kubernetes CKA study (33) - Application Failure, Control Plane Failure, Worker Node Failure, Network Troubleshooting
kubernetes CKA study

Application Failure
애플리케이션 오류부터 시작하겠습니다.
Check Accessibility
웹과 데이터베이스를 가지고 있는 2계층 애플리케이션이 있습니다. 데이터베이스 파드는 데이터베이스 애플리케이션을 호스팅합니다. 그리고 데이터베이스 서비스를 통해 웹 서버에 서비스를 제공합니다. 웹 서버는 웹 파드에서 호스팅되고 웹 서비스를 통해 유저에게 서비스를 제공합니다.
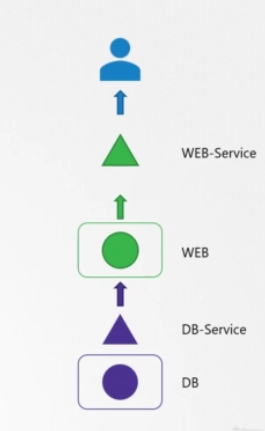
시작하기 전에 애플리케이션이 어떻게 구성되어 있는지 글을 쓰거나, map이나 표를 그려보는 것이 좋습니다. 오류에 대해 얼마나 알고있느냐에 따라 map의 양쪽 끝 중 어디에서 시작할 지 선택할 수 있습니다. 그러나 문제의 근본적인 원인을 찾을 때까지는 이 map에 있는 모든 오브젝트와 링크를 확인해야 합니다.
이번에는 유저가 애플리케이션 접근과 관련된 몇가지 이슈를 보고했다고 합시다. 그렇다면 먼저 애플리케이션 프론트엔드부터 시작합니다. 애플리케이션에 접근할 수 있는 경우에는 표준 테스트 방법을 사용하세요. 웹 애플리케이션인 경우에는 curl을 사용하여 웹 서버가 노드 포트의 IP에 접근할 수 있는지 체크하면 됩니다.

Check Service Status
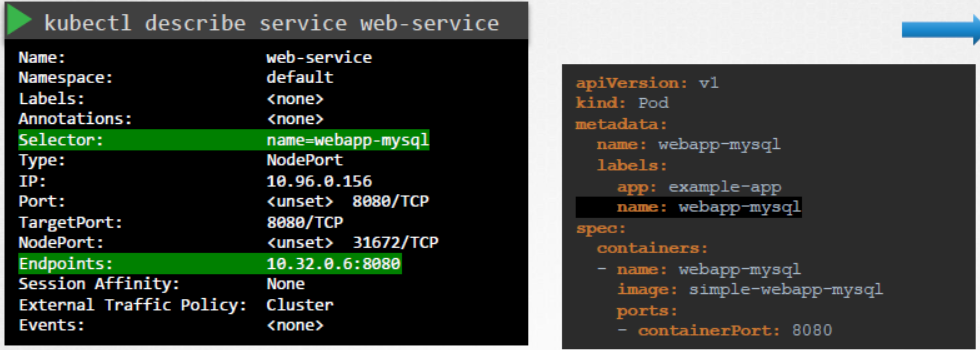
다음으로는 서비스를 체크합니다. 웹 파드의 endpoint를 발견했나요?
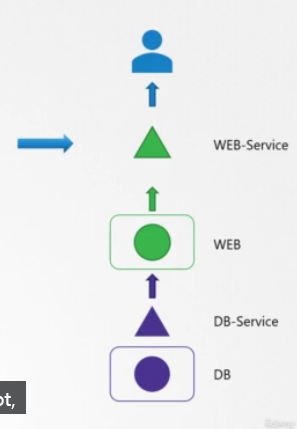
이 경우엔 찾았지만, 만약 못 찾았다면 파드 디스커버리 서비스를 체크하세요.
서비스에서 구성된 selector와 파드에 있는 항목을 비교하고 일치하는지 확인하세요.
Check POD
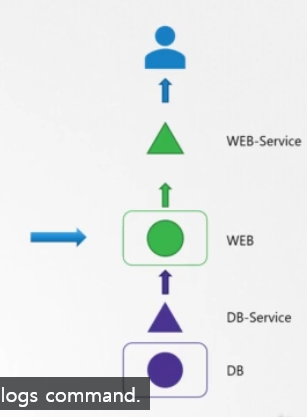
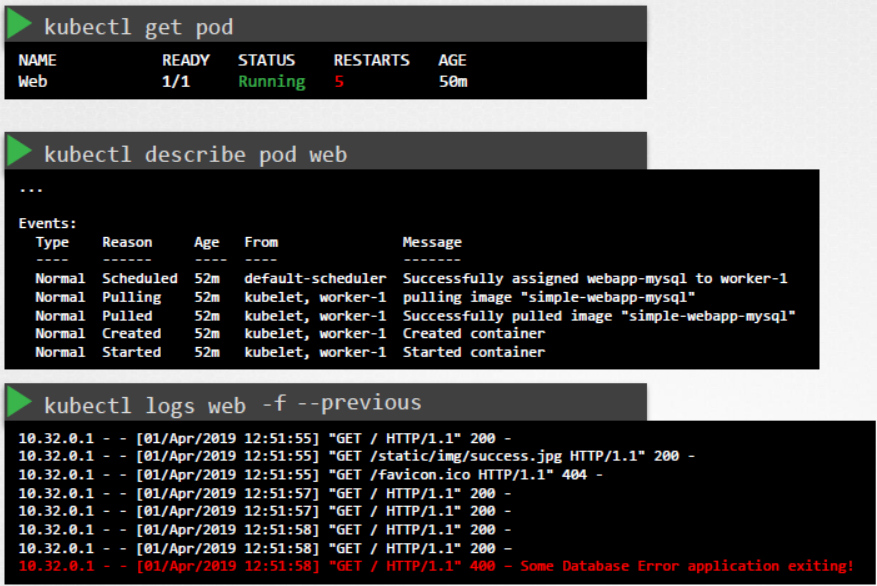
다음으로 파드가 Running state인지 확인합니다.

파드의 STATUS와 RESTARTS를 보면 파드에 있는 앱이 작동하는지, 재시작되는지 알 수 있습니다.
logs 커맨드로 애플리케이션 로그를 확인할 수 있습니다. 오류로 인해 파드가 다시 시작되는 경우, 현재 버전의 컨테이너를 실행 중인 파드의 현재 버전 로그에는 마지막으로 실패한 이유가 반영되지 않을 수 있습니다.
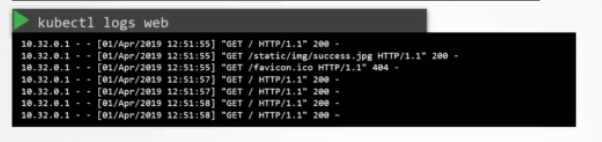
따라서 -f 옵션을 이용해서 로그를 관찰하고 애플리케이션이 다시 실패하길 기다리거나, --previous 옵션으로 이전 파드의 로그를 봐야 합니다.
Check Dependent Service
그 다음, 아까처럼 DB 서비스 상태를 체크하고, 마지막으로 DB 파드를 체크합니다.
DB 파드의 로그를 확인하고 데이터베이스에 오류가 있는지 확인합니다.
테스트 문제 기록
Control Plane Failure
Troubleshooting Test 1: A simple 2 tier application is deployed in the alpha namespace. It must display a green web page on success. Click on the App tab at the top of your terminal to view your application. It is currently failed. Troubleshoot and fix the issue.
mysql application 에 접근할 수 없는 상황이었음
k describe deployments.apps -n alpha webapp-mysql
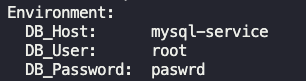
k get svc -n alpha
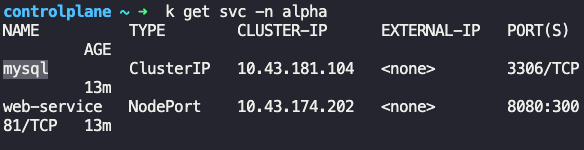
DB_HOST값을 다른 값을 참조하고 있었음. 따라서 서비스에서 name 수정으로 해결
Troubleshooting Test 2: The same 2 tier application is deployed in the beta namespace. It must display a green web page on success. Click on the App tab at the top of your terminal to view your application. It is currently failed. Troubleshoot and fix the issue.
mysql application 에 접근할 수 없는 상황이었음
k describe -n beta svc mysql-service
service 의 target port가 3306이어야하는데 8080 이었음
Troubleshooting Test 3: The same 2 tier application is deployed in the gamma namespace. It must display a green web page on success. Click on the App tab at the top of your terminal to view your application. It is currently failed or unresponsive. Troubleshoot and fix the issue.
k describe pod -n gamma mysql
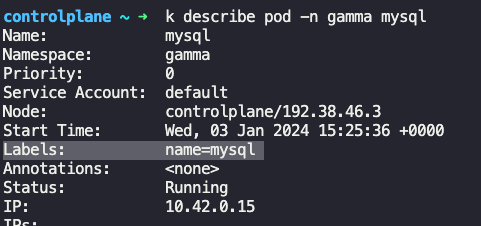
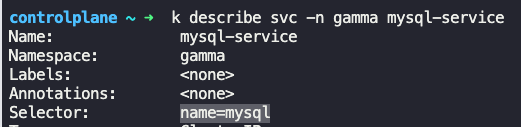
selector가 다르게 되어있어서 수정함
테스트 통과 완료

Control Plane Failure
이번 강의에서는 control plane 장애를 해결하는 다양한 방법을 살펴보겠습니다.
먼저 클러스터에 있는 노드의 상태를 확인하여 모두 정상인지 확인합니다.
kubectl get nodes
그런 다음 클러스터에서 실행 중인 파드의 상태를 확인합니다.
kubectl get pods
Kubeadm 도구로 배포된 클러스터의 경우, 컨트롤 플레인 컴포넌트가 파드로 배포된 경우, kube-system 네임 스페이스에 있는 파드가 실행 중인지 확인할 수 있습니다.
kubectl get pods -n kube-system
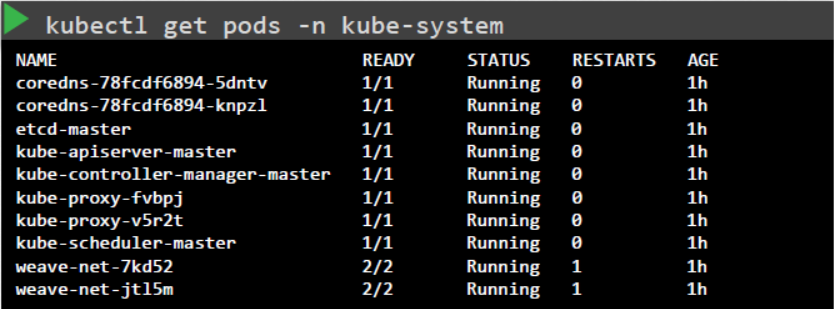
또는 우리의 경우처럼 컨트롤 플레인 컴포넌트가 서비스로 배포된 경우라면 마스터 노드에서 kube API 서버, 컨트롤러 매니저 및 스케줄러, 워커 노드에서 kubelet 및 kube 프록시 서비스와 같은 서비스 상태를 모두 확인해야 합니다.
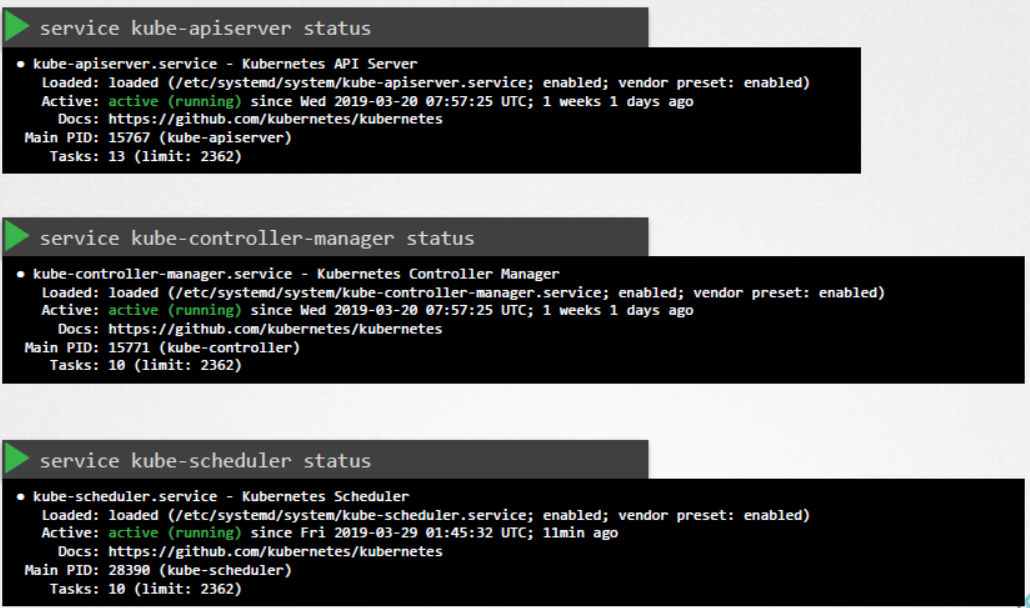
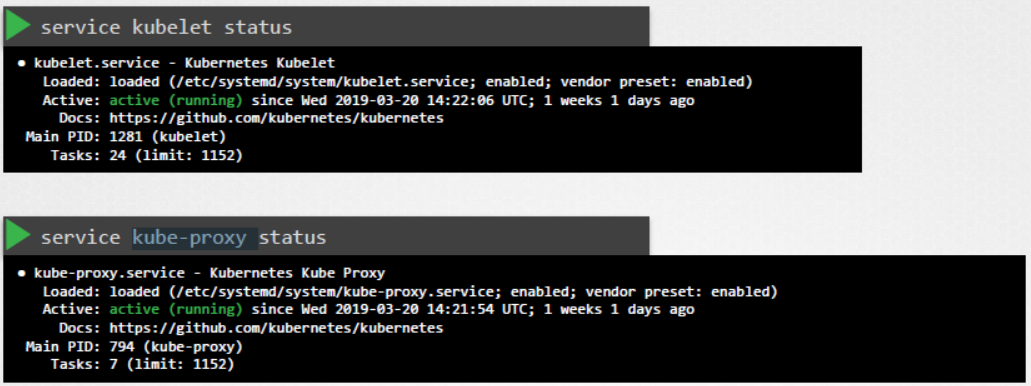
다음으로 컨트롤 플레인 컴포넌트의 로그를 확인합니다. 마찬가지로 kubeadm의 경우, 컨트롤 플레인 컴포넌트를 호스팅하는 파드의 로그를 보려면 kubectl logs 커맨드를 사용합니다.
kubectl logs kube-apiserver-master -n kube-system
마스터 노드에 기본적으로 구성된 서비스의 경우, 호스트 로깅 솔루션을 사용하여 서비스 로그를 확인합니다. 우리의 경우, journalctl 유틸리티를 사용하여 kube API 서버의 로그를 볼 수 있습니다.
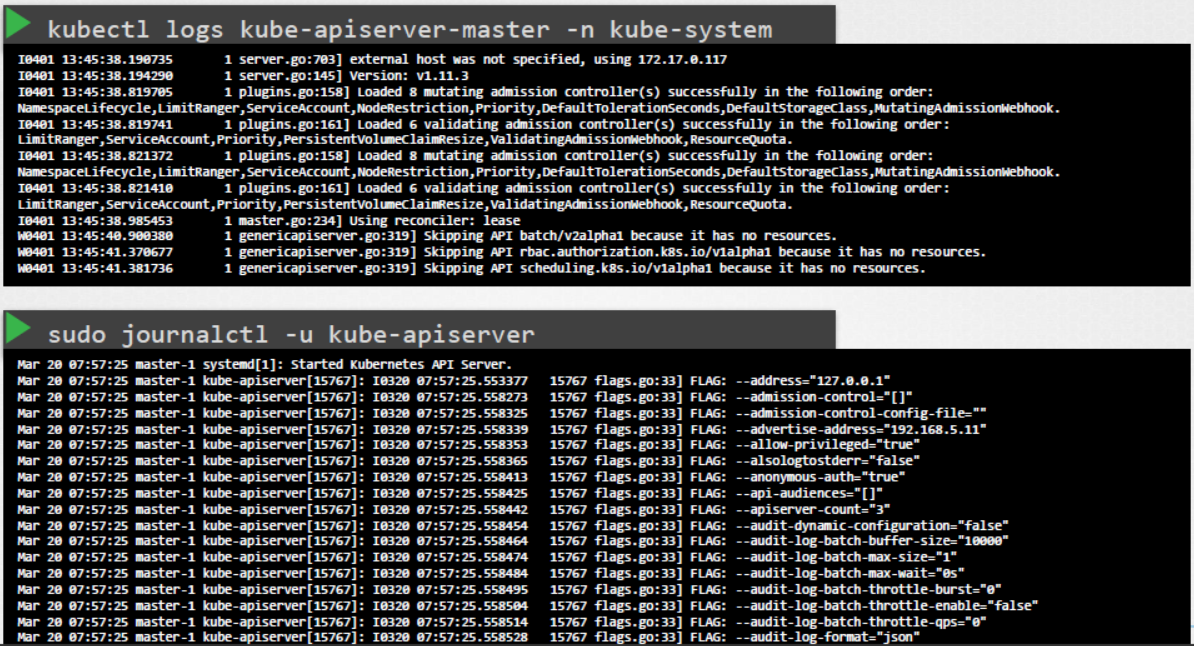
테스트 문제 기록
The cluster is broken. We tried deploying an application but it's not working. Troubleshoot and fix the issue.
kube-scheduler pod에 문제가 생겨서 /etc/kubernetes/manifests/kube-scheduler.yaml 파일에 오타를 수정해줬음
Even though the deployment was scaled to 2, the number of PODs does not seem to increase. Investigate and fix the issue.(scale 2로 증가했는데 생성되지 않는 이유 찾기)
k get po -n kube-system
kube-controller pod에 문제가 있는 걸 파악함
k logs -n kube-system kube-controller-manager-controlplane
로그확인 command가 이상하다라는 로그발견
/etc/kubernetes/manifests/kube-controller-manager.yaml
오타 수정
테스트 통과 완료

Worker Node Failure
Check Node Status
이번에도 클러스터의 노드 상태를 확인하는 것부터 시작합니다.
kubectl get nodes
노드가 모두 Ready로 보이나요, 아니면 NotReady가 보이나요?
NotReady가 있는 경우, kubectl describe node 명령을 사용하여 노드에 대한 세부 정보를 확인합니다.
kubectl describe node worker-1

각 노드에는 노드가 실패한 이유를 알려줄 수 있는 Conditons가 있습니다. Status는 True 또는 False 또는 Unknown으로 설정됩니다. 노드에 디스크 공간이 부족하면 OutOfDisk 플래그가 true로 설정됩니다. 노드에 메모리가 부족하면 MemoryPressure가 true로 설정됩니다. 디스크 용량이 부족하면 DiskPressure 플래그가 true로 설정됩니다. 마찬가지로 프로세스가 너무 많으면 PIDPressure 플래그가 true로 설정됩니다. 마지막으로, 노드 전체가 정상인 경우, Ready 플래그가 true로 설정됩니다. 크래시로 인해 워커 노드가 마스터와의 통신을 중단하면 이러한 상태는 Unknown으로 설정됩니다. 이는 노드의 손실 가능성을 나타냅니다. LastHeartbeatTime 필드를 확인하여 노드가 크래시된 가능성이 있는 시간을 알아보세요.
Check Node
이러한 경우에는 노드 자체의 상태를 확인합니다. 노드가 온라인 상태(?)이거나 크래시된 경우, 크래시가 발생한 경우 노드를 다시 시작합니다. 노드에 가능한 CPU 메모리와 디스크 공간이 있는지 확인합니다.
Check Kubelet Status
kubelet의 상태를 확인합니다. kubelet 로그에서 가능한 문제를 확인합니다. kubelet 인증서를 확인합니다. 만료되지 않았는지, 올바른 그룹에 속해 있는지, 인증서가 올바른 CA에서 발급되었는지 확인합니다.
테스트 문제 기록
Fix the broken cluster
k get nodes 로 node01 에 이슈확인
ssh node01로 들어와서
systemctl status containerd active상태확인
systemctl status kubelet load상태 확인
systemctl start kubelet으로 켜주고 해결
The cluster is broken again. Investigate and fix the issue.
k get nodes 에서 node01 이슈확인
node01 에서 journalctl -u kubelet 로그확인
May 30 13:08:20 node01 kubelet[4554]: E0530 13:08:20.141826 4554 run.go:74] "command failed" err="failed to construct kubelet dependencies: unable to load client CA file /etc/kubernetes/pki/WRONG-CA-FILE.crt: open /etc/kubernetes/pki/WRONG-CA-FILE.crt: no such file or directory"
/var/lib/kubelet/config.yaml 에서 경로 오타 수정
Network Troubleshooting
Network Plugin in Kubernetes
쿠버네티스는 CNI 플러그인을 사용하여 네트워크를 설정합니다. kubelet은 플러그인을 실행할 책임이 있습니다.
-
cni-bin-dir: kubelet은 시작 시 이 디렉터리에서 플러그인을 검색합니다.
-
network-plugin: cni-bin-dir에서 사용할 네트워크 플러그인. 플러그인 디렉토리에서 프로브된 플러그인이 보고한 이름과 일치해야 합니다.
사용 가능한 플러그인은 여러 가지가 있으며 아래는 몇 가지 플러그인입니다.
- Weave Net:
To install,
kubectl apply -f https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml
네트워크 플러그인에 대한 자세한 내용은 다음 문서에서 확인할 수 있습니다. :
https://kubernetes.io/docs/concepts/cluster-administration/addons/#networking-and-network-policy
- Flannel :
To install,
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml
참고: 현재 flannel은 쿠버네티스 네트워크 정책을 지원하지 않습니다.
- Calico :
To install,
curl https://docs.projectcalico.org/manifests/calico.yaml -O
Apply the manifest using the following command.
kubectl apply -f calico.yamlCalico is said to have most advanced cni network plugin.
CKA 및 CKAD 시험에서는 CNI 플러그인을 설치하라는 메시지가 표시되지 않습니다. 그러나 만약 요청을 받으면 설치할 수 있는 정확한 URL을 제공받게 됩니다.
DNS in Kubernetes
Kubernetes는 CoreDNS를 사용합니다. CoreDNS 는 유연하고 확장 가능한 DNS 서버로, Kubernetes 클러스터 DNS 역할을 할 수 있습니다.
Memory and Pods
대규모 쿠버네티스 클러스터에서, 코어DNS의 메모리 사용량은 주로 클러스터의 파드 및 서비스 수에 의해 영향을 받습니다. 다른 요인으로는 filled DNS 응답 캐시의 크기와 CoreDNS 인스턴스당 쿼리 수신 속도(QPS)가 있습니다.
Troubleshooting issues related to coreDNS
-
pending인 상태의 CoreDNS 파드를 발견하면 먼저 네트워크 플러그인이 설치되어 있는지 확인합니다
-
코어DNS 파드가 CrashLoopBackOff 또는 오류 상태입니다.
이전 버전의 Docker로 SELinux를 실행하는 노드가 있는 경우 coredns 파드가 시작되지 않는 시나리오가 발생할 수 있습니다. 이 문제를 해결하려면 다음 옵션 중 하나를 시도해 볼 수 있습니다:
a)최신 버전의 Docker로 업그레이드합니다.
b)SELinux를 비활성화합니다.
c)허용 권한 확장을 true로 설정하도록 coredns 배포를 수정합니다:
kubectl -n kube-system get deployment coredns -o yaml | \
sed 's/allowPrivilegeEscalation: false/allowPrivilegeEscalation: true/g' | \
kubectl apply -f -d) 쿠버네티스에 배포된 CoreDNS 파드가 루프를 감지할 때 CoreDNS에 크래시루프백오프가 발생하는 또 다른 원인이 있습니다.
이 문제를 해결하는 방법에는 여러 가지가 있으며, 그 중 일부는 아래와 같습니다:
- CoreDNS 파드와 kube-dns 서비스가 정상적으로 작동한다면, kube-dns 서비스에 유효한 엔드포인트가 있는지 확인합니다.
kubectl -n kube-system get ep kube-dns
서비스에 대한 엔드포인트가 없는 경우, 서비스를 검사하고 올바른 셀렉터와 포트를 사용하는지 확인합니다.
Kube-Proxy
kube-proxy는 클러스터의 각 노드에서 실행되는 네트워크 프록시이며, 노드에서 네트워크 규칙을 유지 관리합니다. 이러한 네트워크 규칙은 클러스터 내부 또는 외부의 네트워크 세션에서 파드로의 네트워크 통신을 허용합니다.
kubeadm으로 구성된 클러스터에서는 데몬셋으로 kube-proxy를 찾을 수 있습니다.
kubeproxy는 각 서비스와 관련된 서비스 및 엔드포인트를 감시합니다(watching). 클라이언트가 가상 IP를 사용하여 서비스에 연결하려고 할 때, 실제 파드로 트래픽을 전송하는 것은 kubeproxy가 담당합니다.
kubectl describe ds kube-proxy -n kube-system을 실행하면 kube-proxy 컨테이너 내부에서 다음 명령어로 kube-proxy 바이너리가 실행되는 것을 확인할 수 있습니다.
/usr/local/bin/kube-proxy
--config=/var/lib/kube-proxy/config.conf
--hostname-override=$(NODE_NAME)
따라서 configuration 파일(예: /var/lib/kube-proxy/config.conf)에서 구성을 가져오고 호스트 이름을 파드가 실행 중인 노드 이름으로 override할 수 있습니다.
configuration파일에서 클러스터CIDR, kubeproxy 모드, ipvs, iptables, bindaddress, kube-config 등을 정의한다.

테스트 문제를 다 마쳤긴 하지만 application과 master node정도 까진 괜찮은데 worker node 와 network쪽은 연습이 더 필요할 것 같다.
