CKA 자격증 취득을 위해서 유명한 그 강의(Certified Kubernetes Administrator CKA)를 들으면서 공부한 내용을 정리하려고 한다.
Kubernetes Architecture
클러스터의 구성 요소를 설명하기 위해 선박(ship)을 비유로 사용하겠습니다. 쿠버네티스의 목적은 자동화된 방식으로 컨테이너 형태로 애플리케이션을 호스팅하여 애플리케이션 내의 서로 다른 서비스 간에 쉽게 통신 가능하고, 애플리케이션의 많은 인스턴스를 쉽게 배포할 수 있도록 하는 것입니다. 이 목적을 달성하기 위해 함께 작동하는 많은 것들이 있습니다.
쿠버네티스 아키텍처를 10,000피트 정도 떨어져서 본다고 합시다. 두 종류의 선박이 있다고 가정합니다. 하나는 실제 바다를 건너 컨테이너를 운반하는 화물선 선박이고, 다른 하나는 모니터링하고 화물선을 관리하는 control(제어) 선박 입니다.
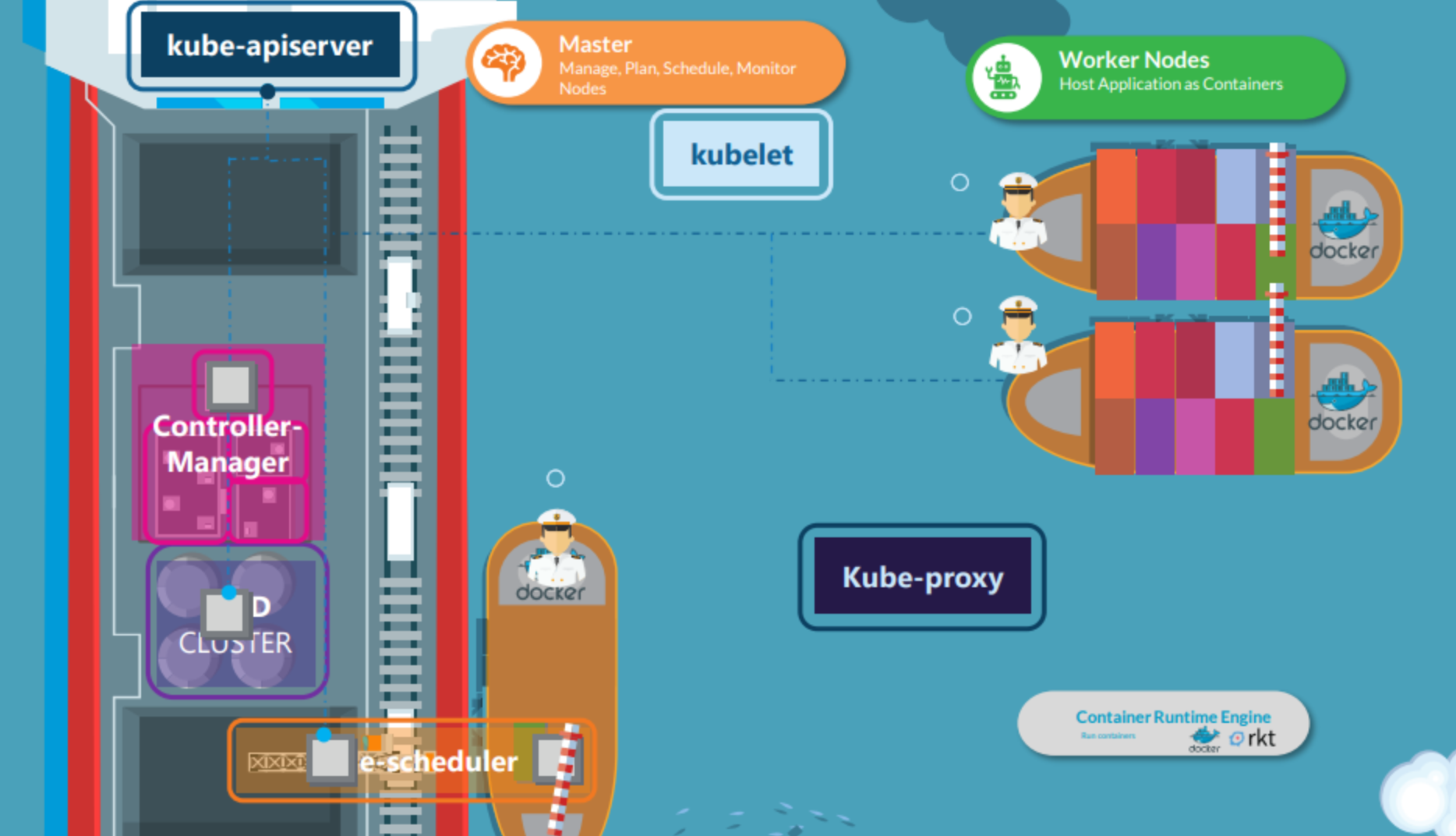
쿠버네티스 클러스터는 일련의 노드로 구성됩니다. 이 노드는 물리적일 수도 있고, 가상일 수도 있습니다. 온프레미스일 수도 있고 클라우드일 수도 있습니다. 노드들은 컨테이너 형태로 애플리케이션을 호스팅합니다.
Master Nodes
클러스터의 워커 노드는 컨테이너를 실을 수 있는 선박입니다. 하지만 누군가가 컨테이너를 실어주어야 합니다. 단순히 싣는 것 뿐만이 아니라 컨테이너를 싣는 방법을 계획하고, 올바른 선박을 식별하고, 선박에 대한 정보를 저장하고, 선박에 들어간 컨테이너의 위치를 모니터링하고 추적하는 등 전체 선적 프로세스를 관리하는 역할이 필요합니다. 이 역할을 수행하는 것이 제어 선박(마스터 노드)입니다.
제어 선박은 서로 다른 사무실과 부서, 모니터링 장비, 통신 장비, 선박 사이에서 컨테이너를 옮기는 크레인 등을 호스팅합니다. 제어 선박은 쿠버네티스 클러스터의 마스터 노드와 관련이 있습니다. 마스터 노드의 역할은 쿠버네티스 클러스터를 관리하고, 다른 노드에 대한 정보를 저장하고, 어떤 컨테이너가 어디로 갈지 계획하고, 노드와 컨테이너들을 모니터링 합니다. 마스터 노드는 이 모든 작업들을 control playing components 라고 알려진 컴포넌트들의 집합을 사용하여 수행합니다.
ETCD Cluster
이제 마스터노드의 각 컴포넌트들을 살펴보겠습니다. 매일 많은 컨테이너가 적재되고 내려지고 있습니다. 이 때 다른 선박들에 대해서, 그리고 어떤 컨테이너가 어떤 선박에 있는 지, 적재된 시간 등 모든 정보를 유지관리해야 합니다. 이 정보들은 etcd라는 highly available key value store에 있습니다. etcd는 정보를 키 값 형식으로 저장하는 데이터베이스입니다. etcd 클러스터가 실제로 무엇인지 뒤에 올 강의에서 자세히 살펴보겠습니다.
kube-scheduler
선박이 도착하면 크레인을 사용하여 컨테이너를 적재합니다. 크레인은 배에 실어야 할 컨테이너를 골라냅니다. 또한 크레인은 선박의 크기, 용량, 선박에 이미 있는 컨테이너의 수, 배의 목적지, 실을 수 있는 컨테이너의 유형 등을 고려하여 올바른 선박을 고릅니다.
이 비유에서의 크레인은 쿠버네티스 클러스터의 스케쥴러입니다. 스케쥴러는 containers resource requirements, 워커 노드 용량, taints와 같은 기타 정책이나 제약조건 & 허용조건, 노드 우선순위 규칙 을 참고하여 컨테이너를 배치할 올바른 노드를 선택합니다.
Controller-Manager
부두(dock)에는 특별한 작업이나 부서에 할당된 사무실들이 있습니다. 예를 들어 운영팀은 선박 취급, 교통 통제 등 피해와 관련된 문제와 다른 배가 가는 경로 등을 다루고 있으며, 화물팀은 컨테이너가 훼손된 경우 새 컨테이너를 사용할 수 있는지 확인합니다. 서비스팀은 다른 선박 간의 IT 통신을 관리합니다.
Node-Controller
마찬가지로 쿠버네티스에는 다양한 영역을 관리하는 컨트롤러가 있습니다. 노드 컨트롤러는 노드를 관리합니다. 새 노드를 클러스터에 온보딩하는 일을 담당하거나, 노드를 사용할 수 없거나 파괴되는 상황을 다룹니다.
Replication-Controller
replication 컨트롤러는 항상 원하는 수의 컨테이너가 replication 그룹에서 실행중이라는 것을 보장합니다.
kube-apiserver
사무실, 선박, 데이터 저장소, 크레인 등 서로 다른 컴포넌트들은 어떻게 통신할까요? 이런 컴포넌트들을 누가 하이레벨에서 관리할까요? Kube API 서버는 쿠버네티스의 기본 관리 컴포넌트입니다.
Kube API 서버는 클러스터 내의 모든 작업을 오케스트레이션합니다. Kube API 서버는 클러스터에서 관리 작업을 수행하기 위해 외부 사용자가 사용하는 쿠버네티스 API를 노출합니다. 뿐만 아니라, 클러스터의 상태를 모니터링하고 필요에 따라 필요한 사항을 변경하기 위해 다양한 컨트롤러들도 노출합니다. 그리고 워커노드가 서버와 통신합니다.
지금 우리는 컨테이너로 작업하고 있습니다. 컨테이너는 어디에나 있으며 우리는 모든 것을 컨테이너와 호환해야 합니다. 우리의 애플리케이션은 컨테이너 형태입니다. 마스터 노드의 전체 관리 시스템에 있는 다양한 컴포넌트들은 컨테이너 형태로 호스팅 될 수 있습니다. DNS서비스 네트워킹 솔루션은 모두 컨테이너 형태로 배포될 수 있습니다.
따라서 컨테이너를 실행(run)할 수 있는 소프트웨어가 필요합니다. 이것이 컨테이너 런타임 엔진입니다. 그 중 인기 있는 것이 도커 입니다. 따라서 제어 컴포넌트를 컨테이너로 호스팅하기 위해서는 마스터 노드를 포함한 클러스터의 모든 노드에 도커나 다른 지원되는 런타임 엔진이 필요합니다. 항상 도커일 필요는 없습니다. 쿠버네티스는 ContainerD, Rocket과 같은 다른 런타임 엔진도 지원합니다.
Worker Nodes
이제 화물선 선박(워커 노드)에 초점을 맞추겠습니다.
kubelet
모든 배에는 선장이 있습니다. 선장은 선박의 모든 활동을 관리합니다. 마스터 선박과의 연락을 담당하여 선장의 선박이 그룹 참여에 관심이 있다는 것을 마스터 선박(제어 선박)에 알게하고, 선박에 적제되는 컨테이너에 대한 정보 수신, 필요에 따라 적절한 컨테이너를 적재하고 마스터 선박에게 이 배의 상태와 선박의 컨테이너 상태에 대한 보고서를 다시 보내는 등을 가능하게 합니다.
배의 선장은 Kubernetes의 Kubelet입니다. kubelet은 클러스터의 각 노드에서 실행되는 에이전트입니다. Kube API 서버의 지시를 수신하고 필요에 따라 노드에 컨테이너를 배포하거나 제거합니다. KubeAPI서버는 kubelet으로부터 노드와 컨테이너의상태를 모니터링한 상태 보고서를 주기적으로 가져옵니다.
kube-proxy
kubelet이 컨테이너를 관리하는 선박의 선장의 역할을 하지만, 워커 노드에서 실행되는 어플리케이션들도 서로 소통해야 합니다. 예를 들어 한 컨테이너의 노드중 하나에서 웹 서버가 실행중이라고 합시다. 그리고 데이터베이스 서버가 다른 컨테이너의 다른 노드에서 실행 중입니다. 웹 서버는 어떻게 다른 노드에 있는 데이터베이스 서버에 접근할 수 있을까요? 워커 노드 간 통신이 워커 노드에 있는 다른 컴포넌트인 Kube Proxy Service 에 의해 가능합니다. Kube Proxy Service는 그 워커 노드에 있는 컨테이너들이 서로 접근 할 수 있도록 하는 필수 규칙이 워커 노드에 있는지를 확인합니다.
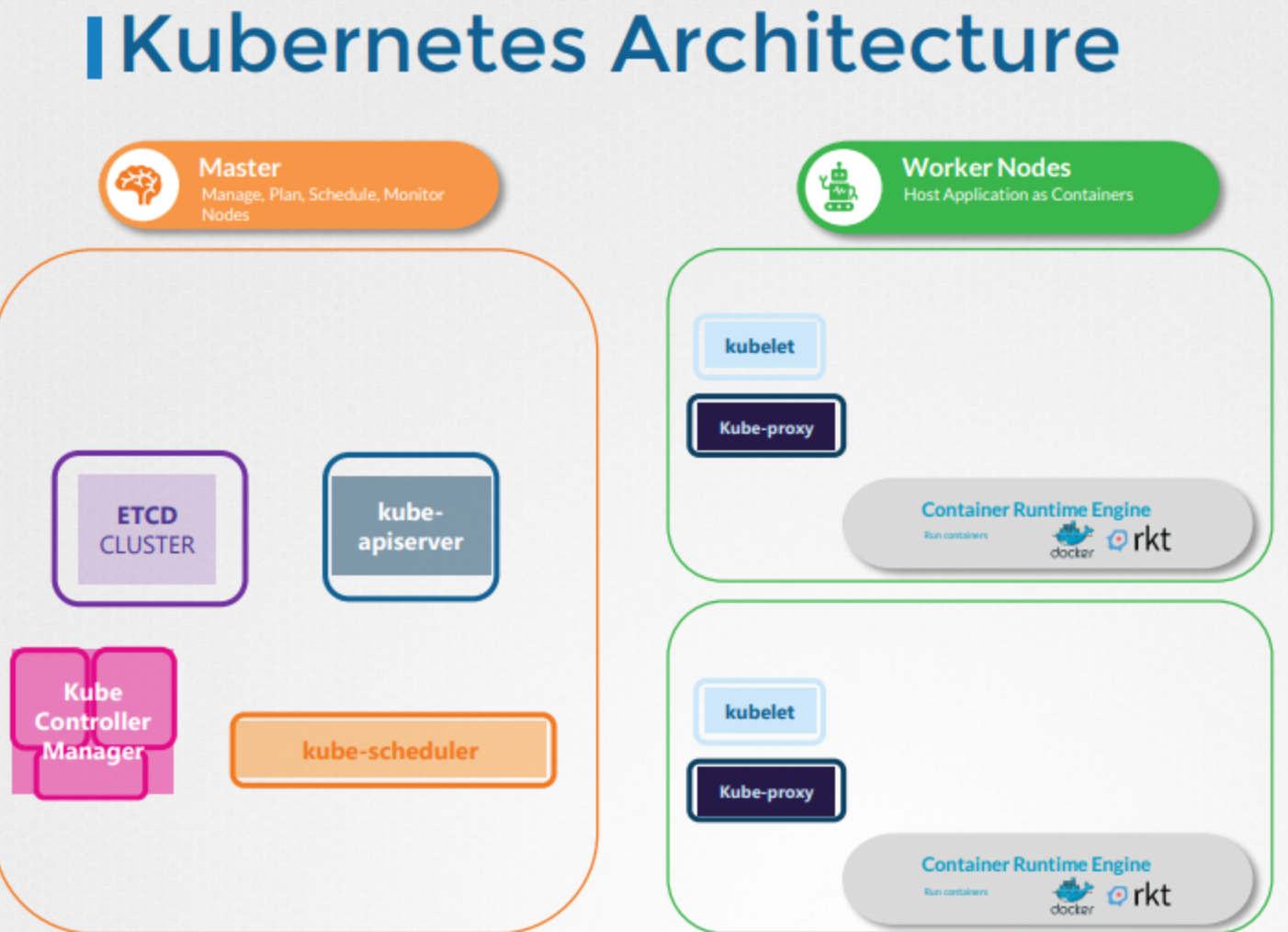
요약하자면, 마스터 노드와 워커 노드가 있습니다.
마스터 노드에는 ETCD클러스터가 있습니다. ETCD클러스터는 클러스터에 대한 정보를 저장합니다. 마스터 노드에는 kube-scheduler도 있었습니다. kube-scheduler는 노드들의 어플리케이션이나 컨테이너들을 스케쥴링합니다. 또한 노드 컨트롤러, replication 컨트롤러 등 다양한 기능을 하는 다양한 컨트롤러가 있었습니다. 또한 클러스터 내의 모든 작업을 오케스트레이션하는 KubeAPI서버도 있었습니다.
워커 노드에는 KubeAPI의 지시를 대기하는 kubelet이 있습니다. kubelet은 컨테이너들과 Kube proxy를 관리하기도 합니다. Kube proxy는 클러스터 내의 서비스 간 통신을 가능하게 도와줍니다.
ETCD 가 뭔데 ?
ETCD
ETCD는 간단하고 안전하고 빠른, 신뢰할 수 있는 key-value store 입니다.
전통적인 데이터베이스
전통적인 데이터베이스는 표 형식입니다. SQL 혹은 데이터를 행과 열의 형태로 저장하는 관계형 데이터베이스에 대해 들어 보셨을 것입니다. 아래 표를 예로 들어 보겠습니다.
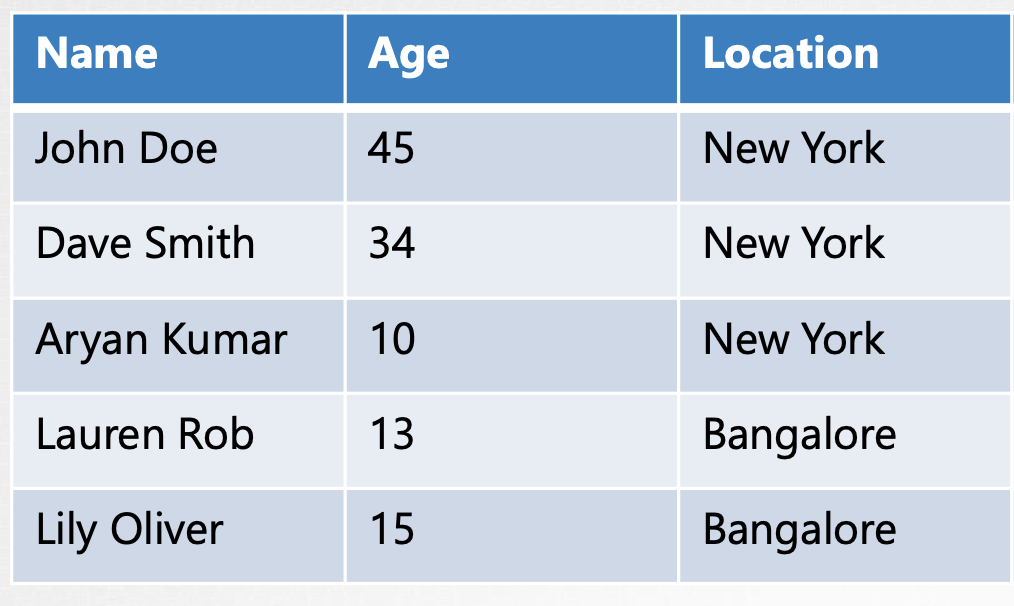
표에는 몇몇 사람들에 대한 정보가 저장되어 있습니다. 행은 각 사람을 나타냅니다. 열은 저장되는 정보의 유형을 나타냅니다. 이제 우리는 여기에 추가 정보를 추가하고 싶습니다. 예를 들어 급여 정보를 추가하고 싶으면, 우리는 열을 하나 추가하고 급여정보를 채워 넣습니다. 표에 있는 모든 사람들이 일을 하지는 않기 때문에 급여 정보는 비어 있을 수 있습니다. 급여 정보 말고 성적 정보도 추가하고 싶습니다. 따라서 새 열을 추가하고, 학생인 사람들의 성적 정보를 채워 넣습니다.
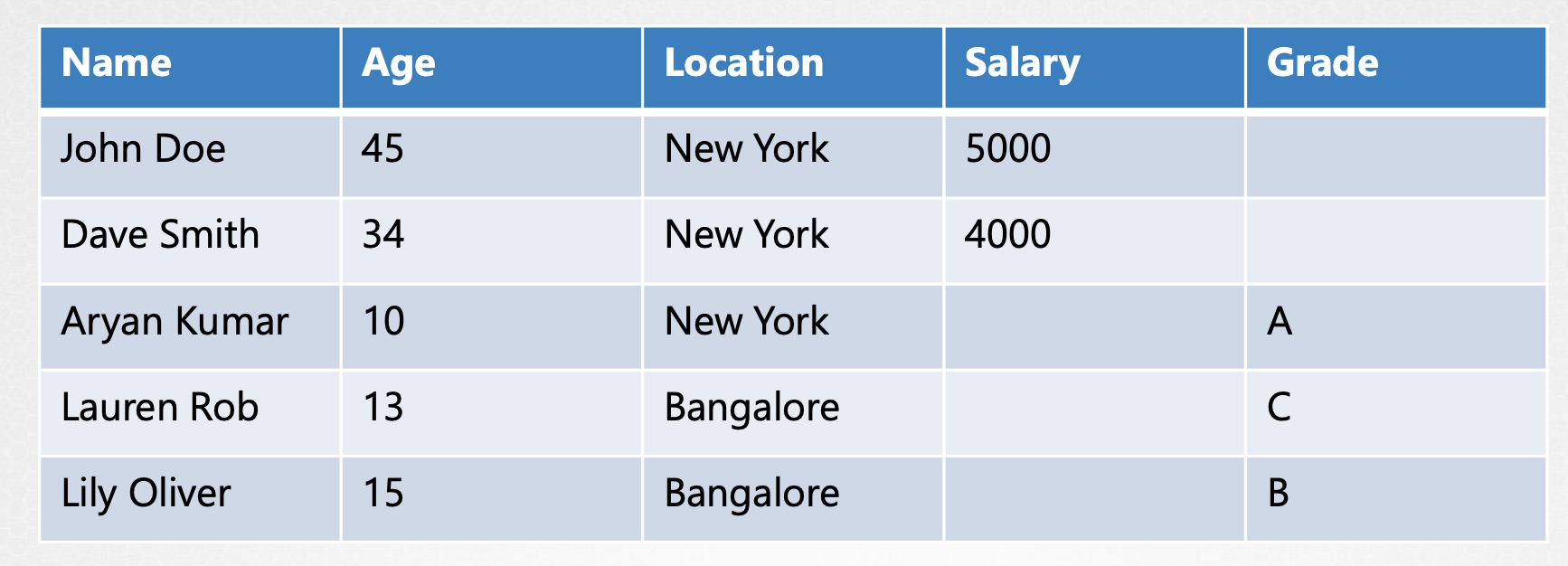
이렇게 새로운 정보를 추가해야 할 때마다 테이블 전체가 영향을 받고, 빈 셀도 많아집니다.
key-value store
key-value store는 문서 또는 페이지의 형태로 정보를 저장합니다. 위에서 다룬 사람들의 정보를 key-value store로 표현한다면, 각 개인의 정보는 하나의 파일에 있는 문서에 저장됩니다.
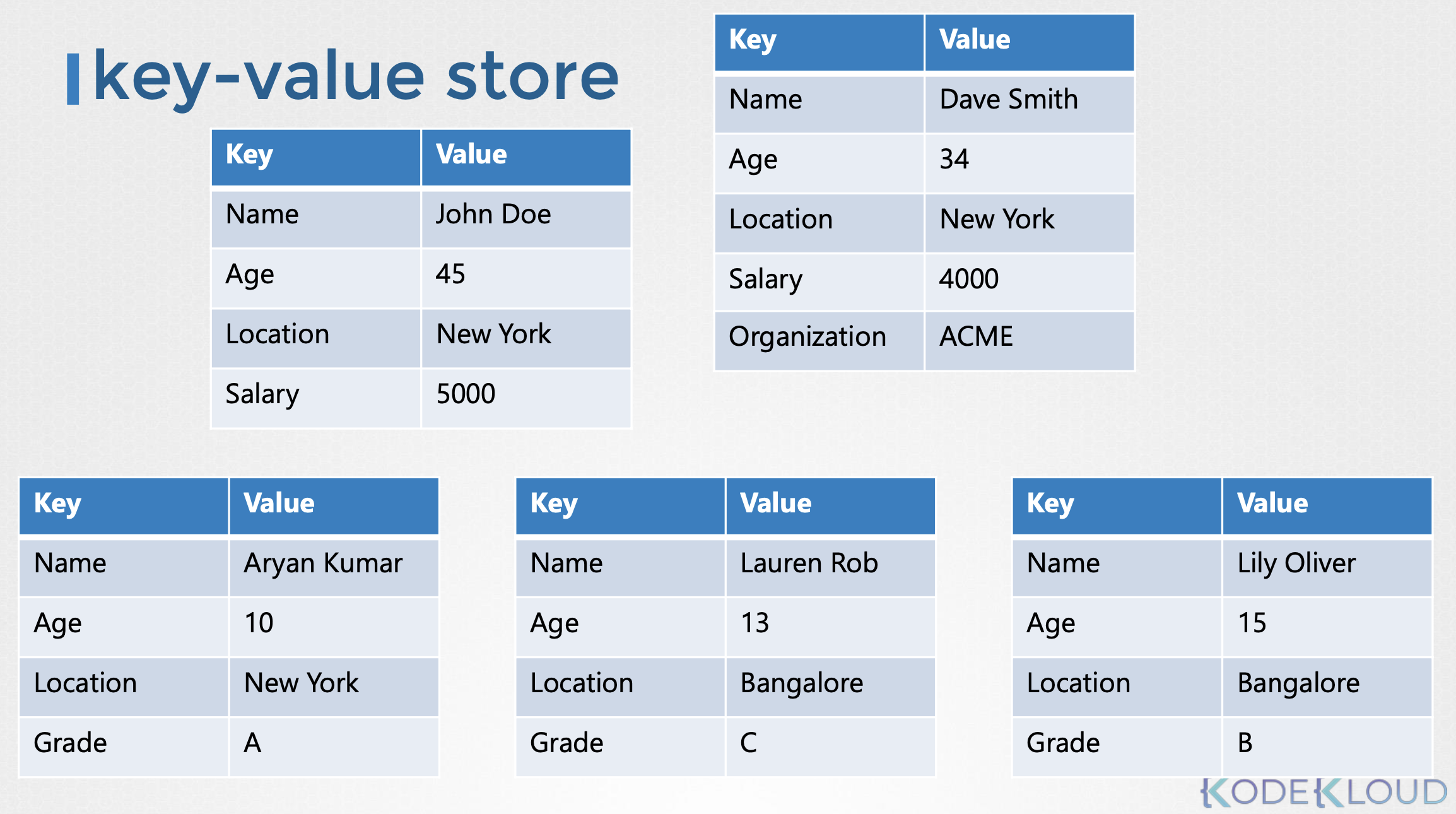
이러한 파일은 어떤 형식이나 구조이든지 상관없습니다. key-value 저장방식을 사용하면, 한 파일을 변경해도 다른 파일에는 영향을 미치지 않습니다. 일하는 사람의 파일에는 급여 필드가 있으며, 학생의 파일에는 성적 필드가 있습니다. 각 파일에 다른 정보를 추가할 수 있습니다. 이때 전통적인 데이터베이스와는 달리 해당 파일만 변경되고 다른 파일은 업데이트되지 않습니다. 간단한 키와 값을 저장하고 검색할 수 있지만 데이터가 복잡해지면 일반적으로 JSON 또는 YANO 와 같은 데이터 형식을 사용하는 것이 좋습니다.

그래서 ETCD 가 뭔데 ?
etcd는 클러스터에 대한 정보를 저장하는 데이터 저장소입니다. 어떤 정보들이 있을까요? Nodes, PODS, Configs, Secrets, Accounts, Roles, Role Bindings등이 있습니다.
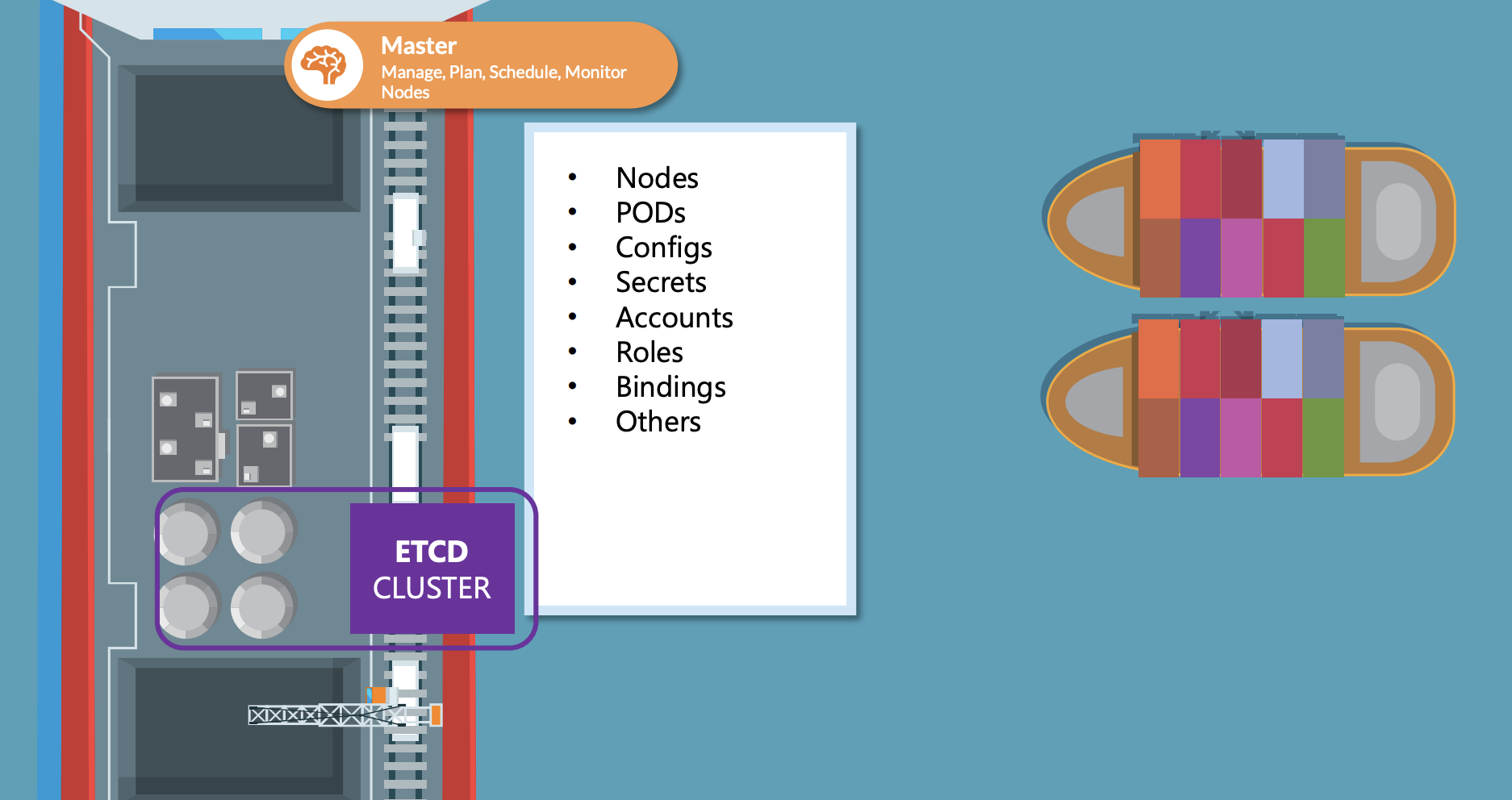
kube control get 명령을 실행할 때 우리가 볼 수 있는 정보는 모두 etcd 서버에서 가져온 것들입니다. 노드 추가, pod 나 replica sets 배포와 같은 클러스터에 대한 모든 변경사항들이 etcd서버에서 업데이트됩니다. etcd 서버에 딱 한 번만 업데이트 되는 것이 있는데 그것은 바로 complete하는 변경사항입니다.
클러스터를 어떻게 설정하느냐에 따라 etcd는 다르게 배포됩니다.
-
scratch로부터의 배포
-
Qadium 툴을 사용하여 배포
Setup - Manual
클러스터를 scratch 설정하는 경우, etcd바이너리를 직접 다운로드 하여 etcd를 deploy하고, 바이너리를 설치하여 etcd를 직접 마스터 노드에서 서비스로 구성합니다.
wget -q --https-only "https://github.com/etcd-io/etcd/releases/download/v3.3.11/etcd-v3.3.11-linux-amd64.tar.gz"서비스에 전달되는 많은 옵션들이 있습니다. 그 중 다수는 인증서와 관련이 있습니다.
Kubernetes에서 high availability를 설정할 때 해당 옵션들을 살펴보겠습니다. 지금 주목할 유일한 옵션은 advertised client URL입니다.
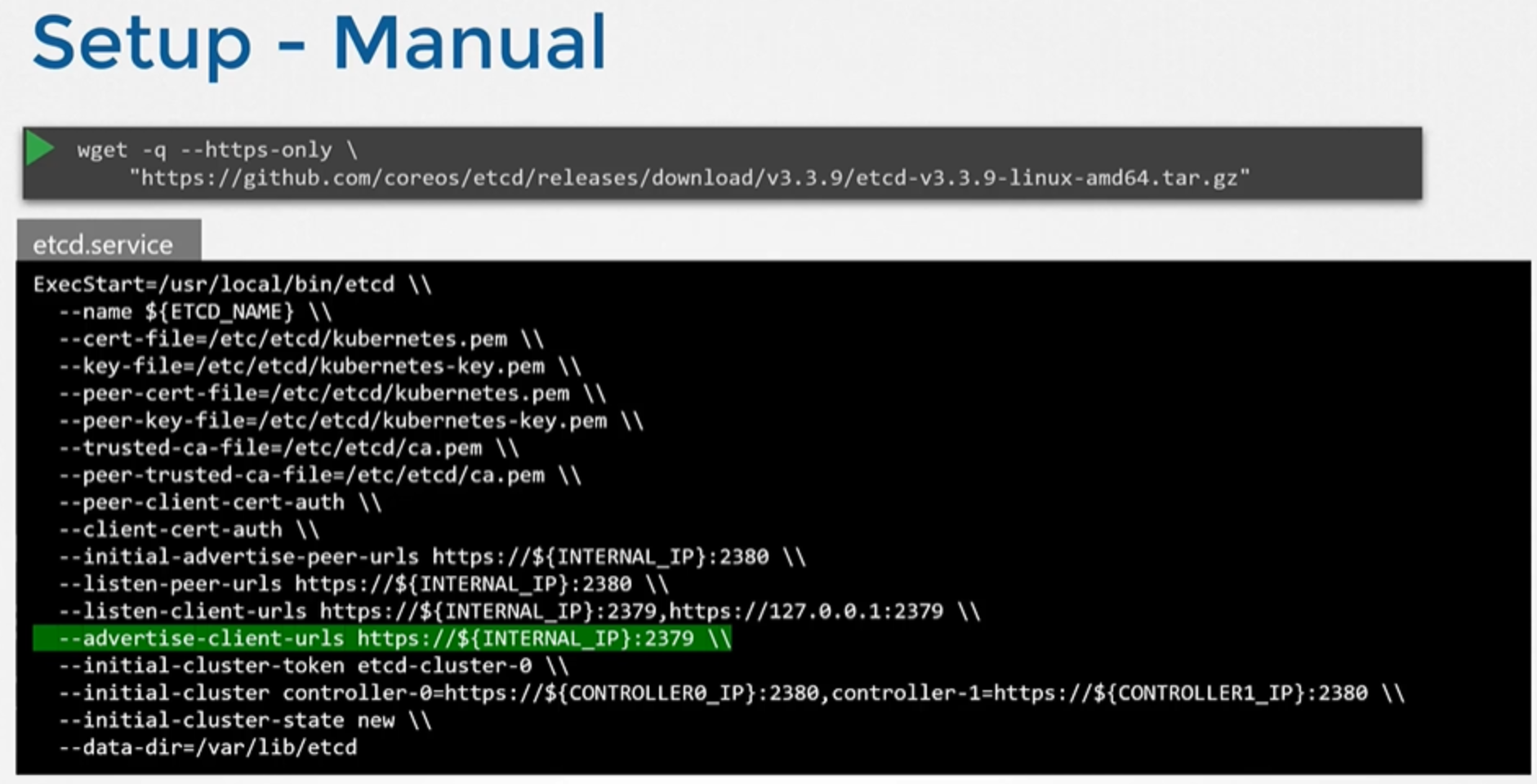
이것은 etcd가 대기(listens)하고 있는 주소입니다. 서버 ip와 2379포트로 구성되어 있는데, 2379포트는 etcd가 대기하는 디폴트 포트입니다. 이 URL은 kube API 서버에서 etcd 서버에 접근하려고 할 때 구성되어 있어야 합니다.
Setup - kubeadm
kubeadm을 사용하여 클러스터를 설정하는 경우, kubeadm이 etcd서버를 kube 시스템 네임스페이스 안의 파드로 배포합니다.
kubectl get pods -n kube-system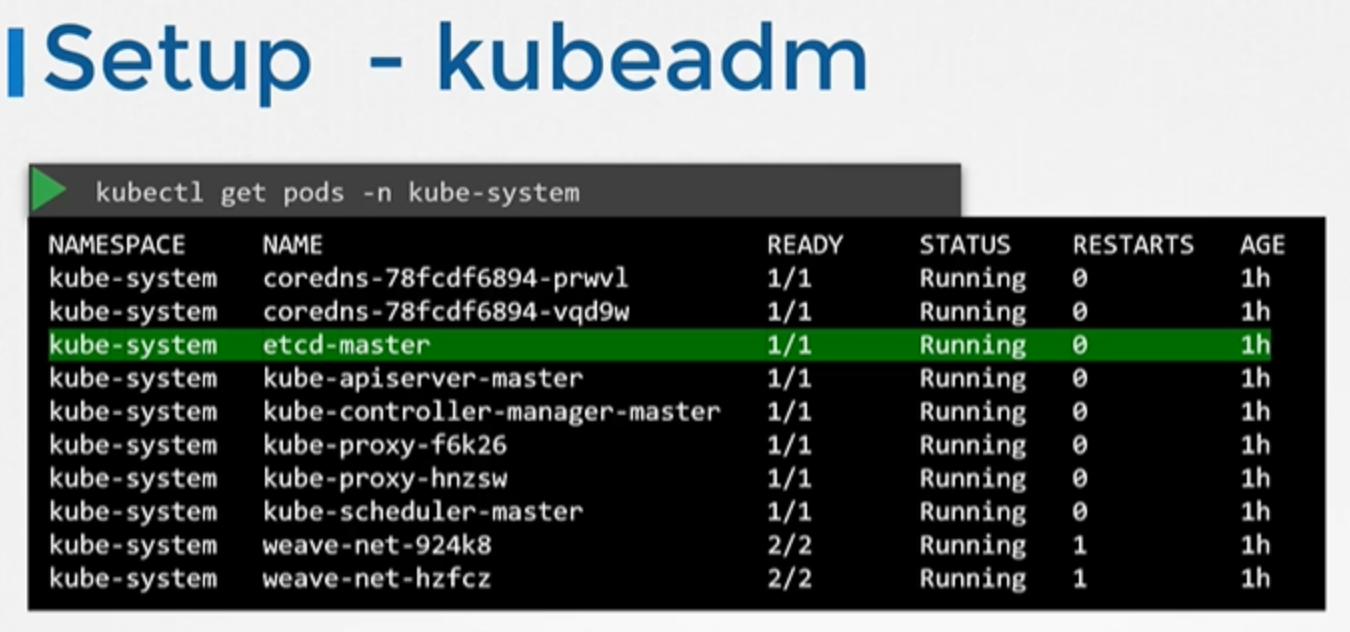
Explore ETCD
etcd 데이터베이스를 탐색할 수 있습니다. 이 파드 내에서 etcd control utility를 사용하여 etcd database를 탐색할 수 있습니다. Kubernetes에 저장된 모든 키를 나열하려면 다음과 같이 etcd control get 명령을 실행하면 됩니다.
etcdctl get / --prefix -keys-only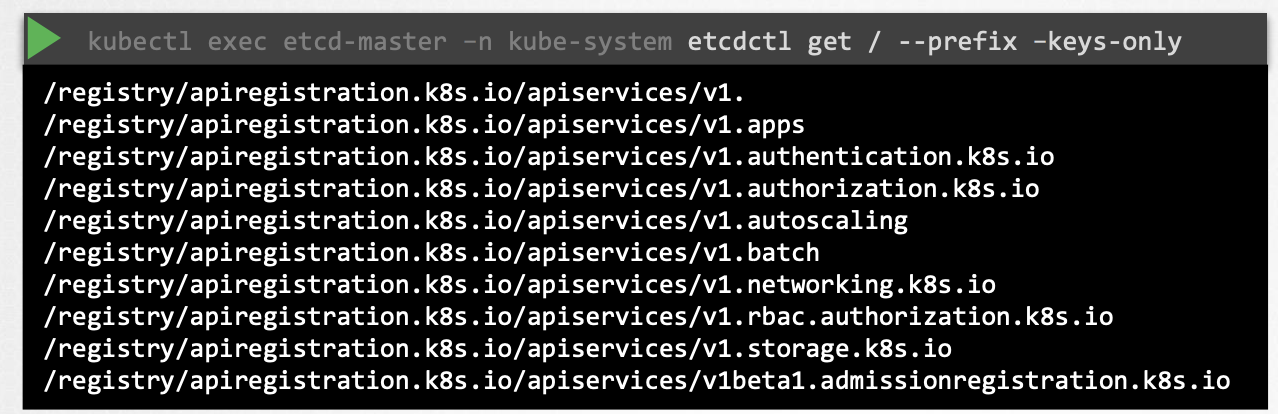
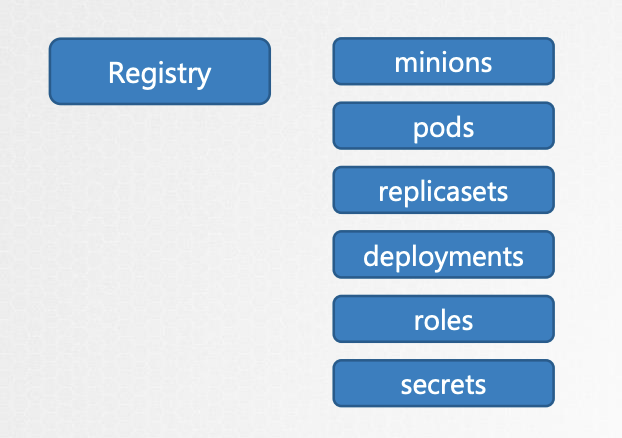
쿠버네티스는 특정 디렉토리 구조로 데이터를 저장합니다. 루트 디렉토리는 Registry이며 그 아래에 minions, pods, replicasets, deployments, roles, secrets 등 다양한 Kubernetes 구성이 있습니다.
ETCD in HA Environment
high availability 환경에서는 클러스터에 여러 마스터 노드가 있습니다. 그리고 마스터 노드들에 분산된 여러 etcd 인스턴스를 갖게 됩니다. 이때, etcd 서비스 구성에서 파라미터를 잘 설정하면 etcd 인스턴스가 서로에 대해 알게 됩니다. --initial-cluster 옵션에 etcd 서비스의 다른 인스턴스를 지정하면 됩니다.

Kube API Server
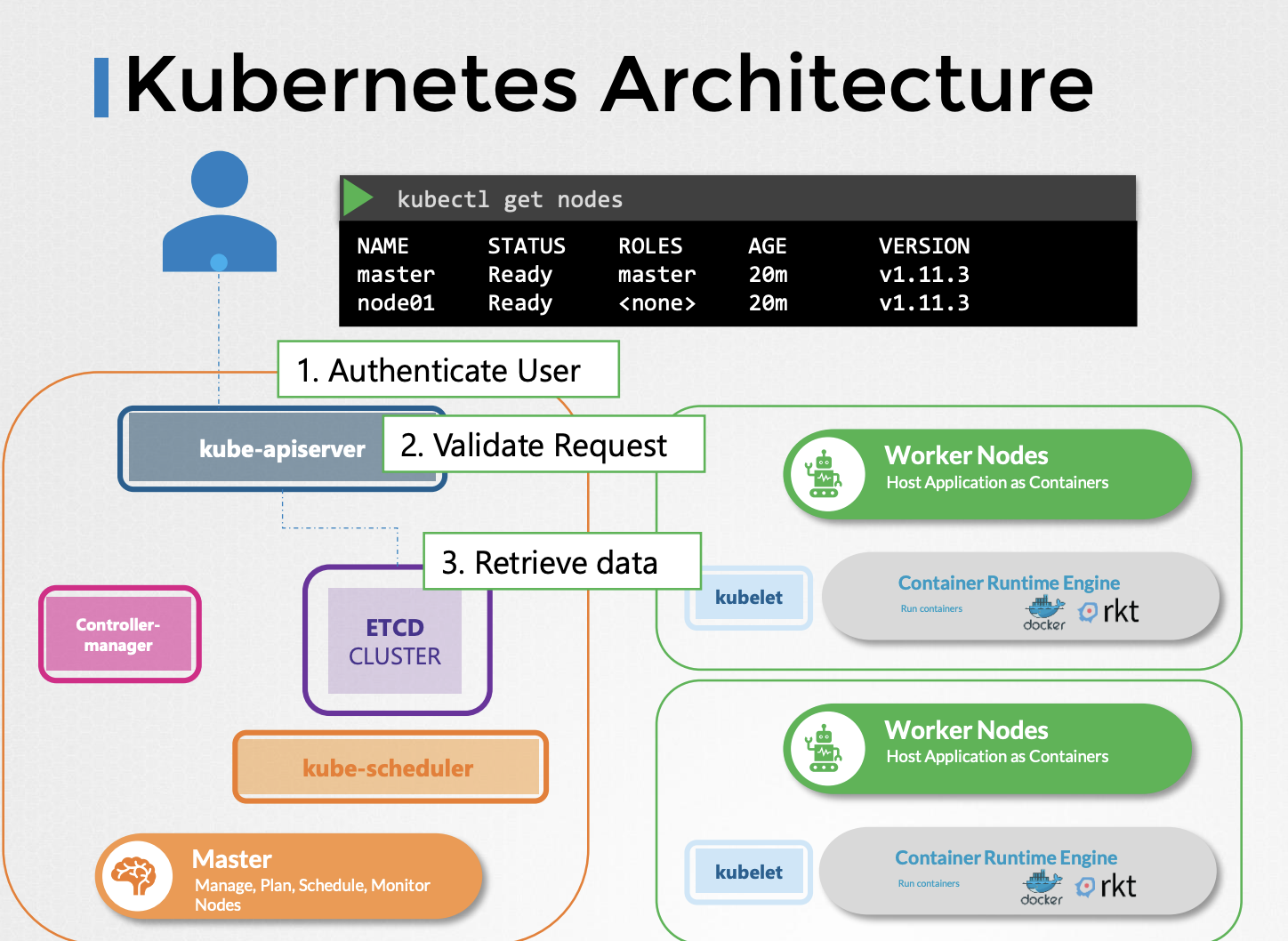
kubectl 명령을 실행하면, kubectl 유틸리티는 실제로 kube-apiserver에 접근합니다. kube-apiserver는 가장 먼저 요청을 인증하고 검증합니다. 그런 다음 etcd 클러스터로부터 데이터를 받아서 다시 요청한 정보와 함께 응답합니다.
반드시 kubectl 명령어를 사용할 필요는 없습니다. 대신 POST 리퀘스트를 보내서 API를 직접 호출할 수도 있습니다.
파드를 생성하는 것을 예로 살펴보겠습니다.
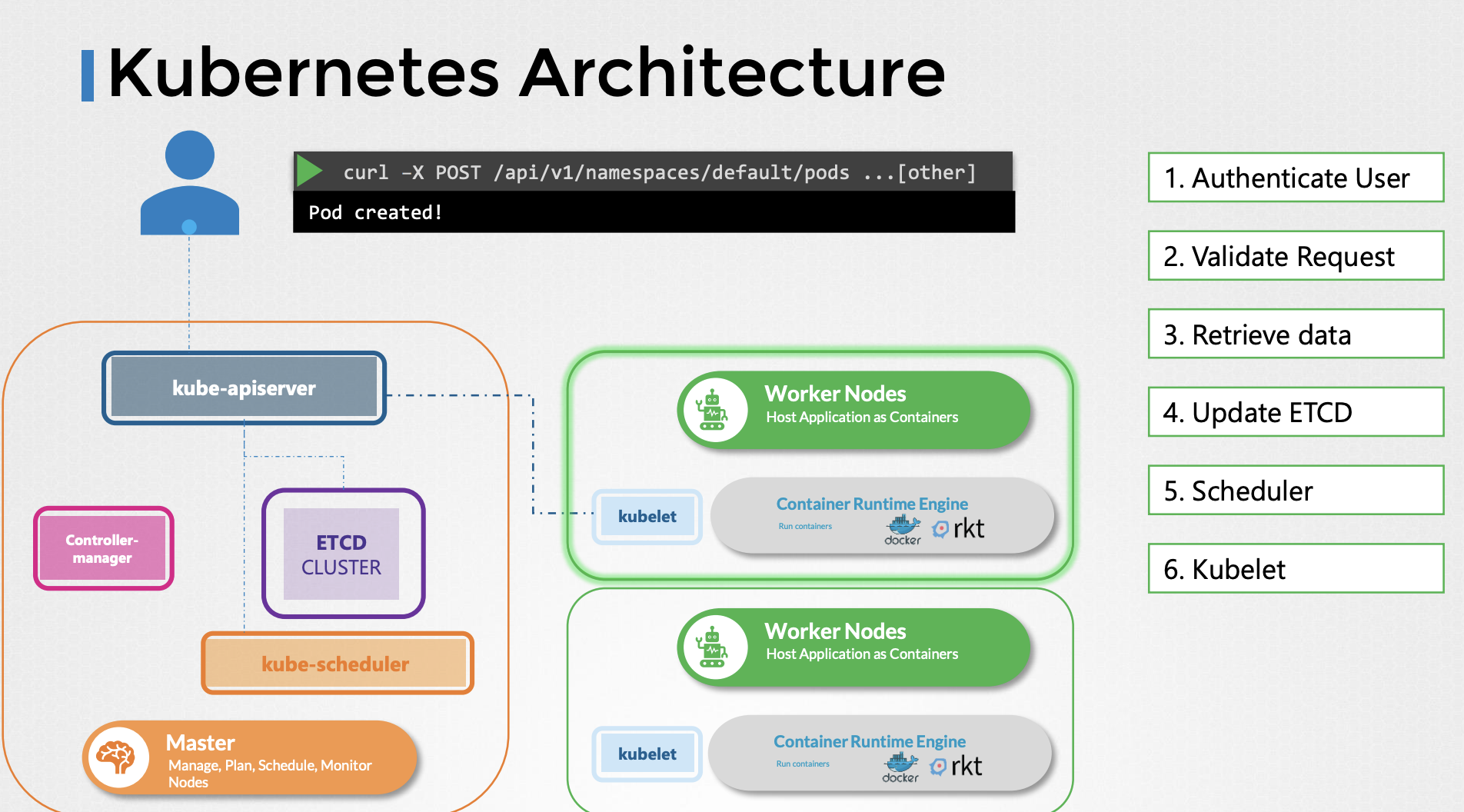
먼저 요청이 인증된 다음 검증됩니다. 이 경우 API서버는 파드 객체를 노드에 할당하지 않고 생성합니다. 그리고 etcd 서버에 있는 '파드를 생성한 사용자' 정보를 업데이트 합니다. 스케쥴러는 API서버를 지속적으로 모니터링 하다가 노드가 할당되지 않은 새로운 파드가 있는 것을 발견합니다. 스케쥴러는 새 파드를 배치하기 위해 좋은 노드를 골라내고 이를 다시 kube-apiserver에 전달합니다. 그러면 API서버가 etcd 클러스터의 정보를 업데이트합니다.
API 서버는 업데이트된 정보를 적절한 워커 노드의 kubelet에 전달합니다. 그러면 kubelet이 해당 노드에서 파드를 생성하고 컨테이너 런타임 엔진에 어플리케이션 이미지를 배포하라고 지시합니다.
완료되면 kubelet이 API 서버로 상태를 업데이트하고 API 서버는 ETCD 클러스터의 데이터를 업데이트합니다.
이 패턴은 변경이 요청될 때마다 비슷하게 나타납니다. kube-api서버가 클러스터를 변경하기 위한 모든 작업의 중심에 있습니다. 요약하자면 kube-apiserver는 인증과 요청 검증을 담당하며, etcd data store의 데이터를 받아오고 업데이트합니다. 사실, kube-apiserver는 etcd data store 와 직접 소통하는 유일한 컴포넌트입니다. 스케쥴러, kube-controller-mangager, kublet과 같은 다른 컴포넌트들은 클러스터 내의 각자의 영역에서 api server를 사용하여 업데이트를 수행합니다.
Installing kube-apiserver
kubeadmin 툴을 사용해서 클러스터를 부트스트랩 한 경우, 이것을 알 필요는 없습니다. 그러나 하드웨어를 세팅했다면 Kubernetes 릴리즈 페이지의 바이너리를 통해 kube-apiserver를 사용할 수 있습니다. 바이너리를 다운로드하고 Kubernetes 마스터 노드에서 서비스로 실행되도록 구성하면 됩니다.
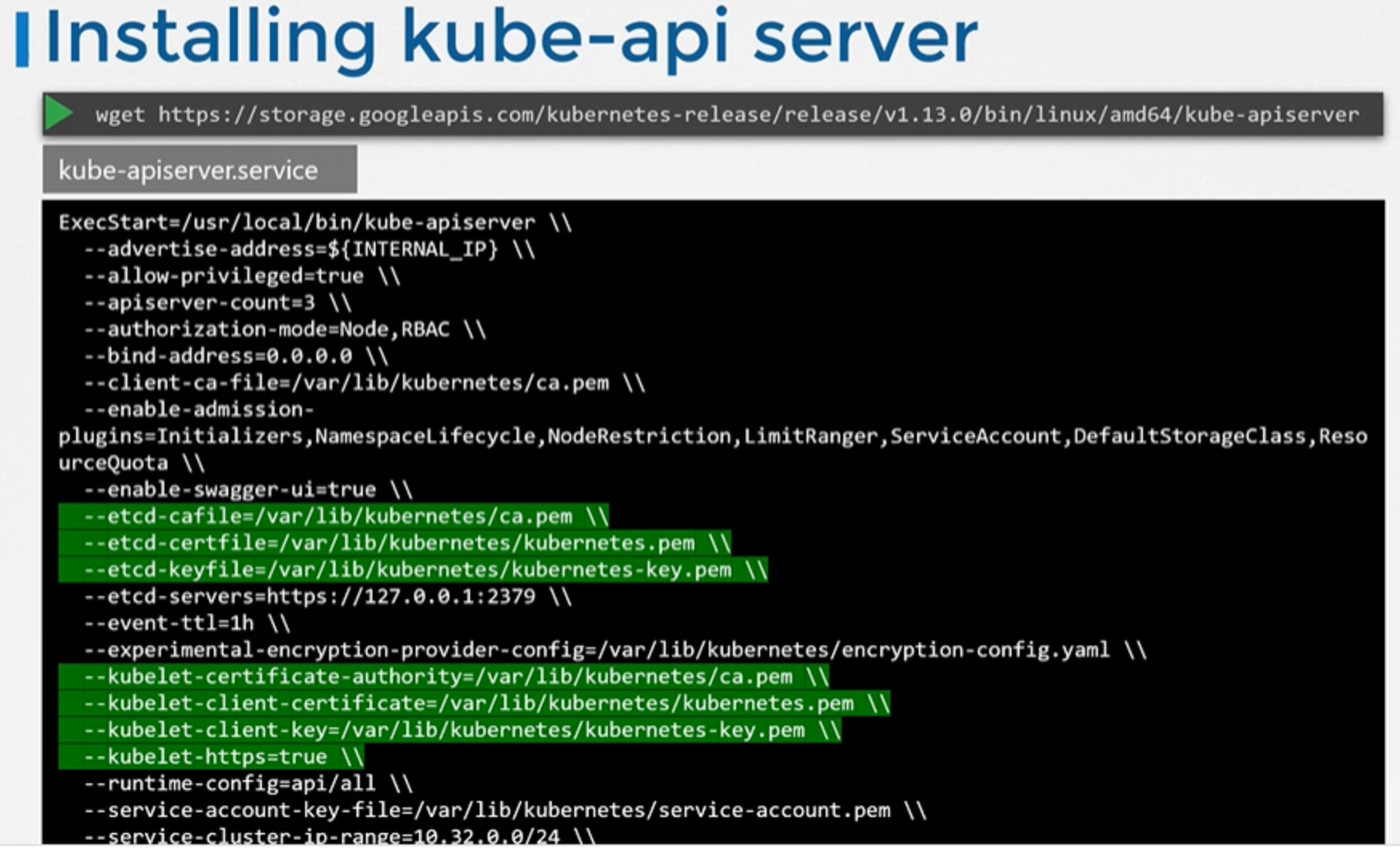
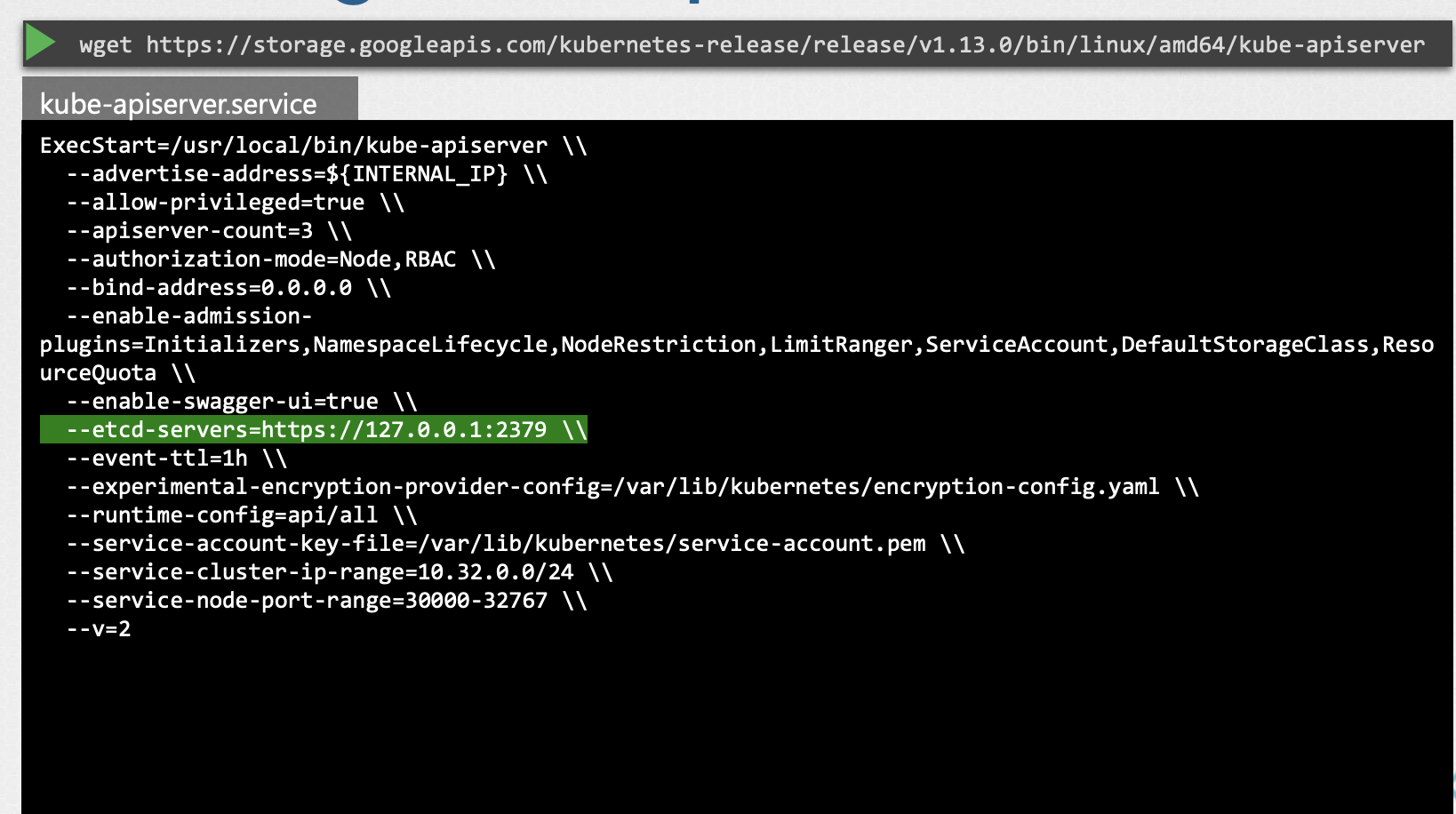
Kubernetes 아키텍처는 여러 방법으로 서로 소통하는 다양한 컴포넌트로 이루어져있습니다. 따라서 컴포넌트들 모두 다른 컴포넌트가 어디에 있는지 알아야 합니다. 인증, 승인, 암호화, 보안에는 다양한 방식이 있습니다. 따라서 옵션들도 굉장히 많습니다. —etcd-servers 옵션은 etcd서버의 위치를 지정합니다. kube-apiserver는 etcd 서버 옵션을 통해 etcd서버와 연결됩니다.
View kube-apiserver - Kubeadm
그렇다면 기존 클러스터에서 kube-apiserver옵션은 어떻게 확인할까요? 이는 클러스터를 설정하는 방법에 따라 다릅니다.
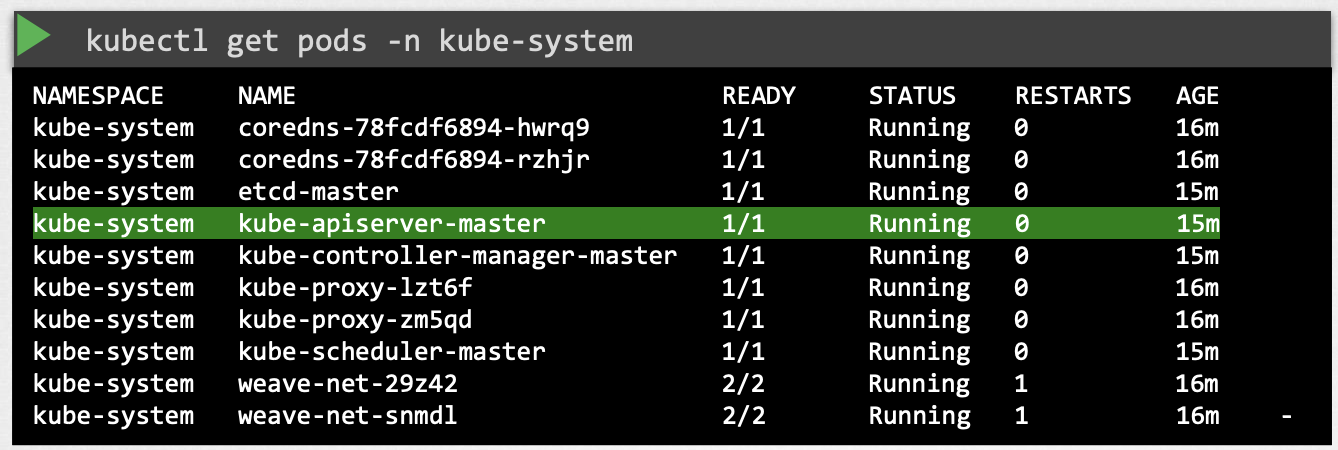
kubeadmin툴로 세팅했다면, kubeadmin은 마스터노드에 잇는 kube-system namespace의 파드로 kubeadmin-apiserver를 배포합니다.
View kube-apiserver options - Kubeadm
파드 definition file에서 옵션들을 볼 수 있습니다. 파드 definition file은 etc/kubernetes/manifests 폴더에 있습니다.
cat /etc/kubernetes/manifests/kube-apiserver.yaml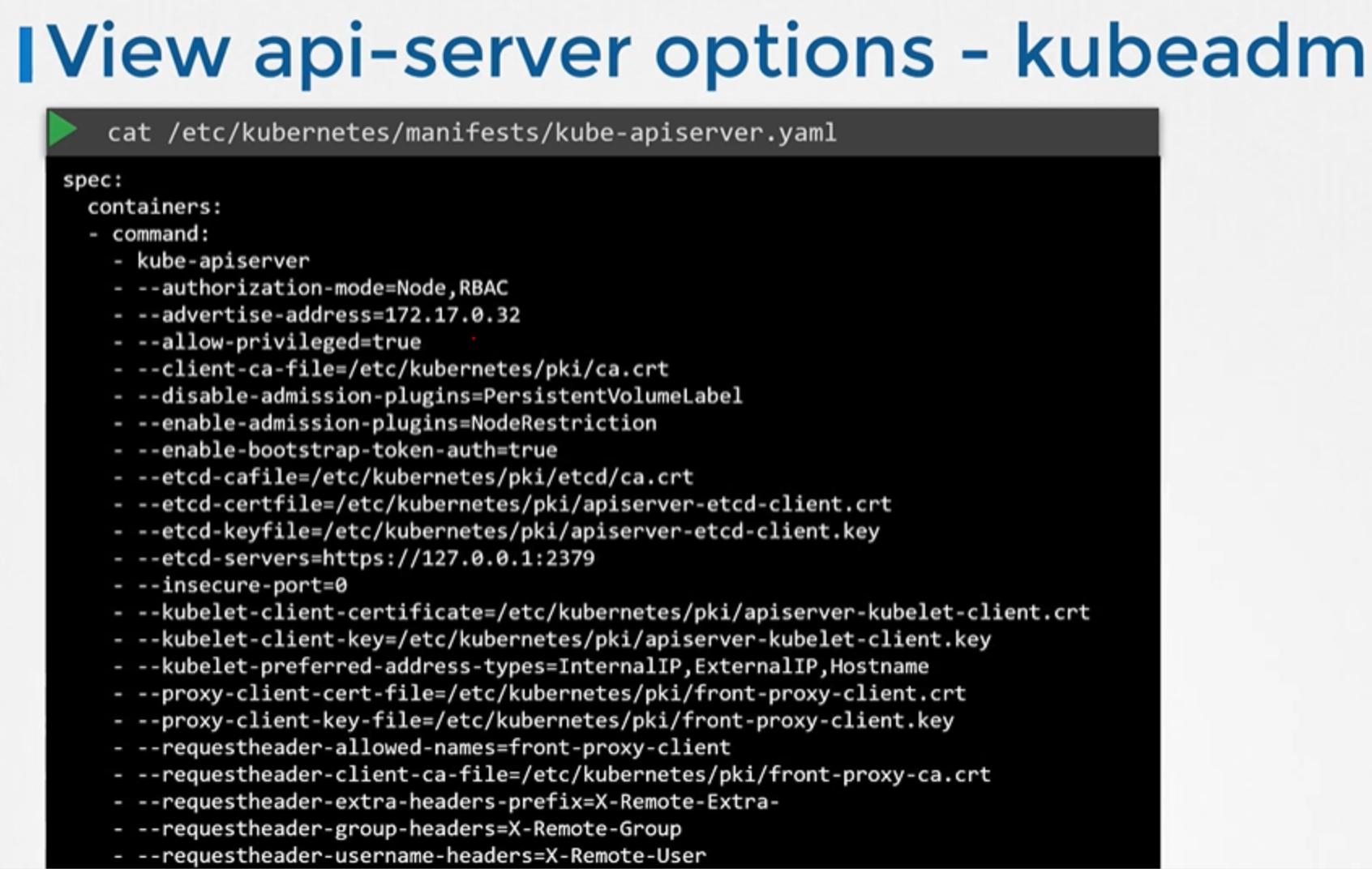
View kube-apiserver options - Manual
kubeadmin으로 셋업하지 않았다면, etc/systemd/system/kube-apiserver.service에 위치한 kube-apiserver 서비스를 확인하여 옵션을 검사할 수 있습니다.
cat /etc/systemd/system/kube-apiserver.service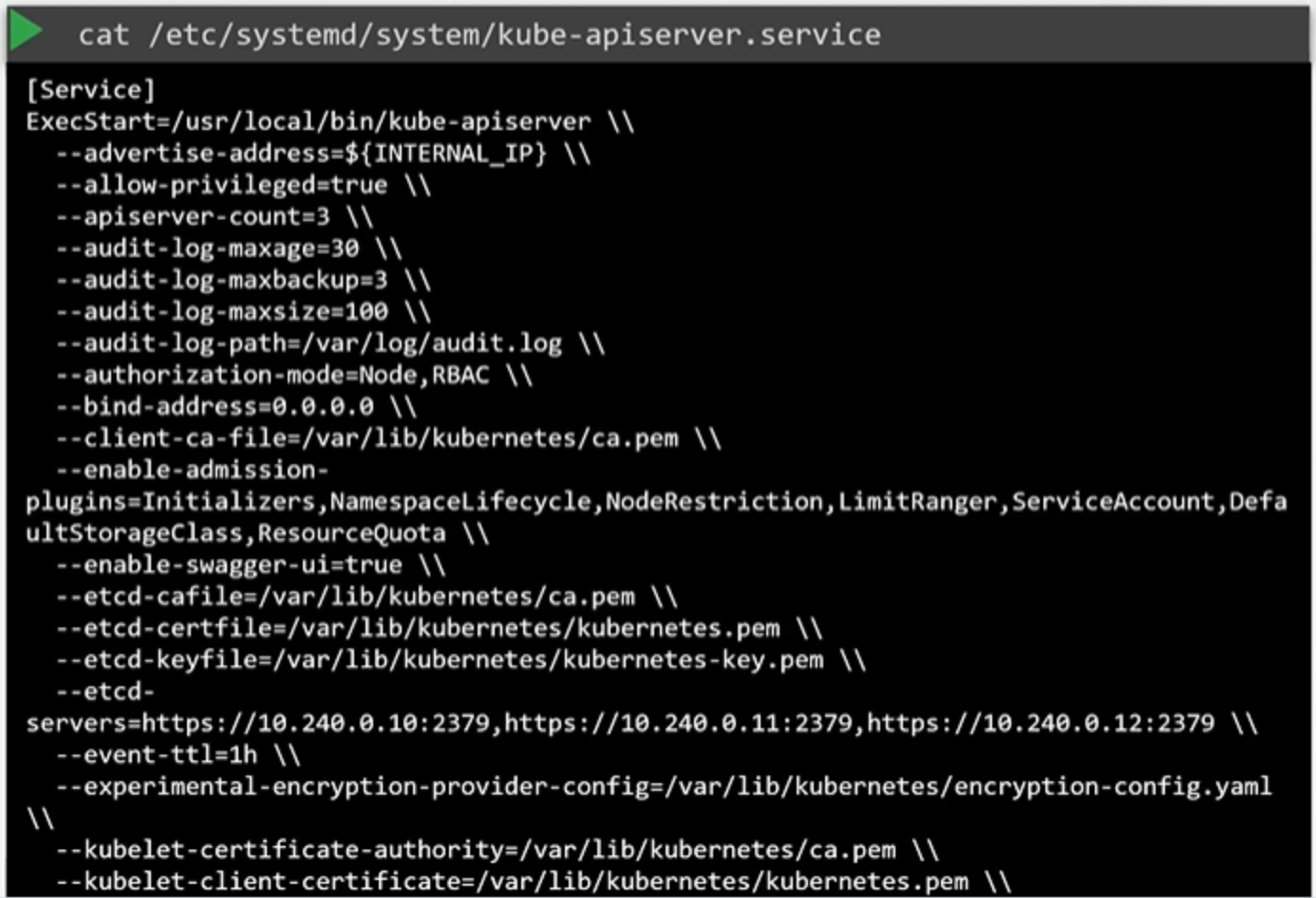
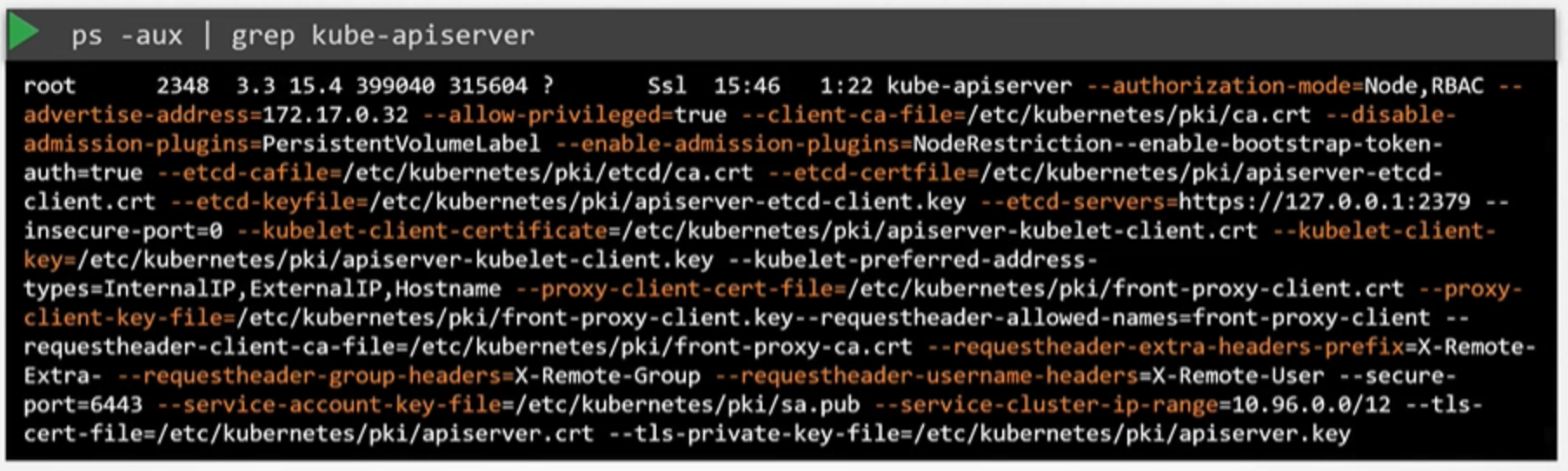
또한, 마스터 노드에 있는 프로세스를 리스트로 보여주고, kube-apiserver를 살펴봄으로써 실행중인 프로세스와 옵션들을 확인할 수 있습니다.
ps -aux | grep kube-apiserver