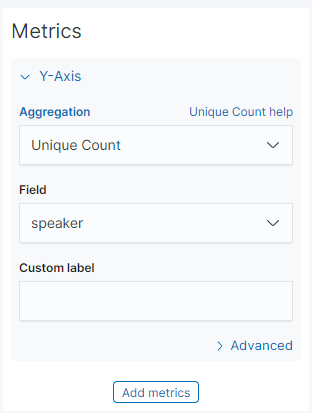
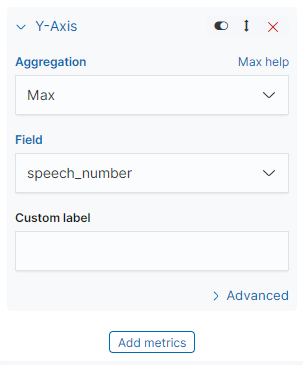
추가 데이터로 말을 얼마나 많이 했는지의 차트도 추가해보자. y축을 하나 더 추가해주고, 조금 더 이해하기 쉬운 모양으로 바꾸기 위해 해당 값 들을 바꿔준다. 그리고 저장하자.
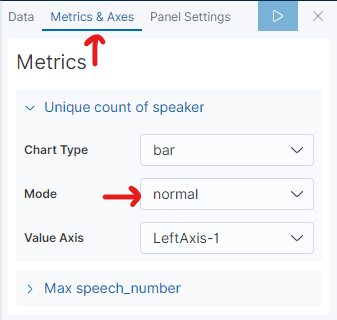
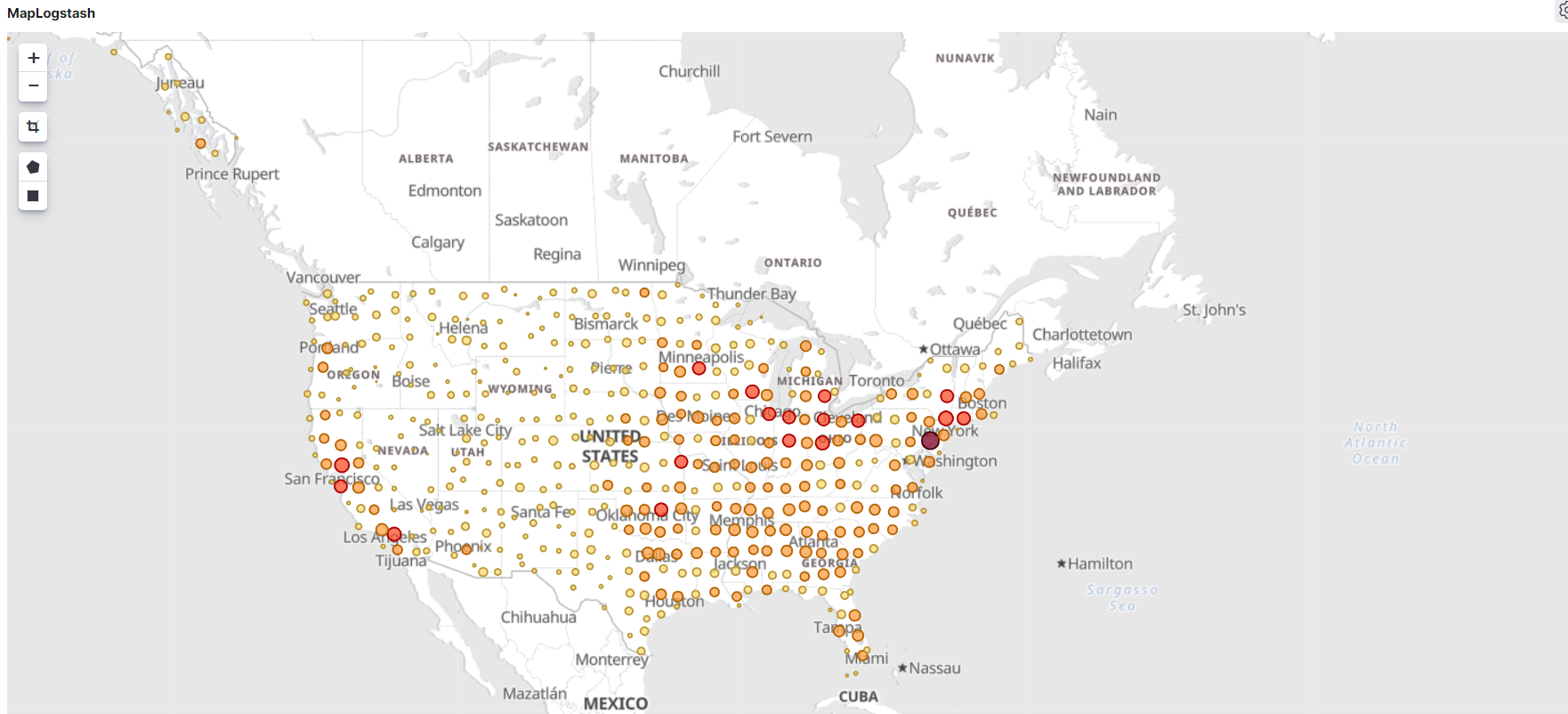
그리고 그린김에 하나만 더 그려보자 . 이번엔 Coordinate Map 으로 shakes* 데이터를 그려보자.
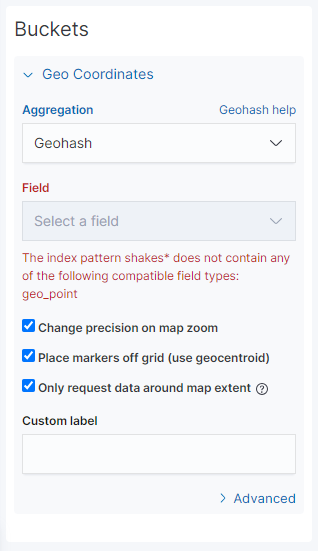
하지만 geo 값이 없어서 그리지 못한다고 한다. geo 값이 있는 logstash 로 그대로 그리고 저장하자. 그런데 아무리 설정해도 data가 나오지 않았음 이유는 데이터가 15분전으로 설정 되어있어서 데이터에 맞게 날짜를 변경해줘야 했다.
설정해주니 데이터가 나타났다.
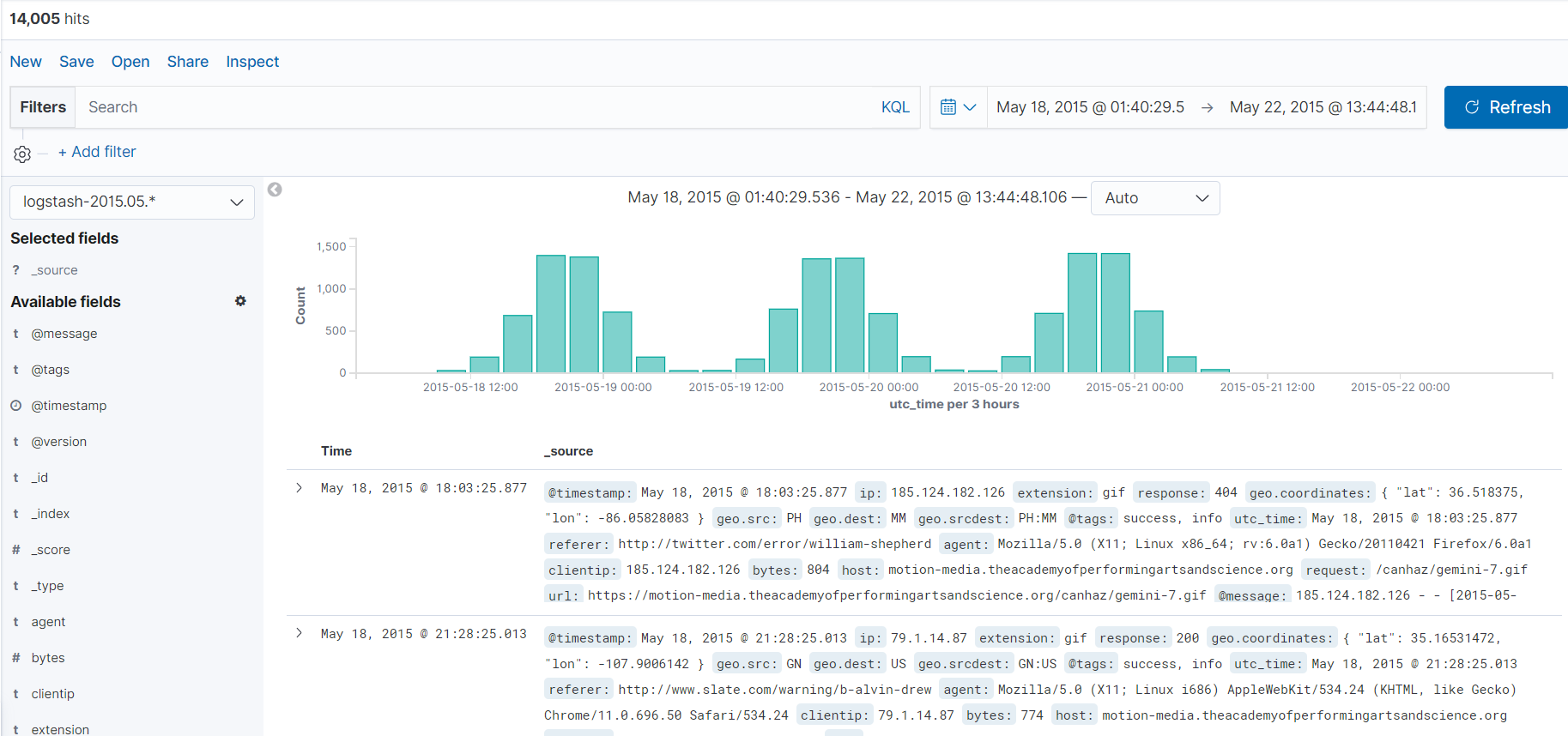
그리고 아까 나오지 않은 차트를 보니 데이터가 나타낫다. 징그럽다;
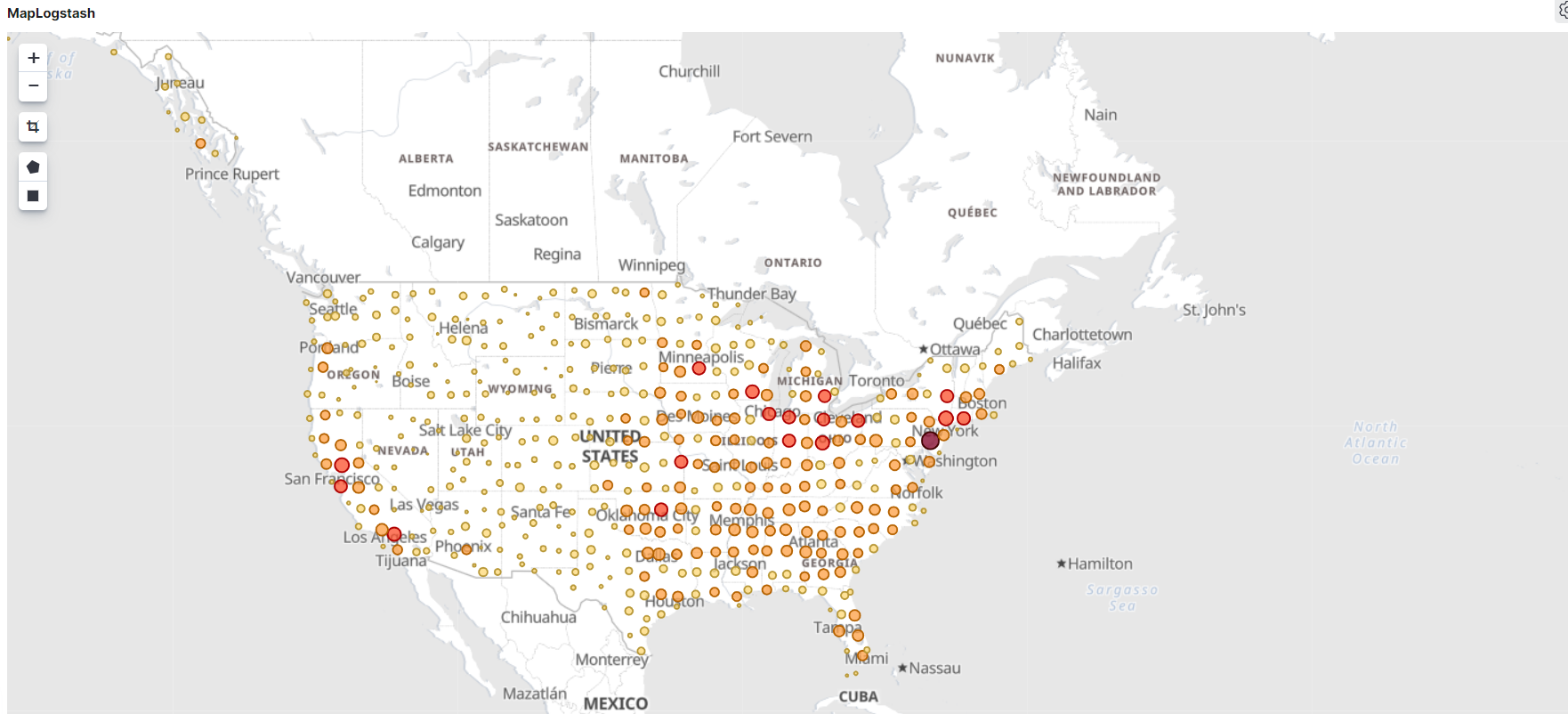
시각화를 대시보드로 어셈블