JPA 사용 중 MySQL에 대용량 데이터를 삽입해야 할 일이 발생했습니다.
데이터를 삽입하는 3가지 방법을 정리해보자면 다음과 같습니다.
save()
-
이 메서드는 단일 엔터티를 데이터베이스에 저장하는 데 사용됩니다.
-
주로 엔터티를 새로운 행으로 삽입하거나, 기존 행을 업데이트하는 데에 사용됩니다.
-
데이터베이스의 기본 키 또는 고유한 제약 조건을 기반으로 합니다.
예를 들어, JPA(Java Persistence API)에서 save() 메서드는 엔터티를 저장하거나 업데이트합니다.
saveAll()
-
이 메서드는 여러 개의 엔터티를 데이터베이스에 저장하는 데 사용됩니다.
-
save()와 비슷하지만, 여러 개의 엔터티를 한 번에 처리할 수 있습니다.
-
여러 엔터티를 한 번에 저장하는 데 사용할 수 있는 배치 삽입 또는 업데이트 작업을 수행할 수 있습니다.
Bulk Insert
-
"Bulk Insert"는 대체로 대량의 데이터를 효율적으로 데이터베이스에 삽입하는 작업을 나타냅니다.
-
이는 일괄 처리된 대량의 데이터를 한 번의 쿼리로 처리하여 성능을 향상시키는 것을 의미합니다.
-
특히, 일괄 삽입은 대량의 데이터를 효과적으로 처리할 수 있도록 최적화된 방법을 사용하는 것이 중요합니다.
10만건 테스트
save()
@Test
@DisplayName("글 등록하기 Save")
public void createPostOneTest(){
long startTime = System.currentTimeMillis();
for (int i =1; i< 100000; i++){
Post post = Post.builder()
.postTitle("title"+i)
.postContent("content"+i+1)
.build();
postRepository.save(post);
}
System.out.println("taken time = "+(System.currentTimeMillis() - startTime)+"ms");
}
310081ms 기록
save() 가 대용량처리를 할 때 효율적이지 않은 이유는 다음과 같습니다.
Individual Database Calls
save 메서드는 각 엔터티에 대해 개별적인 데이터베이스 호출을 수행합니다. 대량의 데이터를 처리할 때 이는 많은 개별적인 쿼리를 실행해야 함을 의미합니다.
많은 작은 트랜잭션이 발생하면 데이터베이스 연결 및 트랜잭션 오버헤드가 발생할 수 있습니다.
Hibernate Session Flush
일반적인 ORM 프레임워크인 Hibernate와 같은 경우, save 호출 이후에 Hibernate는 영속성 컨텍스트를 플러시(flush)하는데, 이는 모든 변경 사항을 데이터베이스에 동기화하는 작업을 수행합니다.
대량 처리 시에는 많은 엔터티가 영속성 컨텍스트에 쌓이고, 이를 플러시하는 과정에서 성능 저하가 발생할 수 있습니다.
Transactional Overhead
대용량 처리에서 save를 사용하면 각 엔터티마다 트랜잭션을 시작하고 종료해야 합니다. 이는 대용량 데이터를 처리할 때 트랜잭션 오버헤드가 발생할 수 있습니다.
Network Round-Trips
각 save 호출은 데이터베이스로의 네트워크 라운드트립을 유발합니다. 대용량 데이터를 처리할 때는 네트워크 비용이 중요한 요소가 될 수 있습니다.
Hibernate Auto-Flush
Hibernate와 같은 ORM 프레임워크에서는 영속성 컨텍스트가 자동으로 플러시되는데, 이는 개별적인 save 호출마다 발생할 수 있습니다. 이는 대량 처리 시에 불필요한 플러시 작업을 초래할 수 있습니다.
SaveAll()
@Test
@DisplayName("글 등록하기")
public void createPostTest(){
long startTime = System.currentTimeMillis();
List<Post> list = new ArrayList<>();
for (int i =1; i< 100000; i++){
Post post = Post.builder()
.postTitle("title"+i)
.postContent("content"+i+1)
.build();
list.add(post);
}
postRepository.saveAll(list);
System.out.println("taken time = "+(System.currentTimeMillis() - startTime)+"ms");
}
139726ms 기록
saveAll() 메서드가 save() 메서드 보다 효율적인 결과가 나온 이유는 다음과 같습니다.
Batch Processing
대량의 데이터를 처리할 때, saveAll() 메서드는 내부적으로 일괄 처리(batch processing)를 사용할 가능성이 있습니다. 이는 여러 개의 엔터티를 하나의 쿼리로 처리하여 데이터베이스 오버헤드를 줄일 수 있습니다.
예를 들어, Hibernate에서 saveAll()은 내부적으로 JDBC 배치 작업을 사용할 수 있습니다.
Optimized Transaction Management
saveAll()은 여러 개의 엔터티를 하나의 트랜잭션 내에서 처리할 수 있습니다. 이는 개별 save() 호출로 인해 발생하는 트랜잭션 오버헤드를 줄일 수 있습니다.
Minimized Hibernate Session Flushing
대량의 save() 호출은 대량의 영속성 컨텍스트 플러시를 유발할 수 있습니다. saveAll()은 일괄 처리를 통해 플러시 작업을 최소화하고, 한 번의 플러시로 여러 개의 엔터티를 처리할 수 있습니다.
Reduced Network Round-Trips
saveAll()은 여러 엔터티를 한 번에 처리하므로 네트워크 라운드트립 횟수를 감소시킬 수 있습니다. 개별 save() 호출로 인해 발생하는 네트워크 비용이 감소합니다.
Potential Database Optimizations
데이터베이스에 따라서는 일괄 처리를 사용함으로써 최적화된 방식으로 대량의 데이터를 처리할 수 있습니다. 몇몇 데이터베이스는 대량 삽입에 특화된 최적화를 제공합니다.
Reduced Transaction Overhead
saveAll()은 여러 엔터티를 하나의 트랜잭션으로 처리하므로, 각각의 save() 호출로 인한 트랜잭션 오버헤드가 감소합니다.
Bulk Insert
JPA와 MySQL을 사용하는 경우에는 일반적으로 IDENTITY 전략으로 PK 값을 자동으로 증가시켜 생성하는 방식을 사용합니다.
하지만, 이 IDENTITY 방식 때문에 Batch Insert를 JPA에서 사용할 수 없습니다. 이유는 DB에 Insert가 되어야 id 값을 알 수 있다는 JPA의 쓰기지연 특성 때문입니다. 이 특징은 Id 값을 알아야하는 Batch 특성과 충돌하게 됩니다.
그러면 기본키의 전략을 바꾸면 되지 않을까라고 생각도 했지만 이 경우에는 테이블의 구조를 또 변경해야 하는 번거로움이 있습니다.
저는 Spring JDBC를 이용하여 Batch Insert를 실행할 수 있었습니다.
JdbcTemplate에는 Batch를 지원하는 batchUpdate() 메서드를 지원합니다.
application.yml의 MySQL에 Bulk Insert를 사용하기 위해 DB-URL에 아래와 같이 rewriteBatchedStatements=true 파라미터를 추가해야 합니다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?&rewriteBatchedStatements=true
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.DriverBatch Insert가 정확하게 나가는지 확인하고 싶으면 url에 옵션을 추가해주면 됩니다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/db명?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999-
postfileSQL = true : Driver에 전송하는 쿼리를 출력합니다.
-
logger=Slf4JLogger : Driver에서 쿼리 출력 시 사용할 로거를 설정합니다.
- MySQL 드라이버 : 기본값은 System.err로 출력하도록 설정되어 있기 때문에 필수로 지정해 줘야 합니다.
- MariaDB 드라이버 : Slf4j 를 이용하여 로그를 출력하기 때문에 설정할 필요가 없습니다.
-
maxQuerySizeToLog=999999 : 출력할 쿼리 길이
- MySQL 드라이버 : 기본값이 0으로 지정되어 있어 값을 설정하지 않을 경우 아래처럼 쿼리가 출력되지 않습니다.
- MariaDB 드라이버 : 기본값이 1024로 지정되어 있습니다. MySQL 드라이버와는 달리 0으로 지정 시 쿼리의 글자 제한이 무제한으로 설정됩니다.
@Repository
@RequiredArgsConstructor
public class PostBulkRepository {
private final JdbcTemplate jdbcTemplate;
@Transactional
public void saveAll(List<Post> postList){
String sql = "INSERT INTO test_table (title, content)"+
"VALUES (?, ?)";
jdbcTemplate.batchUpdate(sql,
postList,
postList.size(),
(PreparedStatement ps, Post post) -> {
ps.setString(1, post.getTitle());
ps.setString(2, post.getContent());
});
}
}테스트코드는 아래와 같이 작성했습니다.
@Test
public void createPostBulkTest(){
long startTime = System.currentTimeMillis();
List<Post> list1 = new ArrayList<>();
for (int i =1; i< 100000; i++){
Post post = Post.builder()
.postTitle("title"+i)
.postContent("content"+i+1)
.build();
list1.add(post);
}
postBulkRepository.saveAll(list1);
System.out.println("taken time = "+(System.currentTimeMillis() - startTime)+"ms");
}
3673ms 를 기록하였습니다.
save() 메서드에 비해 시간 차이가 약 86배 정도로 꽤나 많은 효과를 볼 수 있습니다.
참고
https://dkswnkk.tistory.com/682
https://velog.io/@ssuh0o0/Spring-JPA%EC%97%90%EC%84%9C-save%EC%99%80-saveAll-%EB%B9%84%EA%B5%90
활용 결과
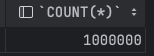
저는 현재 Mysql FullText Search 기능 테스트 때문에 Mysql에 초기데이터 셋팅이 필요했습니다.
따라서 위의 내용을 토대로 작업을 진행한 결과 100만건 초기데이터 셋팅에 대해 다음 결과를 얻을 수 있었고 data faker를 통해 랜덤 문장 생성까지 완료 하였습니다.