kubernetes CKA study (31) - Choosing Kubernetes Infrastructure, Configure High Availability, ETCD in HA
kubernetes CKA study

Choosing Kubernetes Infrastructure
쿠버네테스는 다양한 시스템에 다양한 방식으로 배포될 수 있습니다. 노트북에서 시작해서 회사의 물리적 또는 가상 서버 클라우드에서도 가능합니다. 여러분의 요구 사항과 클라우드 생태계 그리고 배포하고자 하는 앱의 종류에 따라 이 솔루션 중 하나를 선택할 수 있습니다.
노트북이나 로컬 기기로 시작하는 방법은 여러 가지가 있습니다. 먼저, 지원되는 Linux 컴퓨터에선 수동으로 바이너리를 설치해 로컬 클러스터를 설정하는 것부터 시작할 수 있습니다. 하지만 그건 너무 지루합니다. 모든 걸 자동화하는 솔루션에 의존하면 몇 분 만에 클러스터를 셋업할 수 있습니다. 그 솔루션은 잠시 후에 살펴보겠습니다.

반면에, Windows에선 쿠버네티스를 처음엔 설정할 수 없습니다. Windows 바이너리가 없으니까요. Hyper-V나 VMware Workstation, Workshop Box 같은 가상 소프트웨어에 의지해야 합니다. Linux VM을 생성하고, 거기에서 쿠버네티스를 실행할 수 있습니다. Windows VM에서 Docker 컨테이너로서의 도커로 쿠버네티스 구성 요소를 실행하는 솔루션도 있습니다. 이때에도 Docker 이미지는 Linux 기반으로 Hyper-V가 Linux Docker 컨테이너를 실행하기 위해 만든 작은 Linux OS에서 실행된다는 것을 기억하세요.
로컬 컴퓨터에서 쿠버네티스를 쉽게 시작할 수 있는 솔루션은 어떤 게 있을까요? Minikube는 단일 노드 클러스터를 쉽게 배포합니다. Oracle Workshop Box 같은 가상화 소프트웨어에 의존해 쿠버네티스 클러스터 구성 요소를 작동하는 워크숍 기기를 만듭니다. kubeadm 툴은 하나의 노드 또는 다중 노드 클러스터를 아주 빨리 배포하는 데 사용됩니다. 하지만 이걸 위해서는 필요한 호스트를 지원되는 구성과 함께 직접 프로비저닝해야 합니다.

처음 두 개와 kubeadm의 차이점은 처음 두 개는 VM이 자체 구성을 지원한다는 겁니다. 반면에 kubeadm은 이미 VM이 프로비전된 것을 기대합니다. kubeadm은 동시에 다중 노드 클러스터도 배포할 수 있습니다. 처음 두 개는 안 그렇죠.
쿠버네티스 클러스터를 노트북에 로컬로 배포하는 건 보통 학습, 테스트 개발 목적으로 합니다. 생산 목적으로 쿠버네티스 클러스터를 시작할 방법은 많습니다. 사설 또는 공용 클라우드 환경을 사용하면 됩니다.

이는 턴키 솔루션이나 Hosted or Managed 솔루션으로 분류됩니다. 턴키 솔루션은 요구되는 VM을 프로비전하는 곳입니다. 툴이나 스크립트를 이용해 쿠버네티스 클러스터를 구성합니다. 가장 중요한 것은 VM을 관리하고 패치하고 업그레이드하는 것을 책임져야 한다는 점입니다.
하지만 클러스터 관리와 유지 관리는 이런 툴과 스크립트를 사용하면 대부분 쉬워집니다. 예를 들어 KOPs 도구를 이용해 AWS에서 쿠버네티스 클러스터를 배포하는 것입니다. 호스트형 솔루션은 서비스 솔루션으로 쿠버네티스와 비슷합니다. 클러스터와 요구되는 VM을 공급자가 배포하고 공급자가 쿠버네티스를 구성하는 것입니다. VM은 공급자에 의해 유지됩니다. 예를 들어, 구글 컨테이너 엔진은 쿠버네티스 클러스터를 몇 분 만에 배포하게 해줍니다. 여러분 혼자 어떤 구성도 실행할 필요 없이 말입니다.
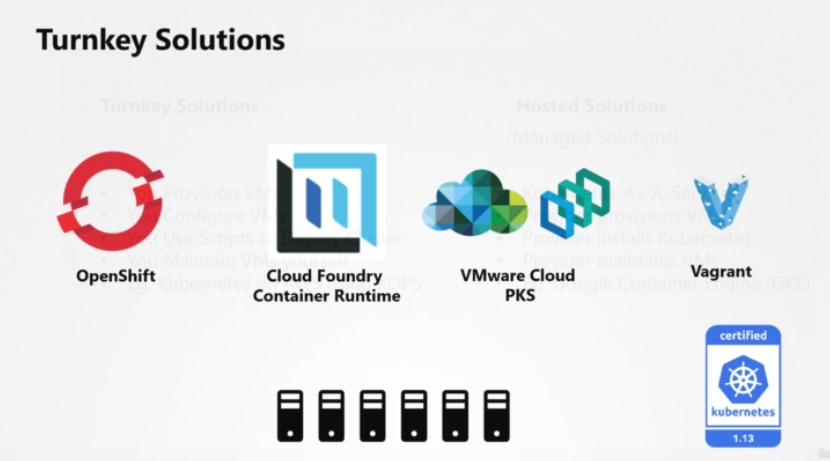
Turnkey Solution
턴키 솔루션에 대해 살펴보겠습니다. OpnShift는 레드 햇의 온프레미스 쿠버네티스 플랫폼입니다. 오픈시프트는 오픈 소스 컨테이너 애플리케이션 플랫폼으로, 쿠버네테스 위에 만들어져 있습니다. 추가적인 툴의 집합과 훌륭한 GUI를 제공해 쿠버네티스의 구성과 CICD 파이프라인을 쉽게 통합할 수 있게 해줍니다. 초급코스에 오픈시프트가 있으니 관심 있으면 한 번 보시기 바랍니다.
Cloud Foundry 컨테이너 런타임은 Cloud Foundry의 OpenSource 프로젝트입니다. Vosch라는 오픈 소스 툴로 고가용성 쿠버네티스 클러스터를 배포 및 관리합니다. 쿠버네티스를 위한 현존하는 VMware 환경을 활용하고 싶다면, VMware 클라우드 PKS 솔루션을 사용하시기 바랍니다. Vagrant는 유용한 스크립트 세트를 제공해 서로 다른 클라우드 서비스 공급자에 쿠버네티스 클러스터를 배포합니다. 이 모든 솔루션은 여러분 회사 내에서 쿠버네티스 클러스터를 배포하고 관리하는 걸 쉽게 해줍니다. 구성이 갖춰진 가상 컴퓨터가 몇 대 있을 것입니다. 이들은 쿠버네티스 인증을 받은 솔루션 중 몇 가지입니다. 더 많은 솔루션들은 쿠버네티스 문서 페이지에서 확인해 보세요.
Hosted Solutions
호스트 솔루션들을 살펴보겠습니다. 구글 컨테이너 엔진은 구글 클라우드 플랫폼의 서비스 제공자로서 아주 인기 있는 쿠버네티스 플랫폼입니다. OpenShift online은 Red Hat이 제공하는 제품으로 온라인에서 완전히 작동하는 쿠버네티스 클러스터에 접속할 수 있습니다. Azure는 Azure 쿠버네티스 서비스를 갖고 있습니다. 마지막으로 쿠버네티스를 위한 아마존 엘라스틱 컨테이너 서비스는 아마존 호스트 쿠버네티스가 제공하는 서비스입니다. 이 솔루션은 일부에 불과합니다. 더 많은 솔루션들이 있습니다.

Our Choice
우리는 지금 쿠버네티스를 학습하는 것이 목적이고 누군가는 공용 클라우드 계정에 액세스할 수 없다는 걸 고려했을 때, 우리는 가상 컴퓨터 로컬 설정을 선호합니다. 우린 로컬 시스템에 로컬 쿠버네테스 클러스터를 처음부터 배포하기로 선택했습니다. VirtualBox에 VM 여러 대를 생성함으로써요.
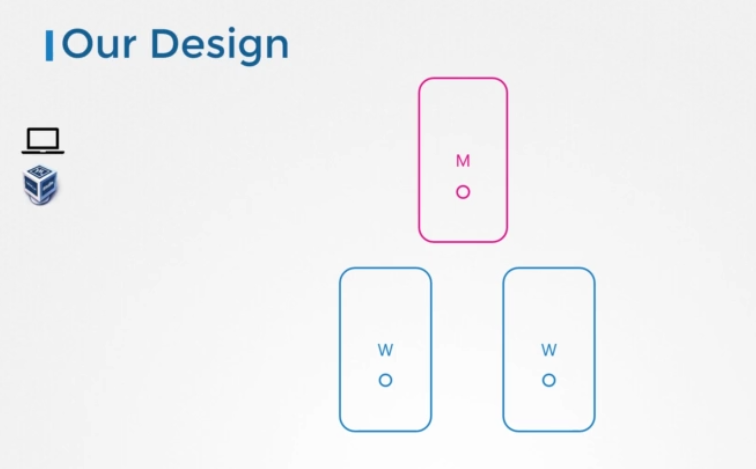
Our Design
이제 우리 설계는 3개의 노드로, 마스터에서 워커노드까지 VM에 프로비전된 Virtual Box에 배포될 것입니다.
Configure High Availability
이제 쿠버네티스의 고가용성(HA)을 살펴보겠습니다.
클러스터의 마스터 노드를 잃어버리면 어떻게 될까요?

워커노드들이 작동하고 컨테이너가 살아 있는 한 어플리케이션은 작동합니다. 사용자는 실패할 때까지 앱에 접속할 수 있습니다. 컨테이너나 파드가 고장 나면 어떻게 될까요? 파드가 레플리카 세트의 일부라면 마스터의 레플리케이션 컨트롤러가 워커노드에게 새 파드를 로드하라고 지시해야 합니다 하지만 지금 마스터는 사용할 수 없죠. 마스터의 컨트롤러와 스케쥴링매니저도 마찬가지고요. 파드를 재현할 사람도 없고 노드에 스케쥴링할 컴포넌트도 없습니다. kube-apiserver도 사용 가능하지 않기 때문에, 관리 목적으로 kubectl 툴이나 API를 통해 외부적으로 클러스터에 액세스할 수 없습니다. 그래서 프로덕션 환경에서 고가용성 구성에서 다중 마스터 노드를 고려해야 하는 것입니다.

고가용성 구성이란 클러스터 내 모든 컴포넌트에 걸쳐 중복을 갖는 것입니다. 단일 실패 지점을 피하기 위해서입니다. 마스터 노드, 워커 노드, 컨트롤 플레인 컴포넌트, 애플리케이션 등이 해당됩니다. 레플리카셋 및 서비스의 형식으로 이미 여러 개의 복사본을 갖고 있습니다.
이번 강의에서는 마스터와 컨트롤플레인 컴포넌트를 중점으로 살펴봅니다. 어떻게 작동하는지 자세히 살펴보겠습니다. 지금까지 3개의 노드가 있는 클러스터에 마스터 1개와 2개의 워커 노드가 있었습니다.
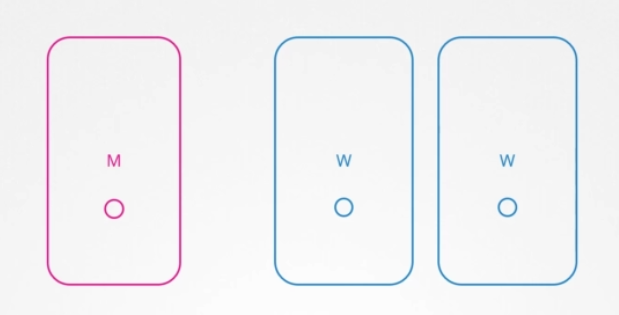
이번 강의에서는 마스터 노드만 집중적으로 살펴보겠습니다. 이미 배웠듯이 마스터 노드는 컨트롤 플레인 컴포넌트를 호스팅합니다 API, 컨트롤러 매니저, 스케줄러, 기타 서버를 포함해서요.
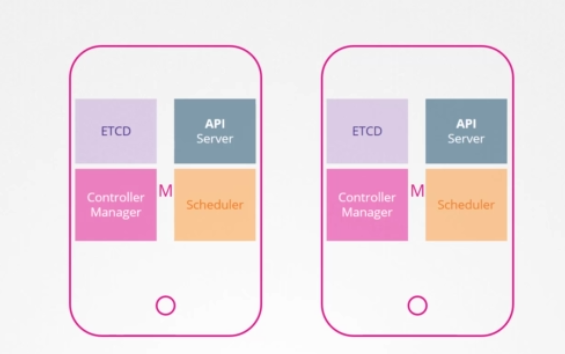
추가 마스터 노드를 설치하면 새로운 마스터에서도 같은 구성 요소가 실행됩니다. 이것은 어떻게 작동할까요? 같은 컴포넌트의 여러 인스턴스를 실행하면 같은 일을 두 번 할까요? 일을 분담할까요? 이것은 어떤 것을 하느냐에 따라 다릅니다.
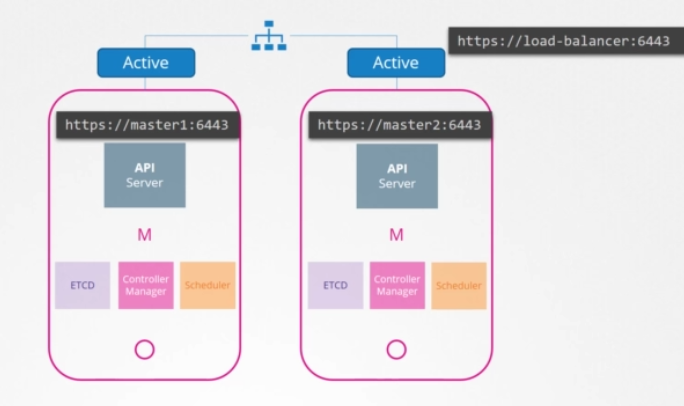
API 서버는 요청을 수신하고 프로세싱하고 클러스터에 관한 정보를 제공할 책임이 있습니다. 한 번에 하나씩 요청에 따라 작업됩니다. 클러스터 노드 전체의 API 서버가 액티브 모드에서 동시에 실행되는 것입니다. 지금까지는 kubectl 유틸리티가 API 서버와 교신해 작업을 완료했습니다. 그 kubectl 유틸리티를 마스터 노드의 포트 6443로 보내도록 했습니다. API 서버가 listening하는 곳입니다. 이건 kube config 파일에서 구성되어 있습니다. 마스터가 둘인데 kbuectl2는 어디 있죠? 어느 쪽이든 요청할 수 있지만 양쪽 다 같은 요청을 해선 안 됩니다. 그래서 API 서버 간의 트래픽을 분할하는 마스터 노드 앞에 일종의 로드밸런서를 갖는 게 좋습니다. 그런 다음 kubectl 유틸리티가 로드밸런서를 가리키게 합니다. 이 목적으로 Nginx나 HA 프록시 또는 다른 로드밸런서를 사용할 수 있습니다.
스케줄러랑 컨트롤러 매니저는 어떨까요? 이 컨트롤러는 클러스터 상태를 보고 행동을 취합니다. 예를 들어 컨트롤러 매니저는 컨트롤러로 구성되어 있는데, 그 중 replication 컨트롤러는 파드 상태를 계속 관찰하다가 파드 하나가 고장 나면 새 파드를 만드는 등 필요한 조치를 취합니다. 다수의 인스턴스가 병렬로 실행되면 작업을 중복하여 필요 이상으로 파드를 늘릴 수 있습니다. 스케쥴러도 마찬가지입니다. 따라서 병렬로 실행되면 안되고, active standby mode로 실행되어야 합니다. 그럼 둘 중 누가 active이고 누가 passive인지 어떻게 결정할까요?
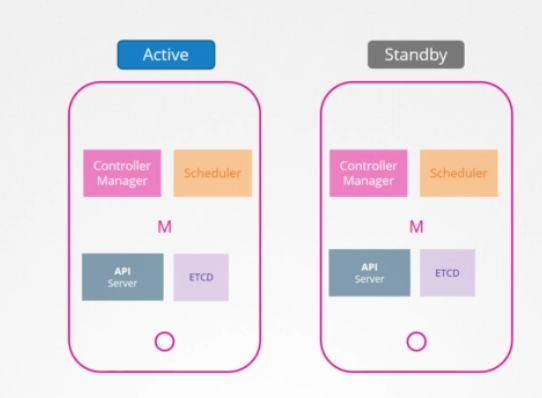
이는 주도적인 선거 과정을 통해 이뤄집니다. 컨트롤러 매니저를 예로 들어보겠습니다.
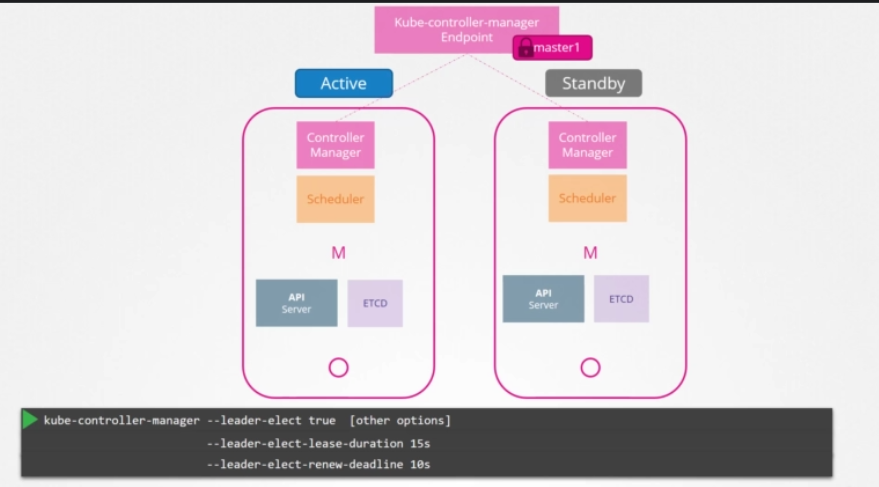
컨트롤러 매니저 프로세스가 구성되면 --leader-elect 옵션을 지정할 수 있습니다. default로 True으로 설정됩니다. 컨트롤러 매니저 프로세스가 시작되면 kube-controller-manager endpoint이라는 이름의 endpoint 오브젝트에 lease나 lock를 얻으려고 합니다. 어떤 프로세스든 해당 정보와 함께 endpoint를 업데이트하는 쪽이 lease를 획득해 둘 중 하나가 활성화되고, 다른 한 명은 passive가 됩니다. default 설정 15초인 --leader-elect-lease-duration 옵션을 이용하여 지정된 lease(임대) 기간을 위한 lock을 설정합니다. active 프로세스가 10초마다 lease를 갱신하는데, 이는 옵션 --leader-elect-renew-deadline 의 default값입니다. 두 과정 모두 leader elect retry period 옵션에서 정한 2초마다 리더가 되려고 노력합니다. 그래야 첫 번째 마스터가 실패해도 두 번째 마스터가 lease를 획득해 리더가 될 수 있습니다. 스케쥴러는 유사한 접근법을 따르고 커맨드라인 옵션은 동일합니다.
다음 단계는 etcd입니다. 앞서 이 코스에서 etcd에 관해 얘기했습니다. 그 과정을 다시 보는것도 좋습니다. 기억을 단축시키기 위해 이 강의에서는 etcd가 어떻게 작동하는지에 관련된 주제를 좀 더 다루겠습니다. 쿠버네티스에서 구성할 수 있는 형태는 두 가지입니다.
Stacked Topology
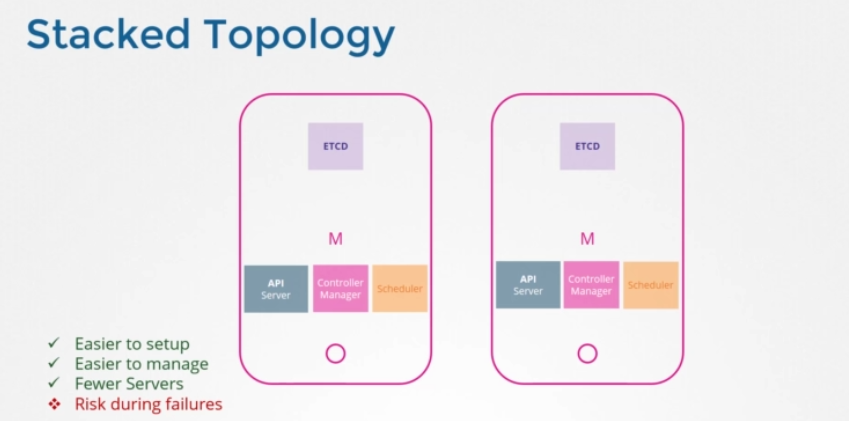
하나는 여기 보이는 것처럼 우리가 이 과정 내내 따라온 동일한 아키텍처입니다. etcd가 쿠버네티스 마스터 노드의 일부입니다. 이를 stacked control plane nodes topology라고 합니다. 설정과 관리가 더 쉽고 노드도 적게 요구합니다. 하지만 한 노드가 다운되면 etcd와 control plane 인스턴스는 둘 다 분실되고 중복은 손상됩니다.
External ETCD Topology
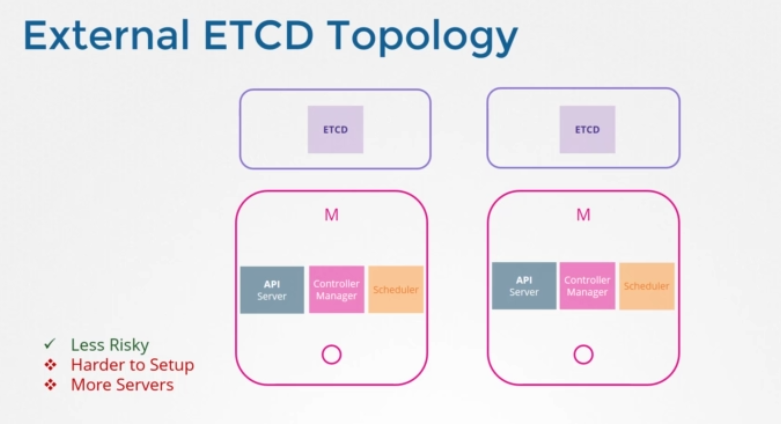
또다른 형태는 etcd가 컨트롤 플레인 노드에서 분리되어 그 자체 서버 세트에서 실행되는 것입니다. topology with external etcd servers입니다. 이전 토폴로지와 비교하면 이것은 덜 위험합니다. 실패한 controlplne이 etcd 클러스터와 저장된 데이터에 영향을 주지 않습니다. 하지만 셋업은 더 어렵고 외부 노드에 대한 서버 수도 두 배가 필요합니다. API 서버는 etcd 서버에 통신하는 유일한 컴포넌트임을 기억하세요. API 서비스 config 옵션을 보면 etcd 서버 위치를 지정하는 옵션 집합이 있습니다. 토폴로지에 상관없이 ETCD 서버 구성 장소가 동일 서버든 분리된 서버든 궁극적으로 API 서버가 etcd 서버의 올바른 주소를 가리키도록 해야만 합니다. etcd는 분산 시스템이란 걸 기억하세요. 따라서 API 서버나, 통신하고자 하는 다른 컴포넌트는 그 인스턴스에서 해당 etcd서버에 도달할 수 있습니다. 이용 가능한 etcd 서버 인스턴스를 통해 데이터를 읽고 쓸 수 있습니다. 이것이 kupe-apiserver configuration에서 etcd 서버 리스트를 명시하는 이유입니다.
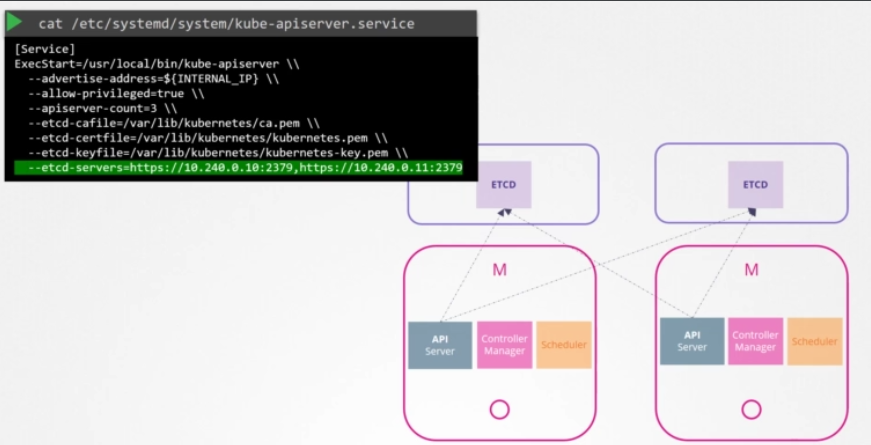
다음 강의에서는 etcd 서버가 클러스터 셋업에서 어떻게 작동하는지와 클러스터에서 권장하는 노드의 개수에 따라 모범 사례를 더 논의하겠습니다.
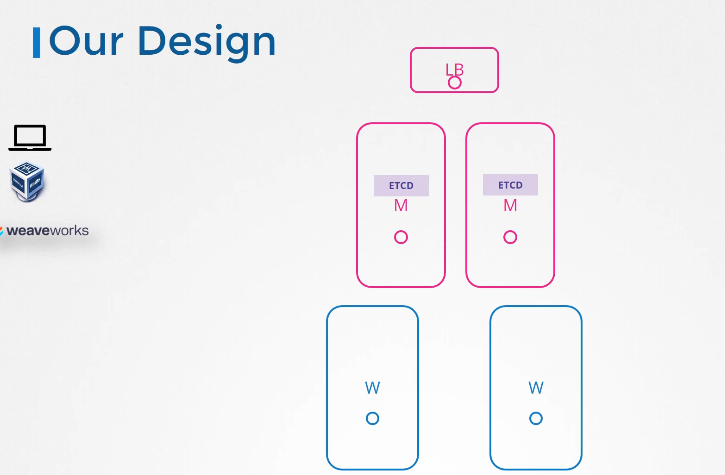
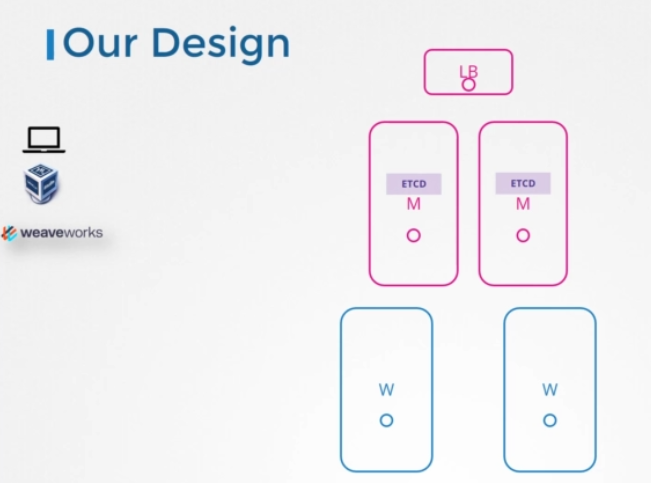
Our Design
다시 디자인으로 돌아가서, 원래는 클러스터의 단일 마스터 노드로 계획했었습니다. 그러나 HA와 함께 여러 마스터를 구성하기로 했습니다. API 서버에 대한 로드밸런서도 언급했습니다. 그것도 다룰 예정입니다. 이제 우리 클러스터엔 총 5개의 노드가 있습니다.
ETCD in HA
ETCD
클러스터의 노드 개수와 래프트 프로토콜 등을 살펴보겠습니다. ETCD가 무엇인가요? 분산되고 신뢰할 수 있는 key value store로 간단하고 안전하며 빠릅니다.
Simple & Fast
전통적인 방법으로는 데이터를 이런 테이블에 정리하고 저장했습니다. 예를 들어 개인의 정보를 저장합니다.
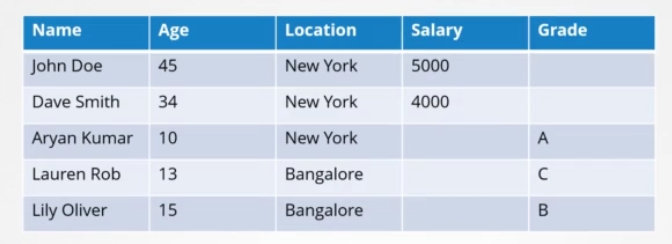
키 밸류 스토어는 문서나 페이지의 형태로 정보를 저장합니다. 각 개인은 문서를 하나 갖고 그 개인에 관한 모든 정보가 해당 파일에 저장됩니다. 이 파일들은 어떤 형식이나 구조로든 존재할 수 있습니다. 한 파일의 변화는 다른 파일에 영향을 주지 않습니다. 이 경우, 근로 개인은 급여 필드가 있는 파일을 가질 수 있습니다. 단순한 키와 값을 저장하고 회수할 수 있는 반면, 데이터가 복잡해지면 일반적으로 JSON이나 YAML 같은 데이터 포맷을 사용하게 됩니다. 이것이 ETCD입니다.

distributed
ETCD가 분산되어있다는 것도 말씀드렸습니다. 이게 무슨 뜻일까요? 이번 강의에서는 이 부분에 집중할 것입니다. 단일 서버에 etcd가 있지만 데이터베이스라 중요한 데이터를 저장할 수 있습니다. 따라서 여러 서버에 걸쳐 데이터 저장소를 가질 수 있습니다.

이제 3개의 서버에 모두 etcd가 실행 중이고 데이터베이스의 동일한 복사본을 유지하고 있습니다. 하나를 잃어도 데이터는 두 개가 남습니다.
Consistent
모든 노드의 데이터가 일관적인지 어떻게 확인하죠? 어떤 인스턴스에서든 쓰고 데이터를 읽을 수 있습니다. ETCD는 데이터의 동일한 복사본이 모든 인스턴스에서 동시에 사용 가능하도록 보장합니다. 어떻게 가능할까요? 읽는 건 쉽습니다. 같은 데이터가 모든 노드에서 사용 가능하기 때문에, 어떤 노드에서든 쉽게 읽을 수 있습니다. 하지만 쓰기는 다릅니다. 2개의 쓰기 요청이 2개의 다른 인스턴스에서 온다면요? 어떤 것이 통과할까요?

예를 들어, 한 쪽 끝에는 John 다른 쪽 끝에는 Joe라는 이름을 쓰도록 했습니다. 물론 두 노드에 두 개의 다른 데이터를 둘 순 없습니다. ETCD는 어떤 인스턴스에도 쓸 수 있다고 했는데 100% 맞는 건 아니었습니다. ETCD는 노드마다 쓰기를 처리하지 않습니다. 대신 한 인스턴스만이 쓰기를 처리합니다.
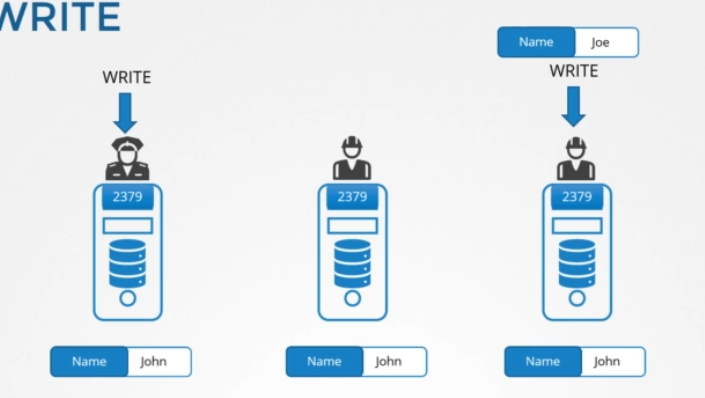
내부에서 두 노드가 선출하는 리더는 하나 입니다. 전체 인스턴스에서 노드 하나는 리더가 되고 다른 노드는 팔로워가 됩니다. 쓰기가 리더 노드를 통해 들어오면 리더가 쓰기를 처리하고, 리더가 다른 노드들에게 데이터 복사본을 보내도록 합니다. 팔로워 노드를 통해 쓰기가 들어오면 팔로워 노드가 리더에게 쓰기를 전달하고 리더는 쓰기를 처리합니다. 쓰기가 처리되면 리더는 쓰기의 복사본이 클러스터의 다른 인스턴스로 분산되도록 보장합니다. 따라서 집단의 다른 멤버들로부터 리더가 동의를 얻어야만 완성된 것으로 간주됩니다.
Leader election - RAFT
그럼 리더 선출은 어떻게 할까요? 쓴 글이 모두에게 퍼지는 걸 어떻게 보장할까요? raft 프로토콜을 이용해 distributed consensus을 구현합니다. 세 노드 클러스터에서 어떻게 작동하는지 보겠습니다.
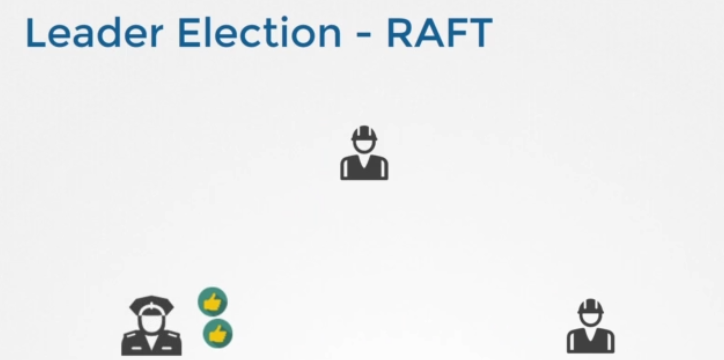
클러스터가 설정될 때, 3개의 노드에는 지도자가 선출되지 않았습니다. raft 알고리즘은 무작위로 타이머를 맞춰 신호를 보냅니다. 예를 들어 3명의 매니저에게 무작위 타이머가 작동하죠 타이머가 먼저 완료된 매니저가 다른 노드에게 리더가 될 권한을 투표합니다. 다른 매니저들의 투표로 요청에 대한 답변을 받으면 그 노드가 리더 역할을 맡습니다. 이제 리더로 선출됐으니 다른 마스터들에게 주기적으로 정기적으로 공지를 보내 자신이 계속 리더의 역할을 하고 있다고 알립니다.
다른 노드들이 리더로부터 어떤 시점에 알림을 받지 못할 수 있습니다. 리더가 다운되었거나 네트워크 연결이 끊겼기 때문일 수 있습니다. 그러면 노드들 사이에서 재선 프로세스를 시작합니다. 새 리더가 선출되는 것입니다.
이전 예제로 돌아가겠습니다. 쓰기가 들어오면 리더에 의해 처리되고, 클러스터 내 다른 노드로 복제됩니다. 쓰기는 클러스터의 다른 인스턴스로 복제됐을 때만 완료된 것으로 간주됩니다. ETCD 클러스터는 고가용성이라고 했습니다. 즉, 노드를 잃어도 기능은 할 것입니다.
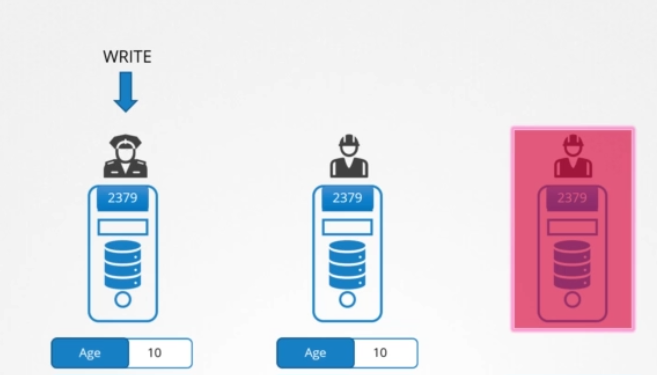
가령, 새 쓰기가 들어왔는데 노드 하나가 응답하지 않는다고 칩시다. 따라서 리더가 클러스터에서 두 노드에만 쓸 수 있습니다. 이 때 다 쓴 건가요? 아니면 세 번째 노드가 올라올 때까지 기다려야 하나요? 아니면 실패한 걸까요? 이 때는 클러스터 내 대부분의 노드에 쓰기가 되었다면 완료로 간주합니다. 가령, 노드가 3개면 대다수는 2개 입니다. 데이터가 두 개의 노드에 작성될 수 있다면 쓰기 완료로 간주됩니다. 세 번째 노드가 온라인이 되면, 데이터도 거기에 복사됩니다.
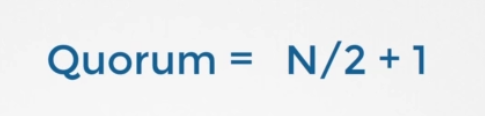
여기서 대다수는 무엇인가요? quorum이라고 하는 게 더 적절하겠네요. quorum은 클러스터가 제대로 기능하고 성공적으로 쓰기우해 반드시 필요한 최소의 노드 수입니다. N이 3이면 2인 것입니다. 어떤 노드든 쿼럼은 노드를 2로 나누고 1을 더한 수입니다.

여기 1부터 7까지 클러스터의 쿼럼을 보여주는 표가 있습니다. 인스턴스1의 쿼럼은 1입니다. 그 말은 단일 노드 클러스터라면 이런 건 프로토콜이 적용이 안 된다는 것입니다. 그 노드를 잃으면 모든 게 사라집니다. 두 개를 보고 같은 공식을 적용하면 쿼럼은 2입니다. 클러스터에 인스턴스가 2개라도 대다수는 여전히 2입니다. 하나가 실패하면 쿼럼이 없어 쓰기도 할 수 없습니다. 인스턴스가 2개인 건 1개인 것과 같습니다. 쿼럼이 충족될 수 없는 어떤 실질적 가치도 제공하지 않습니다. 그래서 추가적인 클러스터에 최소 3개의 인스턴스를 갖도록 권장하는 것입니다. 그렇게 하면 적어도 한 노드의 결함 허용 내역을 제공합니다. 하나를 잃어도 쿼럼을 가질 수 있고 클러스터는 계속 기능할 것입니다.
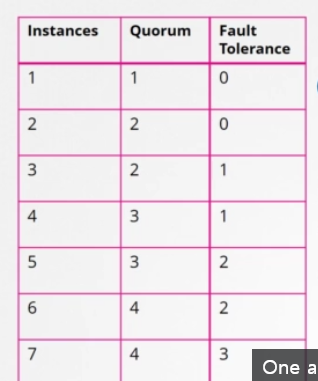
첫 번째 칼럼에서 두 번째 칼럼을 뺀 것을 fault tolerance 라고 합니다. 클러스터가 작동하는 동안 손실할 수 있는 노드의 수입니다. 노드가 1개에서 7개가 있습니다. 1개과 2개의 상황은 제외하고 3개부터 7개까지 뭘 고려해야 할까요? 보시다시피 3개와 4개의 fault tolerance는 1로 같습니다. 5개와 6개의 fault tolerance는 2로 같아요. 마스터 노드의 수를 정할 때는 테이블에서 강조했듯이 홀수를 선택해야 합니다. 3개, 5개, 7개처럼요. 노드 클러스터가 6개라고 치겠습니다. 예를 들어 네트워크의 교란으로 인해 망이 실패해 네트워크가 분할되었습니다. 1번 노드에는 4개, 다른 노드에는 2개가 있습니다. 이 경우 4개의 노드를 가진 그룹은 쿼럼이 있고 정상적으로 작동합니다. 하지만 네트워크가 다른 방법으로 파티션을 가지면 노드가 둘 사이에 동등하게 분배됩니다. 각 그룹은 3개의 노드만 가지게 되죠. 그런데 원래 노드가 6개였기 때문에 클러스터가 계속 살려면 쿼럼이 4개여야 합니다.
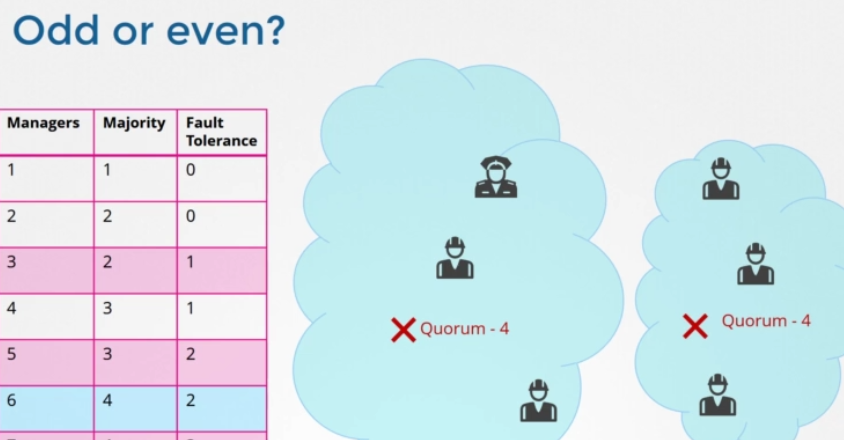
하지만 여기 그룹을 보시면 이 그룹들은 쿼럼에 부합하는 관리자가 네 명이 없습니다 따라서 실패한 클러스터로 끝나게 됩니다. 따라서 노드의 수가 짝수일 경우, 네트워크 세분화 중 클러스터 결함이 발생할 가능성이 있습니다. 원래 매니저 수가 홀수였다면 (예를 들어 7명) 네트워크 세그먼트화 이후 한 세그먼트화 네트워크에서 4명 다른 세그먼트화 네트워크에서 3명이 됩니다. 그래서 우리 클러스터는 여전히 관리자가 4명인 그룹에 살아있습니다. 4명의 쿼럼을 충족하면서요. 네트워크 세그먼트가 어떻든, 홀수 노드의 네트워크 세그먼트화 경우 클러스터가 생존할 확률이 더 높습니다. 따라서 짝수보다 홀수 노드가 선호됩니다. 5개가 6개보다 낫고, 노드가 5개 이상이면 충분합니다. 5개는 fault tolerance이 충분하니까요.
Getting Started
서버에 설치하려면 최신 지원되는 바이너리를 다운로드하고 그걸 압축해 필수 디렉터리 구조를 생성하고 추가로 생성된 인증서 파일 위로 복사하세요. TLS 인증서 섹션에서 이 인증서 생성 방법을 상세히 논의했습니다.
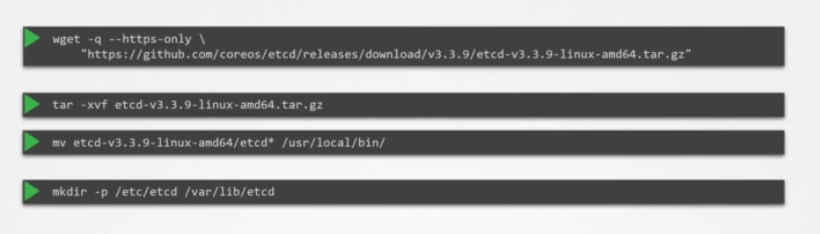
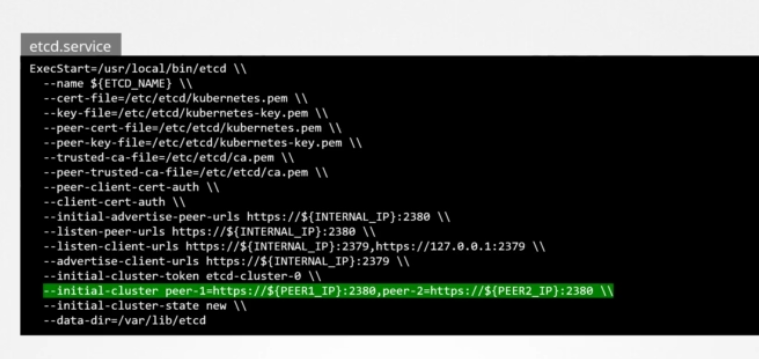
그런 다음 etcd 서비스를 구성합니다. 여기서 중요한 건 피어 정보를 전달하는 초기 클러스터 옵션입니다. 각 별도의 서비스가 그것을 통해 클러스터의 일부와 피어가 어디 있는지 알게 됩니다.
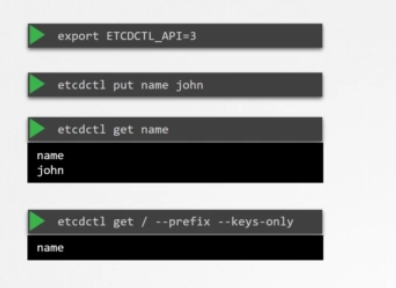
ETCDCTL
설치 및 환경 설정이 끝나면 etcdctl 유틸리티를 이용해 데이터를 저장 및 검색하세요. 이 etcdctl 유틸리티는 두 가지 API 버전이 있습니다. V2와 V3입니다. 그래서 버전마다 명령이 다릅니다. 버전 2는 디폴트값입니다. 하지만 버전 3을 사용할 것입니다. 환경 변수 ETCDTL_API를 3으로 설정하세요. 안 그러면 하위 명령이 안 먹힙니다. etcdctl put 명령을 실행하고 키를 이름과 값으로 지정하세요. 데이터를 검색하려면 키 이름이 적힌 etcdctl get 커맨드를 실행하고 존이라는 값을 반환합니다. 모든 키를 찾으려면 --keys-only를 입력하세요.
Number of Nodes
설계로 돌아가서 클러스터에 노드가 몇 개 있어야 하죠? HA 환경에서 보다시피 인스턴스 한두 개를 갖는 건 말이 안 됩니다. 노드 하나를 잃으면 쿼럼 없이 남겨지게 되고 클러스터가 비기능 상태가 됩니다. 따라서 HA에서 필요한 최소 노드는 3개입니다. 짝수보다 홀수가 좋은 이유도 얘기했습니다. 같은 수의 인스턴스를 갖는 것은 특정 네트워크 파티션 시나리오에서 쿼럼 없이 클러스터를 떠날 수 있습니다. 짝수 노드는 범위를 벗어납니다.
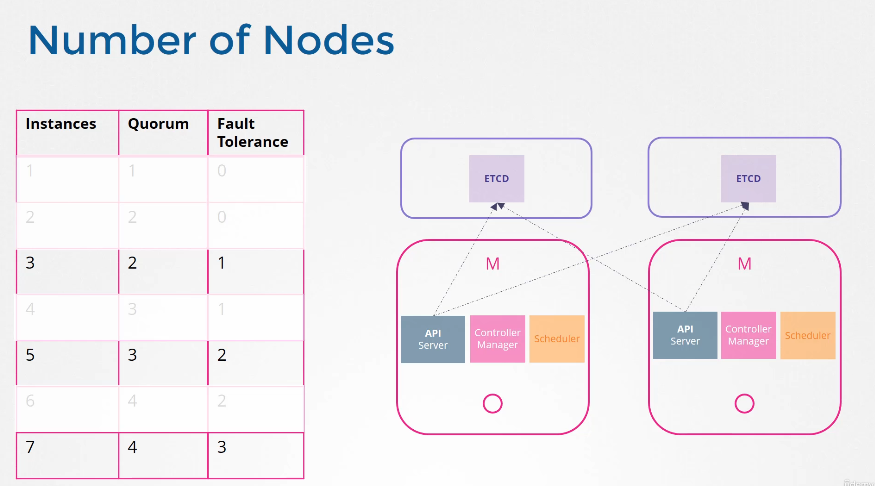
그럼 이제 3, 5, 7이나 그 위의 홀수만 남았습니다. 3개도 좋지만 내결함성(fault tolerance)이 높은 걸 원한다면 5개가 더 좋아요. 그 이상은 불필요합니다. 여러분의 환경, fault tolerance, 요구 사항,그리고 감당할 수 있는 비용을 고려할 때 이 목록에서 숫자 하나를 골라야 합니다. 우리 경우엔 3입니다.
Our Design
지금 우리 설계는 어떤가요? HA는 내결함성을 위해 필요한 최소 노드 수가 3개입니다. 마스터 노드가 3개면 좋겠지만 노트북 용량에 한계가 있어서 2개로 하겠습니다. 하지만 다른 환경에서 셋업을 배포하고 충분한 용량을 확보한다면 3개를 사용하세요. 또한 스택된 topology를 선택했습니다. 마스터 노드 자체에 여러 서버들이 있는 형태입니다.