
Backup and Restore Methods
리소스 구성을 백업하는 더 나은 방법은 kube-api server를 쿼리하는 것이다.
kubectl을 이용해 kube-api server에 직접 접근함으로써 클러스터에 생성된 모든 개체에 대한 리소스 구성을 복사해 저장할 수 있다.
kubectl get all --all-namespaces -o yaml > all-deploy-services.yaml
명령어를 이용해 모든 네임스페이스에 있는 파드, 디플로이먼트, 서비스를 YAML 형식으로 파일에 추출하고 저장할 수 있다.
이는 일부 리소스 그룹을 위한 것이다. 그 외의 다른 리소스들을 고려하기 위해 HeptIO에서 VELERO라고 부르는 도구를 제공한다.

ETCD는 우리 클러스터 상태에 관한 정보를 저장한다.
클러스터 자체에 관한 정보와 노드 및 클러스터 내부에서 생성된 모든 리소스가 여기 저장된다.
그래서 리소스를 백업하는 대신 ETCD 서버 자체를 백업하는 것을 선택할 수 있다.
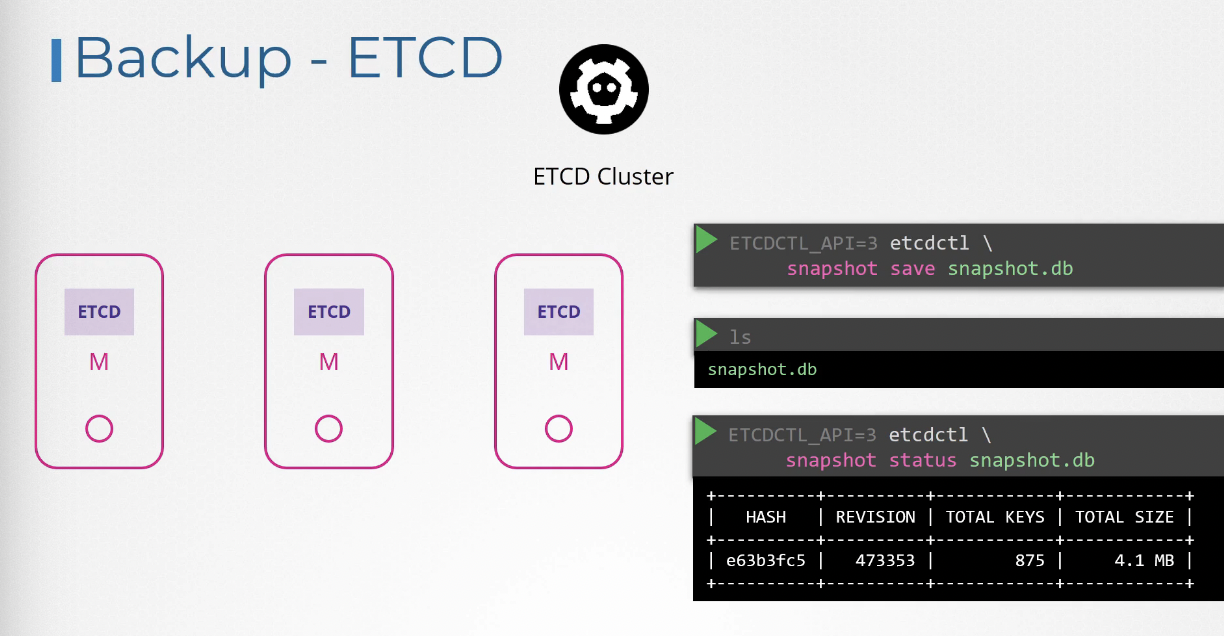
ETCD 클러스터는 마스터 노드에 호스트되어 있다.
ETCD 클러스터를 구성할 때 모든 데이터가 저장되는 장소(/var/lib/etcd)를 명시한다.

ETCD는 빌트인 스냅샷 솔루션도 지원한다.
etcdctl snapshot save 명령어를 이용해 데이터베이스 스냅샷을 찍을 수 있다.
스냅샷 파일은 현재 디렉터리의 이름으로 생성된다. 다른 경로에 생성하고 싶다면 전체 경로를 명시하면 된다.
etcdctl snapshot status 명령어를 이용해 백업의 상태를 볼 수 있다.
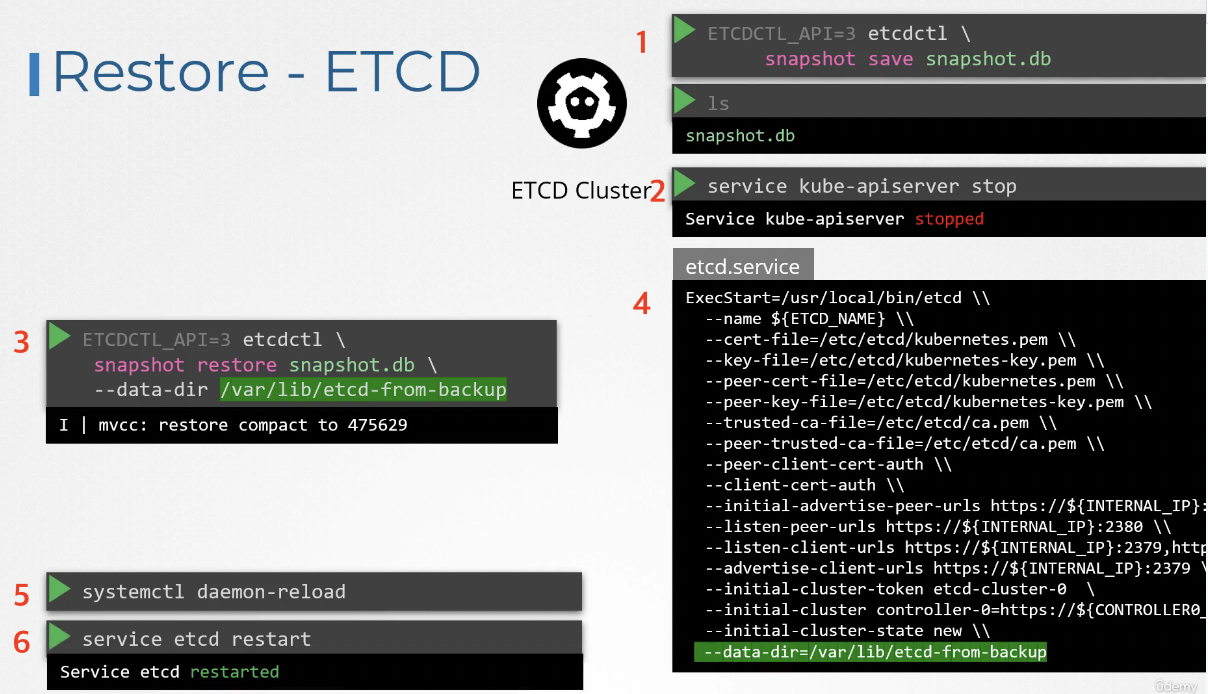
나중에 이 백업에서 클러스터를 복원하려면 먼저 kube-api server 서비스를 중단해야 한다.
복원하기 위해 ETCD 클러스터를 다시 시작해야 하는데 kube-api server가 ETCD에 의존하기 때문이다.
그런 다음 etcdctl snapshot restore 명령어에 백업 파일의 경로를 지정하여 실행하면 된다.
ETCD가 백업에서 복구할 때 새 클러스터 구성을 초기화하고 ETCD의 멤버를 새 클러스터의 새 멤버로 구성한다. 이는 새 멤버가 실수로 기존의 클러스터에 합류하는 것을 막기 위해서이다.
이 명령을 실행하면 새로운 데이터 디렉터리가 생성된다.
그런 다음 ETCD 구성 파일을 구성해 새 데이터 디렉터리를 사용한다.
그런 다음 데몬 서비스를 다시 로드하고 재시작해야 한다.
마지막으로 kube-api server 서비스를 시작해야 한다.
이제 클러스터가 원래 상태로 돌아왔을 것이다.

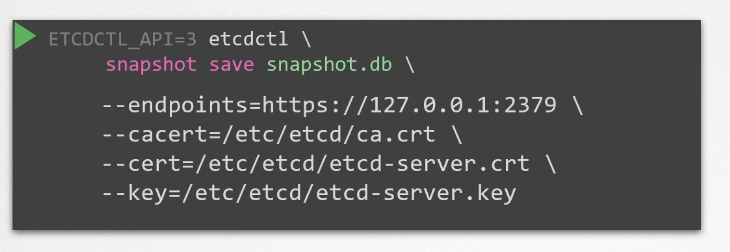
스냅샷을 저장할 때 명령어와 함께 '--endpoint','--cacert', '--cert', '--key' 옵션을 지정하는 것을 기억해라
결론적으로 백업을 위해 두 가지 옵션이 존재한다.
먼저, ETCD를 이용한 백업과 kube-api server 쿼리를 통한 백업이다.
둘 다 장단점이 있다.
관리되는 쿠버네티스 환경을 사용하는 경우 때로는 ETCD 클러스터에 액세스조차 안될 수도 있다. 그 경우엔 kube-api server를 쿼리하는 백업이 아마 더 나은 방법일 것이다.

Working with ETCDCTL
etcdctl은 etcd의 클라이언트를 위한 명령어이다.
우리의 실습 환경에서는 ETCD 키-값 데이터베이스가 static pod 형태로 마스터 노드에 배포되어 있다.
etcdctl을 사용해서 백업과 복구를 하기 위해서는 ETCDCTL_API의 버전을 3으로 세팅해야 한다.
ETCDCTL_API를 사용하기 전에 export ETCDCTL_API=3을 먼저 실행해야 한다.
etcdctl 명령어도 마찬가지로 '-h', '--help' 옵션을 제공한다.
테스트 문제 기록
export ETCDCTL_API=3를 먼저 실행해야 etcd 백업 명령어 등을 사용할 수 있다.

ETCD 버전을 알기 위해서는 ETCD 파드의 이미지 버전을 확인하면 된다.
/etc/kubernetes/manifests 폴더에는 static pod로 배포되는 클러스터 구성 요소들의 정의 파일들이 존재한다.

etcdctl snapshot save 명령어를 사용할 때 반드시 '--endpoint','--cacert', '--cert', '--key' 옵션을 지정해야 한다.
옵션들에 대한 정보는 kubectl describe 명령을 통해 etcd 파드에서 얻어올 수 있다.


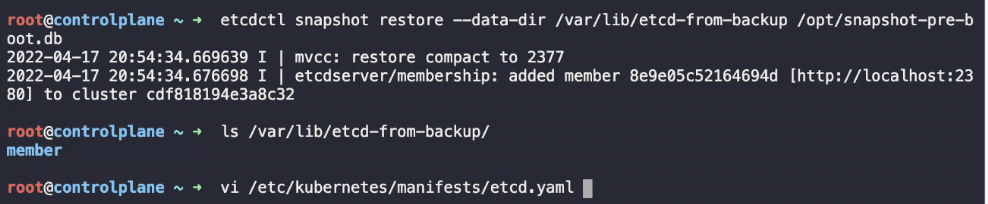
데이터가 복구될 디렉토리를 '--data-dir' 옵션으로 지정해야 한다.
ls 명령어를 통해 복구된 데이터를 확인할 수 있다.
이제 etcd 정의 파일에서 볼륨 경로를 데이터가 복구된 디렉토리로 변경하고 호스트 경로와 백업 경로를 추가하는 작업이 필요하다.
etcd 정의 파일에서 표시된 두 부분은 동일한 위치(데이터가 복구된 디렉토리)를 가리켜야 한다. 이 부분들은 etcd가 재생성될 때 로컬 호스트에 있는 데이터로 간주되는 데이터의 위치를 가리킨다.
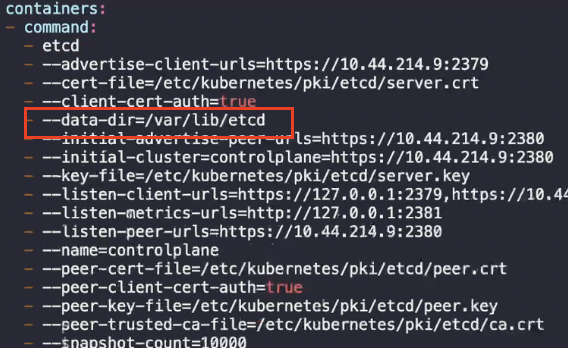
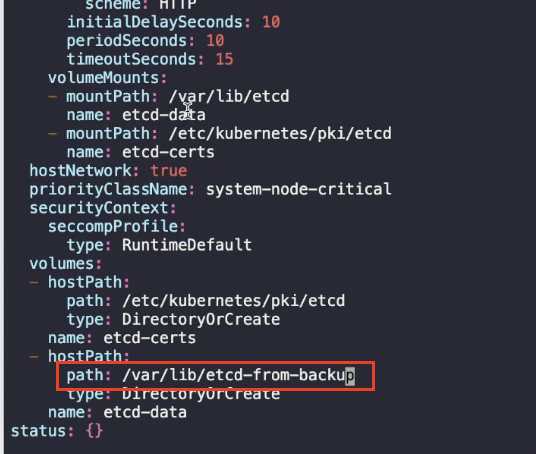
etcd 정의 파일의 내용을 변경해으면 etcd 서버가 잠시 다운되기 때문에 액세스가 잠시 중단될 것이다.
새 정보를 기반으로 새 파드를 생성한다.
만약 자동으로 etcd 파드가 재실행되지 않으면 etcd 파드를 삭제해줘야 한다.
etcd 파드가 재실행되고 매니저와 스케줄러가 재가동되면서 파드, 서비스, 디플로이먼트가 재가동되는 것을 확인할 수 있다.
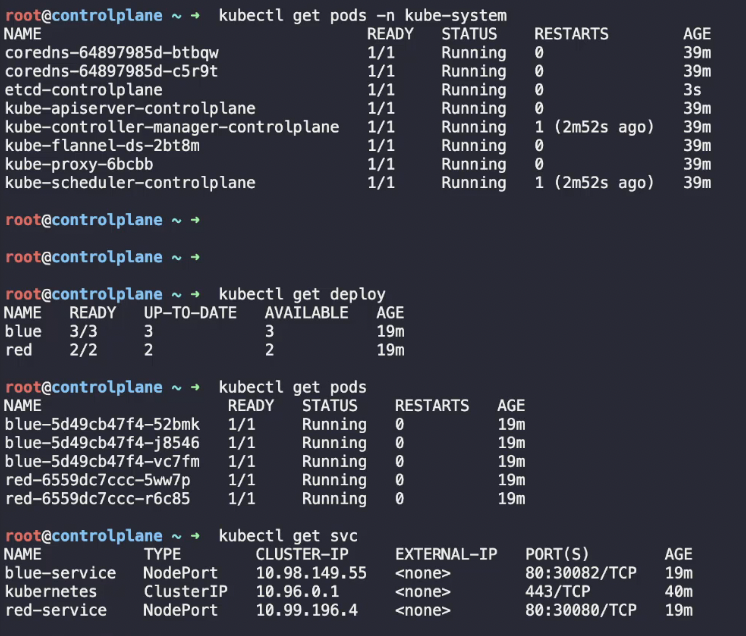
Practice Test Backup and Restore Methods 2
현재 노드에 얼마나 많은 클러스터들이 존재하는 지 확인하기 위해 kubectl config view 명령어를 사용하면 된다.
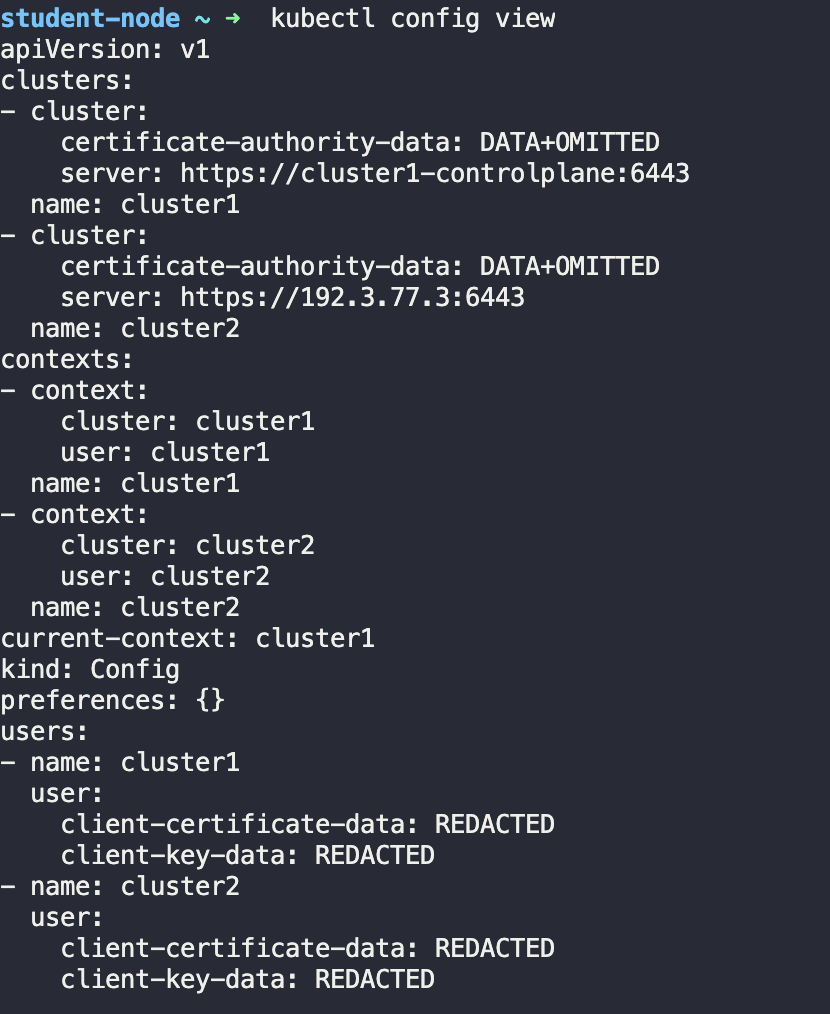
cluster1으로 변경하기 위해서 kubectl config use-context cluster1 명령어를 사용하면 된다.

etcd를 찾는 방법
- kubectl get pods -A | grep etcd 명령어를 통해 etcd 파드를 찾는다.
- '/etc/kubernetes/manifest' 폴더를 확인하여 static pod로 정의되어 있는지 찾는다.
- ps -ef | grep etcd 명령어를 통해 etcd 프로세스를 찾는다.

테스트 마지막 문제 etcd 백업 문제 이해하지 못했음 복습필요
