
POD
전에 언급한 것 과 같이, 쿠버네티스에서의 궁극적인 목표는 클러스터에서 워커 노드로 구성된 컨테이너 형태로 애플리케이션을 배포하는 것입니다. 그러나, 쿠버네티스는 컨테이너를 워커 노드에서 직접 배포하지 않습니다. 컨테이너들은 Pod라는 쿠버네티스 오브젝트로 캡슐화되어있습니다.
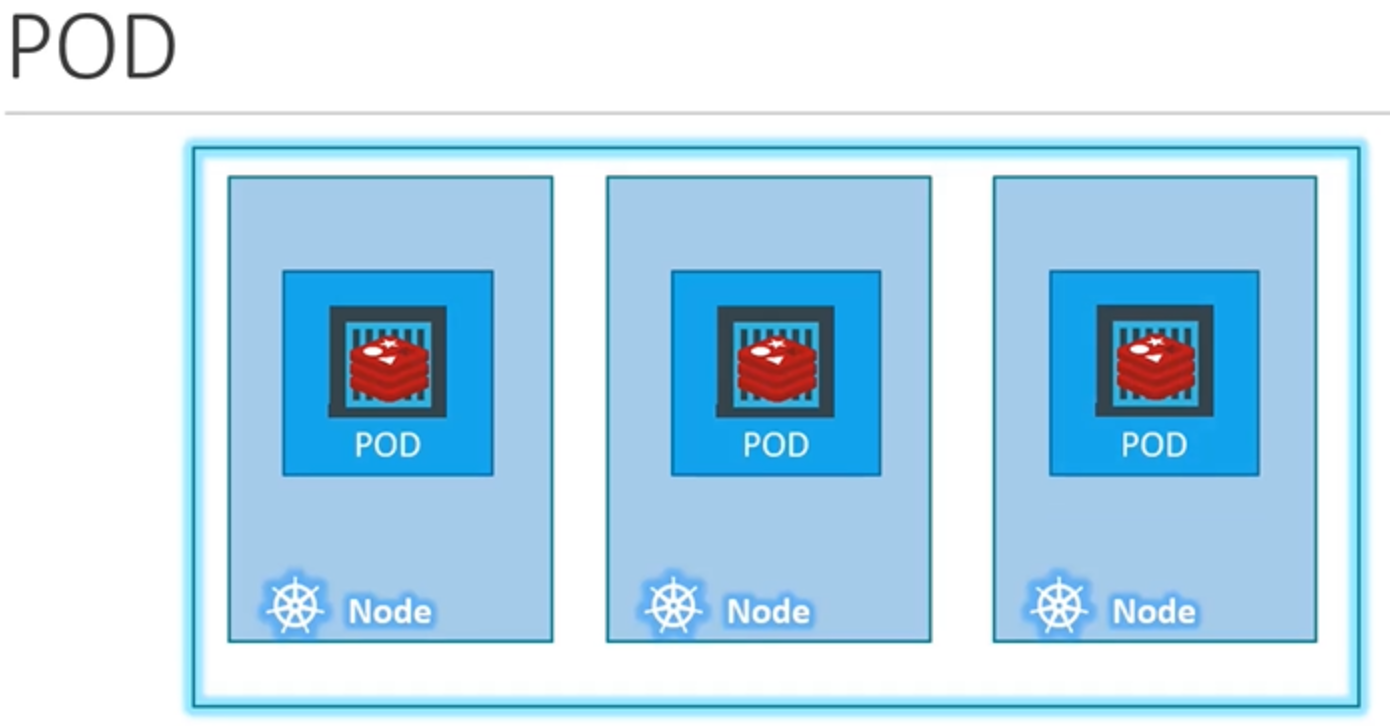
파드는 애플리케이션의 단일 인스턴스이며, 쿠버네티스에서 만들 수 있는 가장 작은 오브젝트입니다. 가장 간단한 케이스로 예를 들어 봅시다.
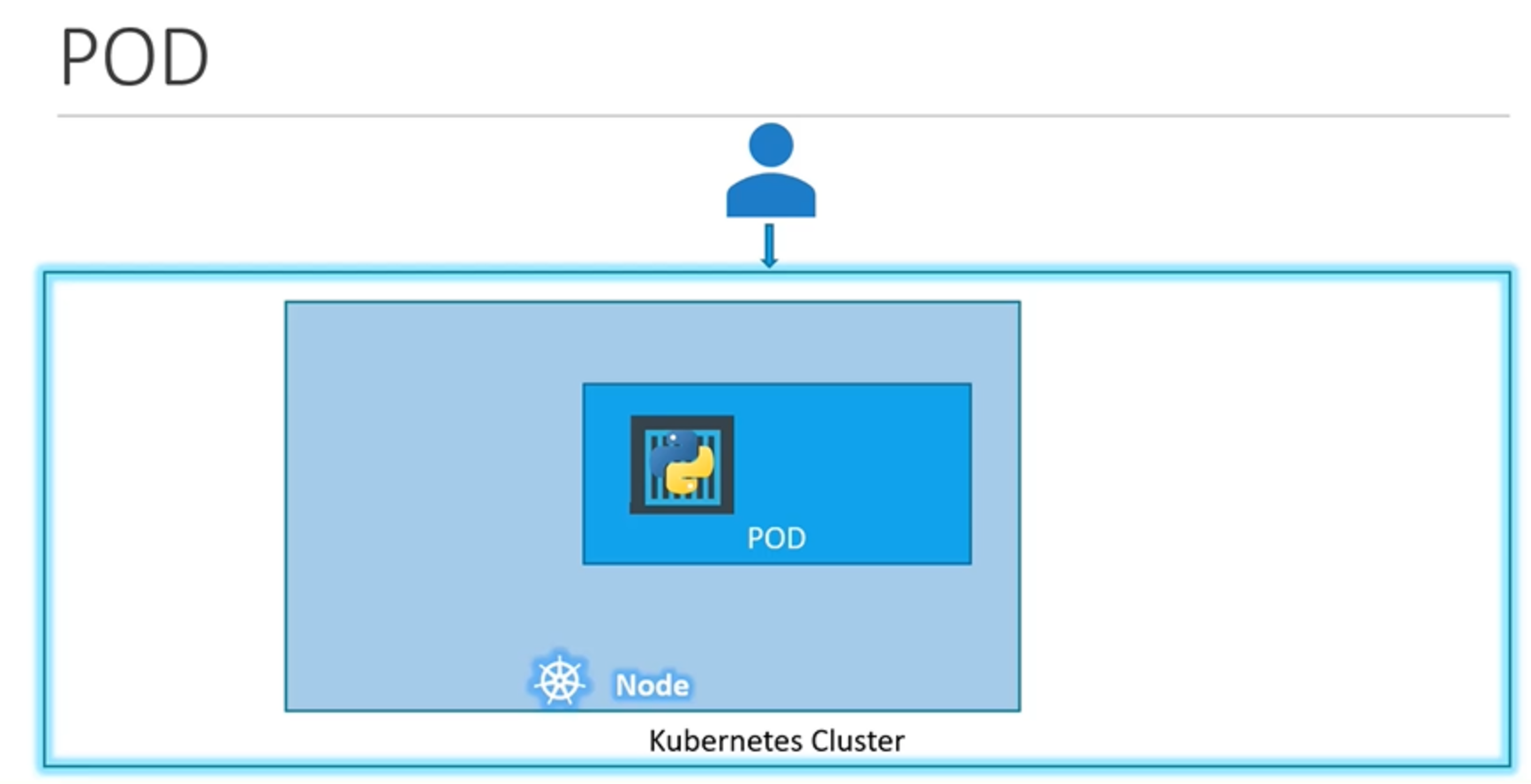
쿠버네티스 클러스터에 하나의 노드가 있고, 노드 안에서 애플리케이션 인스턴스 하나가 도커 컨테이너로 캡슐화된 파드에서 실행되고 있다고 합시다. 애플리케이션에 접속하는 유저 수가 증가해서, 애플리케이션을 확장해야 한다면 어떻게 해야 할까요? load를 분산하기 위해 애플리케이션의 인스턴스를 추가해야 하겠죠. 그렇다면 추가 인스턴스는 어디에다 추가할까요? 같은 파드 내에서 새 컨테이너 인스턴스를 불러와야 할까요? 아닙니다. 새 인스턴스와 함께 새로운 파드를 만듭니다. 이제 같은 노드 안에 있는 두 개의 별도 파드에서 실행되는 애플리케이션의 두 인스턴스가 있습니다. 유저 수가 더 많아져서 노드에 충분한 공간이 없으면 어떻게 할까요? 그렇다면 언제든지 새 노드를 만들어서 추가 파드를 배포할 수 있습니다. 클러스터의 물리적 용량을 확장하기 위해 새 노드를 추가합니다. 여기서 강조하고 싶은 내용은, 파드는 일반적으로 (애플리케이션을 실행하는) 컨테이너와 1:1 관계를 가진다는 것입니다.
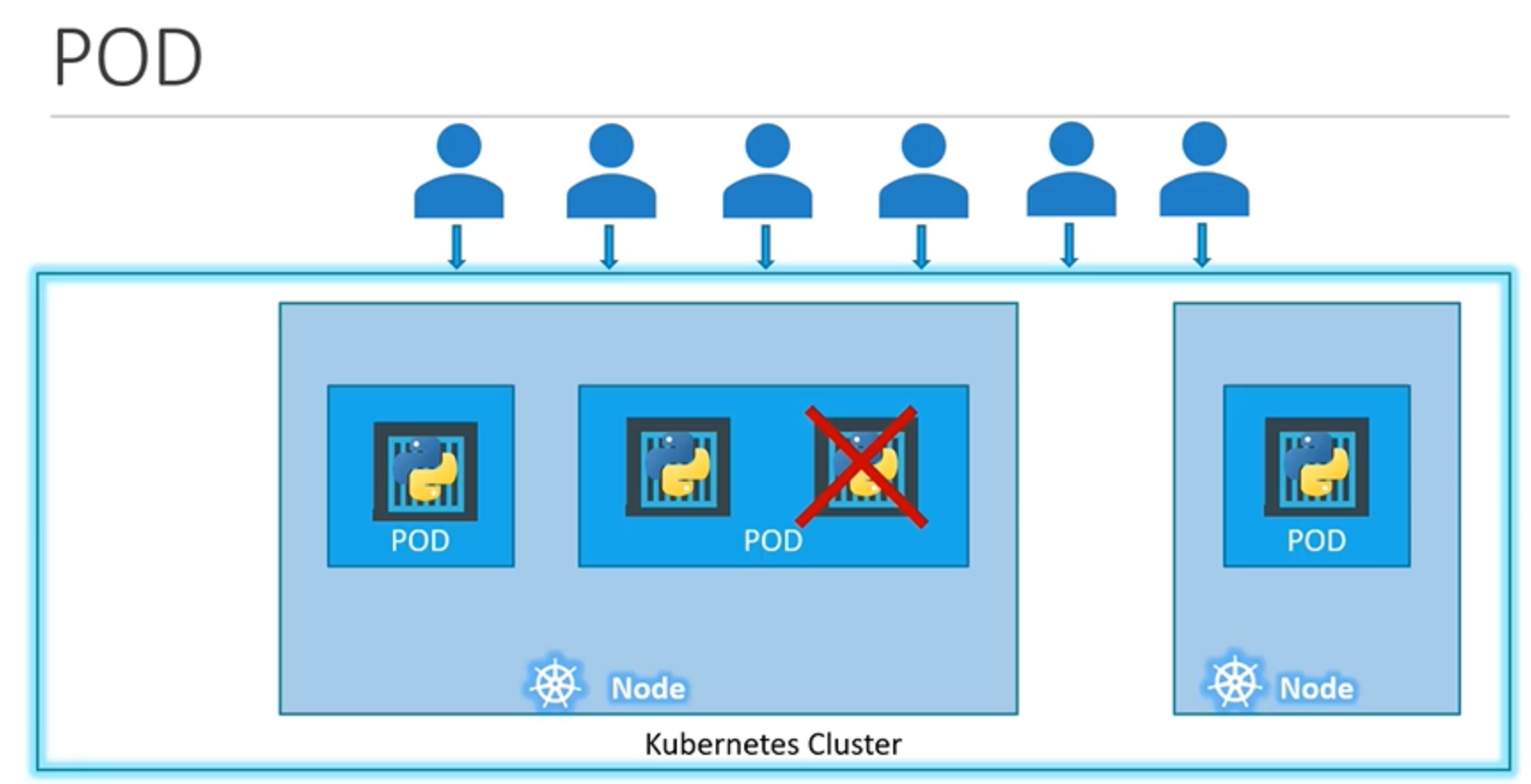
확장하려면 새로운 파드를 만들면 되고, 축소하려면 기존 파드를 삭제하면 됩니다.
Multi-Container PODs
방금 우리는 파드가 일반적으로 컨테이너와 1:1 관계를 가진다고 했었는데요. 그렇다면 쿠버네티스가 한 파드에서는 하나의 컨테이너만 가질 수 있게 제한해둔 것일까요? 그것은 아닙니다. 한 파드는 같은 종류의 컨테이너가 아니라면, 여러 컨테이너를 가질 수 있습니다. 위에서 말씀드린 것과 같이, 우리의 의도가 애플리케이션을 확장하는 것이라면 같은 종류의 인스턴스(컨테이너)를 추가해야 하는 것이므로 추가 파드를 생성해야 합니다. 그러나 확장하는 것이 아닌 다른 시나리오가 있을 수 있습니다. 웹 애플리케이션의 경우, 유저 처리, 업로드된 파일 데이터 프로세싱 등 지원 작업을 수행하는 helper 컨테이너가 있을 수 있습니다. 이 경우 우리는 헬퍼 컨테이너가 애플리케이션 컨테이너와 함께 있길 원할 것입니다. 이런 케이스에는 한 파드 내에서 여러 컨테이너를 가질 수 있습니다.
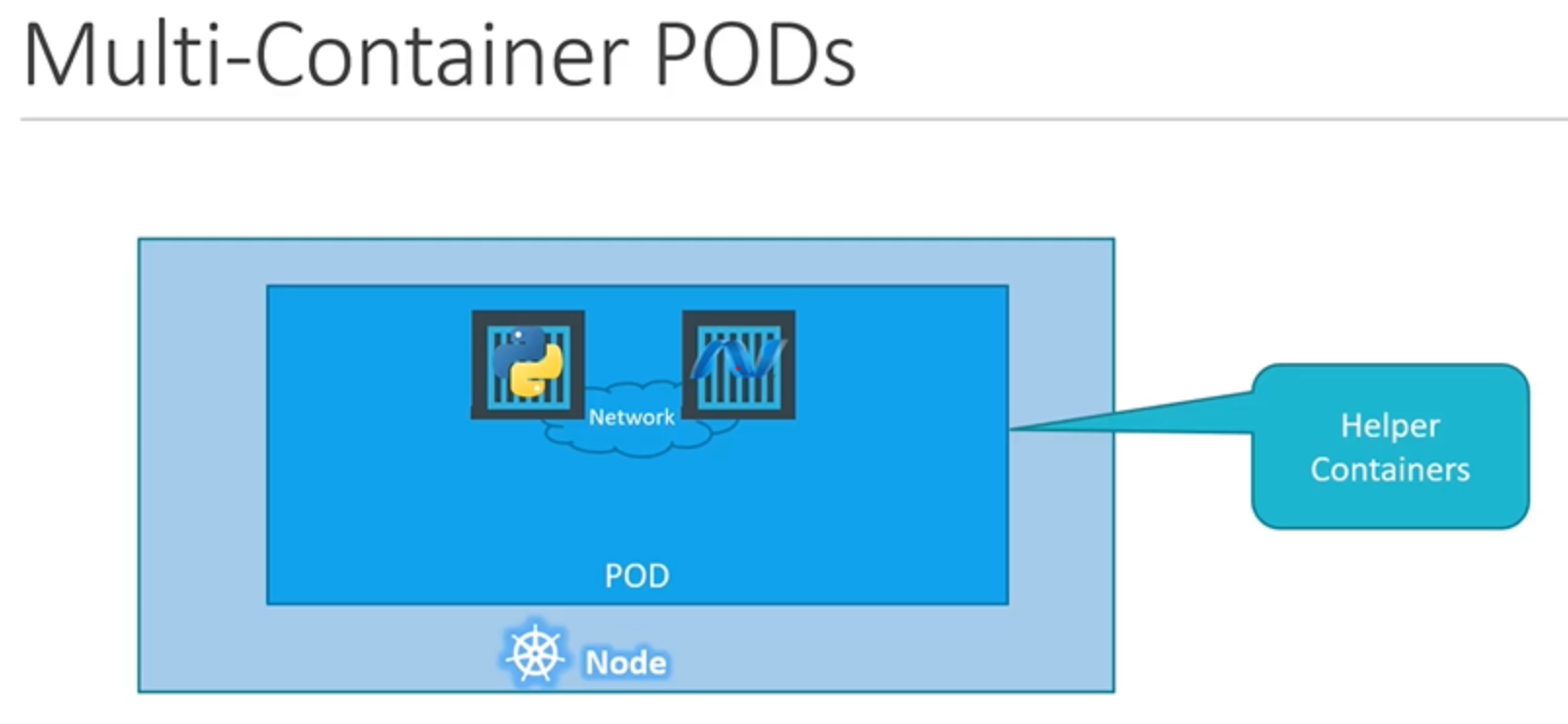
이 경우, 두 컨테이너가 동일한 파드 안에 있기 때문에 새 어플리케이션 컨테이너가 생성되면 헬퍼도 생성되고, 기존 애플리케이션 컨테이너가 죽으면 헬퍼도 죽습니다. 두 컨테이너는 동일한 네트워크 space를 공유하기 때문에 서로를 localhost로 참조하여 직접 소통할 수 있습니다. 또한 동일한 저장 공간을 쉽게 공유할 수도 있습니다.
배포
이제 파드를 배포하는 방법을 살펴보겠습니다. 앞에서 kubectl run 커맨드를 배웠습니다. 이 커맨드가 실제로 수행하는 작업은 파드를 생성하여 Docker 컨테이너를 배포하는 것입니다. 단계별로 더 자세히 살펴보겠습니다.
kubectl run nginx 라는 커맨드를 입력하면, 먼저 파드를 자동으로 생성하고, nginx Docker 이미지의 인스턴스를 배포합니다. 이때 nginx라는 이미지를 가져와야 합니다. 이를 위해 kubectl run nginx --image nginx와 같이, 이미지 이름을 --image 파라미터로 지정해주어야 합니다. 이렇게 하면 도커 허브 레포지토리에서 nginx이미지를 다운로드하게 됩니다. 전에 말씀드린 것과 같이 도커 허브는 다양한 애플리케이션들의 최신 도커 이미지들이 모여 있는 공용 저장소입니다. 우리는 도커 허브나 조직의 프라이빗 저장소에서 이미지를 가져올 수 있도록 쿠버네티스를 구성할 수 있습니다.
이제 파드가 생성되었으므로, 사용 가능한 파드 목록을 보는 방법을 알아보도록 하겠습니다. kubectl get pods커맨드를 사용하면 클러스터의 파드 목록을 볼 수 있습니다.
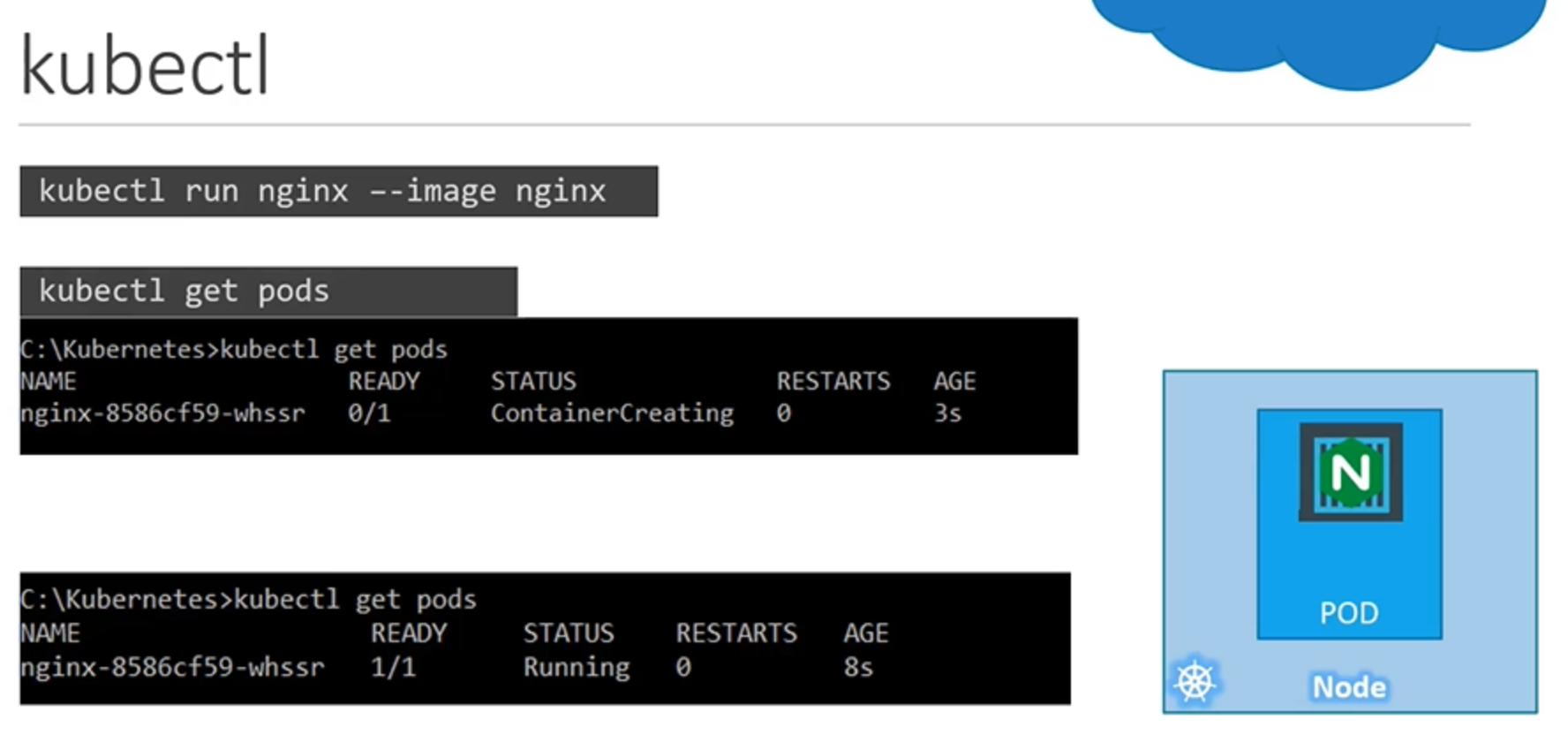
이 경우, 상태가 ContainerCreating인 파드를 볼 수 있습니다. 이 파드는 곧 running상태로 바뀌며 실제로 실행이 됩니다.
YAML in Kubernetes
쿠버네티스는 파드, 레플리카, 배포, 서비스 등과 같은 객체를 생성하기 위해 YAML파일을 입력으로 사용합니다. 이 모든 것들은 비슷한 구조를 가집니다. Kubernetes definition file은 최상위 레벨에 항상 아래 4가지가 포함됩니다.
- apiVersion
- kind
- metedata
- spec
이 4가지는 최상위 레벨(또는 루트 레벨) 속성들이며 필수로 입력해야 하는 속성입니다. 따라서 configuration file에 반드시 필요한 것들입니다. 각각을 자세히 살펴보겠습니다.
ApiVersion
첫번째는 ApiVersion입니다. ApiVersion은 오브젝트를 생성하는 데 사용하는 Kubernetes API 버전을 말합니다. 우리가 어떤 것을 만드려고 하느냐에 따라 올바른 ApiVersion을 사용해야 합니다. ApiVersion에 가능한 값들은 아래와 같습니다.
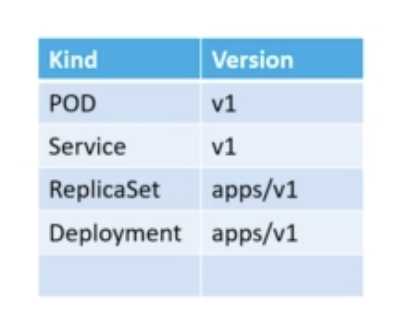
지금은 Pod 작업을 하고 있기 때문에 ApiVersion을 v1으로 설정합니다.
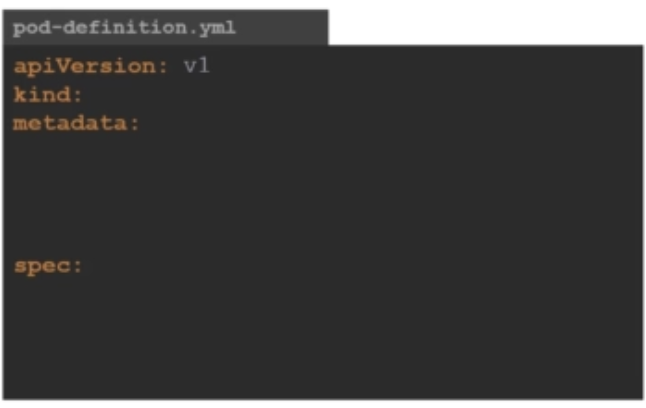
kind
다음은 kind입니다. kind는 우리가 만드려고 하는 오브젝트의 타입을 말합니다. kind에 가능한 값들은 아래와 같습니다.

지금은 Pod를 만드려고 하는 것이므로, Pod라고 넣어주면 됩니다.
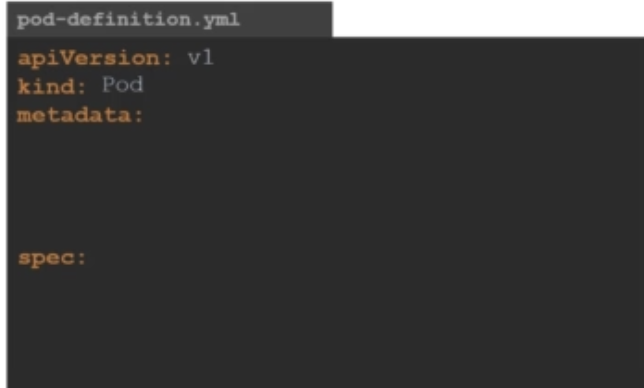
metadata
다음은 metadata입니다. metadata는 name, labels 등과 같이 오브젝트에 대한 데이터들입니다. 아래에서 볼 수 있듯이 ApiVersion과 kind에는 string값을 넣어줬는데, metadata에는 dictionary 값이 들어갑니다.
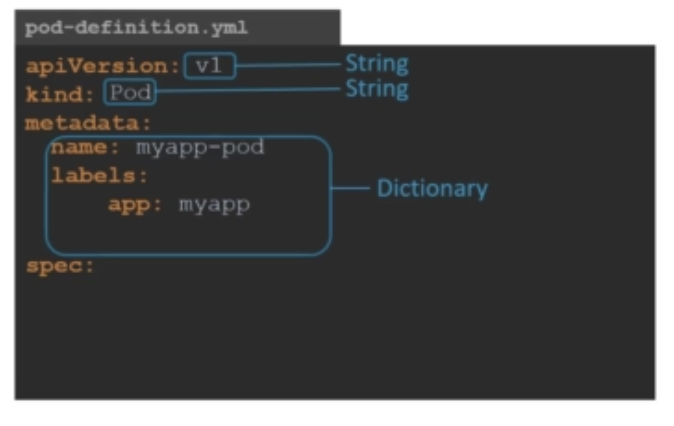
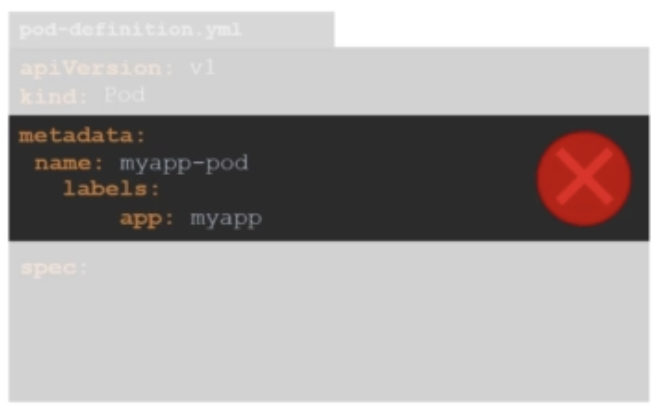
또한 metadata 아래에 있는 값들은 오른쪽으로 들여쓰기가 되어 있어서, name과 label이 metadata의 하위항목이라는 것을 알게 합니다. name과 label 앞에 공백을 몇 칸 두는지는 중요하지 않지만(그러나 공백2칸을 권장합니다), 둘은 sibling 항목이기 때문에 동일하게 공백을 주어야 합니다. 아래와 같이 공백을 다르게 주면, labels를 name의 child항목으로 인식하므로 틀린 예입니다.
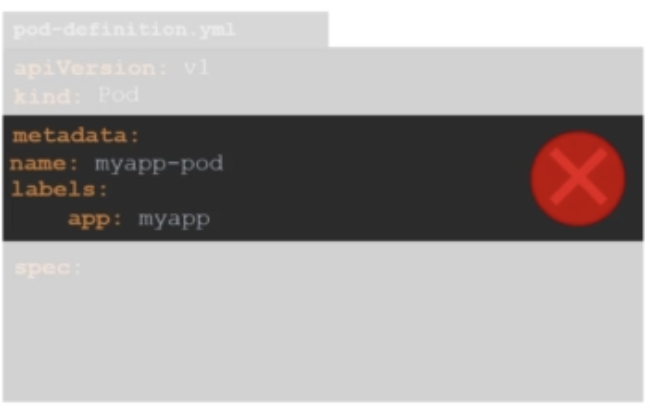
또한 두 속성 앞에는 상위 항목인 metadata보다 더 많은 공백이 있어야 합니다. 이 경우도 틀린 예입니다.
metadata아래에 있는 name에는 Pod의 이름을 지정할 string값이 들어갑니다. labels에는 dictionary값이 들어갑니다. 즉, labels는 metadata dictionary에 있는 dictionary라고 말할 수 있습니다. labels에는 원하는대로 key와 value쌍을 넣을 수 있습니다. 지금은 app: myapp 값을 추가했습니다. 이렇게 적절한 label을 추가할 수 있습니다. label은 나중에 오브젝트를 식별하기 위해 주는 값입니다.
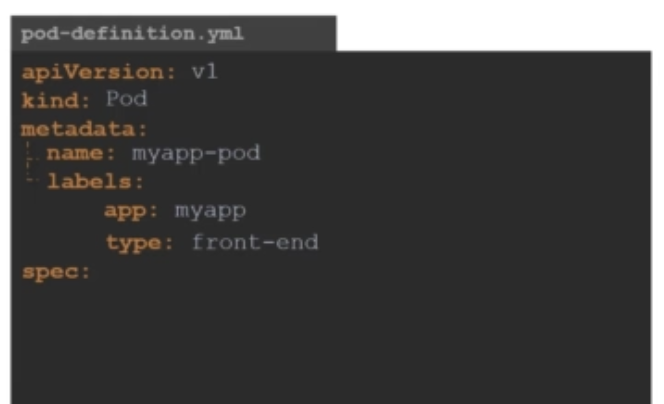
예를 들어 프론트엔드 애플리케이션에서 실행되는 수백 개의 파드가 있고, 백엔드 애플리케이션이나 데이터베이스에서 실행되는 또다른 수백 개의 파드가 있다고 합시다. 이러한 파드들이 모두 배포된 뒤에 프론트엔드, 백엔드끼리 그룹화하는 것은 어려울 것입니다. 따라서 파드에 '프론트엔드', '백엔드', '데이터베이스' 이렇게 label을 달아 놓으면 나중에 이 label을 보고 파드를 필터링할 수 있습니다.
metadata아래에는 name, labels 등 Kubernetes에 미리 지정된 속성들만 추가할 수 있습니다. 우리 마음대로 metadata아래에 속성들을 추가할 수 없습니다. 헷갈리지 않도록 짚고 넘어가면, metadata아래에 labels 아래에는 우리 마음대로 키-값 쌍을 추가할 수 있습니다. 각 속성에 들어갈 수 있는 값들을 잘 이해하는 것이 중요합니다.
spec
현재 우리는 생성할 오브젝트의 타입을 Pod로 정했고, 이름을 'myapp-pod'로 정했습니다. 그런데 아직 컨테이너와 파드에 필요한 이미지를 지정하지 않았습니다. configuration file의 마지막 속성은 spec입니다. 우리가 만들 오브젝트에 따라, 쿠버네티스에 제공할 오브젝트 관련 추가 정보를 작성하는 곳입니다. 이 추가정보들은 오브젝트마다 다릅니다. 따라서 잘 이해하고, 공식 문서를 참조하여 각각에 적합한 포맷을 얻어야 합니다. 지금은 컨테이너 1개를 가진 파드 하나만 생성하기 때문에, 비교적 작성하기 쉽습니다.
spec또한 dictionary입니다. spec아래에 containers라는 속성을 추가합니다. 전에 말씀드린 것과 같이 파드는 여러 컨테이너를 가질 수 있기 때문에 containers 속성은 리스트입니다. 지금의 경우에는 컨테이너 하나만 필요하기 때문에 하나의 containers만 추가해주면 됩니다.
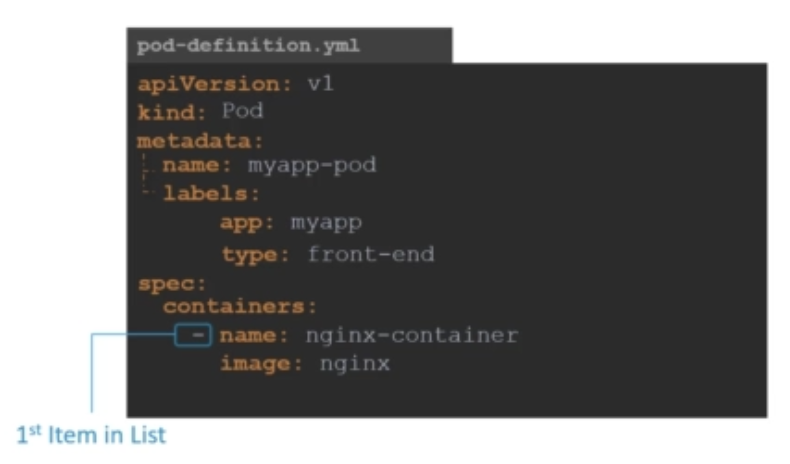
containers 리스트의 아이템에는 name과 image가 key값인 dictionary가 들어갑니다. name 앞에 대시(-)가 붙었는데, 대시는 이것이 리스트의 첫번째 아이템이라는 것을 뜻합니다. container의 name은 'nginx-container'이며, image는 'nginx'입니다. 이 이미지는 도커 레포지토리에 있는 도커 이미지입니다.
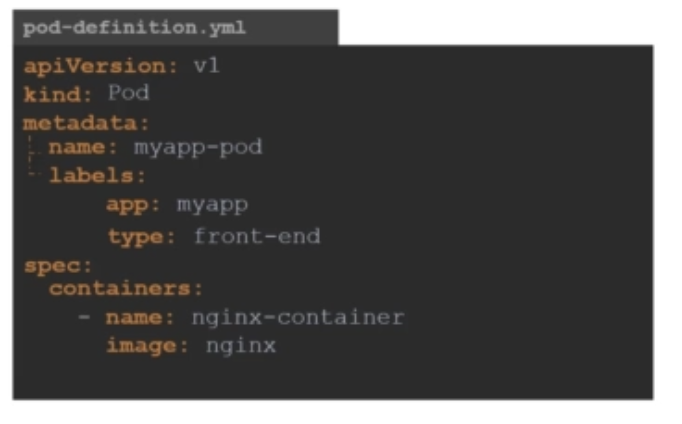
파일이 이렇게 완성되었습니다.
kubectl create -f pod-definition.yml
커맨드를 실행하면 Kubernetes는 파드를 생성합니다.
요약하겠습니다. ApiVersion, kind, metadata, spec 4개의 최상위 속성을 기억하세요. 그 다음, 만드려는 오브젝트에 종속되는 값들을 추가합니다.
테스트 통과 완료

