kubernetes CKA study (12) - Multiple Schedulers, Configuring Scheduler Profiles
kubernetes CKA study

앞에서 스케줄러가 노드에 걸쳐 파드를 고르게 분배하는 알고리즘을 가지고 있다는 것을 배웠다.
스케줄러는 Taints, Toleration, nodeAffinity 등을 통해 우리가 지정하는 다양한 조건들을 고려한다.
쿠버네티스는 확장이 아주 쉽다. 그래서 쿠버네티스 스케줄러 프로그램을 작성해 기본 스케줄러로 패키지하거나 쿠버네티스 클러스터에서 추가 스케줄러로 배포할 수 있다.
그래야 다른 모든 응용 프로그램이 기본 스케줄러를 통과할 수 있다.
하지만 일부 특정 응용 프로그램은 우리가 작성한 사용자 지정 스케줄러를 사용할 수 있다.
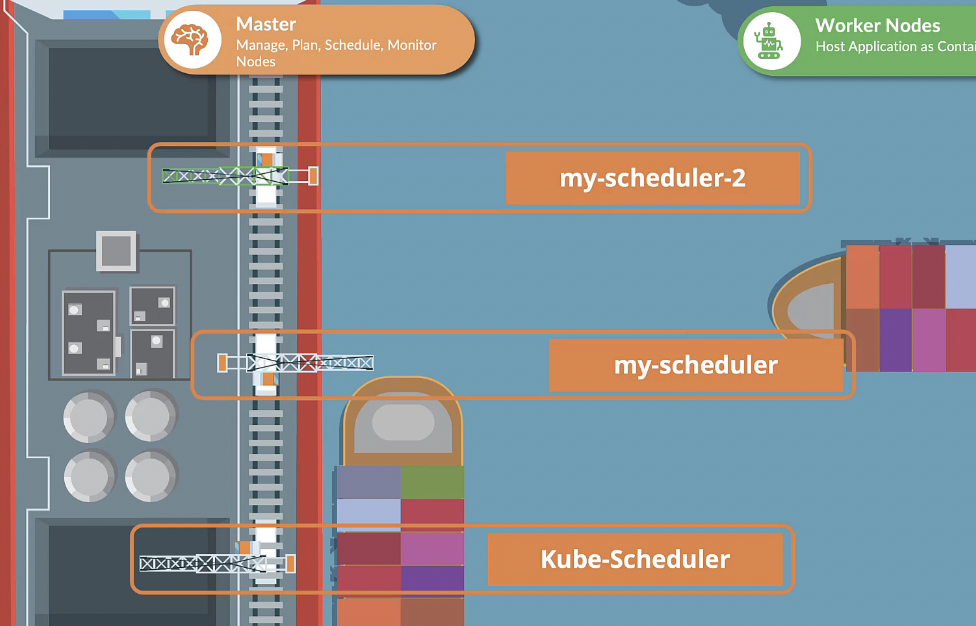
쿠버네티스 클러스터는 한번에 여러 스케줄러를 가질 수 있다.
파드를 만들거나 배치할 때 쿠버네티스에게 특정 스케줄러가 파드를 지정하도록 지시할 수 있다.
스케줄러가 여러개일 경우 반드시 이름이 달라야 한다. 그래야 각각의 스케줄러를 구분할 수 있다.
스케줄러 설정 파일을 통해 각각의 스케줄러의 이름을 설정한다.
이때 이름을 지정하지 않으면 default-scheduler이다.
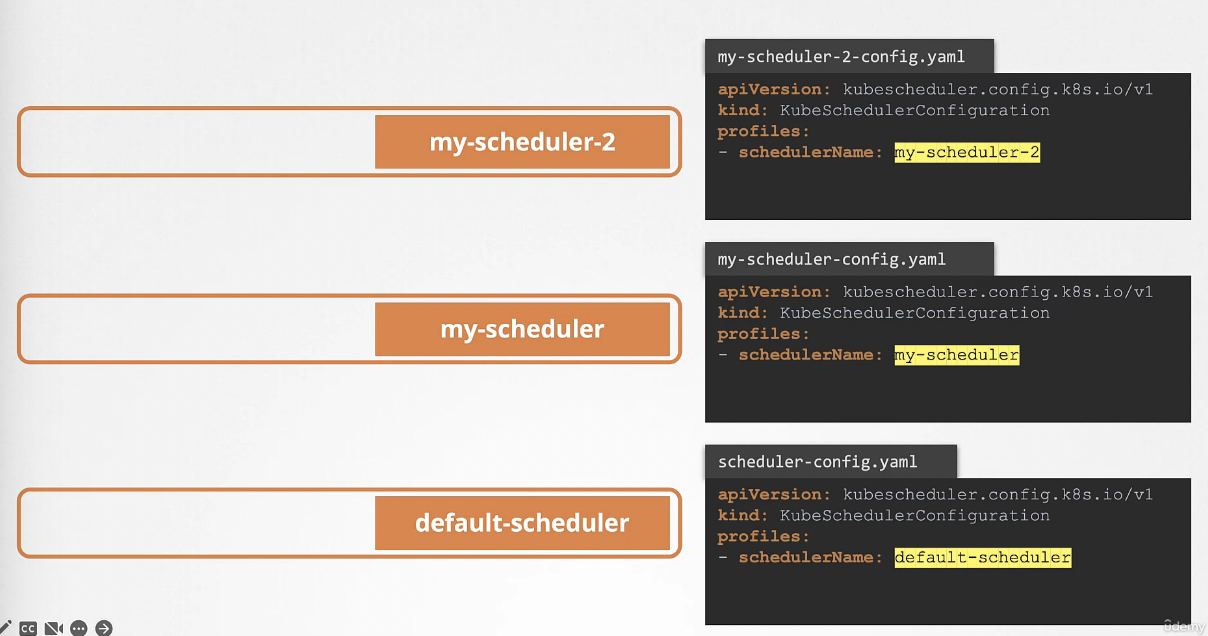
추가적인 스케줄러를 배포하는 방법은 다음과 같다.
kube-scheduler 바이너리를 다운로드해서 여러 옵션과 함께 kube-scheduler.service로 실행한다.
추가적인 스케줄러를 배포하기 위해서는 동일한 kube-scheduler 바이너리를 이용할 수 있다. 혹은 우리가 구축한 것을 이용할 수 있다.
아래 사진에서는 같은 바이너리를 이용해 추가적인 스케줄러를 배포했다.
각 스케줄러는 별도의 config 파일을 사용하고 파일마다 고유한 스케줄러 이름을 갖는다.

99%의 경우 사용자 지정 스케줄러를 이렇게 배포하지 않는다.
kubeadm에선 모든 컨트롤 플레인의 구성요소가 쿠버네티스 클러스터 안에서 pod 또는 deployment로 배포되기 때문이다.
스케줄러를 파드로 배포할 경우 파드 정의 파일을 생성하고 --kubeconfig 속성을 명시한다.
이는 스케줄러의 conf 파일로 가는 경로로서 kube-api server에 연결하기 위한 인증 정보가 있는 파일이다.
그런 다음 사용자가 작성한 config 파일 경로를 --config 속성으로 지정한다. config 파일에는 스케줄러 이름이 명시되어 있다.
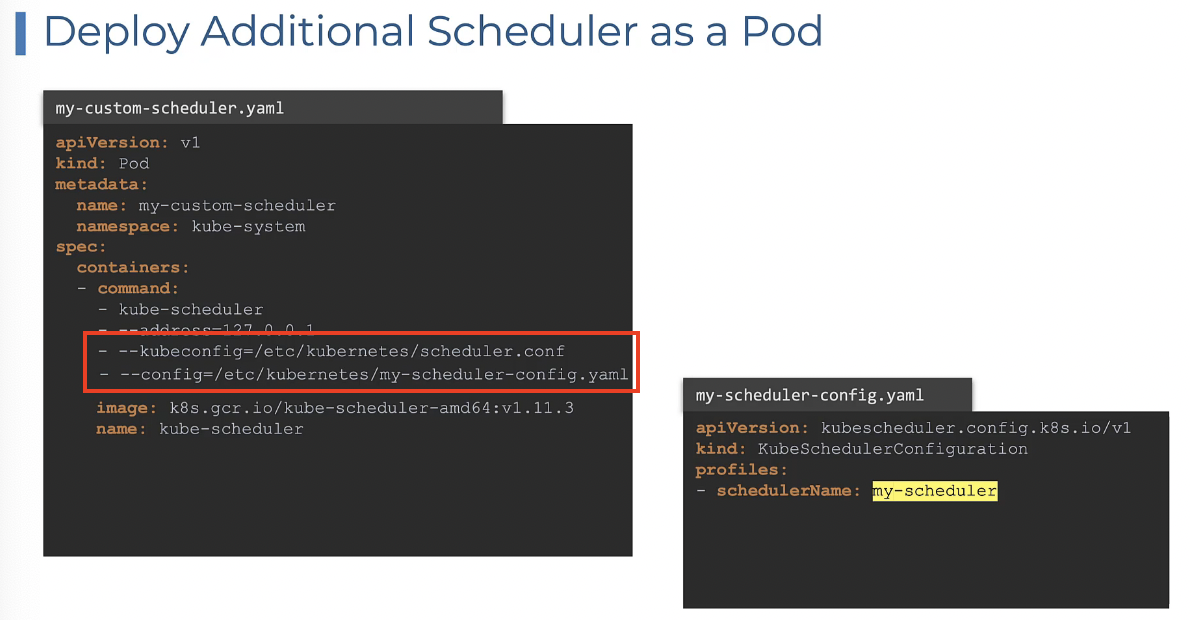
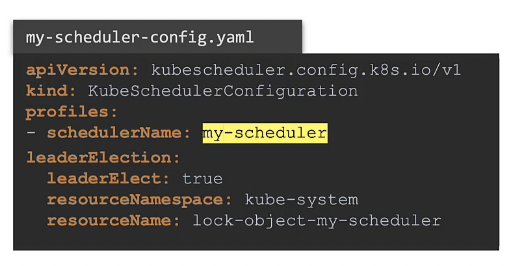
또 다른 중요한 옵션은 config 파일에 명시되는leaderElection 옵션이다.
leaderElection 옵션은 스케줄러의 복사본 여럿이 다른 마스터 노드에서 실행할 때 사용된다. 고가용성을 위해 여러 개의 마스터 노드에서 쿠버네티스 스케줄러 프로세스가 양쪽에서 실행된다.
동일한 스케줄러의 복사본 여러 개가 다른 노드에서 실행될 경우 한 번에 하나만 활성화될 수 있다.
leaderElection 옵션은 스캐줄 활동을 이끌 리더를 선택하는데 도움이 된다.
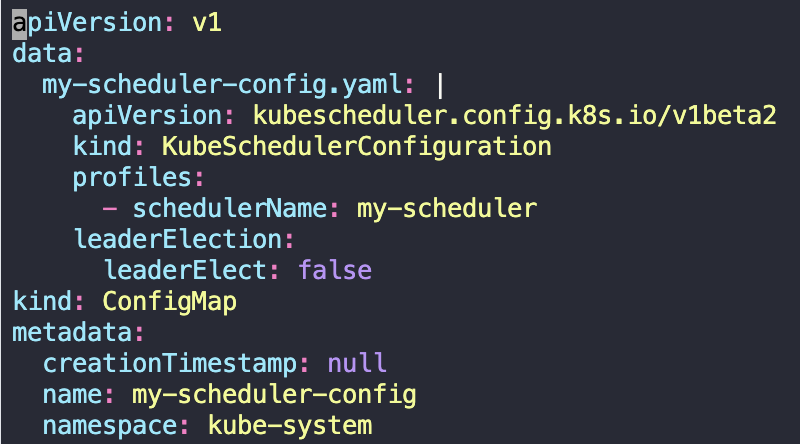
아래 사진처럼 config 파일을 스케줄러에게 전달하기 위해 볼륨 마운트나 ConfigMap을 사용한다.
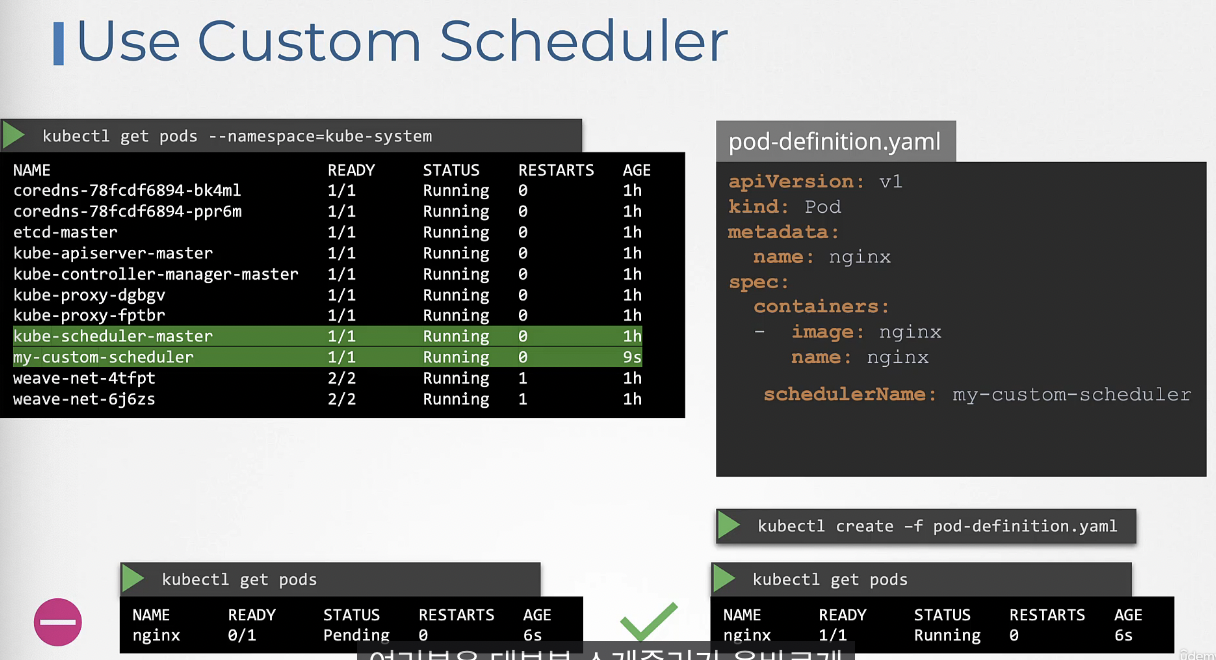
새 스케줄러를 사용하기 위해 schdulerName 필드를 파드 정의 파일에 추가하고 사용할 스케줄러 이름을 명시하면 된다.
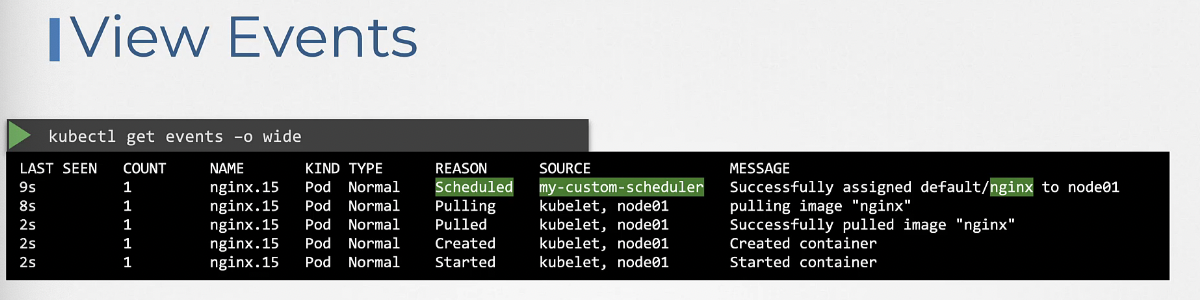
스케줄러가 잘 동작하는지 알기 위해서 이벤트를 확인하면 된다.
kubectl get events -o wide 명령으로 현재 네임스페이스에 있는 모든 이벤트를 열거하고 예정된 이벤트를 확인할 수 있다.
아래 사진에서 성공적으로 nginx를 node01에 할당했음을 확인할 수 있다.
문제가 생겼다면 kubectl logs {스케줄러 이름} 명령어를 통해 스케줄러의 로그를 확인해보면 된다.

테스트 문제 몇가지를 정리해보겠다.
Let's create a configmap that the new scheduler will employ using the concept of ConfigMap as a volume.
(my-scheduler-config.yaml)
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: false(my-scheduler-configmap.yaml)
apiVersion: v1
data:
my-scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: false
kind: ConfigMap
metadata:
creationTimestamp: null
name: my-scheduler-config
namespace: kube-systemkubectl apply -f my-scheduler-configmap.yaml
Deploy an additional scheduler to the cluster following the given specification.
(my-scheduler.yaml)
apiVersion: v1
kind: Pod
metadata:
labels:
run: my-scheduler
name: my-scheduler
namespace: kube-system
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: registry.k8s.io/kube-scheduler:v1.27.0
livenessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts:
- name: config-volume
mountPath: /etc/kubernetes/my-scheduler
hostNetwork: false
hostPID: false
volumes:
- name: config-volume
configMap:
name: my-scheduler-configkubectl apply -f my-scheduler.yaml
A POD definition file is given. Use it to create a POD with the new custom scheduler.
(nginx-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
schedulerName: my-scheduler
containers:
- image: nginx
name: nginx잘 되었는지 확인
kubectl get events -o wide | grep "schedule"
테스트 통과 완료

Configuring Scheduler Profiles
파드들은 Scheduling Queue에서 스케줄되기를 기다린다. 이때 파드를 분류하는 기준은 우선순위이다. 우선순위를 설정하기 위해서는 PriorityClass를 정의하면 된다.

우선순위에 따라 파드들이 정렬되어 우선순위가 높은 파드는 이렇게 가장 먼저 대기자 명단에 오르게 된다.
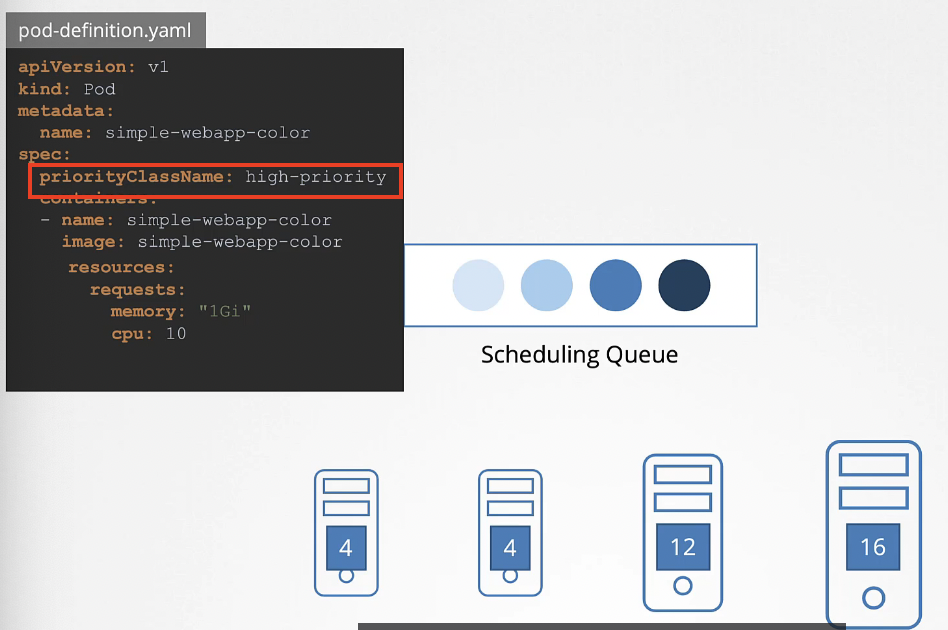
그 다음 필터링 단계에 돌입한다. 파드를 실행할 수 없는 노드는 여기서 걸러진다.
파드의 requests가 CPU 10이기 때문에 두 개의 노드가 리소스 부족으로 걸러진다.
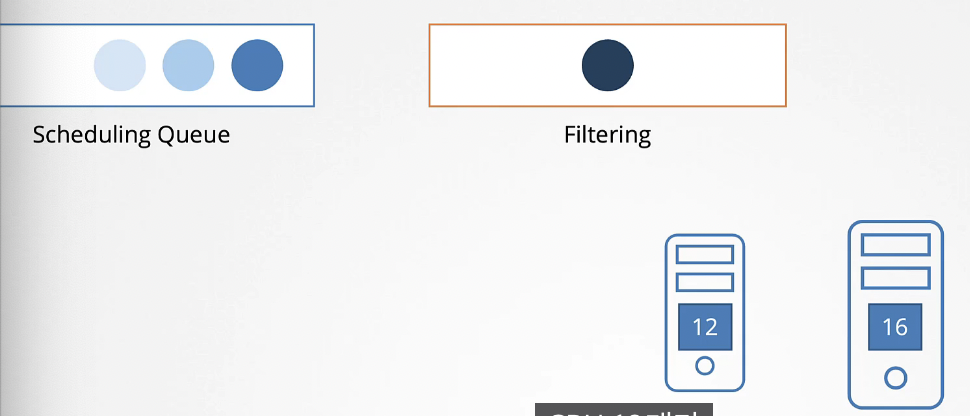
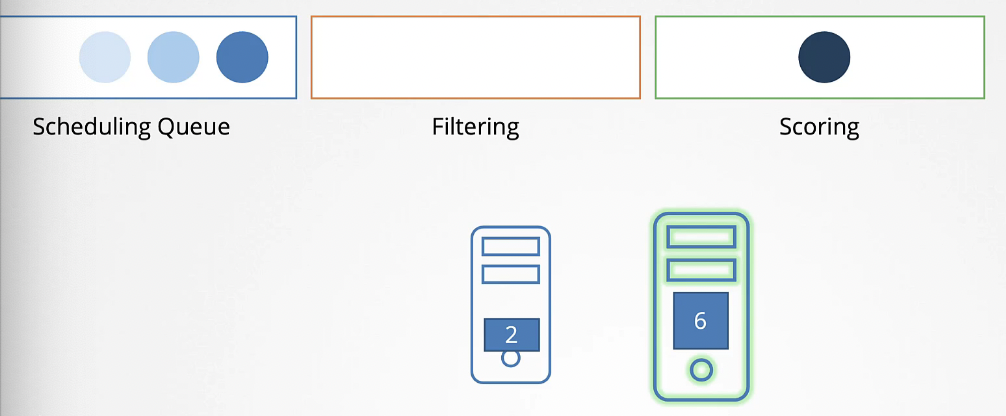
그 다음은 점수 매기는 단계이다. 스케줄러는 해당 파드에 필요한 CPU를 제외하고 남은 공간을 근거로 각 노드에 점수를 매긴다.
이 경우 첫 번째 노드는 2개, 두 번째 노드는 6개 남는다.
두 번째 노드가 더 높은 점수를 갖기 때문에 선택된다.
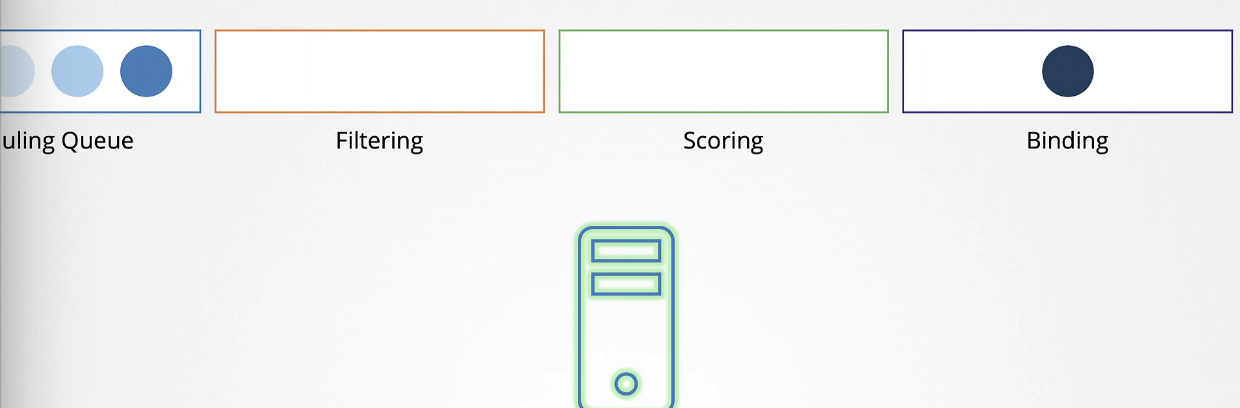
마지막으로 바인딩 단계에서 파드가 마침내 가장 높은 점수를 가진 노드에 바인딩된다.
이 모든 작업의 특징은 플러그 인으로 이루어진다는 점이다.
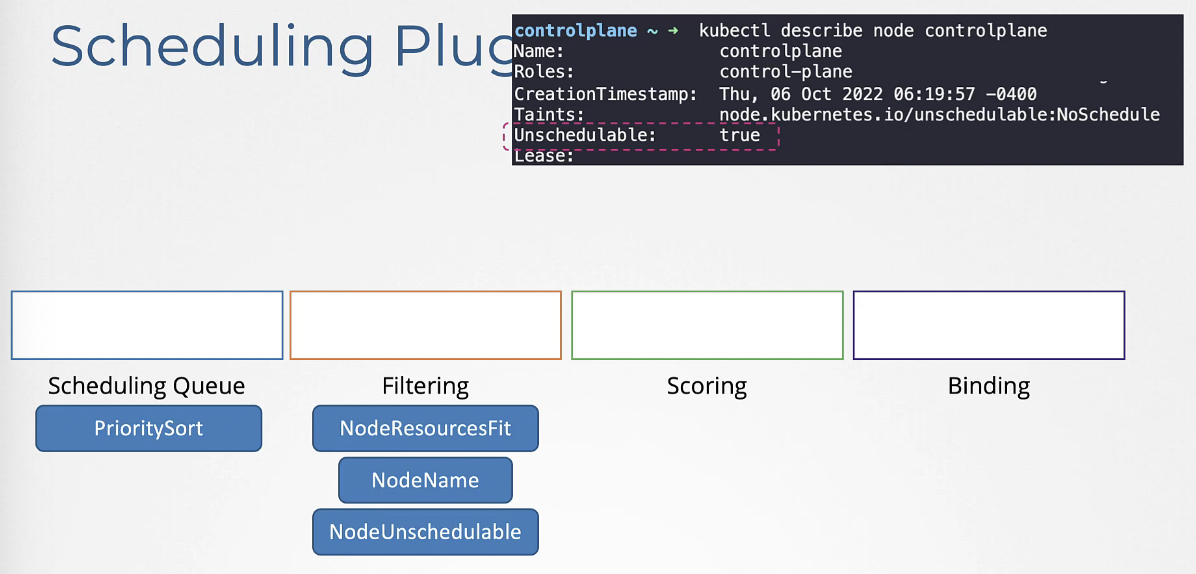
Scheduling Queue
PrioritySort: 파드에서 우선순위로 설정된 기준에 따라 순서대로 정렬한다.
Filtering
-
NodeResourcesFit: 파드에서 요구하는 자원이 충분한 노드를 식별하고 부족한 노드를 필터링한다.
-
NodeName: 파드 정의 파일에서 지정된 nodeName이 있는지 확인하고 이름과 일치하지 않는 모든 노드를 거른다.
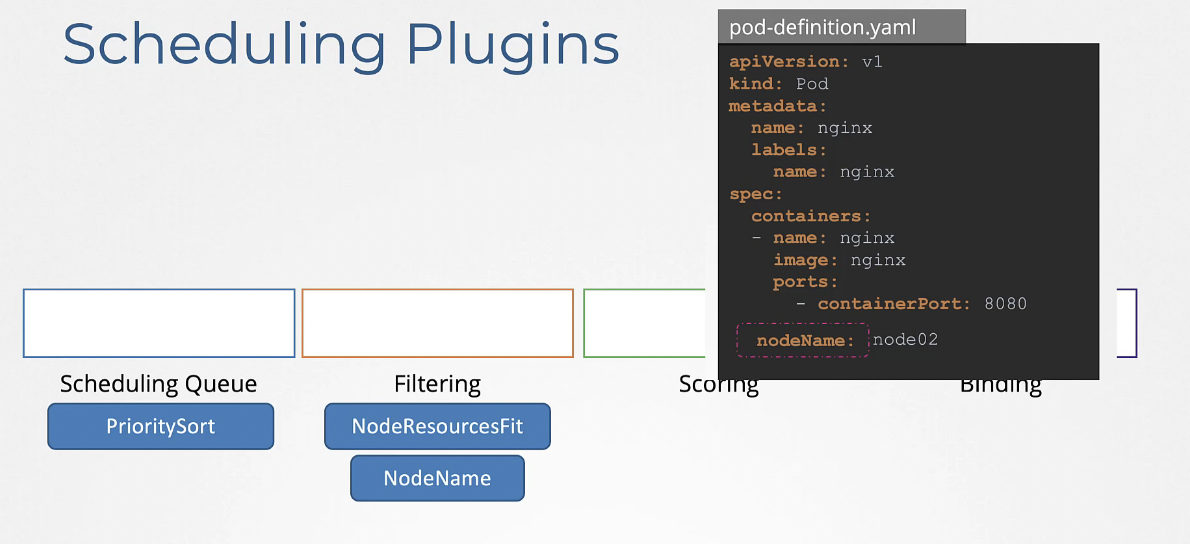
- NodeUnschedulable: Unschedulable이 true로 설정된 노드들을 거른다.
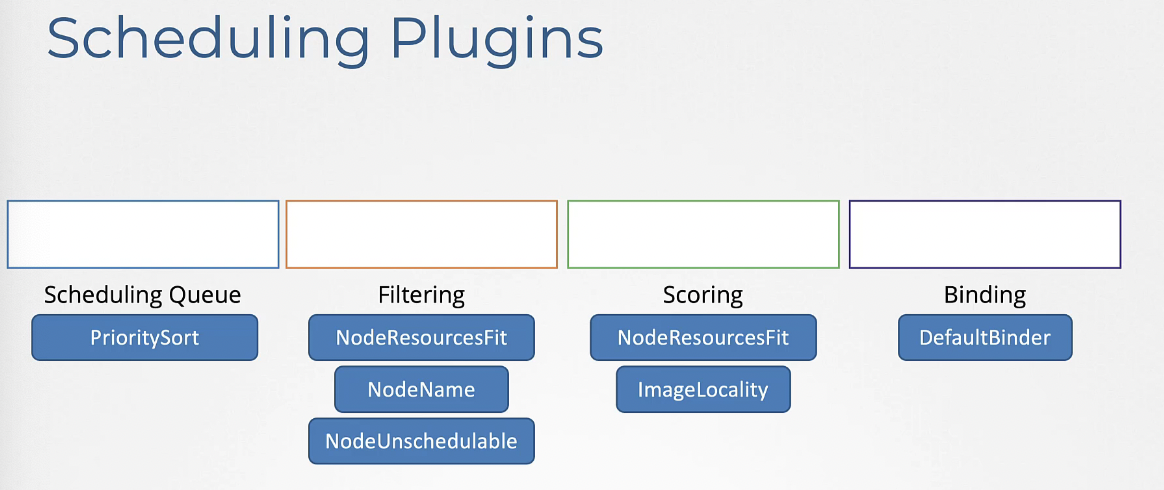
Scoring : 이 단계에서 특정 노드를 거부하지 않는다. 조립만 해보는 것이다.
-
NodeResourcesFit: 파드가 할당된 후 사용 가능한 리소스를 기반으로 점수를 매긴다.
-
ImageLocality: 파드의 이미지가 노드에서 컨테이너 이미지로 사용된다면 높은 점수를 준다.
Binding
- DefaultBinder: 바인딩 메커니즘을 제공한다.
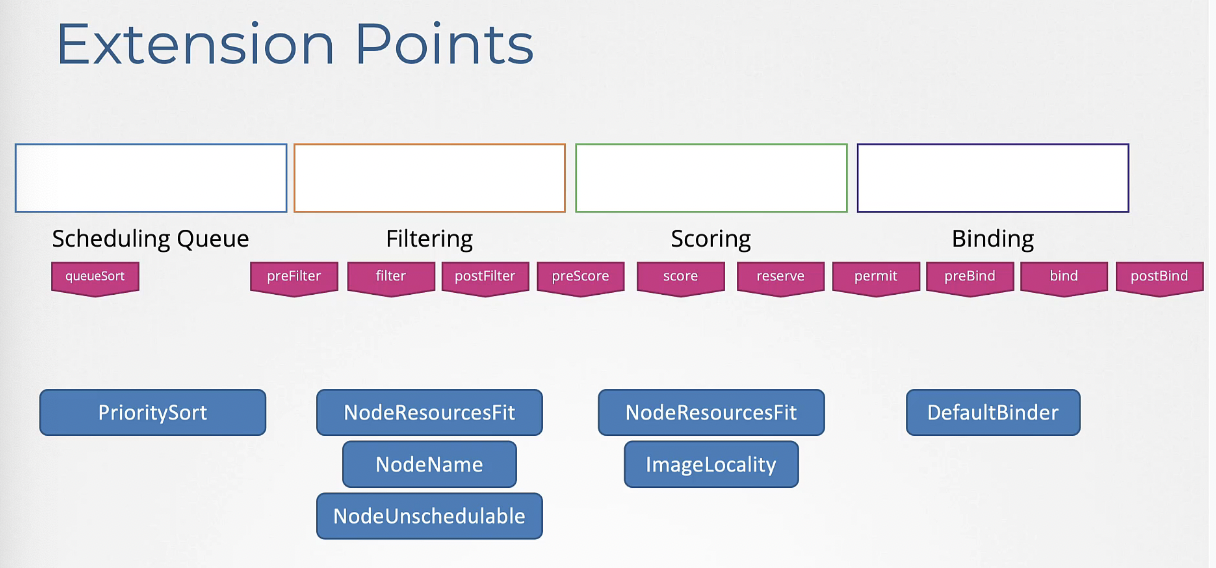
쿠버네티스 제품은 확장성이 매우 뛰어나기 때문에 어떤 플러그인을 어디에 둘지 커스터마이징할 수 있고 자신만의 플러그인을 작성해서 사용할 수 있다.
각 단계마다 플러그인이 연결될 수 있는 확장 지점이 있다.
확장 지점에 생성한 플러그인을 연결하면 된다.
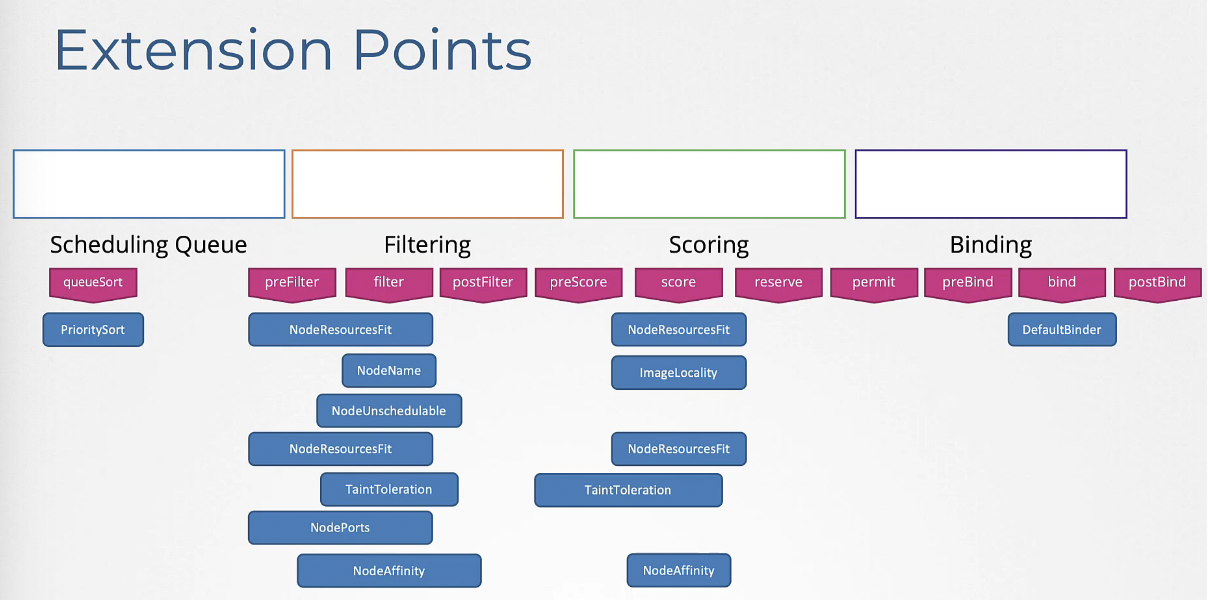
추가적인 플러그인들에 대한 세부사항들은 다음과 같다.
보다시피 일부 플러그인은 여러 확장 지점에 걸쳐 있다.
이제 어떻게 플러그인을 호출하고 어떻게 우리만의 플러그인을 사용할 수 있는지 알아보자.
단일 스케줄러에게 다중 프로필을 지원한다.
config 파일을 통해 단일 스케줄러에게 다중 프로필을 구성할 수 있다.
각각의 스케줄러는 분리된 개별 프로필을 갖는다.
각각의 스케줄러는 분리된 스케줄러처럼 작동한다. 단지 여러 개의 스케줄러가 하나의 바이너리로 실행되는 것 뿐이다.

어떻게 각 스케줄러가 다르게 작동하도록 구성할 수 있을까?
각 스케줄러의 프로필 아래에 확장 지점과 가능/불가능 여부, 플러그인 이름을 명시해서 우리가 원하는 방식으로 플러그인을 구성할 수 있다.

